Основы AS/400 [Фрэнк Солтис] (fb2) читать онлайн
- Основы AS/400 4.45 Мб, 510с. скачать: (fb2) - (исправленную) читать: (полностью) - (постранично) - Фрэнк Солтис
[Настройки текста] [Cбросить фильтры]
[Оглавление]
Основы AS/400
В данном переводе второго издания книги "Основы AS/400" описаны практически все аспекты работы этой вычислительной системы: от используемых в ней новейших аппаратных и программных технологий до истории создания. Издание состоит из предисловия, введения, 12 глав, приложения и предметного указателя; содержит иллюстрации. Автор книги Фрэнк Солтис, сделавший академическую карьеру в области информатики, начиная с замысла System/38, является одним из ведущих специалистов по идеологии и архитектуре AS/400. Книга предназначена для широкого круга читателей: бизнесменов, менеджеров, руководителей подразделений, желающих понять, чем система или сервер AS/400e могут быть выгодны их бизнесу. Тем не менее, издание будет полезно и специалистам, которые хотят разобраться в мельчайших деталях. На русском языке публикуется впервые. Фрэнк Солтис Той, кого люблю уже более 33 лет — моей жене Сандре.От автора
Рочестер— пожалуй, самое творческое подразделение корпорации IBM. Далеко не все сотрудники IBM согласятся с таким утверждением. Разумеется, работа в маленьком городке на краю прерий на юго-востоке Миннесоты не означает полной изолированности от остальной корпорации, но все же создает сложности в части признания заслуг. Мы, сотрудники подразделения IBM в Рочестере, не часто получали право голоса при определении перспектив развития корпорации. Но изолированность имеет и свои преимущества. Самое большое из них — возможность сосредоточиться на нуждах наших заказчиков. Год за годом преданные своему делу люди из Рочестера продолжали творить, и год за годом результаты этого творчества приносили IBM прибыль. Рочестер никогда не достигал больших побед в «битве прожектеров» в штаб-квартире IBM, но мы всегда выходили победителями в битве за заказчиков. Секрет успехов Рочестера — в его людях. Мы здесь, потому что нам это нравится. Нравится жить и работать в маленьком городе, где, как гласят рекламные щиты, «зимы холодны, а компьютеры горячи». Для многих из нас Рочестер — это не просто остановка в пути, но станция назначения. Наверное, именно поэтому мы с таким трепетом относимся к результатам своего труда. В этой книге я стремился поименно вспомнить подвижников, чей самоотверженный труд сделал возможным успех AS/400 и ее предшественниц. Полностью эта задача практически невыполнима. Например, здесь не упомянуты многие лидеры разработки OS/400, так как в книге просто не хватило места для подробного рассказа об этой изумительной операционной системе. Кстати, такой рассказ вполне может лечь в основу отдельного издания. Я надеюсь, те, кого мне не удалось упомянуть, простят мне. За 34 года, проработанных в Рочестере, не было дня, когда бы я ни ощущал царящей там атмосферы творчества. Конечно, наша работа не завершена. Во многих отношениях серия AS/400e — лишь первый шаг на новом пути, и еще далеко не удовлетворяет своих создателей. Книга Inside the AS/400 (первое издание), где было описано то новое, что было внесено при разработке версии 3, создавалась именно под этим углом зрения. В этом, втором, издании мы рассмотрим версию 4 и то, что будет после нее. Замысел этой книги возник еще в 1985 году. Некоторые, в том числе Пол Конт (Paul Conte), написавший предисловие для обоих изданий, предлагали мне написать книгу о System/38 и истории этого проекта. С повторным рождением System/38 в виде AS/400 в 1988 году я начал писать книгу о разработке этих систем и людях, их создавших. С тех пор я постоянно исправлял рукопись. Пол и другие торопили меня с завершением «летописи», и просили поскорей поделиться историей Рочестера с остальным миром. Кое-что из той рукописи вошло в первое издание Inside the AS/400. Этот исторический экскурс имел столь положительные отклики, что я расширил его и включил как приложение в это, второе, издание. В течение нескольких последних лет я с огромным удовольствием сотрудничаю с Duke Communications International (родительской компанией Duke Press и журнала NEWS/400). Дэйв Дюк (Dave Duke) и его сотрудники проделывают огромную работу по изданию журнала, книг и организации конференций. И когда пришла пора подыскивать издательство для этой книги, я, естественно, выбрал Duke Press. С самого начала со мной работал Дэйв Бернар (Dave Bernard), главный редактор Duke Press, благодаря которому и первое, и второе издание книги получились столь качественными. Трудную работу редактора обоих изданий книги выполняла Шэрон Хэмм (Sharon Hamm). Ей приходилось обрабатывать бесконечные изменения, которые я вносил в рукопись, и в то же время удерживать меня и сотрудников издательства в рамках плана. Она прекрасно справилась с этой задачей. Спасибо, Шэрон; работа с тобой была удовольствием. Над этим вторым изданием работала также Триш Фабион (Trish Faubion) — ведущий редактор Duke Press. В первый раз мне довелось сотрудничать с ней при написании статей для NEWS/400 (тогда она была ведущим редактором этого журнала). Триш занималась выпуском второго издания, составляла для нас план и помогала укладываться в него. Спасибо тебе, Триш, за твой вклад в создание этой книги. Наибольший вклад в окончательное оформление обоих изданий внес был научный редактор Ричард Рубин (Richard Rubin). Ричард хорошо известен своими превосходными статьями, особенно в области проектирования баз данных. Я был склонен смотреть на AS/400 изнутри, Ричард же — с точки зрения пользователя. Всякий раз, когда я уносился в облака, прославляя какой-нибудь технический аспект AS/400, он спускал меня на землю вопросом: «Какой смысл это имеет для пользователя?» Благодаря тому, что Ричард почти везде настаивал на наличии примеров и проявлял внимание к деталям, текст стал гораздо понятнее широкому кругу читателей. Спасибо, Ричард. Наконец, эта книга вообще не была бы написана без самого важного человека в моей жизни — Сандры, моей жены. Заметив мои затруднения в начале работы, Сандра помогала мне сортировать материалы и расшифровывать видеозаписи моих лекций по архитектуре AS/400. Эти расшифровки и составили черновой вариант книги. Во время работы над вторым изданием она продолжала играть роль «главного одобряющего», советчика, рецензента и редактора по совместительству. Спасибо тебе за то, что ты всегда была рядом. Сандра и я — счастливые родители трех прекрасных сыновей: Майка, Брайана и Стива. Читателям первого издания известно, что мне вместе с сыновьями нравится водить гоночный Порше по дорогам Среднего Запада. Я сожалением должен признать, что Порше был самым заброшенным членом семьи в этом году. Всякий раз, когда я проходил мимо гаража, оттуда прямо-таки слышались его мольбы покататься. Раньше, когда я бывал слишком занят, эту обязанность принимали на себя мои сыновья. Но в этом году они тоже были слишком заняты собственными семьями и карьерой. Так что моей бедной машине оставалось лишь ждать, пока я закончу эту книгу. Но, что это? Я слышу доносящийся из гаража рев гоночного автомобиля. Кто-то зовет меня! — F.S.Предисловие
IBM AS/400 — одна из самых интересных по инженерным решениям и эффективных коммерчески компьютерных архитектур. Задолго до того, как термин «объектно-ориентированный» широко распространился, машинный интерфейс высокого уровня AS/400, появившийся в предшествовавшей ей System/38, предоставил разработчикам приложений набор объектов (таких как очереди, индексы и файлы базы данных), которые при создании программы можно было использовать в качестве строительных блоков. Объекты придали высоким функциональным возможностям системы согласованную и простую в работе форму. Унифицированный объектный интерфейс скрывает от программистов AS/400 детали, благодаря чему они могут игнорировать сложные управляющие блоки и системные процедуры, относящиеся к внутренним процессам операционной системы (ОС). Более того, с помощью набора заранее определенных операций ОС ограничивает доступ к объектам. Это обеспечивает приложениям дополнительную защиту при исполнении. Объекты AS/400 расположены в слое программного обеспечения поверх аппаратных средств. Это позволяет IBM вносить в аппаратуру значительные изменения, не затрагивая при этом приложения. Обычно новое оборудование требует лишь обновления поставляемого IBM внутреннего кода — ведь интерфейсы объектов, задействованных приложениями, неизменны. Это еще одно преимущество объектов AS/400: они позволяют приложениям воспользоваться новшествами аппаратных средств, при этом модифицировать код приложений не требуется. Все детали реализации системных объектов «скрыты» слоем программного обеспечения. Можно сказать, что архитектура AS/400 «балует» программистов — где еще Вы найдете подобную рациональность? И все же программисты любят знать, как работает системное программное обеспечение, и те, кто работает с AS/400 s не исключение. На любой конференции по AS/400 они обычно собираются группами и растолковывают друг другу, какова сущность внутренних процессов системы, что происходит при активизации программного объекта, переопределении файла при его открытии или выполнении какой-нибудь другой операции. Дело, конечно, не просто в неудовлетворенном любопытстве; во многих случаях глубокое понимание архитектуры AS/400 позволяет программисту писать более функциональный или эффективный код. Но любому опытному программисту известно, что только по руководствам всего не узнаешь. Это особенно справедливо для AS/400, руководства по которой специально лишены описания деталей внутренней структуры или функционирования. Сокрытие деталей высокоуровневым машинным интерфейсом AS/400 повсеместно заслужило высокую оценку, и все же многие из нас давно ждали книги вроде этой — ясного и исчерпывающего описания важнейших компонентов архитектуры этой системы. Знакомство с ней необходимо любому программисту, пишущему для AS/400. Конечно, мой интерес (я думаю, это относится и к другим разработчикам) не ограничивается только текущими техническими подробностями. Хочется больше знать и об истории такой совершенной системы, и о людях, давших ей жизнь, и, конечно, о перспективах AS/400. Автор этой книги, Фрэнк Солтис — именно тот человек, кто действительно «изнутри» знает все это, и может компетентно рассказать о создании AS/400, использованных в ней технологиях и планах IBM. Сам Фрэнк — одна из центральных фигур повествования: с момента появления замысла System/38 он играл ключевые роли в эволюции архитектуры AS/400. Его опыт охватывает несколько основных эпох организационного и технологического развития IBM, ему приходилось отвечать и за аппаратуру, и за программное обеспечение и за организационные вопросы. Фрэнк сочетает в себе таланты инженера и системного архитектора, да к тому же сделал академическую карьеру в области информатики. Добавьте к этому незаурядный миннесотский юмор, и вот результат s чтение разделов, посвященных, к примеру, «тегированной памяти» или «очереди распределения задач», становится захватывающим. Сейчас, когда мы переживаем бум Интернета, Web-узлов, языка Java и распределенных вычислений, очень интересно узнать, какие новые возможности AS/400 позволяют ей претендовать на роль «лучшего из серверов». В этом, втором, издании своей книги Фрэнк объясняет, каким образом новая архитектура RISC, а также существенные усовершенствования в OS/400 и SLIC (System Licensed Internal Code) позволяют обеспечить дополнительные возможности и лучшее соотношение цена/производительность для всего модельного ряда AS/400 — от систем начального уровня до мощных кластеров, обрабатывающих миллионы транзакций в час. Поистине, нет человека, который мог бы сделать это лучше. Я впервые встретился с Фрэнком в 1985 году. Тогда я только что познакомился с System/38 после многих лет работы на мэйнфреймах IBM, и эта система была для меня новой и интересной. Фрэнк произвел на меня впечатление обычного «IBM'ера» — он часами рассуждал о технических деталях архитектуры, уделяя при этом большое внимание «человеческому фактору». Он был таким интересным и толковым рассказчиком, что я принялся убеждать его написать об System/38 книгу. Позднее я узнал, что именно тогда руководству IBM, будущее System/38 представлялось весьма туманным. Понятно, что Фрэнк не хотел рассказывать историю, пока не убедился, что у нее будет счастливый конец. Теперь же огромный успех AS/400, широта ее распространения и ключевая роль в стратегии IBM позволяют Фрэнку поделиться своими знаниями. Счастливого Вам путешествия по AS/400 с гидом, о котором можно только мечтать! Пол Конт. Президент, Picante Software, Inc.Введение
Мы, представители компьютерной индустрии, часто с большой гордостью подчеркиваем, как много нам удалось сделать за относительно короткий период времени. Иногда мы даже хвастаемся, что осваиваем новые технологии быстрее, чем кто-либо еще. И все же, нельзя не упомянуть, что, хотя новое аппаратное и программное обеспечение порой действительно создается удивительно быстро, зачастую мы просто используем заново некоторые очень старые идеи. Однажды бывший президент США Гарри С. Трумен (Harry S. Truman) сказал: «В мире нет ничего нового, за исключением истории, которой Вы не знаете». Чтобы до конца понять, как работает любая вычислительная система, необходимо изучить ее историю, а также понять людей, ее создавших. Особенно верно это для такой системы, как AS/400, которая, как мне кажется, не вписывается в общие рамки. На дизайн вычислительной системы значительное влияние оказывает то, в рамках какой организации она была создана, и то, какие продукты ей предшествовали. Если группе разработчиков удалось нечто успешное, то на следующем цикле проектирования она «изобретет» это заново и вместо новой системы построит улучшенную модель существующей. Радикально новые идеи обычно приходят извне. Возьмем проекты, создававшиеся на протяжении многих лет компьютерными фирмами восточного побережья США. Как правило, их ключевые концепции были заимствованы из исследований, выполненных в учебных заведениях типа Массачу-сетского технологического института MIT (Massachusetts Institute of Technology). В 60-х годах инженеры и ученые MIT под патронажем Министерства обороны США работали над проектом МШг^. Впоследствии и IBM, и другие компании нанимали выпускников этих университетов для создания новых операционных систем. Так как проектировщики имели сходный опыт, то и созданные ими системы оказались очень похожими. Такие операционные системы как ОС MVS для мэйнфреймов IBM, ОС VMS корпорации Digital Equipment и все ОС Unix — имеют общие «восточно-университетские» корни. Даже новая ОС — Windows NT фирмы Microsoft — несет в себе черты того же самого прошлого. Команда, создавшая Windows NT, ранее работала над ОС VMS компании Digital, в результате многие элементы Windows NT «навеяны» VMS. Если Вы замените буквы аббревиатуры VMS на следующие за ними буквы английского алфавита, то получите WNT, и это не просто случайность. История AS/400 совершенно иная. Менее года назад я был в Буэнос-Айресе на встрече с группой пользователей этой системы. По окончании встречи молодой репортер газеты «La Nacion» спросил меня: «Сформулируйте, пожалуйста, коротко причины того, почему в AS/400 столь много новшеств?». И я ответил: «Потому что никто из ее создателей не заканчивал MIT.» Заинтригованный моим ответом, репортер попросил разъяснений. Я сказал, что не собирался критиковать MIT, а лишь имел в виду то, что разработчики AS/400 имели совершенно иной опыт, нежели выпускники MIT. Так как всегда было трудно заставить кого-либо переехать с восточного побережья в 70-тысячный миннесотский городок, в лаборатории IBM в Рочестере практически не оказалось выпускников университетов, расположенных на востоке США. И создатели AS/400 — представители «школ» Среднего Запада — не были так сильно привязаны к проектным решениям, используемым другими компаниями.
Далее я хотел бы предложить Вашему вниманию краткий исторический обзор событий, который привели в конечном счете к современной серии AS/400е, а также мои наблюдения о тех, кто явил миру эту замечательную систему и предрешил ее успех. Более полную историю AS/400, в том числе и информацию об истоках замысла проекта, Вы можете найти в Приложении.
Менее года назад я был в Буэнос-Айресе на встрече с группой пользователей этой системы. По окончании встречи молодой репортер газеты «La Nacion» спросил меня: «Сформулируйте, пожалуйста, коротко причины того, почему в AS/400 столь много новшеств?». И я ответил: «Потому что никто из ее создателей не заканчивал MIT.» Заинтригованный моим ответом, репортер попросил разъяснений. Я сказал, что не собирался критиковать MIT, а лишь имел в виду то, что разработчики AS/400 имели совершенно иной опыт, нежели выпускники MIT. Так как всегда было трудно заставить кого-либо переехать с восточного побережья в 70-тысячный миннесотский городок, в лаборатории IBM в Рочестере практически не оказалось выпускников университетов, расположенных на востоке США. И создатели AS/400 — представители «школ» Среднего Запада — не были так сильно привязаны к проектным решениям, используемым другими компаниями.
Далее я хотел бы предложить Вашему вниманию краткий исторический обзор событий, который привели в конечном счете к современной серии AS/400е, а также мои наблюдения о тех, кто явил миру эту замечательную систему и предрешил ее успех. Более полную историю AS/400, в том числе и информацию об истоках замысла проекта, Вы можете найти в Приложении.
Начало
В 50-х годах XIX века группа фермеров Новой Англии поселилась в Рочестере (Rochester), штат Миннесота. Вероятно, Рочестер и сейчас был бы маленьким сонным фермерским городком, если бы не торнадо 1883 года, от которого пострадали многие жители. Врач Уильям Уоралл Мэйо (William Worall Mayo), в то время гостивший здесь у приятеля, лечил раненых. Он так и остался в Рочестере, а позже к нему присоединились два его сына — Уильям в 1883 году и Чарльз в 1888. Принятое ими в 1889 году решение — открыть частную больницу, которую они назвали клиникой Мэйо, — превратило Рочестер, в конце концов, в международный медицинский центр. Сейчас здесь один врач на 70 жителей, чистая окружающая среда, замечательная система образования и низкий уровень преступности. По данным журнала «Money», Рочестер год за годом входит в двойку или тройку лучших мест страны для проживания. А самое важное для нас то, что Рочестер — колыбель AS/400. В 1956 году IBM, в то время нью-йоркская компания с несколькими производственными и проектными филиалами в разных городах этого штата, объявила о создании нового подразделения в Рочестере. Томас Дж. Уотсон-старший (Thomas J. Watson, Sr.), основатель IBM, прожил большую часть жизни в Нью-Йорке и предпочитал размещать новые филиалы именно там. Решение выйти за пределы штата Нью-Йорк означало для IBM отказ от имиджа местной компании. Впервые я приехал в Рочестер в 1962 году, за год до открытия там проектной лаборатории. Тогда я еще учился в университете, и IBM предложила мне работу на лето в Рочестере. В то время меня не привлекали ни компьютеры, ни тем более жизнь в маленьком степном городе на юге Миннесоты — я грезил авиакосмической индустрией Калифорнии. Но я был знаком с менеджером проекта в Рочестере и думал, что мне будет приятно поработать с ним летом. По приезде я узнал, что работу над проектом уже получил другой человек. Мне предстояло работать над созданием банковского терминала. Я был разочарован, но согласился на этот вариант по той же причине, что заставляет других работать там, где им не нравится: я нуждался в деньгах. Видимо, руководитель проекта банковского терминала знал, что я был разочарован, не получив работу над медицинским проектом. Он провел со мной очень много времени в разговорах о том, какую роль будут играть компьютеры в будущем Рочес-тера. И я поверил, что инженеры, в совершенстве владеющие навыками проектирования программного и аппаратного обеспечения, смогут здесь реализовать себя. В конце лета я вернулся в университет с вновь проснувшимся интересом к проектированию цифровых вычислительных систем. Через год, окончив университет, я вернулся в Рочестер и стал работать под началом того же руководителя проекта. В течение следующих нескольких лет подразделение IBM в Рочестере перешло к разработке компьютеров, и я принял в этом участие. Затем, мне вновь предложили поучиться: я был одним из многих инженеров, имевших весьма ограниченные познания в области операционных систем. Недостаток знаний о вычислительных архитектурах и проектировании операционных систем я возмещал в Университете штата Айова (Iowa State University). Я вернулся в Рочестер в конце 1968 года со степенью доктора и некоторыми вполне сложившимися идеями о том, как следует проектировать новую компьютерную систему. Вскоре, в июне 1969 года, был объявлен первый компьютер Рочестера System/3. System/3 была продукцией специального назначения и более походила на счетную машину, чем на компьютер. Я не понимал тогда, что разработчикам из Роче-стера удалось попасть в компьютерный бизнес, лишь создав в штаб-квартире IBM иллюзию, что они делают счетную машину. В конечном счете это не сыграло большой роли, так как System/3 было суждено стать нашим первым успехом, залогом будущей революции в компьютерной индустрии. В течение 1969 года я работал над проектом, в ходе которого мне удалось «отшлифовать» многие из идей, почерпнутых в университете. В конце 1969 года я получил новое задание — разработать архитектуру для наследника System/3.Революция начинается
В пронизывающе холодный вторник 8 января 1970 года я[ 1 ] представил руководству Рочестера предложения по революционно новой компьютерной архитектуре, основой которой был машинный интерфейс высокого уровня. Примененную в этой архитектуре структуру адресации, названную одноуровневой памятью, я позаимствовал и развил из собственной докторской диссертации. Основной мотив — защитить капиталовложения заказчиков в прикладные программы, сделав вычислительную систему независимой от нижележащих аппаратных технологий. Новая система должна была совершенно отличаться от System/3, но, несмотря на это, содержать большую часть функций последней. Эта способность поддерживать среду System/3 оказалась крайне полезной годы спустя, когда нам понадобилось соединить эти две линии. Не испугавшись поистине радикальных идей, лежавших в основе новой архитектуры, руководство Рочестера решило принять эти предложения и создать специальную группу для разработки новой системы. В течение шести месяцев была создана группа из девяти человек, которая должна была превратить мечты в реальность. Я стал архитектором новой системы. Вряд ли я понимал тогда, что буду оставаться в этой роли более четверти столетия. Подразделение Advanced Systems, сформированное для создания новой системы, действовало изолированно от разработки System/3 (семейство System/3 продолжало расти, и к нему добавились System/32 в 1975 году и System/34 в 1977). До середины 70-х новым проектом занималось не так уж много сотрудников, но затем сотни и тысячи людей со всей IBM присоединились к нашей команде. 24 октября 1978 года мы объявили о создании новой системы. Она была названа System/38. System/38 была немедленно объявлена компьютером с расширенной архитектурой — одна из крупнейших инноваций IBM за долгие годы. Очень немногие люди, как внутри IBM, так и вне корпорации, по-настоящему поняли, что произошло. Но среди тех, кто осознал мощь и потенциал System/38, быстро сформировалось нечто, похожее на культ. Встречи групп пользователей часто походили на религиозные собрания. Однако System/38 не заменила семейство System/3, как мы изначально надеялись. Новая система не привлекла многих наших старых заказчиков. Первые продажи System/38 были задержаны до июля 1980 года, как мы объявили, из-за недостаточной производительности. На самом деле, самая большая проблема производительности заключалась в том, что система не работала сколь-нибудь продолжительное время перед сбоем. Эта задержка отпугнула некоторых заказчиков. Кроме того, владельцы меньших систем — System/32 и System/34 — нашли, что новая система слишком велика и слишком дорога. Удовлетворить потребности большинства таких заказчиков смог объявленный в мае 1983 был последний вариант System/3 — System/36. Так что разработки компьютеров в Рочестере по-прежнему шли в двух разных направлениях.Проект Fort Knox
В начале восьмидесятых IBM решила объединить пять ранее несовместимых линий продукции IBM, включая две из Рочестера, в новой интегрированной системе, названной Fort Knox. Ставилась цель: владельцы всех пяти типов машин должны были иметь возможность перенести свои приложения на эту единую систему. Разработка Fort Knox началась в четырех разных лабораториях IBM с больших инвестиций. В 1985 году стало ясно, что проект Fort Knox зашел в тупик. У нас, в Рочестере, многие считали его нежизнеспособным с самого начала, так как он был призван разрешить проблемы IBM, а не потребителей. Было и такое мнение: проект слишком сложен технически, нет способа преобразовать пять разных систем в одну. И, кроме того, совместной работой четырех лабораторий управлять почти невозможно. По всем указанным причинам, Fort Knox потерпел неудачу, и IBM его закрыла. Fort Knox «высосал» большинство ресурсов, которые иначе были бы направлены на System/36 и System/38. А без инвестиций трудно было поддерживать конкурентоспособность обеих систем. IBM зашла настолько далеко, что объявила System/38 «не стратегической» и не рекомендовала клиентам приобретать ее.Ранняя AS/400 (она же System/38)
В конце 1985 небольшая группа разработчиков из Рочестера продемонстрировала, что на System/38 можно создать среду для программного обеспечения System/36. Стоимость оборудования снизилась настолько, что мы теперь могли создавать малые модели System/38. Это означало, что мы могли «закрыть» весь диапазон продукции Рочестера. Быстро последовало предложение: объединить две системы в одной машине, основанной на System/38. Мы назвали новую машину Silverlake[ 2 ] и убедили руководство IBM, что можем ее создать. Снова Рочестер показал IBM и всему компьютерному миру, на что способен. После беспрецедентного 28-месячного цикла разработки, мы объявили о новой, объединенной, системе под названием AS/400. Посвященные, однако, знали, что внутри каждой AS/400 скрывается System/38[ 3 ]. Успех AS/400 превзошел все ожидания. Очень быстро она не только «отвоевала» часть рынка, захваченную конкурентами в предыдущие годы, но и быстро обошла их всех. Ныне во всем мире работает более 500 000 систем AS/400, что делает ее бестселлером среди многопользовательских вычислительных систем. Культ System/38 стал полноценной религией. В 1991 Apple Computer, Motorola и IBM достигли исторического соглашения по разработке нового семейства процессоров. Эти процессоры должны были использовать архитектуру RISC и применяться везде, от ручных устройств до суперкомпьютеров. Новые процессоры, названные PowerPC, были призваны потрясти компьютерный мир. В это время Рочестер искал новую архитектуру процессора для следующего поколения AS/400. Это должен был быть первый полностью новый процессор по сравнению с 1978, использовавшимся в оригинальной System/38. И мы подумали: почему бы не объединить силы с альянсом PowerPC, чтобы создать для AS/400 новый процессор, основанный на этой архитектуре?Союз AS/400-PowerPC
Я возглавлял в Рочестере группу, которая должна была определить требования к новому процессору для AS/400. Тогда мы вместе с архитекторами и разработчиками PowerPC пытались создать 64-разрядный процессор, основанный на архитектуре PowerPC. По нашему мнению, это должно было обеспечить успех AS/400 в следующем столетии. Появление новых процессоров PowerPC, оптимизированных для AS/400 — веха в истории AS/400, демонстрирующая мощь ее архитектуры. Обычно производители компьютерных систем, планируя перевод своих компьютеров на новые архитектуры процессоров, испытывают смешанные чувства. Ведь тем самым они обрекают своих заказчиков на довольно большие неудобства. Чтобы воспользоваться преимуществами новых процессоров, прикладное программное обеспечение нужно перекомпилировать или переписать. Операционная система также должна быть переписана. В результате, большинство производителей неохотно используют новейшие процессорные технологии. Не зависящая от технологии архитектура AS/400 снимает эту проблему, позволяет пользователям относительно легко переходить на новые процессоры. Существующие приложения AS/400 могут воспользоваться скоростью и расширенной разрядной сеткой без переписывания или перекомпилирования программ. Кроме IBM ни одна другая фирма не может сказать такого о своей продукции. Часто задают вопросы: «Как появилась AS/400?», «Кто эти люди, называющие себя ее создателями?». Далее я постараюсь ответить на них.Команда технических разработчиков
В IBM разработка любой новой продукции осуществляется командой, каждый из участников которой вносит в дело свой вклад. По правде говоря, успех проекта обычно определяют всего несколько человек. Это инженеры и администраторы — лидеры, обладающие предвидением, творческими способностями и энергией. Своим созданием и успехом как System/38, так и AS/400 обязаны именно таким людям. В Рочестере много хороших инженеров и администраторов, но лишь несколько истинных провидцев. Дальновидный лидер способен не только сознавать перспективы проводимых работ, но и донести свое видение до других. Затем идея начинает жить собственной жизнью, и приобретать некие реальные очертания. Теперь дело лидера — поощрение тех, кто старательно и успешно работает над различными частями проекта. В 1972 году я по-прежнему все еще пытался увлечь наших разработчиков радикальными концепциями архитектуры System/38. Большинство технических специалистов успешно трудились над созданием новой аппаратуры, «не ведая, что творят». Они полагали, что просто разрабатывают некое новое программное обеспечение для уже существующей системы. (Формат внутренних команд System/38 был очень похож на используемый в System/370.) Это был единственный способ задействовать людей так, чтобы они чувствовали себя комфортно, не подозревая, что делают нечто необычное[ 4 ]. Прорыв на фронте программного обеспечения тогда достигнут не был. Большинство программистов в Рочестере написали улучшенные версии программного обеспечения System/3. Они чувствовали себя вполне комфортно и не желали никаких революций в области архитектуры. Именно в это время на передовую линию создания полной архитектуры вышли два человека. Они помогли мне убедить все сообщество разработчиков в том, что мы находимся на правильном пути. Дик Бэйнс (Dick Bains) и Рой Хоффман (Roy Hoffman) — одни из наиболее творческих, обладающих истинным даром предвидения людей, которых я когда-либо встречал. Они также отличаются истинной преданностью идее. В течение 1972 мы втроем завершили спецификацию архитектуры AS/400, и хотя в последующие годы некоторое детали претерпели изменения, в целом концепция осталась неизменной. У Дика — талант в области технологии компиляторов и языков. Его опыт стал решающим при определении машинного интерфейса высокого уровня и внутреннего транслятора.
Дик вырос в соседнем штате Висконсин, до начала работы на IBM в Рочесте-ре, попробовал себя в нескольких ролях, одно время даже был инструктором по лыжам в Эспине (Aspen), штат Колорадо. И всякий раз, когда при разработке спецификации архитектуры у нас возникали затруднения, он начинал вздыхать по более легкой жизни лыжного инструктора. По счастью, Дик не поддался этому стремлению.
Дик каждый раз так увлекался решением проблемы, что мог действовать, не задумываясь о последствиях. Например, годом ранее, он пытался убедить руководство в несовершенстве защиты некоторых местных компьютерных систем. Когда никто не захотел его слушать, Дик решил продемонстрировать проблему наглядно. Войдя в систему, допуска к которой он не имел, он оставил там сообщение с предложением позвонить ему, если те, кто несет ответственность за защиту системы, захотят закрыть «дыру». При этом он умудрился нечаянно попортить несколько файлов. Вся эта история чуть не стоила Дику места, но к счастью для всех нас, руководство признало его талант и он не был уволен. Более того, ему удалось доказать свою правоту.
До сего дня Дик сохранил те же качества. Когда он считает, что что-либо должно быть сделано, то формальности его не останавливают; он берет и делает это. Широта знаний по AS/400 и способность решать технические и коммерческие проблемы в контакте с заказчиками делают его очень ценным специалистом. Он остается одним из технических лидеров работ по AS/400.
У Роя уже в те времена был накоплен солидный опыт в области компьютерных архитектур и проектирования операционных систем. Его вклад в разработку архитектуры System/38 — особенно в области низкоуровневых функций операционной системы — обеспечил ей успех.
У Дика — талант в области технологии компиляторов и языков. Его опыт стал решающим при определении машинного интерфейса высокого уровня и внутреннего транслятора.
Дик вырос в соседнем штате Висконсин, до начала работы на IBM в Рочесте-ре, попробовал себя в нескольких ролях, одно время даже был инструктором по лыжам в Эспине (Aspen), штат Колорадо. И всякий раз, когда при разработке спецификации архитектуры у нас возникали затруднения, он начинал вздыхать по более легкой жизни лыжного инструктора. По счастью, Дик не поддался этому стремлению.
Дик каждый раз так увлекался решением проблемы, что мог действовать, не задумываясь о последствиях. Например, годом ранее, он пытался убедить руководство в несовершенстве защиты некоторых местных компьютерных систем. Когда никто не захотел его слушать, Дик решил продемонстрировать проблему наглядно. Войдя в систему, допуска к которой он не имел, он оставил там сообщение с предложением позвонить ему, если те, кто несет ответственность за защиту системы, захотят закрыть «дыру». При этом он умудрился нечаянно попортить несколько файлов. Вся эта история чуть не стоила Дику места, но к счастью для всех нас, руководство признало его талант и он не был уволен. Более того, ему удалось доказать свою правоту.
До сего дня Дик сохранил те же качества. Когда он считает, что что-либо должно быть сделано, то формальности его не останавливают; он берет и делает это. Широта знаний по AS/400 и способность решать технические и коммерческие проблемы в контакте с заказчиками делают его очень ценным специалистом. Он остается одним из технических лидеров работ по AS/400.
У Роя уже в те времена был накоплен солидный опыт в области компьютерных архитектур и проектирования операционных систем. Его вклад в разработку архитектуры System/38 — особенно в области низкоуровневых функций операционной системы — обеспечил ей успех.
 Рой вырос на ферме неподалеку от Рочестера. Как и многие молодые люди, он рано покинул дом, чтобы иметь возможность учиться в колледже и работать. Какое-то время он работал на другую компьютерную компанию, но, получив докторскую степень, вернулся в Рочестерское подразделение IBM. По выходным Рой гоняет по окрестностям на мотоцикле. У нас были долгие дискуссии о сравнительных достоинствах мотоциклов и спортивных машин (я всегда предпочитал, чтобы у меня над головой была какая-то крыша или перекладина).
Рою нет равных в решении технических проблем. Его познания в области вычислительных систем огромны, он способен атаковать проблему с позиций, недоступных большинству из нас. Его свежий взгляд часто помогал найти красивое техническое решение. (На самом деле Рой пошел дальше. Он часто давал окружающим и личные советы, нужны они нам были или нет. Меня по-прежнему забавляет, с каким удовольствием он стремится проанализировать ситуацию и дать мне какой-нибудь дикий совет по воспитанию детей или по другому предмету, в котором абсолютно несведущ.) После завершения работы над System/38, Рой возглавлял некоторые передовые технические проекты Рочестера. Он также работал над новыми технологиями для всей IBM. Рой был членом IBM Academy, где помогал определять направления технического развития всей корпорации. В 1994 году Рой ушел на пенсию. Сейчас он как раз закончил книгу о сжатии данных, и в погожие дни Вы по-прежнему можете увидеть, как он гоняет на своем «Харлей-Дэвидсоне».
Не ясно как, но этот союз лыжного тренера, «рокера» и автомобильного фаната достиг успехов в компьютерной области. К концу 1972 разработка новой архитектуры была завершена. В последующие годы Дик, Рой и я часто собирались для обсуждения изменений и новых идей. До настоящего дня я удивляюсь, как много из того, что мы совместно вложили в систему, другие открывают только сейчас.
Рочестеру повезло со специалистами. В пользу этого суждения говорят многие инновации как в аппаратном, так и в программном обеспечении. Однако никто другой не обладал таким видением системы и ее перспектив, как Дик и Рой. И как и очень многие другие узкие специалисты, чья работа не видна непосвященным, эти двое никогда не получали того признания, которое заслужили.
Рой вырос на ферме неподалеку от Рочестера. Как и многие молодые люди, он рано покинул дом, чтобы иметь возможность учиться в колледже и работать. Какое-то время он работал на другую компьютерную компанию, но, получив докторскую степень, вернулся в Рочестерское подразделение IBM. По выходным Рой гоняет по окрестностям на мотоцикле. У нас были долгие дискуссии о сравнительных достоинствах мотоциклов и спортивных машин (я всегда предпочитал, чтобы у меня над головой была какая-то крыша или перекладина).
Рою нет равных в решении технических проблем. Его познания в области вычислительных систем огромны, он способен атаковать проблему с позиций, недоступных большинству из нас. Его свежий взгляд часто помогал найти красивое техническое решение. (На самом деле Рой пошел дальше. Он часто давал окружающим и личные советы, нужны они нам были или нет. Меня по-прежнему забавляет, с каким удовольствием он стремится проанализировать ситуацию и дать мне какой-нибудь дикий совет по воспитанию детей или по другому предмету, в котором абсолютно несведущ.) После завершения работы над System/38, Рой возглавлял некоторые передовые технические проекты Рочестера. Он также работал над новыми технологиями для всей IBM. Рой был членом IBM Academy, где помогал определять направления технического развития всей корпорации. В 1994 году Рой ушел на пенсию. Сейчас он как раз закончил книгу о сжатии данных, и в погожие дни Вы по-прежнему можете увидеть, как он гоняет на своем «Харлей-Дэвидсоне».
Не ясно как, но этот союз лыжного тренера, «рокера» и автомобильного фаната достиг успехов в компьютерной области. К концу 1972 разработка новой архитектуры была завершена. В последующие годы Дик, Рой и я часто собирались для обсуждения изменений и новых идей. До настоящего дня я удивляюсь, как много из того, что мы совместно вложили в систему, другие открывают только сейчас.
Рочестеру повезло со специалистами. В пользу этого суждения говорят многие инновации как в аппаратном, так и в программном обеспечении. Однако никто другой не обладал таким видением системы и ее перспектив, как Дик и Рой. И как и очень многие другие узкие специалисты, чья работа не видна непосвященным, эти двое никогда не получали того признания, которое заслужили.
Команда менеджеров
Ни одна система не «пойдет» только благодаря удачному инженерному решению; без хорошего управления тоже не обойтись. На мой взгляд, успех System/38 и AS/400 обеспечили пятеро менеджеров, лучше других увидевшие их перспективы. Но один из пяти заслуживает признания более, чем остальные: Гарри Ташиян (Harry Tashjian). Это он, осознав потребность в небольшой, простой в использовании деловой системе, и создал новый рынок для компьютеров. Без его дара предвидения не было бы успеха наших компьютеров. Гарри был главной организующей силой проектов System/3, System/32, System/34, System/36 и System/38. Сначала он выполнял функции системного менеджера (system manager) всех этих продуктов, позднее стал директором Рочестерской лаборатории. Именно благодаря Гарри крошечное подразделение IBM, затерянное среди кукурузных полей Миннесоты, стало мировым лидером в разработке деловых компьютерных систем. Гарри Ташиян — тот самый менеджер проекта банковского терминала, много лет назад склонивший меня к работе с компьютерами. До сих пор помню наши долгие разговоры о потенциале Рочестера в разработке новых вычислительных систем. Гарри «благословил» меня на новое путешествие в университет для изучения компьютерных архитектур, а когда я опять вернулся в Рочестер, именно он назначил меня на разработку архитектуры System/38, которой суждено было превратиться в AS/400, и обеспечил мне поддержку. Без Гарри AS/400 не было бы. Успех System/38 обеспечили еще два менеджера. Рей Клотц (Ray Klotz) был нашим техническим менеджером (engineering manager) и моим боссом на протяжении большей части проекта. В 1970 году Гарри поручил Рею создать команду из 9 человек. Хорошо разбираясь в аппаратном обеспечении, Рей курировал создание процессора System/360 в Эндикотте (Endicott), штат Нью-Йорк, прежде чем пришел в Рочес-тер, чтобы возглавить разработку аппаратуры System/3. Сначала Рей относился к System/38 сдержаннее, чем многие из нас. Он иногда напоминал, что все аппаратное обеспечение System/3 насчитывало лишь 3 000 цепей, и спрашивал, почему нам нужно настолько больше. Он продолжал сомневаться в наших технических решениях до тех пор, пока не приходил к убеждению, что мы рассмотрели все возможные варианты. Затем он давал нам «карт-бланш». Всякий раз, когда мы испытывали трудности, он был рядом, чтобы поддержать и помочь найти выход.
Для большинства из нас Рей был кем-то вроде отца. Мы все вздрагивали, когда он повышал голос, что бывало часто. Он требовал от каждого из нас безупречной работы и обычно добивался своего. Но за грубоватой внешностью Рея скрывался удивительно тонкий человек.
Из всех моих знакомых Гейлорд Гленн Хенри (Gaylord Glenn Henry) — самый выдающийся и совершенно неистовый менеджер.
Сказать, что Гленн не вполне вписывался в образ типичного, консервативного менеджера IBM, — не сказать ничего. Неряшливая борода, часто нелепая одежда и неизменные упаковки по шесть розовых банок какой-то диетической «шипучки» свидетельствовали о том, что перед Вами незаурядная личность.
В 1972 году Гленн перешел к нам из лаборатории IBM в Бока Ратон (Boca Raton), штат Флорида, и стал менеджером по программированию (programming manager) для System/32, а затем и System/38. Сильный и целеустремленный человек, он вдохновлял окружающих, увлекал за собой как разработчиков, так и администраторов. Когда нам казалось, что возникшая проблема непреодолима, Гленн убеждал нас, что все держит под контролем. Вскоре как-то само собой появлялось решение, а Гленн лишь улыбался. Без его таланта и дальновидности разработка System/38 могла быть прекращена множество раз.
Сначала Рей относился к System/38 сдержаннее, чем многие из нас. Он иногда напоминал, что все аппаратное обеспечение System/3 насчитывало лишь 3 000 цепей, и спрашивал, почему нам нужно настолько больше. Он продолжал сомневаться в наших технических решениях до тех пор, пока не приходил к убеждению, что мы рассмотрели все возможные варианты. Затем он давал нам «карт-бланш». Всякий раз, когда мы испытывали трудности, он был рядом, чтобы поддержать и помочь найти выход.
Для большинства из нас Рей был кем-то вроде отца. Мы все вздрагивали, когда он повышал голос, что бывало часто. Он требовал от каждого из нас безупречной работы и обычно добивался своего. Но за грубоватой внешностью Рея скрывался удивительно тонкий человек.
Из всех моих знакомых Гейлорд Гленн Хенри (Gaylord Glenn Henry) — самый выдающийся и совершенно неистовый менеджер.
Сказать, что Гленн не вполне вписывался в образ типичного, консервативного менеджера IBM, — не сказать ничего. Неряшливая борода, часто нелепая одежда и неизменные упаковки по шесть розовых банок какой-то диетической «шипучки» свидетельствовали о том, что перед Вами незаурядная личность.
В 1972 году Гленн перешел к нам из лаборатории IBM в Бока Ратон (Boca Raton), штат Флорида, и стал менеджером по программированию (programming manager) для System/32, а затем и System/38. Сильный и целеустремленный человек, он вдохновлял окружающих, увлекал за собой как разработчиков, так и администраторов. Когда нам казалось, что возникшая проблема непреодолима, Гленн убеждал нас, что все держит под контролем. Вскоре как-то само собой появлялось решение, а Гленн лишь улыбался. Без его таланта и дальновидности разработка System/38 могла быть прекращена множество раз.
 Я еще не упомянул о соревновании по крепости голосовых связок между ° о Гленном и Реем. Если они не были согласны друг с другом, стены дрожали.
Было истинным удовольствием наблюдать за их спорами, особенно зная, что I ни тот, ни другой не понимают по-настоящему того, за что ратуют. Иногда к их спору присоединялся Гарри, но чаще он позволял Гленну и Рею улаживать свои разногласия самостоятельно. Однако все были согласны между ■ собой в одном: мы собираемся создать вычислительную систему, лучшую из когда-либо существовавших в мире. Наградой этим волевым личностям стала System/38.
К сожалению, после окончания работ над System/38 мы расстались с этими людьми. Гарри Ташиян оставил Рочестер, чтобы возглавить создаваемую IBM новую компанию — Discovision. После этого он занимал в IBM другие руководящие посты, прежде чем ушел на пенсию, имея 38 лет стажа.
Гленна перевели в Остин (Austin), штат Техас, где он возглавил разработку PC-RT. Он оставил IBM в 1988 году после 21 года работы, возмущенный неспособностью организации воспринимать новые идеи. Не удивительно, что некоторые из этих идей только сейчас реализованы в продукции IBM. Убежден, что уход Гленна был большой потерей для корпорации.
Но печальней всего была утрата Рея. Он умер вскоре после объявления System/38 и так и не узнал, чем стала его система для всего компьютерного мира. Никто и никогда не сможет занять его место.
Я еще не упомянул о соревновании по крепости голосовых связок между ° о Гленном и Реем. Если они не были согласны друг с другом, стены дрожали.
Было истинным удовольствием наблюдать за их спорами, особенно зная, что I ни тот, ни другой не понимают по-настоящему того, за что ратуют. Иногда к их спору присоединялся Гарри, но чаще он позволял Гленну и Рею улаживать свои разногласия самостоятельно. Однако все были согласны между ■ собой в одном: мы собираемся создать вычислительную систему, лучшую из когда-либо существовавших в мире. Наградой этим волевым личностям стала System/38.
К сожалению, после окончания работ над System/38 мы расстались с этими людьми. Гарри Ташиян оставил Рочестер, чтобы возглавить создаваемую IBM новую компанию — Discovision. После этого он занимал в IBM другие руководящие посты, прежде чем ушел на пенсию, имея 38 лет стажа.
Гленна перевели в Остин (Austin), штат Техас, где он возглавил разработку PC-RT. Он оставил IBM в 1988 году после 21 года работы, возмущенный неспособностью организации воспринимать новые идеи. Не удивительно, что некоторые из этих идей только сейчас реализованы в продукции IBM. Убежден, что уход Гленна был большой потерей для корпорации.
Но печальней всего была утрата Рея. Он умер вскоре после объявления System/38 и так и не узнал, чем стала его система для всего компьютерного мира. Никто и никогда не сможет занять его место.
В последнюю минуту
В начале 80-х годов из-за недальновидного руководства развитие вычислительной техники Рочестера стало спотыкаться. Однако у нас все еще было несколько хороших менеджеров, понимавших значение создаваемых систем. Этим людям приходилось поддерживать жизнь наших проектов зачастую весьма хитрыми способами. Казалось, у нас нет перспектив, и наши позиции на рынке окончательно будут завоеваны конкурентами. По счастью, в последнюю минуту появился человек, спасший Ротчестер от глубокого забвения. Его звали Том Фьюри (Tom Furey). Том всегда был отличным продавцом. Он знал работу IBM изнутри и ухитрился убедить руководство, что системы Рочестера имеют стратегическое значение для будущего корпорации. Затем он начал «накачивать» нас приложить все мыслимые усилия и еще чуть-чуть, чтобы выпустить новую систему в рекордно короткие сроки. Том хорошо знал рынок и требования заказчиков. Он преобразовал Рочестер из организации, управляемой техническими идеями, в организацию, движимую требованиями рынка. Прежде всего, он добился, чтобы наши заказчики были напрямую вовлечены в разработку. Совещания пользователей играли важную роль при выборе вариантов проектирования, а в результате получилась система, которую многие из них чувствовали своей. Позднее, Рочестер выиграл престижную премию Malcolm Baldrige National Quality Award за эту разработку. Часто по-настоящему оцениваешь человека, лишь вглядываясь в него из будущего. Том никогда не был силен по части техники, как некоторые из его предшественников, и многие в лаборатории не принимали его как лидера, под тем предлогом, что Том до конца не может проникнуть в суть того, что они делают. Он и не мог, ну и что? Например, Том никогда не понимал, что AS/400 — это переупакованная System/38; а если и понимал, то никому не говорил об этом. Зато он убеждал всех и вся за пределами Рочестера, что это совершенно новая система, и ему верили.
Своим скорым коммерческим успехом AS/400, несомненно, обязана Тому. Он организовал массированный выход на рынок этого продукта IBM в масштабах, беспрецедентных со времен System/360. В итоге AS/400 выдвинулась на передние позиции среди коммерческих многопользовательских систем. После Рочестера Том перебрался в Санта-Терезу (Santa Teresa), штат Калифорния, где занял должность генерального менеджера разработки базы данных IBM DB/2. Позднее он стал генеральным менеджером IBM по клиент-серверным системам. Сегодня Том возглавляет проекты IBM, связанные с Олимпийскими Играми.
Часто по-настоящему оцениваешь человека, лишь вглядываясь в него из будущего. Том никогда не был силен по части техники, как некоторые из его предшественников, и многие в лаборатории не принимали его как лидера, под тем предлогом, что Том до конца не может проникнуть в суть того, что они делают. Он и не мог, ну и что? Например, Том никогда не понимал, что AS/400 — это переупакованная System/38; а если и понимал, то никому не говорил об этом. Зато он убеждал всех и вся за пределами Рочестера, что это совершенно новая система, и ему верили.
Своим скорым коммерческим успехом AS/400, несомненно, обязана Тому. Он организовал массированный выход на рынок этого продукта IBM в масштабах, беспрецедентных со времен System/360. В итоге AS/400 выдвинулась на передние позиции среди коммерческих многопользовательских систем. После Рочестера Том перебрался в Санта-Терезу (Santa Teresa), штат Калифорния, где занял должность генерального менеджера разработки базы данных IBM DB/2. Позднее он стал генеральным менеджером IBM по клиент-серверным системам. Сегодня Том возглавляет проекты IBM, связанные с Олимпийскими Играми.
Твердая рука
После перехода Тома на новую работу в Калифорнии, мы потеряли значительную часть рынка. Несмотря на то, что нам досталась награда Malcolm Baldrige National Quality Award за учет требований рынка, руководство лаборатории тянуло нас назад к работе, ориентированный на удачные технические, но не коммерческие решения. Совещания заказчиков прекратились, а вместе с ними и прямой вклад пользователей в проектирование, чего удалось добиться Тому. Наше новое руководство состояло из бывших разработчиков и чувствовало себя не в своей тарелке, когда пользователи вмешивались в принятие проектных решений. Единственным замечательным исключением на общем печальном фоне была наша программа Partners in Development (PID). Ей занималась группа энтузиастов, первоначально под руководством Джима Келли (Jim Kelly). Их усилия сосредоточилась на поддержке сообщества бизнес-партнеров AS/400 во всем мире, которые занимались разработкой и продажей большей части прикладного ПО, использовавшегося нашими заказчиками. Эти люди заслуживают самой большой похвалы за наш успех в данной области. Подразделение AS/400 не утратило ориентированности на рынок благодаря еще одному человеку — Биллу Цайтлеру (Bill Zeitler). Биллбыл помощником генерального менеджера по маркетингу примерно с момента выхода первой системы до конца 1995 года, когда он получил назначение в Азию на 15 месяцев. За эти годы до момента временного ухода Билла в нашем подразделении сменилось пять генеральных менед-жеров5. Каждый из этих руководителей внес определенный вклад в успех AS/400, но именно твердая рука Билла направляла наш корабль в бурных водах рынка. Например, в 1993 году, когда имидж AS/400 в прессе и среди экспертов заметно упал, и многие предсказывали конец системы, Билл приложил много усилий, чтобы переломить ситуацию. Не один раз я надевал свой пуленепробиваемый жилет и вместе с Биллом отправлялся в какую-нибудь особо недружественную консалтинговую фирму. После таких визитов злостные критики начинали понимать потенциал AS/ 400 и большинство из них превращались из наших врагов в сторонников. Так что без Билла и его команды AS/400 не смогла бы занять свое нынешнее положение на рынке. По счастью, по окончании командировки в Азию, Билл возвратился к нам в качестве генерального менеджера, чтобы запустить в разработку серию AS/400е.Зачем написана книга?
Никогда прежде IBM не освещала так глубоко и всесторонне историю проектирования и особенности архитектуры AS/400. Никогда не объяснялось, как этой замечательная система делает то, что она делает. Моя задача — снять с AS/400 завесу тайны, а также пролить некоторый свет на то, как система создавалась. Вы, возможно, уже поняли, что я чувствую себя обязанным включить в книгу кое-какую историческую информацию. Несколько лет назад я неформально унаследовал пост историка Рочестера от Карла Гебхардта (Carl Gebhardt), занимавшего его изначально. Карл был бизнес-менеджером (business manager) наших ранних систем, а позже, в бытность Гарри Ташияна директором лаборатории, работал системным менеджером и System/34, и System/38. Карл отвечал за финансовый успех ранних систем Рочестера. Я работал у него в начале 80-х, когда Карл был нашим директором по стратегии (director of strategy). Долгие годы Карл был историографом Рочестера. Он часто так и представлялся (официально такого поста не было, но мы оба считали, что он должен быть). Если возникал вопрос о чем-нибудь, что произошло несколько лет назад, Карл в большинстве случаев знал на него ответ. Когда Карл оставил работу, мы обсуждали, кто должен занять этот почетный пост, и он сдал вахту мне.
Эта книга написана для тех, кто хочет узнать больше об AS/400. Это не спецификация для проектировщиков операционной системы, которым нужно гораздо больше деталей, чем здесь приведено; и не переделка рекламных материалов IBM. Она написана для пользователей, разработчиков приложений и студентов, которые хотят понять, как работает AS/400, чтобы достичь успеха в бизнесе, писать лучшие приложения или просто удовлетворить здоровое любопытство. Волшебство это или просто удачный проект? Возможно и то, и другое.
Хочу подчеркнуть: я излагаю в книге свою точку зрения. Я откровенный фанатик AS/400. Мои взгляды не обязательно совпадают с официальными позициями корпорации IBM. Надеюсь, чтение книги доставит Вам такое же удовольствие, как мне — ее создание.
Вы, возможно, уже поняли, что я чувствую себя обязанным включить в книгу кое-какую историческую информацию. Несколько лет назад я неформально унаследовал пост историка Рочестера от Карла Гебхардта (Carl Gebhardt), занимавшего его изначально. Карл был бизнес-менеджером (business manager) наших ранних систем, а позже, в бытность Гарри Ташияна директором лаборатории, работал системным менеджером и System/34, и System/38. Карл отвечал за финансовый успех ранних систем Рочестера. Я работал у него в начале 80-х, когда Карл был нашим директором по стратегии (director of strategy). Долгие годы Карл был историографом Рочестера. Он часто так и представлялся (официально такого поста не было, но мы оба считали, что он должен быть). Если возникал вопрос о чем-нибудь, что произошло несколько лет назад, Карл в большинстве случаев знал на него ответ. Когда Карл оставил работу, мы обсуждали, кто должен занять этот почетный пост, и он сдал вахту мне.
Эта книга написана для тех, кто хочет узнать больше об AS/400. Это не спецификация для проектировщиков операционной системы, которым нужно гораздо больше деталей, чем здесь приведено; и не переделка рекламных материалов IBM. Она написана для пользователей, разработчиков приложений и студентов, которые хотят понять, как работает AS/400, чтобы достичь успеха в бизнесе, писать лучшие приложения или просто удовлетворить здоровое любопытство. Волшебство это или просто удачный проект? Возможно и то, и другое.
Хочу подчеркнуть: я излагаю в книге свою точку зрения. Я откровенный фанатик AS/400. Мои взгляды не обязательно совпадают с официальными позициями корпорации IBM. Надеюсь, чтение книги доставит Вам такое же удовольствие, как мне — ее создание.
Замечания ко второму изданию
Когда в 1994 году была объявлена Advanced Series, в Рочестере также выпустили первую версию новой операционной системы, которую назвали версией 3 V3R1 (Version 3 Release 1). Мы заявили, что собираемся изменить архитектуру процессоров на RISC, но системное ПО для обоих архитектур останется функционально эквивалентным, чтобы упростить переход под RISC. В 1995 году вместе с первыми RISC-моделями мы представили V3R6, которая должна была обеспечить функциональную совместимость с V3R1. В 1996 году появились расширенные версии обоих этих ПО: V3R2 и V3R7. Таким образом, Version 3 может рассматриваться как промежуточная операционная система на период перехода пользователей на новые RISC-модели. Выход серии AS/400е в 1997 году вместе с OS/400 версии 4 (V4) был вехой, означающей конец периода перехода на RISC. Выпуски этой новой версии (V4R1, V4R2, V4R3 и т. д.) будут работать только RISC-моделях AS/400. Конкретно, OS/400 V4 работает на некоторых моделях Advanced Series (RISC-моделях) и на всех моделях серии AS/400e. Если внешние интерфейсы RISC и не-RISC систем очень похожи, то этого нельзя сказать об их внутреннем устройстве. Некоторые внутренние компоненты одинаковы, другие же сильно отличаются. В этой книге, описывающей внутреннее устройство AS/400, невозможно полностью рассмотреть оба дизайна; для этого потребовалось бы две разные книги. Но вместо того, чтобы просто рассматривать только RISC-системы, я решил, там где это имеет смысл, также описать и некоторые подробности устройства не-RISC систем. Такое решение вызвано двумя причинами: Понимание работы некоторых компонентов не-RISC систем поможет понять, почему мы решили перейти на RISC. Например, основным фактором, заставившим нас отказаться от оригинальной не-RISC архитектуры, была структура адресации. В главе 8 я рассмотрю как старую, так и новую систему, и постараюсь обосновать, почему изменения были необходимы. Многие части не-RISC систем по-прежнему имеют значение: либо их компоненты будут перенесены в будущие проекты, либо переход на новый дизайн только начался. Примером последнего служит ввод-вывод, новая архитектура которого только начала создаваться (подробнее об этом — в главе 10). Во всех случаях, я пытался ясно указать, где обсуждаются решения для RISC, а где нет. Теперь о содержании книги: Глава 1 посвящена идеям, лежащим в основе расширенной архитектуры AS/400. Здесь также обсуждается интеграция и ее значение для заказчиков. В главе 2 рассматривается самый низкий уровень системы AS/400 — архитектура процессора. В этой главе обсуждаются только RISC-процессоры (в том числе и то, как они появились). В главе 3 дается описание внутреннего системного ПО AS/400, известного как System Licensed Internal Code (SLIC), и опять только RISC-систем. Тема главы 4 — машинный интерфейс MI. MI практически одинаков и для RISC- или для не-RISC-систем, но я включил в свой рассказ описание дополнительных команд для RISC-систем. Глава 5 посвящена объектам AS/400 и управлению ими. Все, что сказано здесь, применимо и к RISC-, и к не-RISC-системам. В главе 6 описывается интегрированная реляционная база данных AS/400 и внутренняя структура системы. Глава 7 посвящена защите от несанкционированного доступа, включая становящуюся все более важной защиту в сетях. В главе 8 рассматривается одноуровневая память AS/400. Основное внимание уделено реализации для RISC-систем, но я включил в текст достаточно информации о варианте для не-RISC, чтобы обосновать необходимость произведенных изменений. В главе 9 описана структура управления процессами AS/400. Большая часть сведений применима как к RISC-, так и к не-RISC-системам. Глава 10 посвящена системе ввода-вывода. Вначале рассматривается существующий ввод-вывод для не-RISC систем, затем — изменения в структуре ввода-вывода, реализованные в серии AS/400е. Глава 11 переходит от рассмотрения отдельных компонентов системы к расширениям версии 4, а также тем, которые могут появиться в ближайшем будущем. Значительная часть обсуждения версии 4 посвящена электронному бизнесу, так как он имеет наибольшее влияние на будущий дизайн AS/400. Наконец, в главе 12 мы попробуем предугадать, что ожидает AS/400 в следующем столетии. В дополнение к обсуждению каждого компонента и его взаимодействия с другими я объясняю, как эти компоненты были созданы, и чем они улучшают среду приложений. В конце концов, AS/400 предназначена именно для приложений и освоения с помощью новейших из них мира электронного бизнеса. OS/400 версии 4 и аппаратура серии AS/400e — наш взгляд на то, как лучше использовать возможности интеграции AS/400 в электронном бизнесе. Под электронным бизнесом мы понимаем безопасный, гибкий и интегрированный подход, принятие решений с помощью комбинации систем и процессов, исполняющих базовые деловые функции. Простоту и доступность такого нового подхода к делу обеспечивают технологии Интернета и World Wide Web (WWW). По началу использование серверов WWW в бизнесе обычно принимает форму помещения на Web-страницах собственной информации и обеспечения доступа сотрудников к информации других пользователей, использования электронной почты. В качестве такого сервера может использоваться практически любая вычислительная система. Однако когда компании по-настоящему переходят на электронную форму ведения бизнеса, когда они начинают использовать WWW для важнейших деловых операций, требования к надежности и целостности системы многократно возрастают. Многие годы AS/400 — производительная, работоспособная, надежно защищенная система для традиционных и клиент-серверных приложений. Теперь мы даем своим заказчикам возможность применить эти ее замечательные свойства в мире электронного бизнеса.Как читать эту книгу
Допускаю, что сам факт подобных рекомендаций может показаться читателю странным, но на то есть веские причины. Предполагаемая аудитория достаточно широка: от деловых людей, желающих понять, чем система или сервер AS/400е могут быть выгодны их бизнесу, до «спецов», которые хотят разобраться в мельчайших деталях. Я долго ломал голову, как «потрафить» и тем, и другим, намеревался даже разбить книгу на две части: обзор для обычных читателей и технические детали для «профи». Но как быть с теми, кому интересно все? Думал я и о том, чтобы снабдить книгу указателем, по которому и менеджер, и разработчик приложений, и студент, и любитель подробностей могли бы найти разделы, предназначенные специально для них. Но такая классификация слишком условна; всякий раз, когда я читаю какую-нибудь книгу в соответствии с подобным «путеводителем», мне самому трудно ориентироваться, какие разделы читать, а какие — пропустить. Не знаю, чем закончились бы мои мучения, если бы не Малколм Хейнес (Malcolm Haines) из Лондона — одна из самых светлых голов в IBM. Малколма часто называют «министром пропаганды:» IBM UK, в его обязанности входит реклама IBM через видео-и коммерческие спутниковые телесети. Его компакт-диск «The Case Against the AS/ 400» — гениальный образчик британского юмора. Именно Малколм посоветовал пометить наиболее трудные разделы — а там уж пусть читатель сам решит, читать их или нет. Еще он предложил использовать для обозначения степени сложности раздела перчик чили. Почему, это особая история. В прошлом году Малколм повел меня в англо-индийский ресторан Chutney Mary в Лондоне. Так вот, в меню этого уютного заведения картинки красного перчика чили обозначали остроту блюд — чем больше перчиков, тем острее. И Малколма осенило: почему бы не обозначить так же «остроту» технических разделов книги?! Вот как выглядит в результате мой «гастрономический» рейтинг: Отсутствие перчиков означает, что, с точки зрения технических подробностей, раздел довольно «пресный». Кое-что, конечно, есть, но любому читателю стоит добавить чуточку специй.
Отсутствие перчиков означает, что, с точки зрения технических подробностей, раздел довольно «пресный». Кое-что, конечно, есть, но любому читателю стоит добавить чуточку специй.
 Один перчик — «техники» побольше. Это уровень, так сказать, массового читателя. Попробуйте, — а вдруг Вам придется по вкусу?
Два перца означают, что здесь определенно рассматриваются технические проблемы. И если для Вас это слишком, листайте до менее «острого» раздела.
Один перчик — «техники» побольше. Это уровень, так сказать, массового читателя. Попробуйте, — а вдруг Вам придется по вкусу?
Два перца означают, что здесь определенно рассматриваются технические проблемы. И если для Вас это слишком, листайте до менее «острого» раздела.
 Три чили — ау, любители острых блюд и ощущений! «Спецы» хищно улыбаются, утирая со лба пот. Не исключено, что при слишком внимательном чтении кто-нибудь почувствует запах жареного. Что тут посоветовать? На всякий случай держите под рукой стакан с водой или совсем пропустите подобный раздел.
Приятного аппетита!
Три чили — ау, любители острых блюд и ощущений! «Спецы» хищно улыбаются, утирая со лба пот. Не исключено, что при слишком внимательном чтении кто-нибудь почувствует запах жареного. Что тут посоветовать? На всякий случай держите под рукой стакан с водой или совсем пропустите подобный раздел.
Приятного аппетита!
Глава 1
Расширенная архитектура приложений
Выносливость любой компьютерной системы и ее способность сохранять инвестиции, — самые важные аргументы при выборе компьютера для производства или офиса. Ураган новых технологий, таких как Интернет, захлестнул деловой мир, заставил многих предпринимателей в корне изменить методы своей работы. Сегодня одна новейшая технология меняет другую с поразительной быстротой, постоянны только изменения. Насущным стало не только с выгодой использовать эти изменения для укрепления бизнеса, но и защититься от потерь, вызванных ими. Общеизвестно, что у AS/400 прогрессивная, самая адаптируемая архитектура в мире, и что новые технологии не повлияют негативно на бизнес заказчиков этой системы. Да, это правда. Пользователям AS/400 не требуется «подгонять» свои прикладные программы под новые технологии. Однако, зачастую сами клиенты не понимают (или не хотят понимать) как работает система. Работает — и ладно! Недавно архитектура AS/400 снова оказалась в центре внимания. AS/400 стала первой и единственной в мире системой, завершившей переход к 64-разрядным вычислениям. В новой модели был использован тип архитектуры процессора с сокращенным набором команд — RISC (reduced instruction set computer). Для сравнения: процессоры, использовавшиеся в исходной AS/400, а также другие популярные процессоры, такие как Intel Pentium или Intel Pentium Pro, используют архитектуру со сложным набором команд — CISC (complex instruction set computer). Главное достоинство RISC-архитектуры — более простые команды, чем у CISC. Это позволяет создавать процессоры, отличающиеся поразительной быстротой вычислений и за приемлемую цену. Последние версии RISC-процессоров всех производителей — 64-разрядные. Проектирование и создание такой аппаратуры — не самая сложная проблема компьютерной индустрии. А вот как предоставить существующему программному обеспечению (ПО) возможность воспользоваться преимуществами новой аппаратуры? AS/400 — единственная система, где эта проблема решена. Все ее приложения используют 64-разрядные вычисления в полной мере. Никакая другая система такими возможностями не обладает. Когда другие производители компьютеров переходили с CISC- на RISC-процессоры, это вызывало серьезные проблемы у их заказчиков и независимых производителей програмно-го обеспечения ISV (Independent Software Vendor), которым приходилось переписывать некоторые прикладные программы или их фрагменты. Так случилось, например, когда фирма Hewlett Packard объявила о своей архитектуре PA (Precision Architecture), или когда Digital Equipment Corporation (Digital) представила архитектуру Alpha. Чтобы лучше понять масштаб проблемы, остановимся подробнее на попытке перехода на RISC, предпринятой фирмой Digital. По собственной оценке Digital перевод имеющегося парка на архитектуру Alpha вызовет необходимость переписать от 15 до 20 процентов старого кода приложений, предназначенных для архитектуры VAX. Любому заказчику или ISV такая модификация влетит в копеечку. Архитектура AS/400, напротив, защищает пользователей системы и ISV от этих проблем при переходе на новые 64-разрядные RISC-процессоры. Существующие приложения сразу же в полной мере используют новые возможности аппаратуры. Чтобы понять, как это стало возможным, рассмотрим, чем расширенная архитектура приложений AS/400 отличается от всех других.Архитектура компьютера
Витрувий, римский архитектор I столетия нашей эры, определял архитектуру как акт проектирования структуры, обладающей полезностью, прочностью и способностью восхищать. Это и многое другое — общие характеристики как для архитектуры зданий, так и для архитектуры компьютеров. Современная архитектура многим обязана классической. Корни даже самых футуристических проектов — в прошлом. Египетские пирамиды, греческие колонны, римские арки, романские купола и острые готические своды — все это лежит в основе самых новомодных конструкций. Античная эра истории компьютеров протекала лишь несколько десятилетий назад. Но, как и в проектировании зданий, в самых динамичных и восхитительных примерах современной архитектуры компьютеров четко прослеживается влияние классики. Модель, лежащая в основе архитектуры AS/400, была разработана более четверти века назад. Благодаря гибкому подходу к проектированию, применявшемуся с самого начала, AS/400 способна быстро адаптироваться к современным условиям и потребностям. Ее архитектура не зависит от технологий, и AS/400 уже многие годы обладает средствами и возможностями, до сих пор недоступными для других вычислительных систем.С точки зрения программиста
В 1970 году С. С. Хассон (S. S. Husson) определил термин «архитектура компьютера» как «характеристики (вычислительной) системы с точки зрения программиста»[ 5 ]. Архитектура включает в себя набор команд, типы данных, операции ввода-вывода и другие характеристики. Иногда эти компоненты рассматриваются по отдельности, и тогда говорят об архитектуре наборов команд и архитектуре ввода-вывода. Архитектура в целом включает в себя все, что нужно знать программисту для создания корректно работающих программ. С точки зрения аппаратуры у компьютера имеется пять основных компонентов: ввод, вывод, память, тракт данных (datapath) и устройство управления. Два последних компонента часто объединяют и называют процессором. Архитектура компьютера определяет, какие операции могут выполнять эти компоненты. Процессор выбирает данные и команды из памяти. Аппаратура ввода записывает данные в память, а аппаратура вывода — считывает из нее. Управляющая аппаратура генерирует сигналы, управляющие трактом данных, памятью, вводом и выводом. Иногда процессор называют ЦПУ — центральным процессорным устройством CPU (central processing unit). В последнее время этот термин используется реже, так как современные технологии позволяют упаковать целый процессор в одну микросхему. Процессор, выполненный на одной микросхеме, обычно называют микропроцессором. Достаточно часто термины «ЦПУ», «процессор» и «микропроцессор» используют как эквивалентные. Однако, следует помнить, что не всякий процессор умещается на одной микросхеме — их может потребоваться несколько. Если два компьютера могут выполнять один и тот же набор команд, то говорят, что у них одинаковая архитектура набора команд. Одна и та же архитектура может быть реализована по-разному. Так, например, архитектура Intel x86[ 6 ], применяемая во многих ПК, используется целым семейством микропроцессоров, созданных с помощью разных технологий и имеющих разную производительность. То есть конкретная технология, использованная при создании компьютера, не есть часть его архитектуры.Уровни абстракции
Аппаратные и программные структуры большинства современных компьютеров — многоуровневые. Детали нижних уровней скрываются, чтобы обеспечить более простые модели для верхнего уровня. Данный принцип абстракции — способ, благодаря которому проектировщики аппаратных и программных средств справляются со сложностью вычислительных систем. На самом нижнем уровне — электронных схем — компьютер очень прост. Электронная схема понимает только две команды: включено и выключено, символически обозначаемые при помощи цифр 1 и 0. На данном уровне общение с машиной идет с помощью цепочек нулей и единиц. Команда — это понятный процессору набор двоичных цифр или битов (разрядов). Таким образом, команда представляет собой просто число в двоичной системе счисления или двоичное число. Компьютеры называются цифровыми, потому что на машинном языке для обозначения как команд, так и данных используются цифры. Когда-то давно, программисты «общались» с компьютерами на языке двоичных чисел. Это не слишком удобно, поэтому был изобретен более высокий уровень абстракции — язык ассемблера, представляющий собой символическую форму двоичного языка компьютера. Ассемблером называется программа, транслирующая символическое представление команд в двоичную форму. Для большинства программистов язык ассемблера — также не вполне естественный, поэтому был создан еще более высокий уровень абстракции — язык программирования высокого уровня (ЯВУ). В настоящее время насчитываются сотни таких языков; наиболее известные из них — Basic, C, C++, Cobol и RPG. Программа, принимающая на входе текст на одном из языков высокого уровня и транслирующая его в операторы языка ассемблера, называется компилятором. Иллюстрация многоуровневой абстракции — написание программы на языке высокого уровня. Компилятор выполняет преобразование программы на ЯВУ в язык ассемблера, который затем переводит свои команды в двоичный код, понятный процессору. Замечу, что некоторые компиляторы генерируют команды непосредственно на машинном языке, минуя уровень ассемблера. Перед выполнением программы на ЯВУ компилятор и ассемблер транслируют ее в команды машинного языка. Эта операция выполняется однократно, и при новом запуске программы повторять ее не надо, если только исходный текст программы не изменился. Наличие нескольких уровней позволяет скрыть детали нижележащего машинного языка от программиста и обеспечить более простой и производительный интерфейс. Многоуровневая концепция может также использоваться и в аппаратуре компьютера. Многие процессоры, в том числе из семейства Intel, используют микропрограммирование. В микропрограммируемой машине применяется набор команд еще более низкого уровня. Для отображения между верхним и нижним уровнями микропрограммирование использует эмуляцию. При этом машинные команды выбираются и исполняются по одной, как последовательность команд более низкого уровня. Для преобразования машинных команд в форму, приемлемую для микропрограммы, не требуется отдельный этап компиляции. Похожа на эмуляцию интерпретация программ. Программа-интерпретатор выбирает инструкции по одной и исполняет эквивалентную им последовательность команд более низкого уровня. Некоторые из новейших ЯВУ, используемых в распределенных вычислениях, например Java, разработаны так, чтобы их было легко интерпретировать. Большинство командных языков также интерпретируемы. Введите «dir» в командной строке DOS на любом ПК и на экране появится содержимое каталога. Если после этого нажать клавишу Enter, интерпретатор командной строки DOS считает введенную команду, а затем выполнит последовательность инструкций, необходимых для ее выполнения. Такой интерпретатор команд есть в большинстве операционных систем. В микропрограммируемой машине интерпретация обычно поддерживается специальным оборудованием. Микропрограмма для различения такой аппаратной формы интерпретации называется эмулятором. Обычно архитектура набора команд вычислительной системы рассматривается как интерфейс между аппаратурой и программным обеспечением самого нижнего уровня. В те времена, когда Хассон сформулировал упоминавшееся выше определение архитектуры компьютера, программирование еще не использовало ЯВУ. Сегодня, более подходящим определением этого понятия было бы «характеристики системы с точки зрения компилятора», так как из нынешних программистов лишь немногие имеют дело с программами в машинных кодах. С учетом многих уровней абстракции, более точно было бы говорить, что компьютер имеет несколько архитектур, хотя архитектура двоичного набора команд в большинстве случаев по-прежнему играет основную роль. Когда говорят, что один компьютер способен выполнять программы, написанные для другого компьютера без изменений, то обычно имеют в виду, что первый может выполнять двоичные коды (binaries) другого, и следовательно, для переноса программ с первого на второй их повторная компиляция не требуется. Иначе говоря, двоичный машинный язык одного компьютера непосредственно поддерживается другим компьютером.Создание программ
Программное обеспечение любой вычислительной системы можно условно разделить на два типа: системное и прикладное. Примеры системного программного обеспечения — операционные системы, ассемблеры и компиляторы. Прикладное же программное обеспечение обычно предназначается непосредственно для пользователей и решает конкретные задачи. Ранее считалось, что доступ к архитектуре самого нижнего уровня посредством ассемблера необходим как системному, так и прикладному программисту. В пользу этого суждения приводилось множество аргументов: большинство программ имели доступ к крайне незначительному объему памяти, процессоры были медленными и дорогими, а компиляторы с языков высокого уровня — не слишком хорошими. Когда нужно было «выжать последний грамм» для повышения производительности компьютера, «настоящие» программисты использовали язык ассемблера. Теперь же появилось много приверженцев мнения, что программирование на языке ассемблера — реликт прошлого. Но это не так. Большинство используемых ныне операционных систем (не только старых, чьи корни которых восходят к 60-м и началу 70-х годов, но и более современных) включают в себя большие объемы кода на ассемблере. Таковы, например, операционные системы для ПК: Windows 95 фирмы Microsoft написана по большей части на языке ассемблера Intel. Первые процессоры для ПК имели достаточно ограниченные возможности. Максимальный размер памяти был равен 64 килобайтам. (Один килобайт равен 210 или 1024 байтам. Байт — это 8-разрядная ячейка памяти, в которой может храниться символ или цифра). Память стоила настолько дорого, что операционные системы могли занимать не более 4 килобайт. Язык ассемблера позволял программистам максимально сокращать размер кода. В результате на нем написан такой большой объем операционных систем, что даже когда размер доступной памяти увеличился благодаря удешевлению технологии, возвращаться назад и переписывать оригинальный код оказалось непрактичным. Использование ассемблера действительно позволяет оптимизировать размеры и производительность программ. Тем не менее, у этой технологии, по крайней мере, один существенный недостаток: все программы напрямую привязаны к аппаратуре. Любое ее изменение может вызвать необходимость переписать некоторые или даже все программы. В качестве примера такой ситуации рассмотрим компьютер, имеющий восемь регистров. Регистр — часть тракта данных процессора. Это быстродействующая область памяти, куда помещаются данные и адреса на время их использования процессором. Основное назначение регистров — повышение производительности работы программ. Предположим, что ширина каждого регистра — 16 разрядов, и что программист может помещать данные в регистры и выбирать их оттуда в любой момент по своему усмотрению. Число регистров и их характеристики программист видит из ассемблера. Таким образом, каждая программа для данного компьютера, написанная на этом языке, будет «знать» о восьми регистрах и зависеть от них. Теперь предположим, что технологический прогресс позволил конструкторам увеличить количество регистров до 16 и сделать их 32-разрядными, причем стоит все это столько же, сколько и оригинальные 8 регистров меньшего размера. Зададимся вопросом: «Как это повлияет на программы, написанные для старого компьютера?». Ответ зависит от того, каким образом были сделаны изменения, и сколь хорошо первоначальная архитектура была спланирована для расширения в будущем. Допустим, что в старой архитектуре предполагалось расширение до 16 регистров. В каждой команде было зарезервировано достаточно места для адресации 16 регистров, хотя первоначально были реализованы только 8. Для каждой команды, использующей регистры, в данном случае понадобились бы 4-разрядные поля, так как 4 бита позволяют закодировать 16 различных комбинаций нулей и единиц. На новом оборудовании старые программы могут выполняться без изменений. При этом они по-прежнему будут использовать только 8 регистров, новые же программы смогут воспользоваться всеми 16-ю. А теперь представим себе вместо этого, что в старой архитектуре не были учтены будущие изменения и место для расширения не зарезервировано. Тогда новая архитектура не сможет увеличить количество регистров, не изменив при этом каждую команду, которая их использует. Невозможно растянуть трехбитовые поля в командах до 4 бит, не затронув при этом в той или иной степени существующие программы. Одна из многих архитектур, неспособных увеличить число пользовательских регистров, — Intel Pentium Pro. Она использует то же количество регистров, что и ее предшественник Intel 386. Хотя увеличение числа регистров дало бы Pentium Pro преимущества, но затраты на переписывание существующих ассемблерных программ слишком велики. Вообще, увеличение размера регистров с 16 до 32 разрядов оказывает меньшее влияние, чем изменение их количества. Если увеличился только размер, то старые программы будут по-прежнему работать, но использовать лишь 16 из 32 разрядов новых регистров. Данная информация внедрена в логику программы, и ее трудно изменить[ 7 ]. И подобных примеров, когда широко применяемые программы не способны использовать все ресурсы оборудования, — несметное множество. Процессор Intel 386, появившийся еще в 1985 году, имел 32-разрядный дизайн, то есть размер его аппаратных регистров был равен 32 битам. С того времени все процессоры Intel, включая 486, Pentium, Pentium II и Pentium Pro — 32-разрядные. Однако и большинство программ для ПК, использующих эти процессоры, и операционная система DOS были созданы в те времена, когда был доступен только 16-разрядный процессор Intel 286. Даже операционная система Windows 95 написана в основном на 16-разрядном ассемблере. На переписывание прикладных и системных программ ПК под 32-разрядную аппаратуру ушло уже 12 лет, и процесс все еще не завершен. Эта проблема не ограничивается только индустрией ПК. Прогресс аппаратных технологий поднял планку еще выше: большинство новых процессоров будут 64-разрядными. Чтобы воспользоваться этим более мощным оборудованием, большинство современных 32-разрядных операционных систем и 32-разрядных прикладных программ должны быть переписаны. А это опять долгие годы работы. В рассмотренных выше примерах модификации аппаратуры состояли в изменении размера и числа регистров процессора. Учтите, что аналогичное влияние на программное обеспечение, написанное на ассемблере, могут оказать и изменения в структуре адресации процессора или в самом наборе команд. Основная цель программирования только на языках высокого уровня — минимизировать изменения в программах, вызываемые подобными модификациями аппаратуры. К сожалению, в системном программном обеспечении явно наблюдается тенденция перехода на языки, подобные С и С++. Использование С позволяет повысить переносимость системного программного обеспечения, так как компиляторы для этого языка есть на многих аппаратных платформах, но не устраняет все сложности, связанные с изменениями в оборудовании. Некоторые аппаратные характеристики, например разрядность процессора, видимы программисту на С. Такая возможность доступа к внутренним характеристикам привлекательна для системных программистов и объясняет популярность С. Это язык называют «современным ассемблером». В обычной вычислительной системе переход, например, с 32-разрядного процессора на 64-разрядный по-прежнему будет требовать изменений в программе на С. А это снижает переносимость С-программ. Для иллюстрации рассмотрим опыт Digital. Последние несколько лет эта фирма продает свои машины с 64-разрядным процессором Alpha. Однако две основные операционные системы, используемые на этих компьютерах — Open VMS самой Digital и Windows NT фирмы Microsoft — все еще 32-разрядные, хотя и написаны, в основном, на С. Приложения для этих операционных систем, также 32-разрядные. Простая перекомпиляция здесь не поможет. Чтобы задействовать все ресурсы процессора, и операционные системы, и приложения надо полностью переписать, и это займет много лет. HP также загнала покупателей своей HP 9000 в трясину переделок. Сейчас HP продает 64-разрядные версии своих процессоров PA-RISC. Чтобы воспользоваться преимуществами новых аппаратных средств, заказчикам HP придется ждать появления новой 64-разрядной ОС, и затем переписывать свои приложения. На это потребуется столько времени, что уже теперь, задолго до того, как переделка ПО будет завершена (см. главу 12), есть признаки того, что HP может отказаться от дальнейшей разработки HP 9000. Секрет успешного перехода к 64-разрядным вычислениям на AS/400, в то время как никому больше это не удалось, кроется в ее архитектуре.Классификация архитектур
Принципов классификации компьютерных архитектур немало. Вероятно, самый старый из них — по формату команд процессора. Другой, уже знакомый, — разделение процессоров на категории CISC и RISC. Оба эти подхода учитывают только аппаратный интерфейс процессора. С точки же зрения заказчика прикладные программы гораздо важнее. Следовательно, не менее законно будет классифицировать компьютерные архитектуры по способу взаимодействия прикладных программ с аппаратным интерфейсом.Процессоро-ориентированная архитектура
Подавляющее большинство используемых ныне компьютерных архитектур основаны на традиционном подходе, открывающем программисту аппаратный интерфейс. Такие архитектуры называются процессоро-ориентированными (processor-centric) потому, что аппаратный интерфейс в них видим прикладным программам и используется последними непосредственно. Примеры процессоро-ориентированных архитектур — PA фирмы HP и Alpha фирмы Digital.API-ориентированные архитектуры
Учитывая недостатки процессоро-ориентированных архитектур, многие ISV, производители оборудования и организации по стандартизации совместно разрабатывали архитектуры, в основе которых лежит интерфейс прикладных программ API[ 8 ] (application programming interface). Такие API-ориентированные архитектурыустанавливают коммуникационный барьер — интерфейс, который используется всем прикладными программами для доступа к сервисам операционной системы и изолирует их от аппаратных и программных деталей. Операционная система — это набор программ, управляющих системными ресурсами и служащих фундаментом для написания прикладных программ. Часто таким фундаментом становятся API. Существуют различные формы реализации API. Это может быть вызов или команда, запрашивающая у операционной системы согласие на выполнение некоторых действий. Хорошо известный пример API — функция операционной системы, вызываемая прикладной программой для выполнения операции ввода-вывода, такой как чтение с диска. Очевидно, что прикладной программе незачем «знать» подробности внутренней работы ввода-вывода. Программы операционной системы, выполняющие функции ввода-вывода и часто называемые подсистемами ввода-вывода, изолируют приложения от деталей аппаратной и программной реализации. Приложения, использующие для выполнения ввода-вывода только соответствующие API, не зависят от каких-либо изменений в структуре ввода-вывода на нижних уровнях. Дополнительное преимущество дает реализация разными производителями одного и того же набора API. В этом случае приложения легко переносить с одной системы на другую. Один из наиболее известных стандартных наборов API — POSIX. POSIX — сокращение, неформально расшифровываемое как «переносимый интерфейс операционной системы базирующейся на Unix» (portable operating system interface based on Unix) — это набор международных стандартов для интерфейсов Unix-подоб-ных операционных систем. Правительственные и неправительственные организации поощряют реализацию производителями Unix-подобных операционных систем данных стандартов, как обеспечивающую переносимость приложений с одной системы на другую. Общая проблема стандартов типа POSIX состоит в том, что они никогда не становятся законченными, и стадия определения такого стандарта занимает многие годы. В такой ситуации разработчики приложений часто берут дело в свои руки. В 1993 году группа разработчиков приложений для Unix и производителей Unix-подобных операционных систем решила определить свой собственный набор API. Они не могли ждать, пока спецификация POSIX «созреет» до такой степени, чтобы ее можно было использовать. Кроме того, ясно, что когда спецификация POSIX будет, наконец, полностью завершена, все приложения придется переписывать под новый стандарт. Вместо этого, упомянутая группа разработчиков выделила все API, которые используются в настоящее время наиболее популярными приложениями для Unix. Из тысяч существующих Unix-приложений они взяли 50 самых распространенных и выбрали 1179 функций API в качестве основы нового стандарта, который первоначально был назван SPEC1170. Позднее это название было заменено на «Единая Спецификация UNIX» (Single UNIX Specification), и данный стандарт становится теперь новой промышленной спецификацией Unix. Помимо указанных API в него входит часть интерфейсов POSIX. В состав спецификации продолжают включаться новые API. Очевидная проблема во всей этой работе по определению API была лаконично сформулирована одним из сотрудников института NIST (National Institute of Standards and Technology Национального института стандартов и технологий США): «Самое милое в стандартах — это большой их выбор». В самом деле, множество противоречащих друг другу и быстро изменяющихся стандартов делает невозможным создание приложения, которое было бы переносимо на все платформы. Далее, в главе 11, мы рассмотрим язык программирования Java и предоставляемые им возможности по созданию переносимых приложений. Более того, эти стандарты не являются полными, то есть во многих случаях приложениям приходится действовать «в обход» API. В результате приложение становится зависимым от аппаратуры и программного обеспечения нижних уровней: в тот момент, когда приложение обходит API, все проблемы, присущие процессоро-ори-ентированным архитектурам, возникают снова.Машинная архитектура высокого уровня
Истинная независимость от аппаратуры может быть достигнута, если вместо определения отдельных API для разных специфических приложений (что имеет место в случае такой API-ориентированной архитектуры как Single Unix Specification), будет формально определен общий интерфейс для всех приложений. Более того, если в такой интерфейс заложены возможности расширения, то в любое время для достижения переносимости приложений к нему могут быть добавлены API Single UNIX Specification. Именно такой подход лежит в основе архитектуры AS/400, которая определяет законченный набор API для всех приложений и не позволяет последним обходить API. Независимый от технологии машинный интерфейс (Technology-Independent Machine Interface), который часто называют просто MI[ 9 ], представляет собой формальное определение интерфейса для всех приложений и большинства компонентов операционной системы. Аппаратура, а также все программное обеспечение операционной системы, которому должны быть доступны подробности аппаратной реализации, располагаются ниже границы MI. Чтобы понять, как достигается независимость программного обеспечения от изменений в аппаратуре, обусловленных технологическим прогрессом, необходимо кратко рассмотреть, как работает компилятор. Ранее было сказано, что в традиционной процессоро-ориентированной системе компилятор генерирует двоичный машинный код непосредственно из исходного текста, что иногда требует дополнительного шага ассемблирования. В AS/400 компилятор генерирует из исходного текста код MI, который оформляется в виде так называемого шаблона программы. На втором этапе транслятор AS/400 генерирует двоичный код по содержимому шаблона программы. Фактически, этот транслятор выполняет те же действия, что и заключительный проход современного компилятора. Затем, если явно не запрошено его удаление, шаблон программы сохраняется вместе с двоичным кодом в программном объекте. Такая программа называется отслеживаемой (observable). При переносе программного объекта на новую аппаратную базу, например, на 64-разрядный PowerPC, другой транслятор, созданный для новой аппаратуры, перетранслирует шаблон программы в новый двоичный код. Изменений в исходном коде при этом не требуется — чем и достигается независимость от технологии. Более подробное рассмотрение этого вопроса мы отложим до главы 4. Значимость такой независимости очевидна для пользователей и ISV. Переход на 64-разрядную технологию RISC дает не только более мощный процессор — операционная система и все приложения сразу же становятся 64-разрядными. Для того чтобы воспользоваться преимуществами 64-разрядного оборудования не нужно ничего переписывать. В один день RISC-системы AS/400 получают 64-разрядную операционную систему и десятки тысяч 64-разрядных приложений. Архитектура AS/400 заслужила титул «расширенной архитектуры приложений» (Advanced Application Architecture), так как предоставляет возможности, которых многие другие вычислительные системы все еще пытаются достичь с помощью API-ориентированного подхода. AS/400 уже сейчас независима от нижележащей технологии. Хотя независимость от аппаратуры важна, но не менее важна и независимость от деталей операционной системы. В AS/400 достигнуто и это. Термин «расширенная архитектура» подразумевает, что к ней могут быть добавлены вновь определяемые API других операционных систем, что обеспечивает еще большую переносимость приложений.И это тоже есть!
 «Это там есть; все там есть!», — восклицает телевизионная реклама известного соуса для спагетти. Вместо того, чтобы покупать ингредиенты и делать соус самому — убеждает голос за кадром — лучше просто купить бутылку этого соуса и быть уверенным, что все качественные и свежие составляющие, которые Вы использовали бы, уже там. Гленн Ван Беншотен (Glenn Van Benschoten), системный менеджер AS/400, любит использовать аналогию с соусом для спагетти для описания интегрированной сущности AS/400. Все, что Вы можете пожелать для своего компьютера, уже там есть.
AS/400 — это интегрированная система, и эта характеристика отличает ее от большинства других. Для вычислительной системы интеграция означает, что различные части работают вместе как одно целое. Для заказчика это означает, что систему легче устанавливать, сопровождать и использовать, что снижает накладные расходы в бизнесе.
Если бы Вы спросили разработчика из подразделения в Рочестере, в чем причина успеха AS/400, то вероятно получили бы ответ, что здесь знают, как создавать наилучшие коммерческие многопользовательские системы. Если «нажать» посильнее, Ваш собеседник, вероятно, начнет сравнивать конкретные возможности, такие как база данных или структура защиты, с возможностями других систем. На мой взгляд, главное не в этом. Да, у AS/400 мощная база данных и надежная система защиты, но этим обладают и другие системы. Отличительная черта AS/400, которую многие наши разработчики считают само собой разумеющейся, — то, что все компоненты спроектированы,чтобы работать вместе. Система AS/400 — это больше, чем просто сумма составных частей.
Если задать тот же вопрос ISV, то он, вероятно, скажет, что для AS/400 проще, чем для какой-либо другой платформы, разрабатывать и сопровождать приложения. ISV, имеющие свои приложения как для AS/400, так и для других платформ, например Unix, часто указывают на разницу в численности людей, работающих для одной или другой платформы. Обычно, для разработки приложений для AS/400 требуется гораздо меньше людей, и это также — заслуга интеграции. Гарантируя, что новая добавленная функция будет гладко работать со всеми остальными частями системы, мы сокращаем расходы на разработку для AS/400. Все системы, созданные в Рочес-тере до AS/400 включительно, решены интегрировано, и именно в этом секрет их успеха.
Но если даже наши собственные разработчики порой забывают об этом факторе, то благодаря чему AS/400 остается интегрированной системой? Ответ — MI. MI делает для обеспечения интеграции две вещи. Во-первых, он предоставляет общий интерфейс для всех приложений и функций операционной системы, реализованных поверх него, благодаря чему всем приходится использовать систему одинаковым образом. Во-вторых, MI — функционально законченный интерфейс. Так как обойти его невозможно, MI предоставляет все функции, которые могут потребоваться прикладной или системной программе. Если какая-либо нужная функция отсутствует, то программа не будет работать на AS/400. MI также обладает большими возможностями расширения, что позволяет включать в него новые функции по мере надобности.
Прежде чем кто-нибудь укажет на то, что другие системы Рочестера, такие как System/36, добивались интеграции без машинного интерфейса высокого уровня, я должен отметить, что MI обеспечивает и интеграцию, и аппаратную независимость. У System/36 был эквивалент машинного интерфейса для большинства системных функций, но не для приложений. В этой системе два отдельных процессора выполняли: один — пользовательские приложения, а другой — некоторые функции операционной системы. Доступ к этим функциям на втором процессоре был возможен только посредством строго определенного интерфейса между двумя процессорам. Данный интерфейс, подобно MI, гарантировал полноту набора функций и возможность их совместной работы. Приложения, однако, по-прежнему зависели от аппаратуры. По этой причине (как мы увидим в главе 3) для выполнения приложений System/36 на другой аппаратуре требовался эмулятор.
Отрицательная сторона интеграции — отсутствие гибкости. В интегрированных решениях обычно имеет место подход «все или ничего». Клиент не может выбрать
ОС одного производителя, базу данных — другого и пакет защиты — третьего, так как все они не предназначены для работы в интегрированной системе.
Трудно поверить в то, что в любой компьютерной системе есть компоненты, не предназначенные для тесной совместной работы, но часто именно так и обстоит дело. Такие компоненты как базы данных, подсистемы защиты и коммуникаций обычно разрабатываются независимо друг от друга и могут предназначаться для работы с разными ОС. В результате, такие компоненты обычно самодостаточны, то есть стремятся использовать минимальный набор возможностей, встроенных в ОС. Подобное разделение ведет к дублированию функций между ОС и отдельными компонентами. Оно также может привести к разным интерфейсам пользователя и системного оператора.
Преимущество набора из отдельных компонентов состоит в гибкости. Недостаток — в том, что заказчик должен самостоятельно интегрировать такие компоненты в своей вычислительной системе, а это связано с расходами, и не только на собственно интеграцию. Средства тратятся на обучение пользователей и операторов работе с разными интерфейсами, а также на сопровождение. Модернизации одного компонента могут оказать негативное влияние на другой. Все еще более усложняется при использовании компьютеров в сети, которая сама по себе требует сопровождения. В попытке устранить множество несовместимостей между компонентами некоторые предприятия решают закупать все ПО у одного производителя. Но и это обычно не решает проблему.
«Это там есть; все там есть!», — восклицает телевизионная реклама известного соуса для спагетти. Вместо того, чтобы покупать ингредиенты и делать соус самому — убеждает голос за кадром — лучше просто купить бутылку этого соуса и быть уверенным, что все качественные и свежие составляющие, которые Вы использовали бы, уже там. Гленн Ван Беншотен (Glenn Van Benschoten), системный менеджер AS/400, любит использовать аналогию с соусом для спагетти для описания интегрированной сущности AS/400. Все, что Вы можете пожелать для своего компьютера, уже там есть.
AS/400 — это интегрированная система, и эта характеристика отличает ее от большинства других. Для вычислительной системы интеграция означает, что различные части работают вместе как одно целое. Для заказчика это означает, что систему легче устанавливать, сопровождать и использовать, что снижает накладные расходы в бизнесе.
Если бы Вы спросили разработчика из подразделения в Рочестере, в чем причина успеха AS/400, то вероятно получили бы ответ, что здесь знают, как создавать наилучшие коммерческие многопользовательские системы. Если «нажать» посильнее, Ваш собеседник, вероятно, начнет сравнивать конкретные возможности, такие как база данных или структура защиты, с возможностями других систем. На мой взгляд, главное не в этом. Да, у AS/400 мощная база данных и надежная система защиты, но этим обладают и другие системы. Отличительная черта AS/400, которую многие наши разработчики считают само собой разумеющейся, — то, что все компоненты спроектированы,чтобы работать вместе. Система AS/400 — это больше, чем просто сумма составных частей.
Если задать тот же вопрос ISV, то он, вероятно, скажет, что для AS/400 проще, чем для какой-либо другой платформы, разрабатывать и сопровождать приложения. ISV, имеющие свои приложения как для AS/400, так и для других платформ, например Unix, часто указывают на разницу в численности людей, работающих для одной или другой платформы. Обычно, для разработки приложений для AS/400 требуется гораздо меньше людей, и это также — заслуга интеграции. Гарантируя, что новая добавленная функция будет гладко работать со всеми остальными частями системы, мы сокращаем расходы на разработку для AS/400. Все системы, созданные в Рочес-тере до AS/400 включительно, решены интегрировано, и именно в этом секрет их успеха.
Но если даже наши собственные разработчики порой забывают об этом факторе, то благодаря чему AS/400 остается интегрированной системой? Ответ — MI. MI делает для обеспечения интеграции две вещи. Во-первых, он предоставляет общий интерфейс для всех приложений и функций операционной системы, реализованных поверх него, благодаря чему всем приходится использовать систему одинаковым образом. Во-вторых, MI — функционально законченный интерфейс. Так как обойти его невозможно, MI предоставляет все функции, которые могут потребоваться прикладной или системной программе. Если какая-либо нужная функция отсутствует, то программа не будет работать на AS/400. MI также обладает большими возможностями расширения, что позволяет включать в него новые функции по мере надобности.
Прежде чем кто-нибудь укажет на то, что другие системы Рочестера, такие как System/36, добивались интеграции без машинного интерфейса высокого уровня, я должен отметить, что MI обеспечивает и интеграцию, и аппаратную независимость. У System/36 был эквивалент машинного интерфейса для большинства системных функций, но не для приложений. В этой системе два отдельных процессора выполняли: один — пользовательские приложения, а другой — некоторые функции операционной системы. Доступ к этим функциям на втором процессоре был возможен только посредством строго определенного интерфейса между двумя процессорам. Данный интерфейс, подобно MI, гарантировал полноту набора функций и возможность их совместной работы. Приложения, однако, по-прежнему зависели от аппаратуры. По этой причине (как мы увидим в главе 3) для выполнения приложений System/36 на другой аппаратуре требовался эмулятор.
Отрицательная сторона интеграции — отсутствие гибкости. В интегрированных решениях обычно имеет место подход «все или ничего». Клиент не может выбрать
ОС одного производителя, базу данных — другого и пакет защиты — третьего, так как все они не предназначены для работы в интегрированной системе.
Трудно поверить в то, что в любой компьютерной системе есть компоненты, не предназначенные для тесной совместной работы, но часто именно так и обстоит дело. Такие компоненты как базы данных, подсистемы защиты и коммуникаций обычно разрабатываются независимо друг от друга и могут предназначаться для работы с разными ОС. В результате, такие компоненты обычно самодостаточны, то есть стремятся использовать минимальный набор возможностей, встроенных в ОС. Подобное разделение ведет к дублированию функций между ОС и отдельными компонентами. Оно также может привести к разным интерфейсам пользователя и системного оператора.
Преимущество набора из отдельных компонентов состоит в гибкости. Недостаток — в том, что заказчик должен самостоятельно интегрировать такие компоненты в своей вычислительной системе, а это связано с расходами, и не только на собственно интеграцию. Средства тратятся на обучение пользователей и операторов работе с разными интерфейсами, а также на сопровождение. Модернизации одного компонента могут оказать негативное влияние на другой. Все еще более усложняется при использовании компьютеров в сети, которая сама по себе требует сопровождения. В попытке устранить множество несовместимостей между компонентами некоторые предприятия решают закупать все ПО у одного производителя. Но и это обычно не решает проблему.
 В общем, ситуация напоминает мне ту, в которой я оказался не так давно при покупке и установке новой аудиовидеосистемы. Каждый из четырех ее компонентов имел собственный пульт дистанционного управления. Поскольку все компоненты произведены одной фирмой, продавец заверил меня, что каждый пульт универсален, то есть может управлять всеми частями комплекса, а следовательно для системы в целом нужен всего один пульт. В действительности оказалось, что с помощью одного пульта можно управлять лишь некоторыми функциями каждого компонента, но не всей системой в целом: для этого надо использовать все четыре пульта. Кроме того, «пользовательские интерфейсы» пультов разные, кнопки для выполнения одной и той же функции находятся на них в разных местах и часто имеют разную форму и размер. Даже названия некоторых идентичных функций различаются. Точно также многим пользователям компьютеров приходится использовать несколько «пультов управления» при эксплуатации своих вычислительных систем. И им, и мне больше подошла бы интегрированная система.
В общем, ситуация напоминает мне ту, в которой я оказался не так давно при покупке и установке новой аудиовидеосистемы. Каждый из четырех ее компонентов имел собственный пульт дистанционного управления. Поскольку все компоненты произведены одной фирмой, продавец заверил меня, что каждый пульт универсален, то есть может управлять всеми частями комплекса, а следовательно для системы в целом нужен всего один пульт. В действительности оказалось, что с помощью одного пульта можно управлять лишь некоторыми функциями каждого компонента, но не всей системой в целом: для этого надо использовать все четыре пульта. Кроме того, «пользовательские интерфейсы» пультов разные, кнопки для выполнения одной и той же функции находятся на них в разных местах и часто имеют разную форму и размер. Даже названия некоторых идентичных функций различаются. Точно также многим пользователям компьютеров приходится использовать несколько «пультов управления» при эксплуатации своих вычислительных систем. И им, и мне больше подошла бы интегрированная система.
Глава 2
Технология PowerPC
«По сути своей, IBM s компания технологий», — сказал Лу Герстнер (Lou Gerstner) вскоре после того, как возглавил корпорацию в 1993 году. И действительно, чуть ли не все основные технологии компьютерной индустрии s от RISC до реляционных баз данных s вышли из IBM. В прошлом IBM не всегда удавалось коммерчески использовать свои изобретения, и Герстнер собирается это изменить. По его мнению, главное s продвижение нескольких ключевых технологий, одна из которых — RISC-микропроцессор PowerPC в AS/400 Advanced Series.Микросхемы сжимаются на глазах
Статистика говорит, что сегодня в мире от 300 до 400 миллиардов микросхем, в том числе около 15 миллиардов кристаллов микропроцессоров. В основном, это микросхемы памяти. Произвести их в таком количестве за последние несколько лет позволил быстрый прогресс в технологии кремниевых микросхем. Подавляющее большинство микропроцессоров используются не в компьютерах, а в наручных часах, телевизорах, кухонных приборах и автомобилях. Например, в новом автомобиле обычно от 10 до 12 микропроцессоров, а в некоторых моделях sзначительно больше. С каждым новым поколением микросхем производителям удается разместить на одном кристалле все больше транзисторов, примерно удваивая это число каждые 18 месяцев. Данная закономерность известна как закон Мура, названный так в честь Гордона Мура (Gordon Moore), председателя и одного из основателей Intel. В 1971 году Intel выпустила свой первый микропроцессор 4004, содержавший 2300 транзисторов на одной микросхеме. Современный кристалл микропроцессора содержит миллионы транзисторов. Предсказание Мура сбывается уже более четверти столетия1. Постоянное сокращение размера транзисторов позволяет увеличивать плотность их упаковки на кристалле. По мнению многих экспертов, вскоре после 2000 года появятся транзисторы размером всего лишь около 0,18 микрона; а еще менее чем через десять лет s 0,08 микрон. Для сравнения, толщина человеческого волоса примерно 80 микрон. Представьте себе тысячу транзисторов, размещенных на его срезе! Судя по такой стремительности прогресса, закон Мура продержится еще не один десяток лет. Не пройдет и десятилетия, и мы, вероятно, увидим микросхемы с более чем 100 миллионами транзисторов; а размещение на одной микросхеме миллиарда транзисторов может стать возможным уже лет через 15 лет. Все это обеспечит та же самая кремниевая технология, которая применяется для современных микросхем. Необходимость ее замены возникнет, по-видимому, не раньше чем через 20 лет. Однако у микросхем с высокой плотностью упаковки есть и минусы. Они невероятно сложны, и их разработка и производство становятся все дороже. В будущем экономические проблемы, вероятно, приведут к прекращению производства микросхем несколькими известными сегодня фирмами. Уже сейчас завод, производящий кристаллы для современных микросхем стоит более 2 миллиардов долларов, а стоимость производства микросхем с размером транзисторов менее 0,1 микрон, вероятно, «перевалит» за 10 миллиардов. С учетом продолжающегося падения цен на полупроводниковые микросхемы, можно предположить, что через 10 лет производителей микросхем останется не более десятка. Никто не знает, кто выдержит эту гонку, и сегодняшние удачи ничего не гарантируют в будущем. Возьмем, например, Intel. Многие считают, что благодаря популярности ПК, Intel s крупнейший производитель микропроцессоров. Но это не так! Intel производит только около 1,5 процента всех микропроцессоров. Motorola, Hitachi и даже Zilog (помнит ли кто-нибудь Z80?) продают гораздо больше микропроцессоров, чем Intel. Своим успехом Intel обязан, главным образом, высоким ценам, которые он устанавливает на свои микросхемы для ПК. Другие производители продают микросхемы равной производительности дешевле. Но пока существуют ПК, Intel может запрашивать высокие цены. IBM твердо намерена оказаться в числе тех производителей микросхем, которые выживут в следующем десятилетии. Свои надежды мы возлагаем на процессоры PowerPC, чья технология будет фундаментом AS/400 и другой продукции IBM в течение следующих нескольких лет. Итак, давайте более подробно рассмотрим эволюцию архитектуры PowerPC и использование ее в AS/400, а затем поговорим о процессорах, используемых в различных RISC-моделях AS/400.Альянс PowerPC
В начале 1991 года Apple Computer подыскивала новый процессор для своих компьютеров. Ее специалисты полагали, что будущее процессоров ПК — в RISC-архитектуре. В то время процессоры ПК, производимые Motorola, Intel и другими фирмами, имели архитектуру CISC. Apple тогда использовала процессоры Motorola, и хотя последняя уже создала RISC-процессор, он не имел большого коммерческого успеха. У технологии RISC фундаментальные преимущества над CISC. RISC-процессор более производителен, он упакован на кристалле меньшего размера и потребляет меньшую мощность. В Apple поняли, что вычислительная техника, в конце концов, будет двигаться в этом направлении, но в 1991 году подавляющее большинство доступных микропроцессоров по-прежнему имели архитектуру CISC. В то время IBM производила одни из лучших RISC-процессоров. Они применялись в компьютерах RISC System/6000 (RS/6000). Все эти процессоры имели многокристальную 32-разрядную архитектуру, но IBM планировала выпустить в начале 1992 года однокристальную версию RCS (RISC Single Chip). Узнав, что Apple ищет новый RISC-микропроцессор, в IBM решили узнать, не подойдет ли им продукция IBM. Оправившись от шока, вызванного тем, что их прямой конкурент на рынке ПК — IBM — пытается продать им процессоры, в Apple решили, что в этом что-то есть. Зная, что Motorola также работает над новым RISC-процессором, Apple предложила объединить усилия трех фирм. После переговоров IBM согласилась, и в сентябре 1991 года три фирмы официально объявили о совместной разработке некоторых новых технологий, включая большое семейство микропроцессоров. В основе дизайна микропроцессоров должен был лежать RSC. Новое семейство получило название PowerPC. Три партнера понимали, что успех на рынке зависит от объема продаж новых микросхем и возможностей выбора программного обеспечения. Для этого они стали привлекать к использованию PowerPC производителей аппаратного и программного обеспечения, включая Toshiba, Canon, Zenith Data Systems, Harris Computer и Groupe Bull. Чтобы еще больше повысить объем продаж процессоров, члены альянса привлекли и фирмы, работающие вне области вычислительной техники. Хороший пример такого сотрудничества s компания Ford Motor. В будущих автомобилях Ford микропроцессоры PowerPC будут применяться для управления важнейшими узлами — от двигателя до системы торможения.Эволюция PowerPC
Концепция RISC была разработана Джоном Коком (John Cocke) из IBM Research. Кок установил, что прогресс в области компиляторов достиг той точки, когда можно упростить набор команд процессора, и возложить на компилятор значительную часть работы, ранее выполнявшейся аппаратурой. Впервые идеи Кока были воплощены в миникомпьютере IBM 801. Процессоры PowerPC s прямые наследники 801. Основным мотивом создания архитектур CISC было желание сократить семантический разрыв между двоичным машинным языком процессора и ЯВУ, используемыми программистами. В двоичный машинный язык вводились команды, соответствующие инструкциям языка высокого уровня. Идея заключалась в том, чтобы процессор исполнял меньшее количество сложных команд, что позволило бы сэкономить память. К несчастью, машинные команды стали настолько сложны, что при создании практически любого процессора приходилось применять микропрограммирование. Накладные расходы микропрограммируемого эмулятора замедляли выполнение часто встречающихся простых команд. Кок доказывал, что при использовании только простых команд, необходимость в микропрограммировании отпадет, а все команды будут выполняться аппаратурой непосредственно. Более того, если бы стоимость памяти не была столь существенна, то компиляторы могли бы напрямую подставлять код для выполнения более сложных функций. Потребности в памяти увеличились бы, но возросла бы и производительность. Дизайн процессора 801 был заимствован у суперкомпьютеров s самых быстродействующих ЭВМ. Хотя сам термин «суперкомпьютер» до середины 70-х годов не использовался, но конструкторы, стремившиеся раздвинуть пределы возможностей аппаратных технологий, были всегда. Невозможно говорить о суперкомпьютерах, не вспомнив о Сеймуре Крее (Seymour Cray). Если хотите, Крей и суперкомпьютер — это синонимы. Современные архитектуры RISC-процессоров многим обязаны этому первопроходцу[ 10 ]. Значительно повысить производительность процессоров позволил метод конвейерной обработки (pipelining). На протяжении уже многих лет эта технология используется при создании всех компьютеров, от ПК до больших ЭВМ. Суть ее — в параллельном исполнении фрагментов последовательных команд на разных этапах аппаратного конвейера. Первый компьютер общего назначения, использовавший конвейерную обработку, появился еще в 1961 году. Это был IBM 7030, известный также под названием Stretch. Рисунок 2.1а Конвейерный скалярный процессор — пятиэтапный конвейер команд.
Рисунок 2.1а Конвейерный скалярный процессор — пятиэтапный конвейер команд.
Пример пятиэтапного конвейера команд показан на рисунке 2.1а. Время, необходимое для выполнения каждого этапа выполнения команды, называется временем цикла процессора (processor cycle time). На рисунке 2.1б показана временная диаграмма пятиэтапного конвейера. В течение первого цикла процессора команда № 1 выбирается из буфера команд аппаратурой первого этапа конвейера. В течение второго цикла команда № 1 декодируется, и содержимое необходимых регистров считывается аппаратурой второго этапа. В то же самое время, аппаратура первого этапа считывает из буфера команд команду № 2. Теперь аппаратура разных стадий конвейера параллельно обрабатывает разные части двух разных команд. Благодаря такому параллелизму и достигается повышенная производительность процессоров с конвейерной обработкой. Обратите внимание: предполагается, что некоторая другая часть аппаратуры процессора обеспечивает заполнение буфера команд.
 Рисунок 2.1b Пример временной диаграммы
Рисунок 2.1b Пример временной диаграммы
В течение третьего процессорного цикла команда № 1 поступает на стадию выполнения и вычисления эффективного адреса (стадия 3), команда № 2 поступает на стадию 2, а команда № 3 s на стадию 1. Процесс продолжается вплоть до завершения пятого цикла процессора, когда выполнение команды: № 1 заканчивается и она покидает конвейер. Таким образом, выполнение каждой отдельной команды занимает полные пять циклов, но после того, как конвейер заполнен, на каждом цикле процессора завершается выполнение одной команды. Когда говорят, что для выполнения одной команды необходим один цикл процессора, подразумевается, что конвейер заполнен, что, понятно, близко к идеалу[ 11 ]. В начале 60-х годов Сеймур Крей в Control Data Corporation разрабатывал первый в мире суперкомпьютер — CDC 6600. Он планировал использовать конвейерную обработку и добивался, чтобы время выполнения всех команд было одинаковым. Ведь, как видно из приведенного примера, общее время выполнения команд определяется командой, имеющей самое большое время выполнения. Команды, выбирающие операнды из памяти или записывающие их в память, обычно выполняются дольше остальных. Если эти, работающие с памятью, команды выполняют также и логические или арифметические действия над данными, то время выполнения может стать очень большим. Чтобы максимально сократить общее время выполнения команд, Крей решил, что в его процессоре единственными операциями с памятью будут загрузка в регистр содержимого памяти по некоторому адресу и сохранение содержимого регистра по некоторому адресу в памяти. Любые действия над данными должны производиться только в регистрах. Тогда это было очень непривычно: ведь большинство других компьютеров позволяли выполнять операции над данными в памяти без использования регистров. Например, команды S/360 позволяют сложить два находящихся в памяти операнда и записать сумму обратно в память. Эта операция занимает очень много времени, но выполняется одной машинной командой. Команды данного типа называются командами память-память. Для выполнения той же самой операции на машине Крея потребовалось бы пять команд. Сначала две команды загрузки поместили бы данные в два регистра. Затем команда сложения просуммировала бы содержимое этих регистров и поместила бы результат обратно в регистр. И, наконец, команда сохранения переписала бы сумму из регистра в память[ 12 ]. Но если эффективно поместить все эти пять команд на конвейер и выполнять их параллельно, то общее необходимое для этого время будет меньше времени, необходимого для выполнения эквивалентной операции на машине с командами типа память-память. И все же большее число команд, требуемых для выполнения операции, было недостатком машины Крея. В 1964 году появилась CDC 6600 s первая машина общего назначения с архитектурой загрузка/сохранение (load/store). Крей осознал связь между конвейерной обработкой и архитектурой набора команд, и это привело его к выводу о необходимости упрощения этой архитектуры для повышения эффективности конвейера. Современные RISC-процессоры используют подход Сеймура Крея — в них команды, работающие с памятью, выполняют только загрузку и сохранение. Вот почему RISC-машины быстрее CISC-машин с полным набором команд для работы с памятью. По той же причине и программы, скомпилированные для RISC, больше по размеру. Вклад Сеймура Крея в разработку высокопроизводительных конвейеров не ограничивается только архитектурой набора команд. В CDC 6600 он применил аппаратуру, которая обеспечивала максимум производительности путем максимально возможной загрузки конвейера, то есть ситуацию, при которой на каждой его стадии выполняется часть некоторой команды. В реальности, между командами в программах существуют зависимости. Если команда на конвейере использует данные, которые сохраняются командой, идущей по конвейеру непосредственно впереди нее, то в определенный момент эти данные могут быть еще недоступны, что не только вызывает простой конвейера, но и останавливает выполнение всех последующих команд. Тем самым уменьшается производительность процессора. В CDC 6600 было впервые реализовано оборудование, позволяющее процессору просматривать команды, расположенные далее в потоке команд, и определять, могут ли они быть запущены перед той, что ожидает сохранения результата. Идея аппаратного переупорядочивания команд на конвейере, известная как динамическое планирование (dynamic scheduling), служила поддержанию максимально возможной его загрузки и значительно повысила производительность CDC 6600. В суперкомпьютерах 60-х была реализована и идея предсказания переходов. Команда перехода может разрушить конвейер. Вызванный ею простой затянется до тех пор, пока система не будет в состоянии решить, какая команда должна выполняться следующей. Идея предсказания переходов состоит в том, чтобы на основе опыта угадать, откуда следует выбирать команду, следующую после команды перехода. Использованное в IBM 360/91 сложное аппаратное обеспечение предсказания переходов позволило достичь отличных результатов. 360/91 обладала еще одной интересной аппаратной особенностью. Опираясь на ее опыт, Боб Томасуло (Bob Tomasulo), инженер IBM, усовершенствовал алгоритм Крея, созданный несколькими годами ранее, и создал новый алгоритм динамического планирования. Реализованный аппаратно, алгоритм Томасуло устранил многие случаи простоя конвейера путем выполнения команд не по порядку их следования. Команда, которая должна ожидать получения некоторого результата, более не останавливает команды, следующие за ней. Алгоритм Томасуло требовал невероятно сложной по тем временам аппаратуры, но на деле позволял достичь желаемого роста производительности. Специализированное оборудование для повышения производительности конвейера повышало не только сложность, но и цену аппаратуры. Для суперкомпьютеров цена не играет особой роли, чего не скажешь об обычных системах. В конце 60-х годов Джон Кок работал над проектом быстрого компьютера для научных расчетов в IBM Research Laboratory в Сан-Хосе (San Jose), штат Калифорния, и вплотную столкнулся со сложностью оборудования, необходимого для поддержания загрузки конвейера. Кок полагал, что если переложить большую часть ответственности за это на компиляторы, то оборудование значительно упростится и подешевеет. И тогда высокопроизводительная обработка перестанет быть прерогативой суперкомпьютеров. Так родилась идея RISC. К сожалению, этот исследовательский проект был прерван прежде, чем Кок смог реализовать свои идеи. Еще один шанс сделать это представился ему в 1976 году, в исследовательской лаборатории IBM Yorktown в Нью-Йорке. Коку было поручено спроектировать и построить высокопроизводительный контроллер телекоммуникаций. Именно этот контроллер, получивший кодовое наименование 801 (по номеру здания, в котором работал Кок) обычно считается первым RISC-компьютером. 801 доказал, что планирование загрузки конвейерного процессора может быть возложено на компилятор. Сочетание компилятора, генерировавшего поток команд, оптимизированный для конкретного конвейерного процессора, и упрощенного процессора типа загрузка/сохранение, аналогичного машине Сеймура Крея, до сих пор остается непревзойденным. Современные RISC-процессоры используют идею Джона Кока s оптимизирующий компилятор, соответствующий аппаратуре процессора. Их производительность обеспечивается технологическими достижениями как аппаратуры, так и компиляторов. Поскольку за последние несколько лет компиляторы очень быстро прогрессируют, то есть даже предложения переименовать RISC в «Relegate Interesting Stuff to Compilers»[ 13 ]. Первым продуктом IBM, в котором использовались идеи 801, был PC RT. Подразделению по созданию продукции для офисов в Остине понадобился новый процессор. В качестве отправной точки для разработки был взят 801. Новый микропроцессор, названный ROMP (Research/Office Products Microprocessor), включал в себя подмножество 801, что обеспечивало низкую себестоимость. Главным архитектором и менеджером разработки PC RT выступал Гленн Хенри. Ранее он был программным менеджером нашего проекта в Рочестере, а после выхода на рынок System/38 перебрался в Остин, где возглавил первый проект IBM по созданию RISC-компьютера. 801 использовался также и другими организациями в качестве базы для создания RISC-процессоров. В начале 80-х исследования по этой теме велись группой Дэвида Паттерсона (David Patterson) в Калифорнийском университете в Беркли (Berkeley) и группой Джона Хеннеси (John Hennessy) в Станфордском университете. Именно Паттерсон и придумал термин «RISC». Выпускники обоих упомянутых университетов работали в IBM Research и знали 801. Проект Паттерсона лег в основу микропроцессора SPARC, использовавшегося компанией SUN, а проект Хеннеси s микропроцессора MIPS. Тем временем, в расположенной по соседству компании HP разработкой архитектуры PA-RISC занимался Джоел Бирнбаум (Joel Birnbaum), ранее возглавлявший группу 801 в IBM Research. Таким образом, PA-RISC также s прямой потомок проекта 801. Ранние процессоры RISC, как и 801, использовали один конвейер. Кок и другие сотрудники IBM полагали, что повысить производительность можно путем распределения на каждом цикле нескольких команд из обычного линейного потока по нескольким конвейерам. Такой компьютер был создан и назван суперскалярным. Первый суперскалярный RISC-процессор появился в 1990 году в RS/6000. В основе его архитектуры также лежал 801. Чтобы отметить суперскалярное расширение RISC-процессора, IBM назвала эту архитектуру POWER (Performance Optimization With Enhanced RISC). Архитектура POWER стала стартовой площадкой объединенного проекта Apple, IBM и Motorola.
 Рисунок 2.2. Эволюция PowerPC
Рисунок 2.2. Эволюция PowerPC
Чтобы удовлетворить будущие потребности всех трех корпораций, архитектуру POWER требовалось несколько изменить. Большинство процессоров POWER были многокристальными. Некоторое упрощение архитектуры сделало возможным создание дешевых однокристальных вариантов (иначе говоря, микропроцессоров). Кроме того, архитектура POWER не поддерживала многопроцессорные системы, так что и здесь понадобились соответствующие добавления. Были также увеличены возможности поддержки предполагаемых будущих приложений. Наконец, 32-разрядная архитектура POWER была расширена путем включения 64-разрядных адресов и операций. В результате всех этих изменений на свет появилась новая архитектура s PowerPC. Ее эволюция, начиная с 801, показана на рисунке 2.2. Усилиями инженеров Apple, IBM и Motorola был создан новый проектный центр для разработки микропроцессоров PowerPC. Персонал Somerset[ 14 ] Design Center, расположенного в Остине, состоит, в основном, из инженеров IBM и Motorola. В конце 1995 года Somerset стал частью подразделения IBM Microelectronics. Сотрудничающие фирмы имеют право производить и продавать процессоры, разработанные в Сомерсете. Например, Apple покупает микросхемы PowerPC как у IBM, так и у Motorola. Процессоры PowerPC Motorola производятся на заводе этой фирмы в Остине. IBM производит свои микросхемы PowerPC в Барлингтоне (Burlington), штат Вермонт. Важно отметить, что RISC-процессоры в последние несколько лет неуклонно прогрессируют. Практически каждый их производитель, включая консорциум PowerPC, ныне поставляет на рынок 64-разрядный RISC-процессор, на кристалле которого установлена аппаратура динамического планирования, использующая описанный выше алгоритм Томасуло, а также предсказания переходов. Удивительно, но мы, кажется, совершили полный круг? В современные процессоры снова включена вся аппаратура, для устранения которой и была первоначально предложена RISC-архитектура. Сеймур Крей мог бы гордиться: ведь аппаратные решения, предложенные им впервые в 1964 году, взяли верх над более простыми архитектурами ранних RISC-процессоров. Это определенно не те RISC-процессоры, что раньше!
RISC-процессор AS/400 для коммерческих расчетов
В 1990 году была разработана новая архитектура RISC-процессора для будущих моделей AS/400. Первоначальная архитектура процессора, получившая неуклюжее название Internal Microprogrammed Interface (IMPI)[ 15 ] была разработана в середине 70-х для System/38 и предназначалась для поддержки интерактивных коммерческих систем обработки транзакций. IMPI была преимущественно архитектурой память-память. С помощью одной команды данные могли быть выбраны из памяти, изменены процессором и записаны обратно. Обычно, интерактивные приложения обработки транзакций перемещают много данных, но изменяют лишь их малую часть. Рассмотрим типичную операцию обновления инвентарной описи. Пользователь делает заказ по телефону. Наше приложение должно обновлять инвентарную запись для каждой проданной им единицы товара. Инвентарная запись выбирается из памяти, или, что вероятнее всего, с диска. Размер заказа сравнивается с полем количества в записи, и если это количество достаточно, то оно уменьшается на число проданных единиц товара. Наконец, обновленная запись помещается обратно в память, и к ней может обратиться другой пользователь системы. Описанная операция может считаться отдельной транзакцией, или быть частью более крупной транзакции. В любом случае, мы имеем дело с обработкой транзакций. Кроме того, данное приложение интерактивно, так как им управляет человек за терминалом (приемщик заказа). Этому человеку исключительно важно получить ответ быстро. Следовательно, для создания интерактивной системы обработки транзакций абсолютно необходим процессор, который в состоянии перемещать большие объемы данных и выполнять операции в короткое время. AS/400 отлично подходит для приложений такого типа. На протяжении многих лет мы исследовали тысячи коммерческих приложений, написанных для AS/400 и других многопользовательских систем Рочестера. Все они имеют ряд общих характеристик. Рассмотрим некоторые из них.Возможность поддерживать параллельную работу сотен и даже тысяч пользователей. Длинные последовательные цепочки команд, причем большая часть длины такой цепочки приходится на код операционной системы, а не приложения. Приложения выполняют множество обращений к операционной системе за различными видами обслуживания, например, для ввода-вывода. Адресация структур данных в AS/400 выполняется посредством указателей, что требует использования целочисленной арифметики для обновления адресов. При обработке данных используются, в основном, строковые или целочисленные сравнения, обновления и вставки. Арифметика с плавающей точкой используется редко. Циклы в приложениях для AS/400 встречаются реже, а нециклические переходы чаще, чем в приложениях для научных расчетов. Обрабатываемые данные разбросаны по большому объему дискового пространства. Объем данных, выбираемых за одно обращение к диску, относительно невелик, а последовательные обращения с большой вероятностью будут обращены к разным дискам.
Сравним приложение данного типа с типичным приложением для инженерных или научных расчетов, выполняемом на специализированной рабочей станции. Последние часто называют вычислительными (compute-intensive), так как они выполняют большие объемы вычислений с относительно малыми объемами данных. Обычно, такие приложения имеют малые рабочие наборы команд с большим числом компактных циклов вычислений с плавающей точкой. Ввод-вывод в них чаще последовательный, а не прямой. Сеймур Крей показал, что для приложений такого типа наилучшим будет процессор, который обрабатывает данные только в регистрах, как RISC-процессоры. Коммерческие приложения по-прежнему преобладают, среди программ, написанных для AS/400. Но появляется все больше высокопроизводительных вычислительных приложений, что связано с переходом к модели клиент-сервер. В этой модели приложение разбивается между ПК или сетевым компьютером СК (клиент) и AS/ 400 (сервер). Серверные приложения ориентированы на увеличение числа операций, по сравнению с интерактивными приложениями. Приложения будущего, вероятно, потребуют еще большей вычислительной мощности. С момента своего появления архитектура IMPI неоднократно расширялась и модифицировалась. Но даже и с учетом этих изменений ее нельзя признать подходящей для выполнения большого объема вычислений. Большинству специалистов в Рочестере было ясно, что для удовлетворения будущих потребностей в вычислительной мощности необходимо введение характеристик RISC-процессора. Итак, в 1990 году мы начали проект по добавлению к IMPI свойств RISC. Сначала мы хотели использовать процессор от RS/6000, но быстро отказались от этой мысли. Архитектура POWER была разработана для технических расчетов. Ей недоставало ряда характеристик, необходимых для выполнения коммерческих вычислений. Кроме того, она не могла обрабатывать большие объемы данных с требуемой эффективностью. В то время RISC-процессоры были, как правило, 32-разрядными (то есть ширина трактов данных и регистров процессора равна всего лишь 32 битам). Большинство имело и 64-разрядные регистры с плавающей точкой, но целочисленные регистры — те, которые используются для коммерческих расчетов, — имели только 32 разряда. А так как RISC-процессор перед обработкой данных должен сначала загрузить их в свои регистры, то при больших объемах данных 32-разрядная ширина быстро становится недостатком. Архитектуры CISC, такие как IMPI, могут выполнять команды память-память, обрабатывая данные без загрузки их в регистры, таким образом, это узкое место здесь фактически обходится. Приняв во внимание эти соображения, мы решили, что для нашего будущего компьютера необходим полностью 64-разрядный процессор. Дополнительно на нас влияло то, что ширина адреса в AS/400 равна 48 битам, и этот адрес невозможно втиснуть в 32-разрядный регистр. 64-разрядный процессор позволял нам расширить адрес, используемый в IMPI, с 48 до 64 бит. Наши расчеты показывали, что в будущем, по мере того как системы AS/400 будут становиться все больше и больше, настанет момент, когда потребуется больший размер адреса. Нельзя было не брать во внимание и объем микрокода, который пришлось бы изменить. Начав с IMPI, мы смогли бы минимизировать эти изменения. Итак, было принято решение: взять IMPI, расширить его до 64 бит и добавить вычислительные операции, присущие RISC. Нам предстояло создать первый гибридный процессор CISC/RISC, предназначенный исключительно для коммерческих вычислений. Мы назвали его C-RISC — «Commercial-RISC».
Технология PowerPC для AS/400
Президентом IBM в 1991 году был Джек Кюлер (Jack Kuehler). Он привел IBM к соглашению с Apple и Motorola о создании микропроцессоров PowerPC. Джек Кюлер считал, что к концу десятилетия все компьютеры, от самых маленьких, умещающихся на ладони, до суперЭВМ будут использовать RISC-процессоры. Он также полагал, что компании, создающие такие микропроцессоры, можно будет пересчитать по пальцам одной руки, и был твердо уверен, что альянс PowerPC станет одной из таких выживших фирм. Кюлер не мог понять, почему обе его основные лаборатории одновременно занимаются разработкой новых RISC-процессоров. Лаборатория в Остине ра ботала над спецификацией PowerPC, а лаборатория в Рочестере s над C-RISC. I Кюлер был убежден в необходимости объединить усилия двух этих исследовательских центров, а также в том, что PowerPC подойдет и тем, и другим. Он стал выяснять, почему Рочестер не может использовать этот процессор. Мы покорно ездили в Армонк (Armonk), штат Нью-Йорк, где попытались объяснить различия между процессорами для коммерческих и научных расчетов. Кюлер не оспаривал успехи Рочестера, но и не принимал наши доводы. Он требовал дополнительные данные в обоснование нашей позиции. «Неужели RS/6000 не может выполнять и коммерческие вычисления?» — спрашивал он. Наконец, примерно после третьего визита в Армонк нам удалось его убедить.
Специалисты Рочестера знали, о чем говорят. Они понимали как делать процессоры для коммерческих вычислений, и чем эти процессоры отличались от предназначенных для технических расчетов. И все же Кюлер настоял, чтобы через 90 дней мы вернулись к нему с ответами на два вопроса: «Как изменить архитектуру PowerPC, чтобы она стала подошла для AS/400?» и «Сколько будет стоить перевод AS/400 на эту новую архитектуру?». Тем самым Кюлер дал нам возможность влиять на проект PowerPC. Он также изъявил желание финансировать любые дополнительные расходы, связанные с переходом на новый процессор.
В начале апреля 1991 года я возглавил группу из 10 человек, которая должна была дать ответ на оба эти вопроса. Кюлер также дал указание главе IBM Research, отвечавшему за согласование архитектуры PowerPC с Apple и Motorola, работать в тесном контакте с нами. Кроме того, наши инженеры тесно сотрудничали со своими коллегами из Остина.
Успех проекта во многом зависел от из рочестерской команды:, чьи инженеры были в числе самых лучших. Задача была не из легких. Сначала казалось, что требования AS/400 прямо противоположны задачам PowerPC. Затем возникло ощущение, что в результате слияния этих двух архитектур Рочестер лишится возможности создавать процессоры, оптимизированные для коммерческих расчетов. Нечего и говорить, как горячи были споры!
Было решено начать с архитектуры PowerPC в том виде, как она была определена на тот момент. К ней следовало добавить расширения, необходимые для AS/400. В результате должно было получиться нечто новое, заранее названное, в отличие от базовой архитектуры PowerPC, Amazon.
Кюлер не мог понять, почему обе его основные лаборатории одновременно занимаются разработкой новых RISC-процессоров. Лаборатория в Остине ра ботала над спецификацией PowerPC, а лаборатория в Рочестере s над C-RISC. I Кюлер был убежден в необходимости объединить усилия двух этих исследовательских центров, а также в том, что PowerPC подойдет и тем, и другим. Он стал выяснять, почему Рочестер не может использовать этот процессор. Мы покорно ездили в Армонк (Armonk), штат Нью-Йорк, где попытались объяснить различия между процессорами для коммерческих и научных расчетов. Кюлер не оспаривал успехи Рочестера, но и не принимал наши доводы. Он требовал дополнительные данные в обоснование нашей позиции. «Неужели RS/6000 не может выполнять и коммерческие вычисления?» — спрашивал он. Наконец, примерно после третьего визита в Армонк нам удалось его убедить.
Специалисты Рочестера знали, о чем говорят. Они понимали как делать процессоры для коммерческих вычислений, и чем эти процессоры отличались от предназначенных для технических расчетов. И все же Кюлер настоял, чтобы через 90 дней мы вернулись к нему с ответами на два вопроса: «Как изменить архитектуру PowerPC, чтобы она стала подошла для AS/400?» и «Сколько будет стоить перевод AS/400 на эту новую архитектуру?». Тем самым Кюлер дал нам возможность влиять на проект PowerPC. Он также изъявил желание финансировать любые дополнительные расходы, связанные с переходом на новый процессор.
В начале апреля 1991 года я возглавил группу из 10 человек, которая должна была дать ответ на оба эти вопроса. Кюлер также дал указание главе IBM Research, отвечавшему за согласование архитектуры PowerPC с Apple и Motorola, работать в тесном контакте с нами. Кроме того, наши инженеры тесно сотрудничали со своими коллегами из Остина.
Успех проекта во многом зависел от из рочестерской команды:, чьи инженеры были в числе самых лучших. Задача была не из легких. Сначала казалось, что требования AS/400 прямо противоположны задачам PowerPC. Затем возникло ощущение, что в результате слияния этих двух архитектур Рочестер лишится возможности создавать процессоры, оптимизированные для коммерческих расчетов. Нечего и говорить, как горячи были споры!
Было решено начать с архитектуры PowerPC в том виде, как она была определена на тот момент. К ней следовало добавить расширения, необходимые для AS/400. В результате должно было получиться нечто новое, заранее названное, в отличие от базовой архитектуры PowerPC, Amazon.
 Хотя в Рочестере и были определенные сомнения в плодотворности идеи общей архитектуры RISC, тем не менее, ее разработка шла быстро. Основная роль здесь принадлежала Энди Уоттренгу (Andy Wottreng) и Майку Кор-ригану (Mike Corrigan). Они выполнили выдающуюся работу по интеграции технических требований AS/400 в новую архитектуру. В результате, впервые была создана архитектура RISC, которая одинаково хорошо подходила и для коммерческих, и для технических приложений.
За координацию проекта отвечал Дэррил Соли (Darryl Solie). Он находился в тесном контакте с обеими группами разработчиков в Остине и Рочесте-ре и обеспечивал взаимодействие между ними. Проектировщики Рочестера многому научились у инженеров других подразделений IBM и Motorola. Уровни производительности процессоров, которые сперва казались недостижимыми, внезапно становились возможными. В результате, сейчас в Рочес-тере создаются одни из самых быстрых процессоров в мире. Наша лаборатория отвечает внутри IBM за разработку новых 64-разрядных процессоров для коммерческих вычислений.
Всякий раз, когда возникали трения, разгорались споры, и кто-нибудь начинал утверждать, что порочна идея в целом, в дело вмешивался Билл Берг (Bill Berg). Спокойно, дипломатично и быстро убеждал нас в том, что мы s на правильном пути, и что только мы можем пройти его до конца. Позднее Билл способствовал тому, чтобы убедить разработчиков использовать при создании программного обеспечения новой операционной системы объектно-ориентированные технологии.
Архитектура PowerPC должна была работать как в 32-разрядном, так и в 64-разрядном режимах. Все 64-разрядные версии PowerPC должны были иметь и 32-разрядное подмножество. Мы сосредоточились только на 64-разрядном режиме, практически не изменив 32-разрядное подмножество.
По мере разработки новой архитектуры мы могли предварительно оценить ее стоимость. Работа велась напряженно и была завершена за 90 дней, но результаты не слишком впечатляли.
Многие из необходимых нам архитектурных изменений было бы трудно внести в ранние версии процессоров PowerPC, разработанные в Сомерсете. Процессоры поздних моделей AS/400 должны были обрабатывать очень большие объемы данных, и для нужной производительности требовались очень широкие шины данных. Мы даже не пытались ничего добавлять в конструкции процессоров PowerPC 601, 603 или 604, так как они поддерживали только 32-разрядный режим. Было также крайне сомнительно, сможем ли мы усовершенствовать первый разработанный в Сомерсете 64-разрядный процессор (его окончательное название s 620), так как плотность упаковки элементов на этом кристалле была недостаточна для того, чтобы сделать его подходящим для наших моделей — пришлось бы разработать многокристальную версию архитектуры.
Даже в отношении младших моделей AS/400 у нас не было полной ясности. Некоторое время мы предполагали применить усовершенствованный вариант 620, который мы назвали 621, но в конце концов решили, что проще всего разрабатывать процессоры для AS/400 внутри IBM.
Одновременно с нами разработчики RS/6000 также пришли к заключению, что не смогут использовать ранние версии процессоров PowerPC в своих старших моделях. Для младших моделей подходил однокристальный процессор разработанный в Сомерсете, но для более высокопроизводительных моделей требовался многокристальный процессор. Кроме того, наши коллеги хотели включить в свой проект некоторые коммерчески выгодные возможности технических вычислений, а именно, NIC (numerically intensive computing), большинство из которых отсутствуют в обычном PowerPC. Также было добавлено больше конвейеров и новые вычислительные команды. Созданное в результате расширение первоначальной архитектуры POWER получило название POWER2.
Впервые процессоры архитектуры POWER2 были применены в RS/6000 в 1993 году. Они также использовались в RS/6000 Scalable POWERparallel System (RS/6000 SP). Последняя система ознаменовала выход IBM на рынок компьютеров параллельных вычислений. В RS/6000 SP может работать параллельно много таких процессоров. Параллельные машины очень хороши для ряда научно-технических и некоторых коммерческих приложений, например, для просмотра больших баз данных.
Первоначально архитекторы AS/400 и RS/6000 хотели добиться общей конструкции процессоров, решив включить в архитектуру Amazon все необходимые для них расширения. Мы планировали создать один процессор, который мог бы поддерживать специфические требования обеих систем.
У первого общего процессора PowerPC, предназначенного как для AS/400, так и для RS/6000, было несколько названий. Разработчики RS/6000 часто называли его POWER3, или PowerPC 630. Мы дали ему внутреннее имя Belatrix. Беллатрикс s это звезда в созвездии Ориона. Немногие знают, что ее называют также звездой Амазонки (Amazon Star). Belatrix должен был стать звездой архитектуры Amazon.
Как и многие предыдущие проекты, проект Belatrix был слишком амбициозным и всеохватывающим и не имел успеха. Мы решили, что целесообразнее иметь несколько версий процессоров PowerPC, оптимизированных для разных вычислительных сред. Каждый процессор PowerPC должен был реализовывать базовый набор команд и функций, а также поддерживать необязательные расширения.
Рочестер должен был сделать первые процессоры PowerPC применимыми для коммерческих задач. Первоначально они предназначались исключительно для AS/400.
Позже было принято решение: начиная с 1997 года использовать новое поколение 64-разрядных процессоров PowerPC, разработанных в Рочестере, и для RS/6000.
После прекращения работ над Belatrix в Остине начали разработку новой версии 630 — 64-разрядного процессора PowerPC, который должен был обеспечить вычислительную производительность, необходимую для будущих систем. Мы в Рочестере также стали разрабатывать свою версию Belatrix, которая предназначалась для серии AS/400 1998 года. Так как Belatrix назван по имени звезды, а Миннесота известна как штат Серверной звезды (North Star), то мы назвали новый процессор Northstartitle="">[ 16 ].
В области программного обеспечения ситуация с PowerPC была гораздо хуже, по сравнению с тем, что мы обещали Кюлеру. Все прикладное и системное программное обеспечение, работавшее поверх MI, было защищено благодаря независимой от технологии архитектуре AS/400. Однако, поскольку PowerPC сильно отличается от IMPI, то микрокод, расположенный ниже MI, было необходимо переделать под новый процессор. Это нелегкая задача, несмотря на то, что часть ее можно было осуществить с помощью автоматизированных средств. Между тем наши программисты должны были заниматься выпуском новых версий AS/400. Мы подсчитали, что для работы с RISC-процессором потребуется нанять несколько сотен новых системных программистов.
Наконец, мы были ограничены по времени. Первоначально планировалось выпустить новые процессоры C-RISC в середине 1994 года, мы уже мечтали о них для Advanced Series. При использовании PowerPC нам пришлось бы изменить планы и передвинуть выпуск RISC-процессоров на 1995 год s именно столько времени потребовалось бы для разработки нужных расширений и переписывания внутреннего кода. Пришлось бы оснащать Advanced Series процессорами IMPI и обеспечить возможность их модернизации процессорами PowerPC, когда последние будут готовы.
В начале июля 1991 года мы вновь нанесли визит Джеку Кюлеру. Большинство из нас полагали, что он поблагодарит за проделанную работу, сделает вывод, что переход на процессор PowerPC будет слишком дорогим и отправит обратно заниматься созданием C-RISC. Но Кюлер ничего такого не сделал. Вместо этого он попросил нас ускорить работу и предоставил необходимые для этого ресурсы. Так, внезапно для нас, пришлось полностью изменить направление работ над Advanced Series как в области аппаратного, так и программного обеспечения.
В конце июля мы завершили реорганизацию лаборатории для работы над новой системой. Ответственность за разработку новой модели процессора, названной Muskie, была возложена на Рочестер. Этот многокристальный процессор был предназначен для коммерческих вычислений на очень больших компьютерах. Разработка младших моделей серии AS/400 была переведена в лабораторию IBM в Эндикот-те. Эта линия получила наименование Cobra, и ее процессоры должны были быть однокристальными и полностью 64-разрядными.
Как уже упоминалось, первоначально мы планировали только 64-разрядный режим процессора. В конце концов, AS/400 не использует 32-разрядный режим, да и никто более не собирался использовать ранние 32-разрядные процессоры, так что реализовывать эту архитектуру в полном объеме, как нам казалось, не имело смысла. Но примерно через год, когда стало ясно, что AS/400 необходимо поддерживать все прикладное программное обеспечение, написанное для процессоров PowerPC, это решение было изменено. Поскольку большая часть таких программ написана для 32-разрядных процессоров, то и нам пришлось включить во все свои процессоры 32-разрядное подмножество. Это также должно было обеспечить возможность использовать наши новые PowerPC на других системах IBM.
Одновременно активизировалась работа по переносу микрокода AS/400 на новые процессоры. Это была возможность ревизии внутренностей операционной системы AS/400, чего не делалось с момента разработки System/38. Поскольку мы собирались перекраивать самые основы, то было решено идти до конца и использовать новейшие объектно-ориентированные методологии программирования. Мы планировали получить самую современную операционную систему.
Хотя в Рочестере и были определенные сомнения в плодотворности идеи общей архитектуры RISC, тем не менее, ее разработка шла быстро. Основная роль здесь принадлежала Энди Уоттренгу (Andy Wottreng) и Майку Кор-ригану (Mike Corrigan). Они выполнили выдающуюся работу по интеграции технических требований AS/400 в новую архитектуру. В результате, впервые была создана архитектура RISC, которая одинаково хорошо подходила и для коммерческих, и для технических приложений.
За координацию проекта отвечал Дэррил Соли (Darryl Solie). Он находился в тесном контакте с обеими группами разработчиков в Остине и Рочесте-ре и обеспечивал взаимодействие между ними. Проектировщики Рочестера многому научились у инженеров других подразделений IBM и Motorola. Уровни производительности процессоров, которые сперва казались недостижимыми, внезапно становились возможными. В результате, сейчас в Рочес-тере создаются одни из самых быстрых процессоров в мире. Наша лаборатория отвечает внутри IBM за разработку новых 64-разрядных процессоров для коммерческих вычислений.
Всякий раз, когда возникали трения, разгорались споры, и кто-нибудь начинал утверждать, что порочна идея в целом, в дело вмешивался Билл Берг (Bill Berg). Спокойно, дипломатично и быстро убеждал нас в том, что мы s на правильном пути, и что только мы можем пройти его до конца. Позднее Билл способствовал тому, чтобы убедить разработчиков использовать при создании программного обеспечения новой операционной системы объектно-ориентированные технологии.
Архитектура PowerPC должна была работать как в 32-разрядном, так и в 64-разрядном режимах. Все 64-разрядные версии PowerPC должны были иметь и 32-разрядное подмножество. Мы сосредоточились только на 64-разрядном режиме, практически не изменив 32-разрядное подмножество.
По мере разработки новой архитектуры мы могли предварительно оценить ее стоимость. Работа велась напряженно и была завершена за 90 дней, но результаты не слишком впечатляли.
Многие из необходимых нам архитектурных изменений было бы трудно внести в ранние версии процессоров PowerPC, разработанные в Сомерсете. Процессоры поздних моделей AS/400 должны были обрабатывать очень большие объемы данных, и для нужной производительности требовались очень широкие шины данных. Мы даже не пытались ничего добавлять в конструкции процессоров PowerPC 601, 603 или 604, так как они поддерживали только 32-разрядный режим. Было также крайне сомнительно, сможем ли мы усовершенствовать первый разработанный в Сомерсете 64-разрядный процессор (его окончательное название s 620), так как плотность упаковки элементов на этом кристалле была недостаточна для того, чтобы сделать его подходящим для наших моделей — пришлось бы разработать многокристальную версию архитектуры.
Даже в отношении младших моделей AS/400 у нас не было полной ясности. Некоторое время мы предполагали применить усовершенствованный вариант 620, который мы назвали 621, но в конце концов решили, что проще всего разрабатывать процессоры для AS/400 внутри IBM.
Одновременно с нами разработчики RS/6000 также пришли к заключению, что не смогут использовать ранние версии процессоров PowerPC в своих старших моделях. Для младших моделей подходил однокристальный процессор разработанный в Сомерсете, но для более высокопроизводительных моделей требовался многокристальный процессор. Кроме того, наши коллеги хотели включить в свой проект некоторые коммерчески выгодные возможности технических вычислений, а именно, NIC (numerically intensive computing), большинство из которых отсутствуют в обычном PowerPC. Также было добавлено больше конвейеров и новые вычислительные команды. Созданное в результате расширение первоначальной архитектуры POWER получило название POWER2.
Впервые процессоры архитектуры POWER2 были применены в RS/6000 в 1993 году. Они также использовались в RS/6000 Scalable POWERparallel System (RS/6000 SP). Последняя система ознаменовала выход IBM на рынок компьютеров параллельных вычислений. В RS/6000 SP может работать параллельно много таких процессоров. Параллельные машины очень хороши для ряда научно-технических и некоторых коммерческих приложений, например, для просмотра больших баз данных.
Первоначально архитекторы AS/400 и RS/6000 хотели добиться общей конструкции процессоров, решив включить в архитектуру Amazon все необходимые для них расширения. Мы планировали создать один процессор, который мог бы поддерживать специфические требования обеих систем.
У первого общего процессора PowerPC, предназначенного как для AS/400, так и для RS/6000, было несколько названий. Разработчики RS/6000 часто называли его POWER3, или PowerPC 630. Мы дали ему внутреннее имя Belatrix. Беллатрикс s это звезда в созвездии Ориона. Немногие знают, что ее называют также звездой Амазонки (Amazon Star). Belatrix должен был стать звездой архитектуры Amazon.
Как и многие предыдущие проекты, проект Belatrix был слишком амбициозным и всеохватывающим и не имел успеха. Мы решили, что целесообразнее иметь несколько версий процессоров PowerPC, оптимизированных для разных вычислительных сред. Каждый процессор PowerPC должен был реализовывать базовый набор команд и функций, а также поддерживать необязательные расширения.
Рочестер должен был сделать первые процессоры PowerPC применимыми для коммерческих задач. Первоначально они предназначались исключительно для AS/400.
Позже было принято решение: начиная с 1997 года использовать новое поколение 64-разрядных процессоров PowerPC, разработанных в Рочестере, и для RS/6000.
После прекращения работ над Belatrix в Остине начали разработку новой версии 630 — 64-разрядного процессора PowerPC, который должен был обеспечить вычислительную производительность, необходимую для будущих систем. Мы в Рочестере также стали разрабатывать свою версию Belatrix, которая предназначалась для серии AS/400 1998 года. Так как Belatrix назван по имени звезды, а Миннесота известна как штат Серверной звезды (North Star), то мы назвали новый процессор Northstartitle="">[ 16 ].
В области программного обеспечения ситуация с PowerPC была гораздо хуже, по сравнению с тем, что мы обещали Кюлеру. Все прикладное и системное программное обеспечение, работавшее поверх MI, было защищено благодаря независимой от технологии архитектуре AS/400. Однако, поскольку PowerPC сильно отличается от IMPI, то микрокод, расположенный ниже MI, было необходимо переделать под новый процессор. Это нелегкая задача, несмотря на то, что часть ее можно было осуществить с помощью автоматизированных средств. Между тем наши программисты должны были заниматься выпуском новых версий AS/400. Мы подсчитали, что для работы с RISC-процессором потребуется нанять несколько сотен новых системных программистов.
Наконец, мы были ограничены по времени. Первоначально планировалось выпустить новые процессоры C-RISC в середине 1994 года, мы уже мечтали о них для Advanced Series. При использовании PowerPC нам пришлось бы изменить планы и передвинуть выпуск RISC-процессоров на 1995 год s именно столько времени потребовалось бы для разработки нужных расширений и переписывания внутреннего кода. Пришлось бы оснащать Advanced Series процессорами IMPI и обеспечить возможность их модернизации процессорами PowerPC, когда последние будут готовы.
В начале июля 1991 года мы вновь нанесли визит Джеку Кюлеру. Большинство из нас полагали, что он поблагодарит за проделанную работу, сделает вывод, что переход на процессор PowerPC будет слишком дорогим и отправит обратно заниматься созданием C-RISC. Но Кюлер ничего такого не сделал. Вместо этого он попросил нас ускорить работу и предоставил необходимые для этого ресурсы. Так, внезапно для нас, пришлось полностью изменить направление работ над Advanced Series как в области аппаратного, так и программного обеспечения.
В конце июля мы завершили реорганизацию лаборатории для работы над новой системой. Ответственность за разработку новой модели процессора, названной Muskie, была возложена на Рочестер. Этот многокристальный процессор был предназначен для коммерческих вычислений на очень больших компьютерах. Разработка младших моделей серии AS/400 была переведена в лабораторию IBM в Эндикот-те. Эта линия получила наименование Cobra, и ее процессоры должны были быть однокристальными и полностью 64-разрядными.
Как уже упоминалось, первоначально мы планировали только 64-разрядный режим процессора. В конце концов, AS/400 не использует 32-разрядный режим, да и никто более не собирался использовать ранние 32-разрядные процессоры, так что реализовывать эту архитектуру в полном объеме, как нам казалось, не имело смысла. Но примерно через год, когда стало ясно, что AS/400 необходимо поддерживать все прикладное программное обеспечение, написанное для процессоров PowerPC, это решение было изменено. Поскольку большая часть таких программ написана для 32-разрядных процессоров, то и нам пришлось включить во все свои процессоры 32-разрядное подмножество. Это также должно было обеспечить возможность использовать наши новые PowerPC на других системах IBM.
Одновременно активизировалась работа по переносу микрокода AS/400 на новые процессоры. Это была возможность ревизии внутренностей операционной системы AS/400, чего не делалось с момента разработки System/38. Поскольку мы собирались перекраивать самые основы, то было решено идти до конца и использовать новейшие объектно-ориентированные методологии программирования. Мы планировали получить самую современную операционную систему.
 За организацию работ по переделке основ операционной системы отвечал Майк Томашек (Mike Tomashek). Майк знал, что у него нет ни людей, ни W опыта для того, чтобы уложиться в отведенные сроки. Любой здравомыслящий человек подтвердил бы, что это невозможно. Вместе с ключевыми раз-1 работчиками, такими как Билл Берг и Крис Джонс (Chris Jones) Майк разработал план. Им было нужно нанять сотни новых людей, обучить их объектно-ориентированным технологиям и переписать важнейшие части операционной системы AS/400 за короткие сроки. Майк не потратил много времени на раздумья и дебаты. Он просто объявил, что план сработает, и на полной скорости двинулся вперед.
В конце 1991 мы начали массовый найм программистов. В ряде крупнейших газет Америки стали появляться объявления о том, что в Рочестере требуются системные программисты с опытом работы на С++. Нам удалось быстро нанять несколько сотен новых программистов. Тогда многие обозреватели удивлялись, для чего нам это понадобилось, но теперь они знают.
Прежде чем перейти к более подробному рассмотрению архитектуры PowerPC, хочу напомнить о нашей «перечной» системе рейтинга. Оставшаяся часть этой главы — лишь для тех, кому нужны дополнительные подробности. Обратите внимание, что когда мы начнем обсуждение реализации процессора, материал станет еще «острее». Если «попробовав этой информации Вы найдете ее «чересчур», просто пролистайте книгу, пока не дойдете до тех разделов, где меньше специй.
За организацию работ по переделке основ операционной системы отвечал Майк Томашек (Mike Tomashek). Майк знал, что у него нет ни людей, ни W опыта для того, чтобы уложиться в отведенные сроки. Любой здравомыслящий человек подтвердил бы, что это невозможно. Вместе с ключевыми раз-1 работчиками, такими как Билл Берг и Крис Джонс (Chris Jones) Майк разработал план. Им было нужно нанять сотни новых людей, обучить их объектно-ориентированным технологиям и переписать важнейшие части операционной системы AS/400 за короткие сроки. Майк не потратил много времени на раздумья и дебаты. Он просто объявил, что план сработает, и на полной скорости двинулся вперед.
В конце 1991 мы начали массовый найм программистов. В ряде крупнейших газет Америки стали появляться объявления о том, что в Рочестере требуются системные программисты с опытом работы на С++. Нам удалось быстро нанять несколько сотен новых программистов. Тогда многие обозреватели удивлялись, для чего нам это понадобилось, но теперь они знают.
Прежде чем перейти к более подробному рассмотрению архитектуры PowerPC, хочу напомнить о нашей «перечной» системе рейтинга. Оставшаяся часть этой главы — лишь для тех, кому нужны дополнительные подробности. Обратите внимание, что когда мы начнем обсуждение реализации процессора, материал станет еще «острее». Если «попробовав этой информации Вы найдете ее «чересчур», просто пролистайте книгу, пока не дойдете до тех разделов, где меньше специй.
 Архитектура PowerPC
Архитектура PowerPC
Архитектура PowerPC обладает всеми обычными характеристиками архитектуры RISC: команды фиксированной длины, операции регистр-регистр, простые режимы адресации и большой набор регистров. Но есть и характеристики, отличающие ее от
других.
Как уже упоминалось, архитектура PowerPC — полностью 64-разрядная с 32-разрядным подмножеством. Она допускает как 32-разрядные, так и 64-разрядные версии процессоров PowerPC, но все они должны поддерживать, как минимум, 32-разрядное подмножество. Архитектура определяет переключатель режима 32/64, которые может использоваться операционной системой, чтобы позволить 64-разрядному процессору выполнять 32-разрядные программы.
В основе набора команд лежит идея суперскалярной реализации. В суперскалярном процессоре за один такт несколько команд могут быть распределены на несколько конвейеров. Аппаратура процессора просматривает поток команд и отправляет на выполнение максимально возможное число независимых команд (обычно от двух до четырех за цикл). Эти команды могут далее выполняться параллельно и даже завершиться в порядке, отличном от первоначального. Такой дополнительный параллелизм может значительно увеличить общую производительность процессора.
Команды направляются одновременно в три независимых исполняющих блока. Общая структура PowerPC показана на рисунке 2.3: блок переходов, блок фиксированной точки и блок плавающей точки. Также показан кэш команд[ 17 ], кэш данных, память и пространство ввода-вывода, которое в данной архитектуре выглядит как часть памяти.
 Рисунок 2-3 Модель архитектуры PowerPC
Рисунок 2-3 Модель архитектуры PowerPC
Для каждого исполняющего блока архитектурой определен независимый набор регистров. Любая определенная архитектурой команда может выполняться только одним типом управляющих блоков. Таким образом, у каждого блока собственный набор регистров и собственный набор команд. Эти исполняющие блоки часто называют процессорами, так как им присущи все характеристики процессора. Можно считать, что процессор PowerPC содержит три отдельных процессора s исполняющих блока. При этом каждый исполняющий блок может иметь несколько конвейеров команд. Если, например, для модели, оптимизированной для вычислительных задач, важна производительность операций с плавающей точкой, то блок плавающей точки может содержать два и более конвейеров и, таким образом, выполнять более одной команды плавающей точки одновременно. То же самое верно и для двух других блоков. В принципе, возможно создать процессоры PowerPC, способные выполнять пять и более команд одновременно. Преимущество такой схемы не только в одновременном выполнении нескольких команд, но также и в минимальной необходимости взаимодействия и синхронизации между блоками, что достигается благодаря наличию у каждого блока отдельных ресурсов. Исполняющие блоки могут подстраиваться под изменяющийся поток команд, позволять командам обгонять друг друга и завершаться в ином порядке. Другая характеристика архитектуры PowerPC, отличающая ее от обычного RISC-процессора s использование нескольких составных команд. Самой большой недостаток RISC по сравнению с CISC — увеличение объема кода. Для выполнения одной и той же программы RISC требуется больше команд, чем CISC. Составные команды позволяют уменьшить это разрастание кода. Некоторые из них очень просты, например, обновление регистра базы при загрузке и сохранении, что позволяет исключить дополнительную команду прибавления. Другие более сложны, например, команды множественной загрузки и сохранения, позволяющие перемещать значения нескольких регистров одной командой. Есть также команды загрузки/сохранения цепочек, которые позволяют загружать и сохранять произвольно выровненную цепочку байтов. Фанатики CISC узнают в последней паре команд не слишком хорошо замаскированные команды пересылки символов. Ортодоксы RISC негодуют и обвиняют архитекторов PowerPC в том, что они «продались» сторонникам CISC. На самом же деле, надо просто понять, что в реальности некоторые операции, такие как пересылка невыравненных строк байтов, происходят достаточно часто и требуют определенной оптимизации. Если составная команда дает то, что нужно, даже нарушая при этом какое-то неписаное правило «чистого» RISC, то пусть так и будет. Составные команды не означают возврата к архитектуре CISC, однако их применение в RISC-процессорах лишний раз доказывает, что в мире нет ничего абсолютно белого или черного. Интенсивное применение суперскалярных возможностей и использование составных команд составляют философию проектирования архитектуры PowerPC. Эта философия используется также и другими архитектурами, такими как Sun SuperSPARC и Motorola 88110. Есть мнение, что такая сложность затрудняет достижение процессорами высоких тактовых частот, обычно измеряемых мегагерцами (МГц). Сторонники этой точки зрения полагают, что большая производительность может быть достигнута скорее за счет высокой тактовой частоты, а не интенсивного параллелизма на уровне команд. Что такое МГц? В последние годы стало популярным выражать производительность микросхемы процессора ЭВМ с помощью этой единицы измерения. Для простоты восприятия, ее можно соотнести с оборотами в минуту автомобильного двигателя: эта величина показывает, насколько быстро вращается двигатель автомобиля, или сколько оборотов в минуту совершает коленчатый вал. Скорость процессора можно рассматривать как число тактов, которое он может выполнить в секунду. За один такт процессор обычно может выполнить одну простую команду, так что иногда данная величина воспринимается как приблизительное число команд, выполняемое процессором в секунду. Физическая единица герц (Гц) получила свое название в честь немецкого физика и равна одному циклу в секунду. Один мегагерц (Mrii)s это миллион циклов в секунду. Философию высокой тактовой частоты можно проиллюстрировать и примерами архитектур Digital Alpha, HP PA-RISC и MIPS R4000. Возьмем, например, PA-RISC 1.1. Этот процессор обычно выполняет две команды за такт. Менее мощные модели PowerPC могут за такт исполнять три команды, тогда как старшие модели s четыре и более. Этот дополнительный параллелизм дает PowerPC выигрыш в производительности, хотя и за счет увеличения сложности, что может снизить тактовую частоту. Спор о том, какая из этих двух точек зрения лучше, продолжается. Противоборствующие лагеря условно можно назвать «Speed Daemons» (высокая тактовая частота) и «Brainiacs» (сложность). Суть вопроса в том, что тактовая частота, измеряемая мегагерцами, не всегда адекватно отражает общую производительность процессора. 150 МГц Brainiac может легко превзойти по производительности 300 МГц Speed Daemon. Все зависит от выполняемой программы и степени параллелизма команд, которой может достичь компилятор. Некоторые новости указывают на то, что чаша весов склоняется на сторону архитектур Brainiac, таких как PowerPC. Судя по описанию, новая архитектура HP, получившая название PA-RISC 2.0, выглядит так, словно ее создатели поддались зову сирены сложности. Так как архитектура PA-RISC 2.0 остается процессор- ориентированной, то как объявлено HP, 64-разрядные приложения для новой аппаратуры появятся примерно через 3-5 лет.
 Расширения архитектуры PowerPC
Расширения архитектуры PowerPC
Так как первое поколение процессоров PowerPC создавалось специально под AS/400 и не было PowerPC в полном смысле, мы решили дать этим процессорам новое название s PowerPC Optimized for the AS/400 Advanced Series, но так как это труднопроизносимо, решено было остановиться на более кратком варианте s PowerPC AS. Большинство расшифровывают AS как Advanced Series, но многие из нас предпочитают считать, что это Amazon Series. Во втором поколении наших процессоров, представленном в 1997 году, мы реализовали и полную архитектуру PowerPC, и все расширения. Так как те же самые процессоры используются RS/6000, то обозначение AS более не имеет смысла. Самое существенное новшество архитектуры для AS/400 — использование тегов памяти (memory tags), которые будут подробно рассмотрены в главе 8. А вкратце мы поговорим об этом прямо сейчас.
В System/38 была реализована концепция одноуровневой памяти. Проще говоря, вся память, включая дисковую, представляет собой большое единое адресное пространство. Нам был необходим эффективный механизм защиты памяти от пользователей, не имеющих права доступа к ним. В MI адресация выполнялась с помощью 16-байтовых указателей. Указатель содержит некоторый адрес, и пользователь может этот адрес изменить (подробнее об этом будет рассказано в главе 5). Поскольку адрес после изменения может указывать на любую область памяти, необходимо предотвратить неавторизованные изменения адресов пользователями.
С каждым словом памяти System/38, имеющим 32 разряда данных, связан специальный бит защиты памяти, называемый битом тега (tag bit). Указатель MI занимает четыре таких слова. Всякий раз, когда операционная система сохраняет в четырех последовательных словах памяти указатель, аппаратура включает (устанавливает в 1) четыре бита тега, для индикации того, что указатель содержит адрес, допустимый для данного пользователя. Если пользователь изменяет в памяти любую часть указателя, то аппаратура выключает (устанавливает в 0) бит тега. Если хотя бы один из битов тега сброшен, то адрес в указателе неверен и не может быть использован для доступа к памяти.
В целях безопасности бит тега не может быть одним из битов данных внутри слова, так как последние пользователь может видеть и изменять. Он должен быть скрытым, то есть храниться в недоступной пользователю области памяти, но где именно?
System/38 использует для каждого слова памяти биты кода коррекции ошибок. Содержащая их часть памяти невидима программам, работающим поверх MI. Мы решили добавить к битам кода коррекции ошибок еще один и использовать его как бит тега. При изменении слова памяти какой-либо пользовательской программой, процессор должен автоматически сбрасывать скрытый бит тега. Ведь если данное слово станет частью указателя, то тот будет неверным. Только микрокод расположенный ниже MI имеет команды для включения битов тега.
В памяти AS/400 также используются биты тега. Поскольку в архитектуре PowerPC таковые не предусмотрены, нам пришлось добавить к ней режим активных тегов (tags-active mode). В этом режиме процессор «знает» о битах тега и будет сбрасывать их всякий раз, когда пользователь изменяет слово в памяти. Все процессоры AS/400 работают в режиме активных тегов. Существующие процессоры PowerPC используют режим неактивных тегов.
 65-разрядный процессор?
65-разрядный процессор?
В AS/400 ширина слова памяти возросла до 64 разрядов данных. С каждой восьмеркой байтов памяти AS/400 связан бит тега и указатель MI, занимающий два таких слова. В 1991 году нам виделись некоторые преимущества в том, чтобы хранить два теговых бита в регистрах новых RISC-процессоров, так же как и в памяти. Кроме того, мы хотели сократить размер указателей MI до 8 байтов. Внутри 16-байтовых указателей было неиспользуемое пространство, и казалось, что как раз настал подходящий момент сжать их.
Для того чтобы хранить такие тегированные указатели в регистрах, размер целочисленных регистров нужно было увеличить до 65 разрядов. Мы разрабатывали описанную схему около года, но в 1992 году отказались от нее и вернулись к решению, хранить теги только в памяти. На то было три основных причины. Во-первых, изменение размера указателя влияло на OS/400 и требовало слишком многих модификаций ее кода. Во-вторых, такой подход ограничивал будущие расширения размера адреса 64 разрядами. И третье, самое важное — процессоры в режиме активных тегов оказались бы несовместимы с набором команд PowerPC.
Первоначально мы не считали совместимость с PowerPC важной. Будущие процессоры, реализующие режим неактивных тегов, где 65-й разряд игнорируется, были бы полностью совместимы с PowerPC. А реализация 32-разрядных команд в режиме активных тегов и соответствующее программное обеспечение не планировалась даже в начале проекта. Ведь предполагалось, что этот режим будет использоваться только операционной системой AS/400, которая имеет дело с 64-разрядными командами.
Затем, когда было решено поддерживать совместимость с набором команд PowerPC, мы избавились от 65-го разряда в процессоре. Тогда намечалось некое слияние операционных систем IBM (см. Приложение). В рамках этого проекта предполагалось и программное обеспечение, большая часть которого предназначалась для 32-разрядного процессора. Поэтому мы обеспечили поддержку 32-разрядного набора команд всеми процессорами даже в режиме активных тегов. Наши процессоры второго поколения имеют режимы как активных, так и неактивных тегов и могут исполнять все прикладное и системное ПО PowerPC.
Хотя мы вернулись к 64-разрядным процессорам уже много лет назад, даже в IBM есть люди, по-прежнему упоминающие 65-разрядные, которые так никогда и не были созданы. Эта путаница возникает потому, что многие не знают, что собственно делает бит тега. Вероятно, если бы мы назвали его «битом защиты указателя в памяти» (pointer in memory protection), то не ввели бы в заблуждение столько народу. Но боюсь, тогда бы нам пришлось все время объяснять, зачем нам понадобился «бит pimp»[ 18 ].
 Система команд Amazon
Система команд Amazon
Архитектура PowerPC определяет привилегированные операции и команды, используемые только операционной системой и не предназначенные для прикладных программ. В AS/400 после специальных расширений этим «ведает» режим активных тегов. Например, механизм трансляции адреса должен поддерживать и одноуровневую память с единым адресным пространством, и обычную память с отдельным адресным пространством для каждого процесса. Мы используем режим активных тегов для того, чтобы приказать процессору использовать одноуровневую память. В режиме неактивных тегов процессор использует обычную трансляцию адреса PowerPC.
В состав других расширений AS/400 входят команды для работы с десятичными числами, некоторые новые команды загрузки и сохранения, а также расширения внутреннего регистра состояния процессора, предназначенные для оптимизации выполнения переходов. Мы не будем терять сейчас время на объяснение того, как эти команды используются в AS/400, а отложим это до следующих глав, где рассмотрим, как используется каждая из расширенных команд, более подробно.
А сейчас хочу привести некоторые цифры. Они помогут подытожить разговор об изменениях в архитектуре AS/400 и связанных с ними перспективах развития архитектуры PowerPC.
32-разрядная архитектура PowerPC определяет 187 команд, причем 11 из них — необязательные.
64-разрядная архитектура PowerPC определяет 228 команд (187 из 32-разрядного набора + 41 дополнительная), из них 21 — необязательная.
Архитектура Amazon определяет 253 команды (228 из 64-разрядного набора PowerPC + 25 дополнительных), из них 20 — необязательные. Заметьте, что 25 дополнительных команд доступны только в режиме активных тегов. Режим неактивных тегов поддерживает лишь 64-разрядный набор команд PowerPC. Но учтите, что определение любой архитектуры динамично и конкретные числа могут изменяться!
Реализации процессора AS/400
Первые использовавшиеся в AS/400 RISC-процессоры поддерживали только режим активных тегов и только структуру ввода-вывода AS/400. Поэтому они выполняли приложения, но не операционные системы, написанные для стандартного процессора PowerPC. Любая другая операционная система на одном из этих процессоров для таких функций как ввод-вывод должна пользоваться средствами, предоставляемыми операционной системой AS/400. (Подробнее об этом — в следующих главах). Последнее поколение RISC-процессоров для AS/400е поддерживает и режим активных тегов, и режим неактивных тегов, а, кроме того, обе структуры ввода-вывода одновременно. Они способны исполнять любую ОС для PowerPC и используются как в серии AS/400е, так и в RS/6000. Процессоры будущего сохранят эти характеристики.
 Процессоры Muskie первого поколения
Процессоры Muskie первого поколения
Процессор первого поколения, известный под названием Muskie[ 19 ], был разработан в Рочестере в 1995 году как старшая модель процессора для AS/400. На тот момент он был самым быстрым процессором PowerPC и самым быстрым микропроцессором IBM. Первоначально он имел время цикла 6,5 наносекунд, что соответствует тактовой частоте 154 МГц. В 1996 году мы представили еще более быстрые его версии со временем цикла 5,5 наносекунд (182 МГц).
Muskie явно предназначен для использования в системах коммерческих расчетов, а не в технических рабочих станциях. И хотя это не самая последняя наша разработка PowerPC, его стоит рассмотреть подробнее, чтобы понять различия между процес
сорами, предназначенными для коммерческих и научно-технических расчетов. Тогда станет ясно, почему было решено сконцентрировать усилия Рочестера на разработке процессоров для коммерческих вычислений (и для AS/400, и для RS/6000), тогда как Остин занимается процессорами для научно-технических расчетов.
Процессор Muskie — одномодульный, многокристальный, конвейерный, суперскалярный и предназначен для старших RISC-моделей AS/400. Это единственный многокристальный процессор семейства PowerPC. Процессор построен по четырех-канальной (4-way) суперскалярной схеме, то есть может выбирать и исполнять до четырех команд за цикл. Кроме того, поддерживаются и многопроцессорные конфигурации.
 Рисунок 2.4 Структурная схема процессора Muskie
Рисунок 2.4 Структурная схема процессора Muskie
Однокристальные процессоры обычно изготавливаются по технологии КМОП (комплиментарный метал-окисел-полупроводник). Микросхемы КМОП потребляют меньше мощности, чем микросхемы других технологий, то есть рассеивают меньше тепла. В результате, на одном кристалле может быть размещено больше транзисторов. Пока все схемы размещены на одном кристалле, маломощные цепи КМОП работают очень быстро. Иначе обстоит дело со связями между кристаллами. При использовании усилителей КМОП в многокристальном процессоре производительность уменьшается. Все шесть кристаллов Muskie используют технологию БиКМОП (Биполярный-КМОП). Биполярная технология имеет высокое быстродействие (в этом ее преимущество) и потребляет большую мощность. Недостаток БиКМОП — большое выделение тепла. Из-за объема рассеиваемого тепла биполярные кристаллы не могут использовать столь же высокую плотность упаковки, как кристаллы КМОП. Технология БиКМОП позволяет размещать на одном кристалле как биполярные цепи (для внешних усилителей), так и цепи КМОП (для схем внутри кристалла). Вместе со всеми вспомогательными схемами процессор Muskie занимает семь кристаллов. Последние упакованы в один многокристальный модуль, насчитывающий более 25 миллионов транзисторов. Один из кристаллов управляет вводом-выводом, то есть технически не является частью процессора. Прочие шесть кристаллов, составляющих процессор, вместе с соединениями между ними показаны на рисунке 2.4. БиКМОП отлично подходит для многокристального процессора. Например, известный Intel Pentium Pro выполнен в виде двухкристального модуля и использует технологию БиКМОП по тем же причинам, что и Muskie. Чтобы понять, почему для реализации данной технологии требуется так много транзисторов, рассмотрим микросхемы процессора подробнее. В состав шести основных кристаллов, составляющих процессор, входят кристалл процессорного блока PU (Processing Unit), кристалл блока плавающей точки FPU (Floating-Point Unit) и четыре одинаковых кристалла блоков управления основной памятью MSCU (Main Store Control Unit). На кристалле PU расположены кэш команд, блок переходов и блок фиксированной точки. Кэш команд размером 8 килобайт имеет ширину 32 байта. Он может выбирать из памяти за один такт 32 байта (8 команд[ 20 ]). Для передачи больших объемов данных за один такт имеются 32-байтовые тракты данных. Даже регистровый стек блока фиксированной точки рассчитан на загрузку или сохранение четырех 64-разрядных регистров за один такт. FPU размещается на отдельном кристалле и поддерживает стандарт IEEE для операций с плавающей точкой. Он спроектирован так, что способен выдавать результат в каждом такте, обеспечивая очень высокую производительность команд с плавающей точкой. Четыре команды за такт передаются от кристалла PU на кристалл FPU по 16-байтовой P-шине. Все данные, хранимые в памяти, также пересылаются из PU по P-шине в кэш данных. Данные для FPU выбираются из кэша данных со скоростью 32 байта за такт. Данные из FPU и PU пересылаются в кэш данных по 16-байтовой шине сохранения. MSCU содержит кэш данных, а также интерфейс памяти. Все четыре кристалла совместно реализуют 256-килобайтовый кэш данных и интерфейсы к шинам данных (см. рисунок 2.4). Обращения к кэшу данных выполняются конвейерно, так что за каждый такт считываются 32 и сохраняются 16 байт данных. MSCU поддерживает многопроцессорные конфигурации, обеспечивая когерентность кэшей разных процессоров. PU и FPU вместе насчитывают 5 конвейеров, однако в каждом цикле может быть распределено только 4 команды, а именно: команда перехода (включая операцию над содержимым регистра условия); команда загрузки/сохранения; команда арифметики с фиксированной точкой; команда фиксированной точки (логическая, сдвиг или циклический сдвиг; или команда плавающей точки). Команды плавающей точки исполняются в FPU, но не могут быть выбраны на выполнение одновременно с командами фиксированной точки для логических операций, сдвига или циклического сдвига, выполняемыми в PU. Обратите внимание, что конвейер загрузки/сохранения выполняет выборку и запись данных как с фиксированной, так и с плавающей точкой. Несколько конвейеров выполняют фрагменты нескольких команд одновременно. Процессор Muskie также может работать с разделяемой памятью, и таким образом поддерживает симметричное мультипроцессирование. Muskie первого поколения поддерживал конфигурации до 4 процессоров. Будучи самым быстрым RISC-процессором IBM своего времени, Muskie оптимизирован для нужд коммерческих вычислений. Для иллюстрации приведем некоторые характеристики. Системы и серверы для коммерческих расчетов должны обрабатывать огромные объемы данных. 16-байтовые (128 бит) и 32-байтовые (256 бит) шины позволяют Muskie справляться с этими задачами. Для сравнения: типичные 8-байтовые (64-разрядные) шины, используемые большинством высокопроизводительных RISC-процессоров, предназначены для рабочих станций, где объем обрабатываемых данных гораздо меньше. Кэш — обычно слабое место большинства RISC-процессоров, даже если система способна перемещать большие объемы данных. Для устранения этого недостатка в Muskie предусмотрен 256-килобайтовый кэш данных, работающий за один цикл. Поскольку команда перехода может вызвать простой конвейера, современные RISC-процессоры, подобно суперЭВМ, реализуют некоторую разновидность предсказания переходов. Для большинства RISC-процессоров точность предсказания переходов при выполнении технических задач составляет 80-90 процентов, благодаря тому, что в технических задачах процессор многократно повторяет последовательность команд тела цикла. Для программ подобного типа предсказание переходов работает отлично. В программах для коммерческих задач циклов гораздо меньше и точность предсказания переходов может быть ниже 50 процентов (это соответствует точности случайного выбора). Поэтому, вместо того чтобы пытаться угадать место перехода, Muskie выбирает команды из обоих мест перехода и начинает выполнять их. Данный метод, называемый спекулятивным выполнением (speculative execution), требует очень скоростного кэша (чем Muskie обладает), но зато позволяет достичь по сути стопроцентной точности на задачах любого типа. Еще один важный аспект коммерческих вычислений — высокие требования к целостности данных и коэффициенту готовности. Muskie реализует коды коррекции ошибок для всех связей за переделами кристаллов. Кроме того, большая часть логики управления и передачи данных на каждом кристалле также содержит различные схемы контроля. Типичный же RISC-процессор для рабочей станции вряд ли способен на что-либо подобное в области определения и исправления ошибок.
 Процессоры Cobra первого и второго поколения
Процессоры Cobra первого и второго поколения
Как и Muskie, процессоры Cobra имеют расширенную 64-разрядную архитектуру PowerPC. Они суперскалярные, что позволяет использовать параллелизм на уровне команд. Функционально оба семейства процессоров исполняют один и тот же набор команд уровня приложений. Некоторые различия между ними заключаются в реализации необязательных команд. Так Cobra предназначается для средних и младших моделей AS/400, поэтому реализация команд, поддерживающих, например, мульти-процессирование, в нем не предусмотрена.
Все четыре модели процессоров Cobra разработаны в Эндикотте. В системах AS/ 400, объявленных в 1995 году, используются Cobra-4 и Cobra-CR (CR расшифровывается как «cost reduced» — «цена уменьшена»). Cobra-CR — это Cobra-4, но с возможностью работать только на частоте 50 МГц, самой низкой для этого процессора[ 21 ].
Специально для тестирования нового программного обеспечения операционной системы команда проектировщиков в Эндикотте разработала вариант Cobra-0. Он никогда не применялся в AS/400.
Существовала также версия Cobra-Lite, названная так, поскольку в ней отсутствуют 17 обязательных команд PowerPC[ 22 ]. Ее разработала небольшая группа из Рочестера для системы Advanced 36, анонсированной в 1994 году.
При разработке процессоров Cobra ставилась задача объединить процессор и интерфейс памяти на одном кристалле, который, в результате, содержит 4,7 миллиона транзисторов. Интерфейс шины ввода-вывода располагается на отдельном кристалле, что позволяет использовать процессор с разными интерфейсами ввода-вывода. Cobra использует КМОП, а не БиКМОП, а точнее — технологию, названную IBM CMOS-5L. В результате, процессор рассеивает меньше тепла, чем Muskie, и меньше его нуждается в охлаждении. Только процессоры Cobra помещаются в корпуса небольшого размера, изготовленные для Advanced Series в 1994 году.
Подобно Muskie, Cobra имеет 5 конвейеров, но за один цикл может распределять не более трех команд (то есть выполнен по трехканальной суперскалярной схеме). Это команды:
перехода (включая команду регистра условия);
загрузки/сохранения;
арифметики с фиксированной точкой (включая логические команды, команды сдвига и циклического сдвига), или команда плавающей точки, или команда регистра условия.
Три конвейера (фиксированной точки, плавающей точки и команд регистра условия) совместно используют третий слот диспетчирования команд.
Первые процессоры Cobra работали на тактовых частотах 50 и 77 МГц, но их конструкция, как уже упоминалось, допускает и более высокие частоты. Для поддержания подобной скорости Cobra имеет 4-килобайтный внутренний (на кристалле) кэш команд и 8-килобайтный (также внутренний) кэш данных. По сравнению с Muskie, это не очень много. Большой кэш трудно разместить в однокристальном процессоре, поэтому процессоры, подобные Cobra, используют иерархию кэшей. Маленькие внутренние кэши (называемые кэшами первого уровня или кэшами L1) дополняются большим по размеру внешним кэшем (кэш второго уровня или L2). Cobra может работать с внешним (на отдельной микросхеме) кэшем L2 размером 1 мегабайт.
Процессоры третьего поколения Apache
Модели AS/400 1997 года используют новый дизайн процессора. Этот однокристальный процессор PowerPC, разработанный в Рочестере и названный Apache. Он предназначен для средних и старших моделей AS/400е. Младшие модели серии по-прежнему используют процессор Cobra. Apache можно считать процессором третьего поколения. В его основе — процессор Cobra, улучшенный и оснащенный новыми возможностями, например поддержки многопроцессорных систем. Apache — первый однокристальный процессор AS/ 400, которому по силам поддержка конфигурации SMP до 12 процессоров (даже Muskie поддерживал лишь четырехпроцессорные конфигурации). В отличие от Cobra или Muskie, Apache полностью реализует архитектуру PowerPC. Он использует режим активных тегов для поддержки одноуровневой памяти AS/400 и режим неактивных тегов — для поддержки стандартной модели адресации PowerPC; а также стандартные шины адреса и данных PowerPC 6хх — для соединений за пределами кристалла. Так что Apache можно использовать с любой вспомогательной микросхемой, разработанной для семейства процессоров PowerPC 6хх. (О том, как это позволило преобразовать структуру ввода-вывода компьютеров серии AS/400е мы поговорим подробней в главе 10). Apache — первый из когда-либо разработанных в Рочестере процессоров, который может использоваться вне рочес-терских систем. Процессоры Apache используются как в RS/6000, так и AS/400е. Рисунок 2.5 Структурная схема процессора Apache
Рисунок 2.5 Структурная схема процессора Apache
Как и Cobra, Apache — однокристальный, 64-разрядный суперскалярный RISC-процессор (его структурная схема — на рисунке 2.5). Он реализован по новейшей технологии IBM CMOS-5S, что позволяет достичь большей плотности упаковки на кристалле, а также времени цикла в 8,0 наносекунд (125 МГц), хотя в некоторых моделях AS/400е используются более медленные версии. Технология КМОП значительно сокращает объем рассеиваемого тепла, который нужно отводить от процессора. В результате, на одной плате может быть установлено до четырех процессоров Apache. В новом процессоре наиболее значительны изменения в подсистеме памяти. О том, как системы с Apache используют совершенно новую подсистему памяти, предназначенную для пересылки больших объемов данных без замедления работы, читайте в следующем разделе. Несмотря на то, что время цикла у Apache не столь мало как в Muskie, новая подсистема памяти повышает масштабируемость Apache для конфигураций SMP, что позволяет создать еще более производительные модели AS/400е. Прежде чем продолжить сугубо технический разговор, хочу представить вам новые корпуса, появившиеся вместе с процессорами Apache. Три оригинальных черных корпуса AS/400 Advanced Series (известные как Apex, Cedar Key и Key Largo) были заменены на два новых, также черных, корпуса (Millennium и Mako). Корпус для Advanced Entry (Eiger) остался тем же. Мы изменили дизайн корпуса по нескольким причинам. Средние модели серии AS/400 поддерживают конфигурации SMP. Корпус Millennium допускает установку до четырех процессоров Apache, а корпус Mako для старших моделей — до 12 процессоров. (В прежний корпус для старших моделей (Key Largo) помещалось до четырех процессоров Muskie). Корпус Mako гораздо выше (около полутора метров, напоминает оригинальные белые стойки AS/400) и кроме дюжины процессоров в нем есть место для большего объема основной памяти и большего числа дисков. Новые корпуса, которые предполагается использовать в серии AS/400е до 2000 года, были разработаны совместно с подразделением RS/6000 для оптимизации общности компонентов этих систем.
 О Процессоры четвертого и следующих поколений
О Процессоры четвертого и следующих поколений
Итак, мы рассмотрели процессор Muskie и то, каким образом он производит коммерческие вычисления, обрабатывая большие объемы данных. Четырехканальная суперскалярная архитектура, а также шины шириной 16 байт (128 бит) и 32 байта (256 бит) ясно свидетельствуют, что Muskie создан для обработки больших объемов данных и команд. А теперь представьте себе, процессор Muskie, упакованный вместе с набором 64-килобайтных кэшей для команд и данных в одну микросхему КМОП. Добавьте к этому полную архитектуру PowerPC процессора Apache и возможность поддерживать конфигурации с 12 или даже 16 процессорами. Что получилось? Конечно, это наш процессор четвертого поколения Northstar.
Сегодня можно уверенно сказать, что через несколько лет на первый план выйдут однокристальные КМОП-процессоры, помещенные в новые черные корпуса. Мы также знаем, что они будут использовать преимущества новой подсистемы памяти, впервые появившейся в Apache.
А впрочем, давайте отложим обсуждение процессоров будущего до главы 12. Там мы рассмотрим некоторые новейшие технологии, включая те, которые сегодня разрабатывает IBM для процессоров AS/400.
 О Подсистема памяти
О Подсистема памяти
Одна из самых больших проблем любого процессора — обеспечение его загрузки. За последние несколько лет производительность процессоров необычайно выросла, в среднем удваиваясь каждые два года. Производительность памяти и ввода-вывода не успевает за этими темпами.
В 1991 году я купил новую IBM PC для домашних нужд. В ней был установлен процессор Intel 386 20 МГц, 70-наносекундная память и жесткий диск с временем доступа 16 миллисекунд. Маломощный процессор 386 не долго меня устраивал; поэтому я, как и многие другие, начал бесконечную гонку за новейшей аппаратурой, приобретая последовательно системы с процессорами 486 и Pentium. В последнем купленном мною компьютере (который уже тоже устарел) установлены процессоры Pentium Pro 200 МГц, 60-наносекундная память и жесткие диски со временем доступа 8,5 миллисекунд.
Да, за последние несколько лет разрыв в скорости между процессором и памятью-вводом/выводом вырос невероятно. Теперь вполне возможна ситуация, когда память и ввод-вывод не смогут поставлять достаточно информации для поддержания загрузки процессора, и последний будет проводить множество своих высокоскоростных циклов в ожидании выборки команд или данных.
Универсальный прием для компенсации разницы в производительности между процессором и основной памятью — применение кэшей. Как мы уже говорили, кэш — это быстродействующая память, используемая для хранения блоков команд и данных, к которым процессор недавно обращался. При этом предполагается, что в ближайшем будущем процессор будет обращаться к тем же самым блокам.
Кэши эффективны благодаря тому, что большинство программ обладают так называемыми пространственной и временной локализацией. Это означает, что программа, скорее всего, обратится к команде или элементу данных, расположенным в памяти недалеко от места последнего обращения (пространственная локализация); а также что такой доступ произойдет через короткий отрезок времени (временная локализация). Нетрудно предположить, некоторые программы обладают большей степенью локализации, чем другие. Программа, предполагающая выполнение многих циклов или большой объем повторной обработки одних и тех же данных, имеет очень высокую степень локализации. Приложения для коммерческих расчетов, наоборот, выполняют мало обработки такого сорта, и имеют несколько меньшую степень локализации. Большие кэши и иерархия кэшей могут обеспечить загрузку процессора данными и командами даже при низких уровнях локализации.
При использовании иерархии кэшей происходит следующее: если нужная процессору информация отсутствует в кэше L1, процессор обращается к кэшу L2. Если информация не найдена и там, то происходит обращение к основной памяти. Пока идет поиск информации и выборка ее в регистр, процессор простаивает. Обычно это называют циклами простоя (stall cycles) процессора. В том случае, если информации нет даже в основной памяти и система должна обратиться к диску, процессор не ждет, а переключается на выполнение другой задачи в системе. Такую ситуацию обычно называют страничной ошибкой (page fault). Подробней мы поговорим об этом в главе 8.
Высокая производительность Muskie достигается с помощью небольшого 8-кило-байтного кэша команд L1 и 256-килобайтного кэша данных L1. Большой кэш данных реализован на четырех отдельных 64-килобайтных микросхемах памяти высокого быстродействия. Будучи однокристальными процессорами, Cobra и Apache имеют гораздо меньшие внутренние кэши L1 (4К и 8К для команд и данных соответственно). Эти внутренние кэши дополняются кэшами L2 большего размера, выполненными в виде отдельных микросхем. Часть производительности Apache достигается за счет очень больших кэшей L2 объемом от 4 до 8 мегабайт.
Несмотря на использование больших кэшей и иерархии кэшей, большинство процессоров все равно тратят много циклов простоя, ожидая выборки из памяти. Проблема заключается в шине между процессором и основной памятью. Большая часть систем, включая ранние AS/400, имеют одну такую шину, обычно высокоскоростную, но все равно работающую медленнее самого процессора. Например, мой Intel Pentium Pro 200 МГц работает с шиной памяти 66 МГц. Это означает, что при обращении к памяти процессор простаивает по три цикла на каждый цикл шины. Легко понять, что таких циклов простоя может быть много.
В конфигурации SMP ситуация может значительно ухудшиться. Теперь одну шину памяти и одну основную память пытаются задействовать несколько процессоров. Так как в данный момент времени шина может использоваться только одним процессором, то все остальные процессоры, которым она понадобилась в этот момент, обречены ждать. А если та же шина памяти используется еще и для ввода-вывода, положение еще более усугубляется.
Эта борьба за шину памяти приводит к уменьшению производительности при добавлении к системе SMP каждого нового процессора. Например, добавление второго процессора не позволит увеличить общую производительность на 100 процентов; фактическое увеличение будет несколько меньшим из-за борьбы за память. Добавление третьего и четвертого процессора еще сильнее сократит прирост производительности на один процессор. А когда дело дойдет до восьми и более процессоров, рост производительности системы SMP может и вовсе прекратиться.
 Организация памяти
Организация памяти
Давайте проведем краткий обзор организаций памяти для многопроцессорных систем. Нас интересуют три схемы организации памяти: централизованная разделяемая память, распределенная память ираспределенная разделяемая память.
Машина с централизованной разделяемой памятью предоставляет центральную память для использования всеми процессорами. Обычно, к такой разделяемой памяти подключены посредством одной шины несколько десятков процессоров. Подобная организация называется SMP (ее мы рассматривали выше). Преимущества SMP в том, что все процессоры используют общую память, и время необходимое для доступа к любой части этой памяти, для них одинаково. Поэтому конфигурации SMP часто называют машинами с однородным доступом к памяти UMA (uniform memory access). Недостаток SMP — в ограниченности максимально поддерживаемого числа процессоров.
В машинах с распределенной памятью последняя поделена между несколькими узлами, каждый из которых содержит несколько процессоров, соединенных с памятью узла как в SMP. Пример — кластер AS/400 OptiConnect (подробнее см. главу 6). Иногда машины с распределенной памятью называют архитектурами без разделения (shared-nothing), так как память не разделяется между узлами, а для связи между ними используется передача сообщений. Преимущество разделяемой памяти в том, что она может быть очень большой, если такое разделение памяти не требуется приложениям.
Если каждый процессор в машине с распределенной памятью может выполнять одну и ту же операцию или одну и ту же программу над множеством независимых друг от друга наборов данных, то подобная конфигурация называется процессором с массовым параллелизмом MPP (massively parallel processor). Пример — система MPP в IBM SP2, использующая по одному процессору на узел[ 23 ]. У SP2 также очень хороший механизм передачи сообщений, позволяющий процессорам быстро обмениваться информацией друг с другом. Системы MPP могут насчитывать тысячи процессоров; их недостаток в том, что такая архитектура полезна только для некоторых типов приложений, таких как параллельная обработка баз данных или научных вычислений (то есть там, где совместное использование данных не требуется).
Третья конфигурация — с распределенной разделяемой памятью, представляет собой вариант распределенной памяти. Здесь все узлы, состоящие из одного или нескольких процессоров, подключенных по схеме SMP, используют общее адресное пространство. Отличие этой конфигурации от машины с распределенной памятью в том, что здесь любой процессор может обратиться к любому участку памяти. Однако, время обращения к разным участкам памяти для каждого процессора различно в зависимости от того, где участок физически расположен в кластере. По этой причине такие конфигурации еще называют машинами с неоднородным доступом к памяти NUMA (non-uniform memory access). Мы рассмотрим NUMA в главе 12.
Это отступление от основной линии повествования здесь для того, чтобы помочь Вам, читатель, понять новую подсистему памяти, используемую сейчас в серии AS/ 400е. Эта подсистема разработана для конфигурации SMP, так как последняя наилучшим образом подходит для решения коммерческих задач, когда процессорам требуется использовать память совместно. Но Вы увидите, что она может использоваться и с другими конфигурациями памяти.
 Перекрестные переключатели
Перекрестные переключатели
В рамках начавшейся в 1995 году десятилетней программы ASCI (Accelerated Strategic Computing Initiative) министерство энергетики США DOE (Department of Energy) запросило у производителей компьютеров предложения по созданию самых мощных на сегодня ЭВМ. Задача ACSI — разработка «триллионных» компьютеров, которые могут быть использованы в том числе для моделирования ядерных испытаний. Предполагается, что триллионные (tera-scale) вычисления (таково официальное название для триллиона операций в секунду) будут широко применяться в коммерческих и научных приложениях в следующем столетии. Такие компьютеры создаются в трех национальных лабораториях DOE, связанных с проектом ASCI.
На первом этапе проекта ASCI — ASCI Option Red — рассматривалась большая конфигурация MPP с процессорами, организованными по традиционной модели распределенной памяти. Intel получил контракт на разработку компьютера с 9 072 процессорами Pentium Pro, 283 гигабайтами памяти и двумя терабайтами дискового пространства. Эта система имеет архитектуру MPP без разделения. Испытания новой системы происходили в национальной лаборатории Сандиа (Sandia), штат Нью-Мехи-ко. Ставилась задача — Сандиа (Sandia), «выжать» из единственного в своем роде компьютера, стоимостью в 55 миллионов долларов, триллион операций с плавающей точкой в секунду (один терафлоп). В декабре 1996 компьютер Intel DOE достиг этой цели.
DOE также хотело устранить ограничения двух распространенных многопроцессорных архитектур (SMP и MPP). Как мы уже говорили, системы SMP использующие шины, не масштабируются больше 32 процессоров, но отлично работают для большинства приложений. Схемы MPP сложнее в программировании и подходят только для некоторых классов приложений. Кроме того, их работа сильно замедляется при необходимости доступа к данным, разбросанным по системе. Поэтому DOE предложила новый проект масштабируемого SMP, названного ASCI Option Blue.
Контракты на создание этих систем к концу 1998 года получили две компании, чьи предложения были самыми обещающими: IBM и Cray Research, которая была приобретена SGI (Silicon Graphics Incorporated). Машина IBM названная ASCI Blue Pacific будет установлена в национальной лаборатории имени. Лоуренса (Lawrence) в Ливер-море (Livermore), штат Калифорния, а машина SGI/Cray, получившая имя ASCI Blue Mountain — в национальной лаборатории в Лос-Аламосе (Los Alamos), штат Нью-Ме-хико. Задача обоих компьютеров Option Blue — достичь производительности более 3 терафлоп.
В проекте IBM используются компактные узлы SMP с восемью процессорами; эти узлы соединяются с помощью переключателей передачи сообщений SP2. Проект SGI/
Cray более сложен и включает в себя комбинацию соединений и технологий операционных систем с целью создания образа единой SMP-подобной машины. И хотя физически данные будут распределены по системе, это будет архитектура NUMA.
Компьютер IBM ASCI Blue Pacific будет содержать 512 8-процессорных узлов SMP, 4 096 сверхвысокопроизводительных процессоров PowerPC. Процессор, предназначенный для версии Belatrix Остина, назван 630. Он имеет высокую производительность для вычислений с плавающей точкой и в точности соответствует типу проблем, решать которые призван компьютер DOE.
Для связи между узлами в ASCI Blue Pacific планируется новый высокоскоростной переключатель передачи сообщений типа SP2. Подсистема памяти, позволяющая процессорам внутри узла эффективно использовать память, будет использовать новый 128-разрядный перекрестный переключатель (cross-bar switch)[ 24 ]. Подсистема памяти на основе таких переключателей позволяет нескольким процессорам обращаться к памяти узла параллельно и обеспечивает конфигурацию UMA, где устранена проблема, присущая шине памяти в большинстве конфигураций SMP.
Я упомянул о проекте DOE для того чтобы рассказать о новой подсистеме памяти, используемой в узлах SMP ASCI Blue Pacific. Первая подсистема UMA, использующая 128-разрядный перекрестный переключатель, была разработана в Рочестере. Аналогичная схема используется в настоящее время в компьютерах SMP Apache. Вместо одной шины между памятью и кэшем второго уровня, как в предыдущих системах SMP AS/400, в Apache применены перекрестные переключатели. Благодаря поддержке нескольких параллельных обращений к памяти за один цикл, возможна пересылка больших объемов данных между кэшем и разделяемой памятью, что позволяет поддерживать загрузку процессоров в больших конфигурациях SMP.
Пример подобной конфигурации с двенадцатью процессорами Вы можете увидеть на рисунке 2.6. На одной плате — четыре процессора Apache вместе с четырьмя кэшами L2. В 12-процессорной конфигурации установлено три таких платы. Размещенные на платах кэши L2 размером 4 или 8 мегабайт обладают цикличностью в 8 наносекунд. Таким образом, за один цикл процессора между кэшем второго уровня и кэшем данных или команд первого уровня в микросхеме Apache может быть передано 16 байтов (см. рисунок 2.5).
Основная память в данной конфигурации может достигать 20 гигабайт, каждая плата памяти — содержать до гигабайта, так что на рисунке 2.6 показаны 20 таких плат. Обратите внимание на наличие четырех банков памяти с одинаковым числом плат в каждом, что позволяет обеспечить прослоенную память (memory interleaving) — технический прием, при котором открывается доступ к последовательным блокам данных памяти через разные банки. Например, если каждая плата памяти имеет 8-байтовый интерфейс, то одновременно из четырех банков памяти может быть считано 32 последовательных байта (байты 0-7 из банка 1, байты 8-15 из банка 2 и т. д.).
Четыре перекрестных переключателя подсистемы памяти UMA обеспечивают соединение между кэшами второго уровня и платами основной памяти. Три шины данных 6хх — по одной на каждую плату процессора — соединяют 12 процессоров с каждым из четырех переключателей. Эти 128-разрядные шины данных имеют время цикла 12 наносекунд (в полтора раза больше времени цикла процессора). Дополнительная шина данных 6хх соединяет с каждым из переключателей памяти подсистему ввода-вывода. У каждого переключателя — два независимых 128-разрядных интерфейса к платам памяти.
В подобной конфигурации в каждом цикле памяти к ней может осуществляться несколько параллельных обращений, что фактически устраняет проблемы, связанные с использованием одной шины памяти на традиционных системах SMP.
Имейте в виду, что здесь представлена лишь одна из возможных конфигураций соединения процессорных плат, переключателей и плат памяти. Другие модели линии AS/400 будут использовать иные комбинации этих компонентов. Например, в 4-процессорной конфигурации SMP может использоваться одна процессорная плата, два переключателя и четыре банка памяти.
Также, обратите внимание, что переключатели используются только линиями данных. Линии адресах всех кэшей второго уровня (показанные на рисунке как адресные линии 6хх) общие, что позволяет обычное отслеживание адресов, иначе называемое снупингом кэша (cache snooping) — прием, при котором каждый контроллер кэша L2 постоянно отслеживает все адреса, передаваемые по общей адресной шине. Кроме того, контроллеры проверяют, содержится ли адрес на шине в их кэше. Если это так, то соответствующие данные кэша становятся недействительными. Таким образом достигается когерентность информации во всех кэшах, ведь общие данные могут быть изменены одновременно не более чем одним процессором.
На рисунке 2.6 также показана общая подсистема ввода-вывода. Для подключения устройства расширения ввода-вывода к корпусу Mako, в котором размещается 12-процессорная конфигурация, используется SAN (System Area Network). Два таких интерфейса показаны на рисунке. В главе 10 мы рассмотрим использование SAN для поддержки разных интерфейсов ввода-вывода в AS/400е и соединения этих систем друг с другом.
 Рисунок 2.6 12-конфигурация SMP
Рисунок 2.6 12-конфигурация SMP
Итак, причина использования перекрестных переключателей — стремление повысить эффективность, или, иначе говоря, процентный рост производительности SMP при добавлении нового процессора в конфигурацию. Во многих системах с разделяемой памятью эта эффективность равна примерно 70 процентам при использовании от четырех до восьми процессоров.[ 25 ] Благодаря новой подсистеме памяти, процессоры Apache должны поднять эффективность до 85—90 процентов.
Будущее переключателей памяти
Если используются иерархии кэшей, то почему бы не использовать иерархии переключателей? Фактически, именно это и произойдет в будущем. Мы рассмотрели пример, где каждый процессор был соединен посредством шины 6хх с каждым из четырех переключателей. А ведь вместо этого можно установить на каждый четырех процессорный узел один переключатель, который, логично назвать контроллером узла. Такие контроллеры могут быть подключены к набору переключателей, которые, в свою очередь, подключаются к банку плат памяти. Можно также подключить контроллеры узлов к нескольким наборам переключателей, а каждый из этих наборов — к отдельным банкам памяти. Таким образом будет получена очень большая конфигурация SMP. Вспомните этот разговор после выхода четвертого поколения процессоров Рочестера! Вы еще не забыли про компьютер IBM ASCI Blue Pacific? В нем будет 512 процессорных узлов по восемь процессоров в каждом и подсистема памяти UMA на переключателях. Не следует ожидать в скором времени появления столь мощной версии AS/400, но разве не приятно осознавать, что такая конфигурация возможна, даже если и не очень практична? В конце концов, кодовым названием System/38 было Pacific[ 26 ], и мы действительно собирались создать по-настоящему большую систему. Ну что ж, посмотрим, как будут выглядеть рочестерские процессоры PowerPC следующего поколения...Выводы
Сегодня 64-разрядный процессор стал стандартом в компьютерной промышленности. Все RISC-процессоры AS/400 — современные, 64-разрядные, способные обеспечить функциональные возможности и производительность, необходимую для коммерческих систем и серверов. Мы считаем, что семейство RISC-процессоров PowerPC приведет AS/400 в следующее столетие.Глава 3
System Licensed Internal Code (SLIC) —сердце AS/400
Часто возникает некая терминологическая путаница: что, собственно, является операционной системой AS/400? Первое, что приходит в голову — ну, конечно, это Operating System/400 (OS/400); в конце концов, иначе ее не называли бы так. И все же такой ответ неверен. OS/400 нельзя признать операционной системой AS/400, так как в ней не предусмотрены большинство функций, присущих другим ОС. В главе 1 мы определили ОС как набор программ, управляющих системными ресурсами и предоставляющих базу для написания прикладных программ. Мы также оговорили, что законченный набор API для написания приложений для AS/400 — это MI, высокоуровневый машинный интерфейс. Таким образом, на вторую часть вопроса мы ответили. Осталось решить, где же находятся программы, управляющие системными ресурсами. И снова ответ «OS/400» будет неверен. Компоненты традиционной ОС выполняют такие функции как управление памятью, процессами, программами и вводом-выводом. Но, обычно, эти низкоуровневые функции сильно зависят от аппаратуры и тесно связаны с нижележащими физическими структурами. Например, компонент управления памятью должен «знать» точную конфигурацию и характеристики иерархии памяти. Независящий от технологии интерфейс MI не обладает этими качествами. Следовательно, управление памятью должно осуществляться ниже MI, OS/400 же, наоборот, расположена выше. Следовательно, ни одна из таких аппаратно-зависимых компонент не может быть в ее составе, этого не допускает основное условие задачи — независимость от технологии. Итак, благодаря расположению аппаратно-зависимых компонентов ниже MI, последний защищает прикладные программы и OS/400 от аппаратных изменений. ПО операционной системы, расположенное ниже MI, называется LIC (licensed internal code). Давайте еще раз взглянем на структуру AS/400. Теперь очевидно: OS/400 состоит из объектов и программ поверх MI, а LIC составляют структуры данных и программы ниже MI. Таким образом, LIC связывает MI и аппаратуру. Фактически, ОС AS/ 400 — сочетание OS/400 и LIC. Получается, что AS/400 представляет собой пирог, в котором OS/400 играет роль глазури, а LIC — начинки между слоями. В последние годы такую нижнюю часть ОС в других системах стали называть ядром. Есть много определений того, что именно относится к ядру операционной системы. Некоторые педанты могли бы сказать, что LIC содержит гораздо больше функций операционной системы, чем, обычное ядро. И все же термин ядро наиболее удобнен для описания функций ОС, реализованных ниже MI.Разделяй и властвуй
Очевидно, что некоторые компоненты ОС, такие как управление памятью, реализованы в LIC. Для других компонентов это не столь очевидно. Возьмем, например, базу данных. Некоторым ее частям необходима информация о физических дисковых устройствах и о пересылке данных в системе, другие же — могут быть написаны аппа-ратно независимо. Проектировщики обязаны решить, где разместить ПО базы данных — целиком в OS/400, целиком в LIC или и там, и там. Рискуя забежать вперед (подробно мы рассмотрим MI в главе 4) должен отметить, что, говоря о разделении на OS/400 и LIC, я имею в виду объекты MI, реализованные в LIC. Позже мы подробней остановимся на системных объектах MI, реализованных в LIC, и на объектах OS/400, реализованных только MI. Конечно, все функции OS/400 присутствуют в LIC в том смысле, что они должны использовать MI для обращения к аппаратуре. Но часто инструкция на ЯВУ после преобразования в соответствующую форму MI транслируется в команды PowerPC (или старого IMPI) напрямую, без каких-то особых структур данных или вызовов процедур LIC. Считать, что некоторая системная функция реализована OS/400, а не LIC, можно в тех случаях, если реализующий ее код видим OS/400 и необходимые структуры данных находятся в объектах OS/400 или в их видимых частях. На рисунке 3.1 показано распределение функций ОС между OS/400 и LIC. Некоторые функции, такие как управление планированием заданий, могут быть реализованы в основном в OS/400, так как мало зависят от аппаратуры. Другие, такие как поддержка устройств — частично в OS/400, а частично в LIC. Общие характеристики устройств могут поддерживаться OS/400. Например, информация о том, что устройство является принтером, не привязывает прикладную программу к конкретному принтеру. А вот информация о деталях потока данных принтера вызывает подобную привязку и должна использоваться в LIC, ниже MI. Рисунок 3.1 Распределение функций AS/400
Некоторые аппаратно-независимые функции ОС также реализованы ниже MI, например, защита. Эта функция не зависит от аппаратуры, и таким образом может быть осуществлена целиком в OS/400 поверх MI. Однако реализация части защиты ниже MI обусловлена требованиями безопасности. Подробнее о том, как осуществляется общесистемная защита в OS/400, а контроль доступа к системным ресурсам — в LIC, мы поговорим в главе 7.
Подобно защите, большинство функций ОС реализованы частично над, а частично — под MI. Даже отдельный компонент некоторой функции ОС может быть реализован по обе стороны этой границы. На рисунке 3.1 показаны некоторые компоненты базы данных и их распределение относительно MI.
Другая причина расположения некоторой функции или части ее ниже MI — производительность. Общий принцип таков: чем более функция аппаратно-зависима, тем лучше ее можно настроить для максимальной производительности. Реализация ниже MI не гарантирует повышение производительности для всех функций, но в некоторых случаях может помочь. Недостаток такого подхода — увеличение объема кода ОС, зависящего от аппаратуры.
Рисунок 3.1 Распределение функций AS/400
Некоторые аппаратно-независимые функции ОС также реализованы ниже MI, например, защита. Эта функция не зависит от аппаратуры, и таким образом может быть осуществлена целиком в OS/400 поверх MI. Однако реализация части защиты ниже MI обусловлена требованиями безопасности. Подробнее о том, как осуществляется общесистемная защита в OS/400, а контроль доступа к системным ресурсам — в LIC, мы поговорим в главе 7.
Подобно защите, большинство функций ОС реализованы частично над, а частично — под MI. Даже отдельный компонент некоторой функции ОС может быть реализован по обе стороны этой границы. На рисунке 3.1 показаны некоторые компоненты базы данных и их распределение относительно MI.
Другая причина расположения некоторой функции или части ее ниже MI — производительность. Общий принцип таков: чем более функция аппаратно-зависима, тем лучше ее можно настроить для максимальной производительности. Реализация ниже MI не гарантирует повышение производительности для всех функций, но в некоторых случаях может помочь. Недостаток такого подхода — увеличение объема кода ОС, зависящего от аппаратуры.
Микрокод
Ранее микропрограммирование было определено как технический прием, при котором программирование внутреннего компьютера служит цели эмуляции операций внешней вычислительной архитектуры. Соответствующее ПО часто называют микрокодом. В System/38 было два разделенных IMPI слоя микрокода ниже MI: горизонтальный микрокод HMC (Horizontal Microcode) и вертикальный микрокод VMC (Vertical Microcode)[ 27 ]. Самым низким уровнем был HMC, использовавший специализированный набор микрокоманд, исполняемый аппаратурой процессора непосредственно. Он содержал микропрограммируемый эмулятор, выполнявший команды IMPI. В состав HMC были также включены некоторые функции ОС самого низкого уровня. HMC был спроектирован так, чтобы обеспечить высокопроизводительный параллелизм работы процессора. Из-за этого ЯВУ для написания такого кода не существовало, а программирование было очень сложным и требовало много времени. Вторым слоем, расположенным под MI, но над IMPI, был VMC. В этом слое содержались те аппаратно-зависимые функции ОС, которые не были реализованы в HMC. VMC был написан частично на специализированном ЯВУ, разработанным внутри IBM для системного программирования, и частично на ассемблере IMPI. Он не был микрокодом в традиционном смысле; а представлял собой самый нижний уровень ПО ОС. Ядро операционной системы System/38 было названо микрокодом во избежание коммерческих проблем, типичных для 60-х годов. Тогда среди компьютерных гигантов, включая IBM, была распространена следующая практика: связывать получение системного ПО с требованием покупать фирменную аппаратуру. Так продолжалось до тех пор, пока различные фирмы ни создали множество компьютеров, совместимых с мэйнфреймами IBM (сегодня, мы назвали бы их клонами), для продажи по более низкой цене. Производители совместимой аппаратуры получали прибыль только в том случае, если бы покупатели могли приобретать ОС IBM без аппаратных средств. Под угрозами судебных преследований IBM согласилась в будущем не привязывать ПО к своим компьютерам. С System/38 проблема связанных продаж ПО и аппаратуры возникла вновь. Мы хотели получить систему, единственным внешним интерфейсом которой был бы MI. Если бы мы продавали только аппаратные средства, то потеряли бы обеспеченную MI независимость от технологии. Для выхода на рынок годился только законченный машинный продукт MP (Machine Product), который бы содержал аппаратные средства плюс ядро ОС. Чтобы выйти из положения, ядро назвали микрокодом, позаимствовав этот термин у разработчиков проекта IBM Future Systems, которые еще в начале 70-х также пытались объединить некоторые функции ПО с аппаратурой. Так как микрокод рассматривался как часть аппаратуры, то тем самым мы не нарушали соглашения и были чисты перед законом. Все затраты по разработке VMC должны были быть отнесены на аппаратные средства. По тем же соображениям для написания VMC необходимо было создать проектную организацию, отдельную от группы программирования. Именно этим и объясняются разные названия сходных функций и структур в OS/400 и VMC (см. последующие главы). С появлением AS/400 названия двух слоев микрокода были изменены. Сегодня наши заказчики могут покупать аппаратное, но не программное обеспечение. Вместо этого они приобретают лицензию на использование ПО (иногда — только для определенной системы) и не могут изменять, копировать или перепродавать его, если это не разрешено лицензией. Микрокод же — часть аппаратуры, а следовательно, покупатель может владеть им. Так как при объявлении AS/400 вопрос о связывании более не стоял (сегодня мы продаем даже OS/400 в едином комплекте с аппаратурой), то IBM решила переименовать микрокод System/38. Таким образом, у AS/400 имеется вертикальный LIC VLIC (Vertical Licensed Internal Code) и горизонтальный LICHLIC (Horizontal Licensed Internal Code). С появлением новых RISC-процессоров потребовалось еще одно изменение названия. HLIC содержал микропрограммируемый эмулятор, необходимый для реализации IMPI. Так как у RISC-процессора микропрограммируемого эмулятора нет, то нет и HLIC, остается только VLIC. В связи с этим при переходе на RISC-процессоры, функции ОС, ранее выполняемые в HLIC, были переписаны для VLIC. И когда остался единственный слой внутреннего кода, мы с радостью отбросили, наконец, бессмысленные названия «вертикальный» и «горизонтальный».
Впереди скользкая дорога
Вопрос: Что содержит более трех миллионов строк кода, создано усилиями 200 программистов и имеет имя, вызывающее в памяти зимнюю дорогу в Миннесоте? Ответ: Внутренний код для систем с RISC-процессором — SLIC (System Licensed Internal Code). Хотя, несомненно, придумавшие это имя разработчики имели в виду значение слова slick на сленге («чудесный», «замечательный», «первоклассный»), а не свойства зимних миннесотских дорог[ 28 ]. Когда в 1991 году в Рочестере начались работы над RISC-процессором, потребовалось внести множество изменений в LIC, расположенный под MI. Некоторые компоненты (но не все!) должны были быть полностью переработаны. Большая часть существующего LIC также требовала реструктуризации. Этот код уже претерпевал частые изменения и модернизации при создании новых моделей System/38 и AS/400. Из-за множества изменений производительность работы программистов над этой частью системы уменьшалась, а расходы на сопровождение росли. Моральный дух наших программистов, постоянно латавших старый код, тоже падал. До перехода на RISC-процессоры нам нужно было еще выпустить три новых версии VLIC, из-за чего мы не могли полностью переключиться на SLIC. Поэтому для создания новой ОС было решено создать специальное подразделение во главе с Майком Томашеком. Входившие в его состав инженеры могли выбирать любые методы разработки по своему усмотрению. На совещании по выработке плана действий эта группа рассмотрела два подхода к модернизации LIC. Первый состоял в том, чтобы заново спроектировать и написать низкоуровневые компоненты, затронутые изменением процессора. Второй — переместить эти затронутые компоненты в аппаратуру RISC с минимальными изменениями. Данный тип миграции ПО без изменения логики работы программы часто называется переносом. Все остальные компоненты, не затронутые изменением процессора, такие как база данных, должны были быть перенесены с минимально возможными модификациями. Майк и его команда решили перепроектировать и переписать затронутые компоненты заново. Это было нелегким решением, так как большая часть низкоуровневого кода основывалась еще на первоначальном проекте System/38 и интенсивно настраивалась для повышения производительности в течение 15 версий системного ПО. Не все верили в успех: ведь предстояло полностью изменить лишь «начинку» переписываемых компонентов, оставив в неприкосновенности все интерфейсы, чтобы не затронуть переносимые компоненты. Кроме того, надо было учесть возможность расширений ПО в планируемых новых версиях AS/400. В общем, все это напоминало стрельбу по движущейся мишени. Билл Берг — один из десяти специалистов, рекомендовавших использовать PowerPC для AS/400, — продвигал идею сократить время разработки, использовав объектно-ориентированное программирование (ООП). Объектно-ориентированные языки приобрели популярность конце 80-х как способ быстрого создания программ и уже были достаточно совершенными, чтобы использовать их в таком большом проекте. Билл Армстронг (Bill Armstrong) и Дик Мастейн (Dick Mustain) — также твердые сторонники объектно-ориентированной разработки — были с ним согласны. Пол Мэттисон (Paul Mattison) собрал команду и подготовил план действий. Поддержка ключевых разработчиков также доказала, что новая технология программирования поможет обеспечить делу успех. Кроме того, мы собирались нанять новых людей.
Концепции объектно-ориентированного программирования
Давайте кратко рассмотрим основные элементы и термины ООП. Объект — это основной элемент программы, объединяющий в себе данные и операции над ними. Операция, которую может выполнить объект, иногда называется методом. Внутренняя структура данных и реализация методов объекта скрыта от остальной программы. Это называется инкапсуляцией. Программе доступен только интерфейс объекта. ООП отличается тем, что объединяет операции и данные воедино (при процедурном программировании операции отделены от данных). Подход ООП предполагает повторное использование ПО. Основной механизм обеспечения повторного использования — класс, представляющий собой шаблон, описывающий все объекты, для которых характерны одинаковые операции и элементы данных. Следовательно, может быть создано много объектов каждого из классов. Часто они называются экземплярами объекта. Для существующего класса можно создать подклассы путем использования наследования. Наследование позволяет программисту и создавать новые подклассы, и повторного использовать код, а также данные базового класса без их повторения. Вновь полученные подклассы настраиваются так, чтобы соответствовать конкретным потребностям приложения. Способность подклассов одного класса отвечать на одно и то же входящее сообщение по-разному называется полиморфизмом. Полиморфизм объединяет концепции наследования и динамического связывания (dynamic binding). Наборы объектов, созданные из классов и подклассов, могут быть объединены для построения необходимых сервисов ОС. После определения достаточно сложного набора классов (называемого библиотекой классов), программисты могут использовать классы этого набора, а не программировать заново функции, предоставляемые классами. Однако в объектно-ориентированной технологии есть и недостатки. Производительность ядра ОС чрезвычайно важна, так как сильно влияет на производительность системы в целом. Исследования приложений для AS/400 показали, что значительная часть длинных цепочек команд приходится на код ОС. А при применении объектно-ориентированной технологии для некоторой функции повторно используется большое число маленьких модулей, и общая длина цепочек команд увеличивается, по сравнению с реализацией той же функции как единого целого. Группе пришлось включить в план работ время для выполнения тонкой настройки таких функций, чтобы сохранить показатели производительности ядра, достигнутые за предшествующие годы его разработки[ 29 ].Среда разработки SLIC
Группа разработчиков должна была выбрать язык программирования. Язык программирования VLIC, называвшийся PL/MP и использовавшийся со времен разработки оригинальной System/38, был основан на языке PL/I. MP в его названии расшифровывается как Machine Product — имя, которое часто использовалось для обозначения аппаратных средств и обоих слоев микрокода. Компилятор PL/MP, как и ассемблер IMPI, генерировал двоичные машинные команды IMPI. Язык PL/MP не пригоден для ООП, но его по-прежнему использовали для тех компонентов, которые не переписывались. А для остальных был разработан новый компилятор PL/MP, генерировавший двоичный код для PowerPC. Кроме того, было создано специальное средство переноса программ, которое сканировало код, отыскивая зависимости от IMPI, прежде чем преобразовать его в новый PL/MP. В течение ряда лет мы пытались использовать другие языки при разработке компонентов VLIC. Например, один из наших новейших трансляторов был написан на Modula-2, применялся также язык С. Однако, мы чувствовали, что ни один из них не подходит для проекта, основанного на объектно-ориентированной технологии. Выбор напрашивался сам собой — язык C++. Нам нужно было разрабатывать код ОС очень низкого уровня. Иногда, для достижения оптимальной производительности приходилось прибегать к ассемблеру, и С+ + легче позволял это. Ведь, фактически, язык С++ и есть современный вариант ассемблера[ 30 ]. Другим преимуществом С++ была возможность легко найти людей, его знающих. Для этого проекта нам было нужно много новых программистов, и начался массовый найм. Скоро над проектом SLIC работало более 200 человек. Для успеха проекта обучения было крайне важно, чтобы вновь набранные сотрудники поскорее изучили внутреннее устройство AS/400[ 31 ], а наши старые работники — программировать на С++. Некоторые уже умели это, но большинство из них использовали С++, как улучшенный С. Нужно было научить каждого объектно-ориентированному подходу. Это стало настоящей проблемой, так как в Рочестере на тот момент не оказалось никого, кто зашел бы дальше прочтения нескольких книг по данной теме. Решение было предложено Крисом Джонсом. Согласовав свои действия с другими руководителями проекта, он нашел стороннего консультанта — эксперта как в объектно-ориентированной технологии, так и в программировании на С++. Никогда ранее мы не обращались «на сторону» по подобным поводам. У IBM были внутренние программы обучения, и персонал, который этим занимался. Разумеется, приглашение на работу чужака было воспринято в штыки. Крис настаивал и убедил-таки руководство нанять консультанта для интенсивного шестинедельного обучения наших сотрудников. Мы даже специально выгородили прямо посередине отдела разработки классную комнату, которая использовалась исключительно для обучения.
Возможность повторных итераций при разработке — фундаментальное преимущество ООП, но при ее использовании трудно оценить, в какой степени мы продвинулись вперед. Прием, который мы использовали для «измерения прогресса», заключался в так называемых BUB (Bring up Bind). Каждый BUB представлял собой группу объектов, реализовывавших четко определенный набор функций ОС, и имевшую общий интерфейс с другими компонентами. Путем сравнения BUB с другими компонентами, мы могли оценить, как продвигается разработка. Кроме того, BUB позволили нам действовать в определенном порядке, а также вызвали переделку известного рекламного лозунга Budweiser: «This BUB's for you»[ 32 ].
Технология ООП не подвела: производительность программистов при разработке SLIC повысилась почти в четыре раза по сравнению с традиционной методикой. В период с июля 1992 года, было создано более миллиона строк кода на С+ + и более 7 000 классов. Считая весь перенесенный код, ниже MI работает более 3 миллионов строк кода ОС.
Для успеха проекта обучения было крайне важно, чтобы вновь набранные сотрудники поскорее изучили внутреннее устройство AS/400[ 31 ], а наши старые работники — программировать на С++. Некоторые уже умели это, но большинство из них использовали С++, как улучшенный С. Нужно было научить каждого объектно-ориентированному подходу. Это стало настоящей проблемой, так как в Рочестере на тот момент не оказалось никого, кто зашел бы дальше прочтения нескольких книг по данной теме. Решение было предложено Крисом Джонсом. Согласовав свои действия с другими руководителями проекта, он нашел стороннего консультанта — эксперта как в объектно-ориентированной технологии, так и в программировании на С++. Никогда ранее мы не обращались «на сторону» по подобным поводам. У IBM были внутренние программы обучения, и персонал, который этим занимался. Разумеется, приглашение на работу чужака было воспринято в штыки. Крис настаивал и убедил-таки руководство нанять консультанта для интенсивного шестинедельного обучения наших сотрудников. Мы даже специально выгородили прямо посередине отдела разработки классную комнату, которая использовалась исключительно для обучения.
Возможность повторных итераций при разработке — фундаментальное преимущество ООП, но при ее использовании трудно оценить, в какой степени мы продвинулись вперед. Прием, который мы использовали для «измерения прогресса», заключался в так называемых BUB (Bring up Bind). Каждый BUB представлял собой группу объектов, реализовывавших четко определенный набор функций ОС, и имевшую общий интерфейс с другими компонентами. Путем сравнения BUB с другими компонентами, мы могли оценить, как продвигается разработка. Кроме того, BUB позволили нам действовать в определенном порядке, а также вызвали переделку известного рекламного лозунга Budweiser: «This BUB's for you»[ 32 ].
Технология ООП не подвела: производительность программистов при разработке SLIC повысилась почти в четыре раза по сравнению с традиционной методикой. В период с июля 1992 года, было создано более миллиона строк кода на С+ + и более 7 000 классов. Считая весь перенесенный код, ниже MI работает более 3 миллионов строк кода ОС.
Затраты на разработку SLIC
Создание вычислительной системы с высокоуровневым машинным интерфейсом и значительной частью ОС, расположенной под этим интерфейсом, было связано с определенными затратами. На разработку ПО пришлись основные расходы, связанные с AS/400. Давайте ненадолго остановимся и рассмотрим, почему так получилось. SLIC содержит 3 миллиона строк надежного кода. (Под надежным имеется в виду код, который всегда должен работать правильно, чтобы обеспечить целостность и защищенность системы.) Так как SLIC — ядро ОС, мы не защищаем один его компонент от другого. Это совершенно обычный подход: ядра большинства ОС защищены от кода, расположенного вне его, но весь код внутри ядра считается надежным. Если ядро невелико, скажем, состоит из 100 тысяч строк кода, то его целостность очень легко протестировать при каждом изменении. Если же строк 3 миллиона, то такое тестирование становится и сложнее, и дороже. Много лет мы в Рочестере использовали следующий подход: строго ограничивали круг тех, кому позволено работать с ядром, группой разработки и тестирования. Таким образом, код для SLIC могут написать заново только разработчики из Рочестера (впрочем, это достаточно большое число людей). Дополнительно надежность гарантируется тем, что разработчики действуют в условиях жесткой организационной структуры. У подобного подхода есть и свои недостатки. Неоднократно сторонние организации, включая другие подразделения IBM, запрашивали у нас разрешение написать функции для SLIC. Во всех случаях мы отвечали твердым отказом: если позволить кому-либо написать хотя бы малую часть SLIC, то это может нарушить целостность всей системы, чего мы не допустим. Но следствие такого подхода — то, что создание новых функций SLIC жестко зависит от возможностей наших программистов. Мы практически никогда не можем позаимствовать код у кого-либо еще в IBM, по крайней мере, не на уровне SLIC. В главе 4 мы рассмотрим, как компиляторы ЯВУ генерируют код PowerPC, исполняемый ниже MI. Мы увидим, что это требует использования компонента SLIC, известного как транслятор. Как и все компоненты SLIC, транслятор надежен, то есть должен всегда генерировать код, чтобы не нарушить целостность или защиту других компонентов системы. Трансляторы также разрабатываются только в подразделении SLIC в Рочестере. Хорошо, что все функции SLIC работают как единое целое. Так как весь SLIC разрабатывался под одной крышей, мы достигли уровня целостности, о котором можно только мечтать в системах, разработка которых ведется «кусками». Использование общих программных компонентов в разных ОС может значительно сократить затраты, но не даст той интеграции функций, которой обладает AS/400. Что касается общих компонентов, то как мы увидим в следующем разделе, и здесь существует возможность подключения без нарушения целостности.Технологии ядра в SLIC
В прошлом ядро каждой ОС было уникальным, мало кто брался разрабатывать ядро отдельно от ОС. Однако в середине 80-х годов положение стало меняться. В некоторых университетах, например, в Карнеги-Меллон (Carnegie-Mellon), начали изучение возможности использовать ядро с несколькими ОС. Именно там было спроектировано микроядро Mach, представляющее собой подмножество ядра, и выполняющее функции, необходимые большинству ОС. Если одно и то же микроядро лежит в основе двух или нескольких ОС, то возможно исполнять эти ОС параллельно на одном и том же процессоре. Более того, такие ОС могут очень эффективно разделять ресурсы и взаимодействовать друг с другом. В последние годы операционные системы, выполняющиеся поверх одного микроядра, стали называть индивидуальностями (personality). Так как SLIC разрабатывался в качестве нового ядра ОС, имело смысл включить в него технологии для поддержки множественных индивидуальностей. Фактически, большая часть такой поддержки уже имелась в оригинальном LIC. Например, для распределения процессора между ОС микроядро использует механизм передачи сообщений. Аналогичный подход использовался в оригинальной System/38 и был перенесен оттуда на AS/400. Подробно мы рассмотрим этот механизм в главе 9. В то время, когда мы разрабатывали SLIC, в IBM были проведены исследования в области применения общих компонентов ОС на всех системах IBM, включая использующие процессор PowerPC. Одним из основных предложений было — принять в качестве базовой модели микроядро IBM, сконструированное по принципам микроядра Mach. В SLIC уже имелось большинство технологий микроядра, но возникали сомнения: следует ли нам в качестве всеобщей основы использовать микроядро IBM?. Ответ был совершенно очевиден. Единственно существовавшим в то время было 32-разрядное микроядро. Чтобы использовать это микроядро для AS/400, нужно было бы создать 64-разрядную версию. Перспективы возможности разделения ПО были также довольно туманны, кроме того, оставались вопросы по поводу масштабируемости этого микроядра (сколько пользователей сможет оно поддерживать?). Поэтому мы отвергли мысль использовать его в качестве основы для SLIC. Однако в Рочес-тере была создана группа для разработки 64-разрядных модификаций микроядра IBM с прицелом на будущее. Было также решено включить в SLIC возможности по поддержке множественных индивидуальностей ОС. Добавление в SLIC поддержки других ОС, на первый взгляд, не имело смысла. Какие еще ОС, кроме OS/400, нам следует поддерживать? Некоторые из нас все понимали, но были вынуждены пойти на небольшую хитрость, чтобы показать, как эта поддержка могла бы работать.Индивидуальность System/36
В Рочестере была и группа разработчиков, продолжавших оставаться приверженцами System/36. В 1993 году в разгар работ над SLIC у двоих руководителей группы System/36, Дика Мастейна и Стива Дала (Steve Dahl), возникла идея. Почему бы не создать новую System/36? Такая возможность появлялась с переходом AS/400 на RISC и наличием в SLIC поддержки для других ОС. Упомянутые разработчики быстро подготовили предложения по переносу ОС System/36 на RISC-аппаратуру. В предыдущие несколько лет различные производители по всему миру начали поставлять на рынок программные пакеты, позволявшие клиентам System/36 перейти на RISC-компьютеры: либо на RS/6000 IBM, либо на продукты конкурентов. Беда этих пакетов-«имитаторов» заключалась в том, что они предоставляли только часть возможностей System/36. Пользователям System/36 по-прежнему было необходимо вносить изменения в свои приложения и методы работы, а некоторые из программ для System/36 и вовсе не работали на новом компьютере. В IBM был принят официальный план перевода пользователей System/36 на AS/ 400. Но лишь немногие заказчики воспользовались этой возможностью, а большинство отвергло ее. Согласно оценкам, более 200 000 System/36 по-прежнему работают в во всем мире. И все же многие в IBM полагали, что переход приверженцев System/ 36 на какую-либо новую платформу IBM — лишь вопрос времени. Не стоит и говорить, что в таких условиях предложение разработчиков о создании новой System/36 не было встречено с особым энтузиазмом. По счастью, некоторые из рочестерских руководителей всегда хотели проверить новые возможности, и вскоре для разработки новой System/36 была создана «подпольная» группа («skunkwork»), что, впрочем, практиковалось в Рочестере и раньше[ 33 ]. Мы использовали такой трюк для разработки систем, которые не считались стратегическими и, таким образом, не финансировались централизованно. Вспомните, что и сама AS/400 появилась в результате подобной «подпольной» деятельности. Итак, небольшая группа экспертов по System/36 под руководством Боба Шмидта (Bob Schmidt) вынуждена была скрываться от зорких глаз финансистов. Тем не менее, у Боба не было недостатка в добровольцах. Всего через несколько месяцев работы этой небольшой команды энтузиастов System/36 работала на новом RISC-процессоре. Серия продуктов System/36 получила новое дыхание.Что-то старое, что-то новое
Процессор оригинальной System/3, появившейся на свет в 1969 году, был полностью реализован аппаратно. Он был очень прост и поддерживал всего 28 команд. Поверх аппаратуры System/3 функционировала ОС вместе со всеми приложениями. С появлением в 1975 году System/32 эта структура претерпела существенные изменения. Уже в начале 70-х годов в процессе работ над System/38 перевод некоторых функций ОС в микрокод для достижения независимости от технологии был в Рочестере хорошо отлажен. Для поддержки набора команд System/3 в System/32 использовался микропрограммный эмулятор. По соображениям производительности некоторые функции были вынесены из ОС System/3 в микрокод System/32. Таким образом, System/32 и System/38 имели общие черты: некоторые части их ОС были реализованы в микрокоде, хотя и по разным причинам. System/32 была разработана как система начального уровня и полностью соответствовала этому предназначению. Эмуляция набора команд System/3 выполнялась медленно, производительности процессора не хватало. Однако, процессор System/ 32 отлично выполнял эти функции. Примечательно, что сам он был 16-разрядным, использовал регистры и очень напоминал некоторые ранние RISC-процессоры. Для повышения производительности System/32 требовались некоторые изменения. Ее процессор хорошо справлялся с выполнением ОС, так что было принято решение оставить его. Но поскольку он слишком медленно выполнял эмуляцию команд System/3, то был добавлен второй процессор, сходный с оригинальным процессором System/3, для исполнения команд последнего непосредственно аппаратурой. Значительная часть ОС была написана с помощью команд System/3 и должна былаисполняться на втором процессоре. Так как он выбирал команды из основной памяти, второй процессор был назван MSP (Main Store Processor). Процессор же System/32 выбирал команды из отдельной области памяти, и был переименован в CSP (Control Store Processor). В 1977 была выпущена первая система на двух процессорах, названная System/34. В 1983 году вслед за System/34 появилась модель System/36. Она по-прежнему использовала двухпроцессорную структуру. Подобно AS/400, чья ОС разбита на две части — OS/400 и SLIC — ОС System/36 также состояла из двух частей. Первая часть под названием SSP (System Support Program) исполнялась на MSP, а другая — на CSP. Старшие модели System/36 имели дополнительные процессоры для выполнения функций ввода-вывода. Они также представляли собой CSP, на которых исполнялись части ОС, управлявшие вводом-выводом. За следующие несколько лет были выпущены новые модели System/36, и все они также использовали два процессора. В 1993 году разработчики System/36 пришли к выводу, что RISC-процессор, который предназначался для AS/400, достаточно быстр, чтобы эмулировать набор команд MSP без дополнительного процессора. Если соответствующий эмулятор встроить в SLIC вместе со всем кодом CSP, то ОС SSP могла бы выполняться новым RISC-процессором непосредственно. Для этого необходимо было создать эмулятор и переписать код CSP на С++ как часть SLIC. Интерфейс между оригинальными MSP и CSP был интерфейсом SVC (Supervisor Call). Команда вызова супервизора (SVC) исполняется MSP и представляет собой запрос на выполнение CSP некоторых действий. Концептуально это то же самое, что и исполнение команды на уровне MI для запроса на выполнение некоторых действий SLIC. Разработчики рассудили, что если расширить MI включением интерфейса SVC, то SPP можно будет исполнять поверх MI, что позволит сделать SSP так же независящим от технологии. Соответствующее расширение MI было названо Technology Independent Emulation Interface (интерфейс эмуляции независящий от технологии)[ 34 ] Приняв решение использовать для выполнения набора команд MSP не отдельный аппаратный процессор, а эмулятор, разработчики получили конструкцию, которая внутренне более походит на System/32, нежели на System/34 или System/36. Как часто происходит, история повторяется. В новом черном корпусе снова живет «bionic desk» (прозвище System/32)!Advanced 36
Вот так внезапно мы получили совершенно новую System/36, работавшую на 64-разрядной RISC-аппаратуре с использованием ядра SLIC. Более того, это была System/ 36 в чистом виде. В SSP не было никаких изменений, затронувших интерфейсы приложений. Новая система была полностью двоично совместимой с System/36. Для переноса приложения на новую систему не требовалась даже перекомпиляции. Очевидно, что эта новая индивидуальность System/36 могла бы выполняться на AS/ 400 с переходом на новые RISC-процессоры. Однако была и другая возможность — воссоздать раннюю версию процессора Cobra полностью (процессор, кэш и интерфейс ввода-вывода) на одном кристалле. В Рочестере была организована небольшая группа, которая вскоре получила однокристальный процессор, основывавшийся на дизайне ендикоттовской лаборатории. Этот процессор работал на частоте 50 МГц, что было достаточно быстро для любого приложения System/36. Процессор получил название Cobra-Lite, так как в нем не было реализовано примерно 17 команд из обязательного набора 64-разрядного PowerPC. Данные команды, по большей части для работы с плавающей точкой, были реализованы программно, но это не имело значения. Отсутствовавшие команды, включая комбинированную команду умножения и сложения с плавающей точкой, применяющуюся для матричных вычислений, не использовались в SLIC и не влияли на новую System/36. IBM подтвердила, что ее завод в Барлингтоне может производить специальные микросхемы в количестве, достаточном для выпуска новых System/36 на RISC-процессорах в конце 1994 года. Мы знали, что можем включить в этот продукт раннюю версию SLIC с новой версией SSP. Перед нами была непростая дилемма. Можно начать выпуск первого 64-разрядного RISC-компьютера IBM — но это System/36! Мы много лет призывали своих заказчиков отказаться от System/36, а теперь были готовы выпустить ее новую версию на основе самой современной технологии. Принять такое было нелегко. Подразделения IBM по всему миру отвергли новую System/36. Наконец, мы убедили руководство позволить нам самим поговорить с заказчиками и бизнес-партнерами и предоставить рынку решать, следует ли нам объявлять в 1994 году о новой системе. Я делал доклад о новой System/36 на самой большой конференции наших бизнес-партнеров в начале 1994 года. Подавляющее большинство аудитории проголосовало за объявление новой системы. Многие были готовы прямо на месте купить у нас демонстрационную машину. Руководство и службы маркетинга IBM быстро оценили потенциал новой системы. В октябре 1994 года Advanced 36 появилась на рынке, где сразу же стала пользоваться спросом.
Первая модель Advanced 36 исполняла только ОС SSP. Последующие модели могут исполнять OS/400 и SSP параллельно на одном и том же процессоре. Advanced 36 продемонстрировала всю мощь архитектуры AS/400 и ее способность прозрачно интегрировать новую функциональность и даже целую новую ОС. Теперь внутри SLIC каждой RISC-модели AS/400 «живет» System/36. Может, имеет смысл на каждую новую AS/400 приклеивать метку «System/36 Inside»?
Перед нами была непростая дилемма. Можно начать выпуск первого 64-разрядного RISC-компьютера IBM — но это System/36! Мы много лет призывали своих заказчиков отказаться от System/36, а теперь были готовы выпустить ее новую версию на основе самой современной технологии. Принять такое было нелегко. Подразделения IBM по всему миру отвергли новую System/36. Наконец, мы убедили руководство позволить нам самим поговорить с заказчиками и бизнес-партнерами и предоставить рынку решать, следует ли нам объявлять в 1994 году о новой системе. Я делал доклад о новой System/36 на самой большой конференции наших бизнес-партнеров в начале 1994 года. Подавляющее большинство аудитории проголосовало за объявление новой системы. Многие были готовы прямо на месте купить у нас демонстрационную машину. Руководство и службы маркетинга IBM быстро оценили потенциал новой системы. В октябре 1994 года Advanced 36 появилась на рынке, где сразу же стала пользоваться спросом.
Первая модель Advanced 36 исполняла только ОС SSP. Последующие модели могут исполнять OS/400 и SSP параллельно на одном и том же процессоре. Advanced 36 продемонстрировала всю мощь архитектуры AS/400 и ее способность прозрачно интегрировать новую функциональность и даже целую новую ОС. Теперь внутри SLIC каждой RISC-модели AS/400 «живет» System/36. Может, имеет смысл на каждую новую AS/400 приклеивать метку «System/36 Inside»?
Выводы
Интеграция обеспечила уникальные возможности AS/400. Компоненты разработаны для взаимодополняющей совместной работы друг с другом. Интеграция также затрудняет изучение компонентов по отдельности, как в других системах. Например, ранее мы говорили, что защита реализована частично в OS/400 и частично — в SLIC. Изучение только защиты OS/400 не дает полной картины. Сравните это с другими системами, где компонент защиты представляет собой отдельный самодостаточный пакет, работающий поверх ОС. Рассматривать AS/400 как набор горизонтальных слоев не результативно. Лучше понять систему можно, «делая» ее вертикальные срезы, — то есть изучая конкретную функцию, части которой реализованы в OS/400, в SLIC и в аппаратуре как единое целое. В следующей главе мы рассмотрим слой MI. Это позволит лучше понять типы функций, реализованных в OS/400 и в SLIC. Мы также увидим, каким образом программа, прежде чем выполняться, компилируется до уровня аппаратуры. Далее мы поговорим об основных компонентах AS/400 как о ряде вертикальных срезов. После этого Вы увидите, как справедливо в приложении к AS/400 старое изречение: «Целое больше, чем простая сумма частей».Глава 4
Машинный интерфейс, независимый от технологии
Итак, после того, как к большинству компьютерных систем были добавлены уровни абстракции, их архитектура стала многоуровневой. Главные уровни AS/400 — это архитектура независимого от технологии машинного интерфейса MI (Technology Independent Machine Interface) и архитектура RISC-процессора PowerPC. Определение архитектуры PowerPC было дано с очевидным уклоном в сторону аппаратуры. Конструкторы микросхем играют важную роль в создании любой процессорной архитектуры — ведь именно они держат в голове массу вариантов ее реализации. Дабы не выйти за пределы возможностей конкретной аппаратуры конкретного кристалла, соблюсти время процессорного цикла, от одних функций им приходится отказываться, другие — определять заново. Это единственно верный подход — ведь в нереализуемой аппаратной архитектуре смысла мало. В то же время архитектура, учитывающая только требования аппаратуры, недолговечна. Правда, есть и опирающиеся на аппаратуру архитектуры-долгожители. Например, Intel успешно довела свой процессор x86 с начала 80-х до сего дня. Начав с Intel 8086, эта компания продолжает наращивать его функциональные возможности, по мере того как технология позволяет упаковать все больше транзисторов в один кристалл. Семейство процессоров 186, 286, 386, 486, Pentium, Pentium II и Pentium Pro — грандиозный успех Intel. Для поддержания программной совместимости к оригинальной 16-разрядной архитектуре были добавлены 32-разрядные расширения. С этой же целью новые (1997 год) команды расширений мультимедиа (MMX) используют существующие регистры с плавающей запятой, а не добавляют новые. С целью повысить конкурентоспособность и производительность Intel добавила в процессоры Pentium Pro и Pentium II набор микрокоманд RISC. Каждая CISC-команда x86 реализована в этих процессорах как последовательность RISC-команд. Благодаря использованию RISC-техноло-гии архитектура x86 продолжает жить.Обзор архитектуры MI
Определение архитектуры MI не привязано к аппаратуре. Это не физический, а логический интерфейс системы. Как уже говорилось в главе 1, архитектура MI предлагает полный набор API для OS/400 и всех приложений. Этот набор полон по определению; то есть ни система, ни приложения в принципе не могут выйти за пределы MI. Единственный способ связи с аппаратурой и некоторым системным ПО ниже MI — через сам MI. Это свойство отличает архитектуру MI от API-центрической архитектуры, где приложения могут обходить API и, следовательно, становиться зависимыми от нижележащих аппаратуры и ПО. Когда создавалась архитектура MI, термин API еще не был четко определен, так что разработчики называли эти модификации просто командами. Чтобы показать, что интерфейс архитектуры поддерживает как прикладное, так и системное ПО, они выбрали название машинный интерфейс. Так что можно считать, что «I» в аббревиатуре «API» — то же, что и в «MI». API — не что иное, как команды MI. Вы поражены прозорливостью разработчиков первоначальной архитектуры MI, раз и навсегда определивших набор API, используемый OS/400 и всеми приложениями? Не стоит: они не сделали этого, да и не могли сделать. По мере появления новых приложений в архитектуру MI добавлялись поддерживающие их новые API. Дело в том, что архитектура MI безразмерна, и новые API для поддержки новых приложений или функций операционной системы к ней можно добавлять в любое время. А раз эта архитектура постоянно изменяется, приобретая новые функции, то значит, она никогда не устареет. Так как все предыдущие API остаются при этом нетронутыми, для всех ранее написанных приложений сохраняется защита в границах MI. Архитектура MI состоит из двух компонентов: набора команд и операндов, над которыми эти команды выполняются. Часть операндов — из битов и байтов — не отличается от тех, что используются в обычных компьютерных архитектурах. Другие представляют собой объекты. Объект — это сложная структура данных, единственная, поддерживаемая в рамках MI. Компьютер обычно представляет свои информационные ресурсы — каталоги, файлы баз данных и описания физических устройств — в виде структур данных или хранящихся в памяти блоков с заранее определенными полями. Приложения и системное ПО, обладая непосредственным доступом к этим структурам данных, манипулируют их полями. А следовательно, они должны «знать», как это делать. Объект в границах MI — это контейнер, содержащий структуру данных, соответствующую информационному ресурсу. Определенный уровень независимости достигается следующим образом: прикладные и системные программы вместо того, чтобы работать непосредственно со структурой данных через инструкции на уровне битов и байтов, имеют дело лишь с инструкциями, рассматривающими объекты в целом. Благодаря использованию объектов, прикладному и системному ПО больше не требуется информация о структуре или формате данных. Эта информация хранится в контейнере и невидима за пределами объекта. Поэтому любые изменения в структуре данных не влияют на прикладные или системные программы, и они остаются независимыми от структур нижнего уровня. Такое свойство сокрытия внутренних деталей называется инкапсуляцией. Мы обсудим инкапсуляцию, а также внутреннюю структуру объекта и команды для работы с ними в главе 5, а теперь сосредоточимся на наборе команд архитектуры MI. Давайте обсудим несколько примеров команд, выполняемых над обычными данными и команд, оперирующих объектами. Поговорим и о том, как компиляторы используют MI для генерации кода, выполняемого аппаратурой, познакомимся с характеристиками MI и программами MI. И наконец, рассмотрим структуру команд MI.Неисполняемый интерфейс
Команды MI не исполняются аппаратурой непосредственно. Они либо предварительно (до исполнения программы) транслируются в аппаратный набор команд, либо специальный компонент SLIC интерпретирует некоторые команды MI одну за другой. Пример интерпретируемых команд MI — API Advanced 36. Мы называем процесс преобразования команд MI в низкоуровневые аппаратные команды трансляцией, а не компиляцией, так как при этом выполняется лишь часть функций компиляции. Прежде результатом такой трансляции был набор инструкций IMPI — теперь это набор инструкций PowerPC. Набор инструкций MI нельзя считать ЯВУ в обычном смысле. Правильнее рассматривать его как разновидность промежуточного представления программы в современном компиляторе ЯВУ. Кое-кто предпочитает представлять набор инструкций MI как ЯВУ, требующий трансляции на более низкий уровень или исполнения посредством интерпретации. Краткое описание оптимизирующих компиляторов поможет понять, почему MI лучше рассматривать как промежуточное звено. Структура современного оптимизирующего компилятора показана на рис. 4.1. Обычно, компилятор состоит из двух и более проходов или фаз. Проход — это одна фаза, за которую компилятор считывает и модифицирует всю программу. Термины фаза и проход часто используются как синонимы. В процессе выполнения каждого прохода компилятор преобразуя программу, понижает уровень ее представления (от более абстрактного к менее). В конечном итоге получается набор команд аппаратуры. Такая структура оптимизирующего компилятора была впервые предложена в 60-х годах для упрощения сложных преобразований, имевших целью получение оптимизированного кода. Возможности однопроходного компилятора по оптимизации ограничены. Проще говоря, он не может просмотреть код программы вперед и учесть то, что произойдет дальше. «Заглянуть вперед» может многопроходный компилятор. Назначение регистров переменным в зависимости от их связей с другими переменными, запись в память ненужного более содержимого кэша, предварительная выборка операндов — вот лишь некоторые примеры оптимизации, выполняемой многопроходным компилятором. Оптимизации, произведенные компилятором, могут значительно ускорить выполнение программы, особенно если она работает на процессоре, способном выполнять несколько команд параллельно. RISC-процессор — именно такого типа и ему необходим оптимизирующий компилятор для достижения высокой производительности. Применение нескольких проходов также облегчает процесс написания самого компилятора. Рисунок 4.1 Структура оптимизирующего компилятора
Рисунок 4.1 Структура оптимизирующего компилятора
Первый проход компилятора, показанного на рис. 4.1, часто называют препроцессором (front end) компилятора. Его задача — преобразование текста на ЯВУ в общую промежуточную форму (common intermediate form). Постпроцессор (back end) компилятора состоит из фаз оптимизации и фазы генерации кода. Препроцессоры зависят от ЯВУ, тогда как постпроцессоры — от аппаратуры. Если общая промежуточная форма независима как от ЯВУ, так и от аппаратуры, то она может использоваться несколькими компиляторами. Для каждого нового ЯВУ нужен лишь новый препроцессор. Аналогично, если создан постпроцессор для новой аппаратуры, то с ним будут работать все старые препроцессоры. Такой модульный подход упрощает создание компиляторов ЯВУ для нового компьютера. Набор команд MI аналогичен общей промежуточной форме, применяемой в компиляторах. Компилятор ЯВУ преобразует исходный текст в форму для MI. Транслятор, расположенный уровнем ниже MI, считывает программу в этой форме, выполняет оптимизацию и генерирует инструкции IMPI или PowerPC. Транслятор очень напоминает постпроцессор компилятора. Общая промежуточная форма для некоторых языков может как транслироваться, так и интерпретироваться. В главе 11 мы рассмотрим язык Java, использующий как раз такую форму. Промежуточная форма Java, известная как байт-код, также включена в MI. Набор инструкций MI заменяет общую промежуточную форму не во всех компиляторах AS/400 — некоторые языки имеют собственную промежуточную форму. Ниже приводится описание внутренней структуры компиляторов языков для AS/400, и место MI в этой структуре.
 Компиляторы для AS/400
Компиляторы для AS/400
Ранние компиляторы (например, RPG/400 и языка управления CL) для System/38 и AS/400 генерировали команды: MI довольно прямолинейно. Хотя они и проходили уровень ассемблера, в самом компиляторе не было общей промежуточной формы. Ее роль выполняли команды MI.
Модель программы для этих языков, включая форму программы ниже уровня MI, называется исходной моделью программ или OPM (Original Program Model). Позднее, для языков типа C/400, была добавлена расширенная модель программ или EPM (Extended Program Model). На рисунке 4.2 показан процесс генерации кода IMPI для OPM и ЕРМ. Мы представили здесь эти две модели только для демонстрации эволюции компиляторов AS/400. На RISC-системах версии 4 не используются ни компиляторы ОРМ, ни ЕРМ.
Сначала рассмотрим компилятор ОРМ. Он принимает на входе операторы ЯВУ ОРМ (вместе с не показанными на рисунке описаниями файлов) и на выходе генерирует код промежуточного представления программы IRP (Intermediate Representation of a Program). IRP, по сути, — ассемблер для команд MI. Следующий шаг — код IRP преобразуется в команды MI с помощью компонента под названием PRM (Program Resolution Monitor), который создает шаблон программы, помеченный на рисунке как шаблон программы ОРМ и содержащий команды MI и другие данные. Шаблоны используются для создания объектов MI. Транслятор, расположенный ниже уровня MI, создает по шаблону программы программный объект, содержащий команды IMPI. Содержание шаблона программы будет рассмотрено далее.
ОРМ — пример классического компилятора, генерирующего ассемблерную форму программы (IRP), после чего ассемблер (PRM) генерирует двоичную машинную программу (шаблон программы). Компиляция на AS/400 требует дополнительного шага (этапа трансляции) и поэтому может занимать больше времени, чем на некоторых других системах. Обратите внимание, что все эти этапы для пользователя AS/400 невидимы и выглядят, как одна операция.
По мере реализации на AS/400 новых языков, таких как С/400 и Pascal, потребовалось добавить расширения. Этапы компиляции для ЕРМ (расширенной версии ОРМ) также показаны на рис. 4.2. В компиляторах таких языков препроцессор и постпроцессор разделены. Общая промежуточная форма в них называется U-код. Для AS/400 был создан новый постпроцессор компиляторов CUBE-1 (Common Use Back End 1).
 Рисунок 4.2 Компиляторы ОРМ и ЕРМ
Рисунок 4.2 Компиляторы ОРМ и ЕРМ
Для повышения производительности модульного программирования и стимуляции его распространения на все языки, были внесены архитектурные расширения в MI и объекты, расположенные ниже. Эта модификация датирована 1993 годом и называется ILE (Integrated Language Environment). В состав ILE входят новые компиляторы ЯВУ, новый оптимизирующий транслятор (OX) и новые средства связи для создания многомодульных программ[ 35 ]. ILE изменил программирование. В отличие от ОРМ, на выходе у этого транслятора не программный объект, а модуль. Средство связывания ILE компонует эти модули в программы. Кроме поддержки вызовов с поздней компоновкой ОРМ, в ILE есть возможность компоновки во время компиляции. Преимущество такой ранней компоновки состо- ит в сокращении накладных расходов, связанных с внешними динамическими вызовами. Заранее скомпонованные или статические вызовы выполняются быстрее. Прежде чем идти дальше, требуется четко оговорить, что мы понимаем под некоторыми терминами. • Процедура — последовательность операторов, которая может быть вызвана в точке входа, возможно, с некоторыми параметрами. • Модуль — объект, содержащий код, полученный на выходе компилятора ILE. В отличие от программы, создаваемой компилятором OPM, модуль не исполняем. Модуль может содержать одну или несколько процедур. Компоновщик ILE собирает программы и служебные программы из модулей, возможно, написанных на разных языках. • Программа — исполняемая единица кода, состоящая из одного или нескольких модулей, которые могут быть сгенерированы компиляторами разных языков. У программы единственная точка входа, и она запускается динамическим вызовом. Входом в программу при ее создании назначается одна из процедур, и после вызова программы управление передается этой процедуре. Процедуры внутри программы запускаются статическими вызовами. • Служебная программа — исполняемая единица кода, состоящая из одного или нескольких модулей, которые могут быть сгенерированы компиляторами разных языков. Служебная программа активизируется как единое целое, но рассматривается как набор процедур. Каждая из таких процедур может быть вызвана статическим вызовом. Таким образом, служебная программа может иметь несколько точек входа — по одной на каждую процедуру. • Группа активизации — рабочая область памяти внутри задания, выделенного для выполнения одной или нескольких программ. Подробно мы рассмотрим группы активизации в главе 9. Деление на программы и служебные программы связано с необходимостью поддержки двух типов статических вызовов: связь через копию (bound by copy) и связь через ссылку (bound by reference). Первые позволяют копировать в программу одновременно несколько модулей. Как мы только что говорили, сама программа вызывается динамически, но после этого вызовы процедур из всех модулей происходят статически. Так как имена процедур преобразуются в адреса во время компиляции, данный тип статического вызова внутри программы выполняется быстрее, чем динамический вызов. Недостаток связи через копирование в том, что в памяти может одновременно находиться несколько копий модуля, если он связан с несколькими программами. За все нужно платить, и здесь за быстродействие мы расплачиваемся дополнительным расходом памяти. В случае связи через ссылку, модули находятся в служебной программе, а в программе сохраняются именные ссылки на них. При этом существует только одна копия служебной программы. При активизации программы эти ссылки разрешаются на адрес таблицы, находящейся в служебной программе и содержащей адреса вызываемых процедур. Запуск программы связан с некоторыми дополнительными накладными расходами, например, с проверкой авторизации (рассматривается в главе 7). Тем не менее, производительность собственно исполнения программы примерно соответствует связи через копию. В обоих методах ранней компоновки используется новая команда вызов связанной процедуры CALLB (call bound procedure). Другая новая команда, вызов программы или CALLPGM (call program) поддерживает позднее связывание и заменяет команду вызова внешней процедуры ОРМ. Структура компиляторов программной модели ILE показана на рис. 4.3.
 Рисунок 4.3 Компилятор программной модели ILE
Рисунок 4.3 Компилятор программной модели ILE
Препроцессор компилятора ILE генерирует общую промежуточную форму — W-код. Постпроцессор таких компиляторов называется CUBE-3. Цифрой 3 обозначено третье и самое последнее поколение технологии компиляторов IBM. CUBE-3 и W-код спроектированы с учетом эффективной поддержки RISC-процессоров. Другие системы IBM, в частности RS/6000, используют те же технологии. Постпроцессор компилятора ILE генерирует непосредственно шаблон программы ILE, устраняя IRP и шаг PRM. Чтобы обеспечить необходимую оптимизацию RISC-процессоров, в MI добавлены арифметические команды и команды переходов в стиле W-кода, которые мы рассмотрим далее. Модель ILE — единственная программная модель для RISC-процессоров — является расширением архитектуры MI. На системах IMPI программные модели ILE и ОРМ/ЕРМ сосуществуют, так что на одном и том же компьютере может использоваться и код, сгенерированный старыми компиляторами, и сами компиляторы.
 Рисунок 4.4 Компиляторы ОРМ и ЕРМ на V4 RISC
Рисунок 4.4 Компиляторы ОРМ и ЕРМ на V4 RISC
Перенос программы ОРМ/ЕРМ на систему RISC вызывает ее внутреннее преобразование в программную модель ILE. На рис. 4.4 показаны шаги компиляции ОРМ или ЕРМ для системы RISC версии 4. Для использования старых компиляторов на новых RISC-моделях нужен дополнительный шаг: результат работы таких компиляторов — шаблон оригинального MI — должен быть преобразован в шаблон ILE MI. Компонент, выполняющий данное преобразование, называется Magic, (намек на то, что преобразование происходит как бы магическим образом).
Рисунок 4.4 Компиляторы ОРМ и ЕРМ на V4 RISC
Характеристики машинного интерфейса
Сравнивая MI с обычным машинным интерфейсом, мы отмечаем, что MI — интерфейс высокого уровня. Дело в том, что многие команды MI выполняют очень сложные функции. Например, не многие обычные машинные интерфейсы содержат функции вызова, поддерживающие как раннюю, так и позднюю компоновку, для них более характерны обычные команды перехода. Чтобы лучше понять разницу, разберем команду обычного машинного интерфейса (см. рисунок 4.5). Она состоит из кода операции и одного или нескольких полей операндов. Команды могут быть арифметическими (в каждом компьютере есть команда сложения), передачи управления и манипуляции с данными. Самое важное, с какого рода операндами имеют дело эти команды.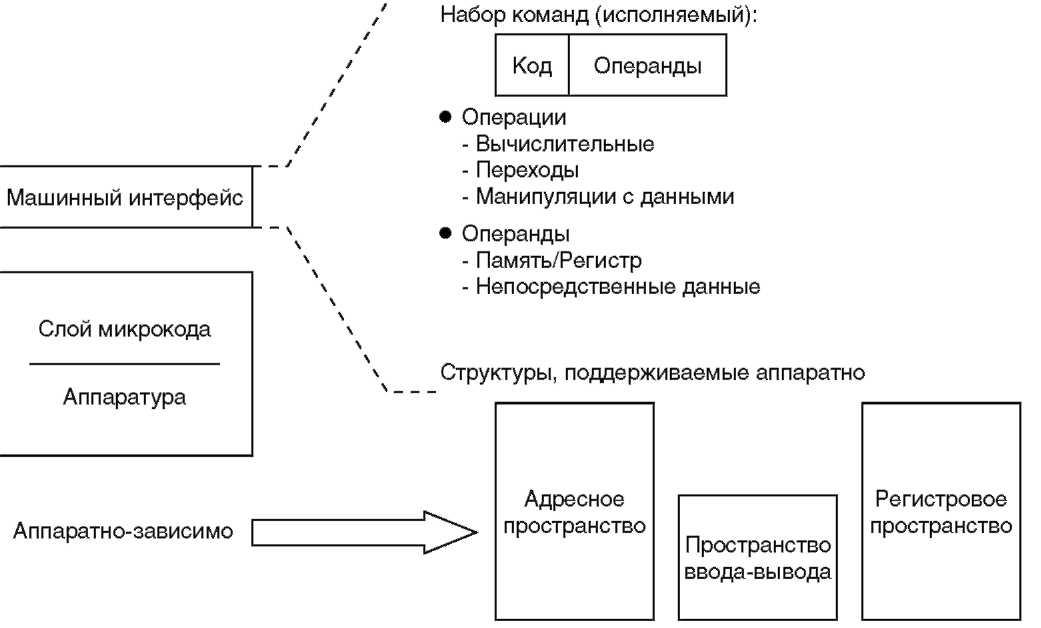 Рисунок 4.5 Обычный машинный интерфейс
Рисунок 4.5 Обычный машинный интерфейс
Обычные машинные интерфейсы работают с содержимым регистров, памяти или непосредственно с данными, записанными в самой команде. Иначе говоря, они «не подозревают» о данных приложения или операционной системы. Возьмем стандартную команду «регистровое сложение». Она задает два регистра процессора и выполняет операцию, извлекая биты из одного регистра, складывая их с битами из другого регистра и помещая результат в определенное место. Смысла этих битов команда «не понимает» —о нем «заботится» программа. Для машины это просто набор битов, к которому применяется алгоритм сложения. То, что в регистрах находятся, например, имена двух сотрудников и поэтому рассматривать их в качестве арифметических операндов нет смысла, никого не волнует. Операции этого уровня просто механически обрабатывают содержимое регистров или памяти. Мы уже говорили о недостатке такой структуры — ее существенной зависимости от аппаратной технологии. Так как команды: работают в адресном пространстве, с областями ввода/вывода и регистрами, они привязаны к этим физическим структурам. Изменение последних может потребовать изменения команд. Значит, преобразование существующих программ может вызвать существенные проблемы.
 Рисунок 4.6 Машинный интерфейс AS/400
Рисунок 4.6 Машинный интерфейс AS/400
Машинный интерфейс AS/400 (см. рисунок 4.6) устроен совсем иначе. У него, как и у обычных, есть набор команд с кодами операций и операндами. Есть в нем и разные типы арифметических операций (например, команды: сложения) и операций передачи управления, работающие с традиционными операндами. Но в отличие от обычного интерфейса в нем есть команды, аналогичные промежуточному представлению, используемому в современных компиляторах ЯВУ, а также структуры данных (объекты). Самое важное отличие не в самих командах или операциях, а в используемых ими операндах. В обычном интерфейсе есть регистры, память и непосредственные данные. На AS/400 мы по-прежнему имеем непосредственные данные, но нет ни регистров, ни памяти. Их заменяют объекты. В MI определены объекты нескольких типов. Большинство из них — сложные структуры данных, нужные для представления информационных ресурсов. Один из самых важных типов объектов в системе — пространство (просто набор байтов, не связанный с физическим оборудованием). Многие с трудом представляют себе массу подвешенных неизвестно где байтов, им хочется обязательно связать их с аппаратурой. Но в MI понятие пространства не имеет отношения к физической памяти, он абсолютно независим от того, что находится ниже[ 36 ]. Когда программе MI требуется память, она использует пространство. На этом уровне нет понятий регистров, физической памяти и адресов памяти в традиционном смысле. Например, компилятор AS/400 должен куда-то деть созданный шаблон программы — в пространство! Кроме пространств, существуют и другие типы объектов, которые мы обсудим далее. До сих пор мы обсуждали только системные объекты MI. Но объекты поддерживает и OS/400.
Работа с программами MI
Несколько команд MI работают с программами. Так как программа представляет собой объект, эти команды: рассматривают программу целиком. Все команды выполняют над программой только операции, имеющие смысл. Есть команда создания программы, но нет команды перемножения программ, так как первая имеет смысл, а вторая — нет. Короче, команды специфичны для объектов того типа, с которым они манипулируют. Команды применяются к объекту целиком, а не к некоторым частям данных внутри объекта. Объект нельзя использовать не по назначению, так что еще одно крупное преимущество объектной ориентации — целостность. Программы в MI играют только присущую им роль. Давайте рассмотрим, как программа создается, уничтожается и материализуется.Создание программы
Программа создается на основе шаблона — заранее описанной структуры со всеми характеристиками определенного системного объекта MI. Шаблон формируется частью компилятора AS/400, отвечающей за генерацию кода. Все системные объекты MI образуются по шаблонам, хранящимся в пространствах MI. Так как объектам разного типа присущи разные характеристики, единого общего шаблона нет — у каждого объекта свой уникальный шаблон. Команда создания программы «Create Program» указывает на шаблон программы. Пока мы остановимся на двух типах указателей: системном и пространственном (позже мы увидим, что есть указатели и других типов). Первый направлен на системный объект MI, второй — на байт в пространстве. Длина каждого из этих указателей 16 байт. Через указатели в MI осуществляется адресация, так что указатель в MI можно представлять себе просто как адрес. Команда создания программы исполняется с помощью кода, лежащего ниже MI. Сначала через пространственный указатель команды «Create Program» код находит шаблон программы, над которым выполняется синтаксический контроль. Затем транслятор преобразует последовательность команд MI-шаблона программы в последовательность внутренних команд IMPI или PowerPC, которая упаковывается в системный объект MI — программу. Наконец, инициатору запроса возвращается адрес вновь созданной программы в виде системного указателя на этот объект. Если в какой-то части данной операции возникают проблемы, соответствующая диагностическая информация возвращается в виде сообщения.Уничтожение программы
Любой объект на уровне MI, который можно создать, можно и уничтожить. Соответственно на каждую команду создания объектов MI приходится команда уничтожения. Пользователь на уровне MI устанавливает системный указатель на программу или другой объект MI и дает команду: «Уничтожить». Конечно, сделать это просто так нельзя: у пользователя должны быть соответствующие права на доступ к разным объектам. Тему прав пользователей по отношению к объектам мы подробно обсудим в главе 7, а сейчас только упомянем, что пользователь может иметь разные уровни прав доступа к разным объектам. Чтобы уничтожать объекты, нужен самый высокий уровень. Как правило, объект может уничтожить только его владелец; но бывают ситуации, когда такие права имеют несколько пользователей. Каждому пользователю в системе соответствует специальный объект — профиль пользователя. Вместе с другими объектами профиль пользователя определяет права данного пользователя по отношению к тем или иным объектам. Когда пользователь прибегает к команде уничтожения, система сначала обращается к его профилю и выясняет, есть ли у него такое право, и лишь в случае утвердительного ответа выполняет операцию.Материализация и адаптируемость программы
Наблюдать характеристики программы поверх MI можно лишь через шаблон программы. Шаблон — результат работы компиляторов ЯВУ. Это самый нижний уровень, на котором возможна работа с компонентами программы поверх MI. Ниже MI программа существует в виде системного объекта, и все работающие с ним команды MI воспринимают его как единое целое. Внутри объекта находится последовательность команд IMPI или PowerPC. Объект инкапсулирован, то есть, невидим извне. Это обеспечивает независимость от технологии, однако программа не имеет законченной формы, так как последовательность ее команд невидима. Однако, если прикладному или системному ПО необходим доступ к характеристикам программы, команда MI, позволяет эту программу материализовать. Команда материализации указывает на инкапсулированный программный объект, по которому воссоздается шаблон программы. Материализация — операция, противоположная инкапсуляции. Технологию материализации не всем просто понять. Честно говоря, обратная компиляция (восстановление исходного текста программы при наличии ее только в откомпилированном виде) не слишком хорошо разработана и многолетние исследования в этой области идут пока без особого успеха. Как же решает эту задачу AS/400? Да просто жульничает: она не выполняет де-компиляции последовательности команд IMPI или PowerPC. Вместо этого копия шаблона программы сохраняется вместе с объектом. Когда выполняется команда MI материализующая программу, в ответ возвращается объект шаблона программы. Хранение шаблона программы в качестве системного объекта MI и придает System/38 и AS/400 возможности, отсутствующие в других системах. Это позволяет изменять набор команд, не влияя на приложения заказчиков. Изменения вносятся в новую версию транслятора, а затем все программы ретранслируются из своих шаблонов. Наконец, новые последовательности команд снова инкапсулируются в объекты. Все это происходит ниже MI и без участия пользователя. Чтобы Вы смогли лучше «почувствовать разницу», обратимся к классическому примеру внедрения System/38 Model 7. System/38 появилась как абсолютно новая система с абсолютно новым набором команд, новыми приложениями и новой ОС. Но как использовать эти команды:, никто точно не знал. Как правило, для того, чтобы достичь максимальной производительности системы, оптимизируют аппаратную реализацию наиболее часто встречающихся последовательностей команд с целью достичь их как можно более быстрого выполнения. Первоначально набор команд IMPI имел только 8-битные коды операций, то есть команд не могло быть более 256 (28 = 25 6). Когда начали писать приложения для System/38, то обнаружилось, что нужны новые функции. В ответ мы изобретали новые команды (своего рода болезнь!) и очень скоро вышли за эти пределы. Вполне естественно стремление сохранить набор операций небольшим, а следовательно, контролируемым и не избыточным. Но не менее законно желание упростить сложные задачи. Как увязать эти противоречия? Хорошо, если б существовал научный метод создания наборов команд, но, увы! Это скорее искусство, чем наука. Через пару лет мы пришли, как нам казалось, к оптимальному набору команд IMPI. И чтобы добавить эти новые команды, решили ввести в формат команд IMPI расширения кода операции. К тому времени мы уже знали, как работать с существующими командами IMPI и как повысить производительность путем перевода наиболее часто используемых команд в другие, более быстрые форматы. Изменение кодов операций означает, что команда, на предыдущей версии оборудования вызывавшая, скажем, загрузку, на новой версии служит для передачи управления. В любой «нормальной» системе такая замена привела бы к хаосу, но не в System/38 — ведь она не зависит от технологии. При модернизации оборудования системы устанавливалась и новая версия транслятора. У каждой программы в системе был свой заголовок объекта, который, кроме всего прочего, показывал, какой уровень транслятора использовался для создания программы. При первом исполнении программы система проверяла заголовок и при обнаружении старой версии обрабатывала связанный с объектом шаблон программы новым транслятором, сохраняя новый код IMPI в объекте. После этого программа выполнялась. Ретрансляция производится лишь однажды — при следующих вызовах программы используется новый код. Это работало блестяще, но... начались претензии заказчиков: «Я только что °—° установил систему, и мне кажется, что прикладные программы стали работать медленнее». Это и понятно: ретрансляция впервые запущенного приложения приводила к замедлению работы. Как Вы думаете, что мы отвечали? Конечно же — «Попробуйте еще раз». Тот же метод скрытой ретрансляции программ применялся при переходе на RISC-процессоры. Разница была лишь в том, что заказчиков заранее предупреждали, что приложения будут работать, только если не удалена адаптируемость. Что же изменилось со времен System/38?
AS/400 должна была привлечь и пользователей System/36, и System/38. Между тем вторые привыкли к большим объемам памяти и жестких дисков, так же как и пользователи System/36 — обходиться малым. Поэтому размеры новых программ последних пугали, и казались им чересчур большими.
Программы для AS/400 действительно впечатляли — ведь каждая хранилась в двух копиях: в инкапсулированной форме и в форме шаблона. Для экономии пространства на диске заказчики могли удалить шаблоны. Это называлось удалением адаптируемости программы (Delete Program Observability), так как после программу уже нельзя было материализовать.
В результате те, кто удалил адаптируемость некоторых или всех своих программ, должны были вернуться к исходным текстам на ЯВУ и заново откомпилировать их, прежде чем переносить на RISC-процессоры. И хотя на AS/400 это все равно проще, чем на большинстве других систем, все же перенос не выполнялся автоматически, как при наличии программного шаблона.
Это работало блестяще, но... начались претензии заказчиков: «Я только что °—° установил систему, и мне кажется, что прикладные программы стали работать медленнее». Это и понятно: ретрансляция впервые запущенного приложения приводила к замедлению работы. Как Вы думаете, что мы отвечали? Конечно же — «Попробуйте еще раз». Тот же метод скрытой ретрансляции программ применялся при переходе на RISC-процессоры. Разница была лишь в том, что заказчиков заранее предупреждали, что приложения будут работать, только если не удалена адаптируемость. Что же изменилось со времен System/38?
AS/400 должна была привлечь и пользователей System/36, и System/38. Между тем вторые привыкли к большим объемам памяти и жестких дисков, так же как и пользователи System/36 — обходиться малым. Поэтому размеры новых программ последних пугали, и казались им чересчур большими.
Программы для AS/400 действительно впечатляли — ведь каждая хранилась в двух копиях: в инкапсулированной форме и в форме шаблона. Для экономии пространства на диске заказчики могли удалить шаблоны. Это называлось удалением адаптируемости программы (Delete Program Observability), так как после программу уже нельзя было материализовать.
В результате те, кто удалил адаптируемость некоторых или всех своих программ, должны были вернуться к исходным текстам на ЯВУ и заново откомпилировать их, прежде чем переносить на RISC-процессоры. И хотя на AS/400 это все равно проще, чем на большинстве других систем, все же перенос не выполнялся автоматически, как при наличии программного шаблона.
 Внутри шаблона программы
Внутри шаблона программы
Чтобы выяснить, что там происходит, возьмем в качестве примера шаблон программы ОРМ, хотя он и не поддерживается на RISC-системах. Я выбрал ОРМ по двум причинам. Во-первых, это дает возможность рассмотреть еще несколько интересных концепций, лежащих в основе оригинального набора команд MI. Во-вторых, некоторые детали шаблона программы ILE не опубликованы. И поэтому прежде чем заняться шаблоном программы ОРМ, рассмотрим те изменения, которые были внесены в программную модель ILE.
При создании компиляторов для программной модели ILE, в MI были добавлены новые команды. Некоторые из них имеют структуру близкую к W-коду, используемому компиляторами ILE, однако не совпадают с его командами в точности. Права на W-код принадлежат лаборатории IBM в Торонто (Toronto), Канада, которая пока не желает лицензировать интерфейс W-кода кому-либо за пределами IBM, опасаясь, что другие смогут разрабатывать и продавать компиляторы для AS/400. Мы решили определить команды! MI, которые похожи, но не в точности совпадают с W-кодом, чтобы не связываться с Торонто, если там когда-либо будет принято решение открыть этот интерфейс другим фирмам.
Наилучший целевой компьютер для компиляторов ILE — стековая машина, поэтому MI был расширен для поддержки стеков. Стек — набор данных, хранящихся последовательно. Первый помещенный в стек элемент называется его дном, последний — вершиной. Для работы со стеком используются команды без явного указания операндов, которые определяются путем извлечения из стека двух верхних элементов. В противоположность этому, команды ОРМ имеют два операнда, заданных непосредственно в команде. Для стековой машины операция задается после операндов. Такая форма записи называется постфиксной или обратной польской в честь математика Лукашевича (J. Lukasiewicz), исследовавшего ее свойства[ 37 ].
Интересно, что архитектура, разработанная в 1972 году, имела аналогичную поддержку стека. В то время многие полагали, что блочно-структурированные языки, такие как PL/1, станут очень популярными. Но они так и не вытеснили RPG и Cobol, так что стек был временно отвергнут. Теперь, с появлением таких языков как С, мы снова вернулись к нему.
 Рисунок 4.7 Команды и ODT
Рисунок 4.7 Команды и ODT
Шаблон программы состоит из нескольких частей. Шаблон программы ОРМ содержит заголовок, последовательность команд MI, пользовательские данные и структуру под названием таблица определения объектов ODT (object definition table). Команды и ODT представлены на рисунке 4.7. Последовательность команд на рисунке содержит пример команды MI. Использована классическая команда OPM с тремя операндами —арифметическое сложение. Она состоит из кода операции, за которым следуют три значения, используемые для поиска трех операндов. Каждое из них является индексом в ODT. Показанная на рисунке команда запрашивает сложение операнда 6 с операндом 2 и помещение суммы в операнд 3. ODT состоит из двух компонентов. Первая — ODV (ODT Direction Vector) — содержит по одному элементу для каждого операнда программы. Все элементы имеют одинаковую длину, так что значение из последовательности команд может использоваться как индекс в ODV. Элементы ODV описывают операнды. В нашем примере, операнды 6 и 3 — это двоичные числа длиной 2 байта, а операнд 2 — константа. Константы и другие типы операндов могут иметь переменную длину, что задает необходимость второго компонента ODT. OES (ODT Entry String) содержит операнды переменной длины, не умещающиеся в ODV. Содержимое поля ODV указывает на начало цепочки в OES. В нашем примере операнд 2 представляет собой константу 1253. Пример иллюстрирует несколько характеристик команд MI модели ОРМ. Во-первых — это команда арифметического сложения. Это не команда двоичного или десятичного сложения, или сложения с плавающей запятой; она универсальна. Формат операндов команды определяется в ODT. В нашем примере используются двоичные целые операнды, но они могли бы иметь любой числовой формат. За генерацию необходимых преобразований отвечает транслятор. Во-вторых, из примера видно, что ОРМ MI — неисполняемый интерфейс. Обратите внимание, что ни с операндом 3, ни с операндом 6 не связаны значения. Элемент ODV эквивалентен объявлению переменной. Память для переменной не выделена, так что транслятор обязан завершить компиляцию и назначить переменным регистры или области памяти. И, наконец, в примере показана обычная вычислительная команда. Команда, работающая с объектом, имела бы аналогичный формат, но в ODT было бы указано, какнайти объект (детали адресации объектов будут рассмотрены в главе 5).
 Форматы команд MI
Форматы команд MI
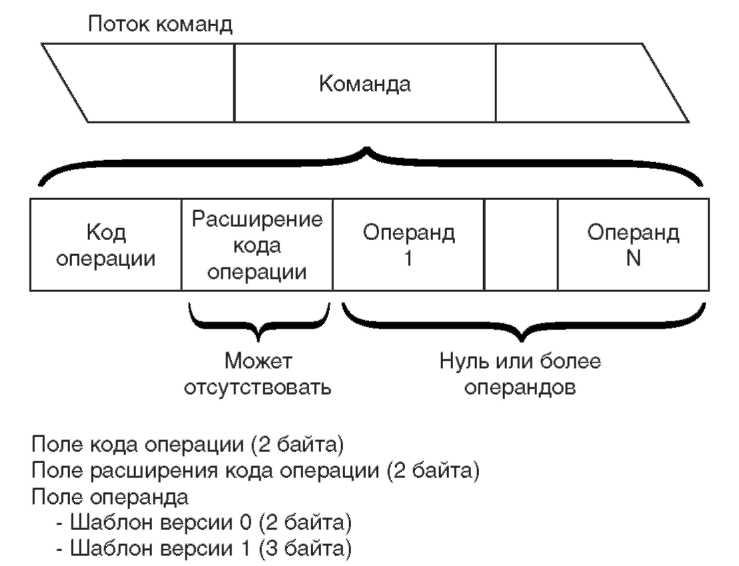 Рисунок 4.8 Формат команд MI
Рисунок 4.8 Формат команд MI
На рисунке 4.8 показан формат команд ОРМ MI в потоке команд. Команда состоит из кода операции, необязательного расширения кода операции, а также нуля или более операндов. MI проектировался в расчете на последующие расширения, так что формат команды допускает увеличение числа команд и операндов. Код операции и его расширение представляют собой 16-разрядные поля. Поле операнда, используемое как индекс в ODV, первоначально на System/38 имело длину 16 бит, но затем было расширено до 24 бит. Это означает, что в программе может быть до 16 миллионов (224) разных операндов, и эта цифра может быть увеличена. Экономия памяти не была слишком важна для шаблона программы. Например, команда арифметического сложения заняла бы 2 байта для кода операции, 2 байта — для расширения кода операции и 9 байтов — для операндов. Получается 13 байтов, и мы еще не учли пространство для операндов в ODT. Не удивительно, что пользователи System/36 были недовольны объемом дискового пространства, занимаемого программами.
 Код операции MI
Код операции MI
В таблице 4.14 показано назначение битов кода операции MI. Бит 3 задает вычислительный или невычислительный формат команды. Во втором случае функция, которая должна быть выполнена, закодирована в битах 5-15 кода операции. Функция, выполняемая вычислительной командой, задается битами 8-15. В этом случае, как в примере с арифметическим сложением, биты 5-7 содержат дополнительную информацию о команде.
Бит 6 вычислительного формата указывает, должно ли производиться округление. Обычно, округление характерно для арифметики с плавающей запятой, однако, проектировщики MI имели в виду не это. AS/400 — это машина для коммерческих расчетов, и округление, используемое в MI — это десятичное округление. Десятичные данные рассматриваются как данные с плавающей десятичной запятой.
Бит 7 указывает на сокращенную форму команды, что также имеет смысл только для вычислительных команд. В нашем примере арифметического сложения участвуют три операнда. Два из них складываются, и результат помещается в третий, то есть два первых операнда не изменяются. Сокращенная команда также складывает первые два операнда, но результат помещается в первый операнд. Таким образом, сокращенная команда использует формат только с двумя операндами.
 Таблица 4.1 Назначение битов кода операции
Таблица 4.1 Назначение битов кода операции
Наконец, в вычислительном формате имеются два бита, описывающих расширение кода операции. Биты 4 и 5 определяют наличие расширения и если таковое присутствует — способ его использования. Это требует более подробного объяснения.
 Расширение кода операции
Расширение кода операции
Расширение кода операции MI занимает следующие 16 бит команды и имеет две формы: опция перехода и опция индикации. Наличие расширения задается установкой бита 4, а в положительном случае разряд 5 выбирает опцию перехода или индикации.
В случае использования опции перехода расширение кода операции делится на четыре 4-разрядных поля. Каждое из них применяется для определения возможностей перехода для данной команды. В процессе исполнения любой вычислительной команды MI возможен условный переход. Другими словами, в зависимости от результатов вычисления следующая команда MI может быть выбрана из некоторого другого места последовательности команд.
Рассмотрим первое 4-разрядное поле расширения. Значение 1 (двоичное 0001) в этом поле означает переход в том случае, если в результате вычисления получено положительное число. Значение 2 (двоичное 0010) задает переход при отрицательном значении результата. Если же поле имеет значение 4 (двоичное 0100), то переход выполняется при результате равном 0. Имеются также значения для перехода при ненулевом, неположительном, неотрицательном и не ненулевом результате. Кроме того, та же самая комбинация битов может иметь разный смысл для разных типов команд. Например, команда сравнения интерпретирует биты иначе, чем команда сложения.
Если условие перехода, заданное первым 4-разрядным полем выполнено, то цель перехода может быть найдена за последним операндом команды. Если условие перехода не выполнено, то будет исполняться следующая команда по порядку. Такие возможности команд приводят к увеличению их длины.
Так как каждое из четырех 4-разрядных полей расширения используется для задания условия перехода, то каждая вычислительная команда может содержать до
четырех условий и до четырех целей перехода. Если нужно менее четырех условий, то значение 0 задает отсутствие перехода.
Возможность MI выполнять переход в четыре точки после каждой вычислительной команды обеспечивает набору команд большую мощность за счет их удлинения. В примере с арифметическим сложением — до четырех целей перехода, что увеличивает длину команды еще на 12 байтов. Команда может занимать в памяти до 25 байтов. Это не создает проблем во время выполнения, так как команды: MI не исполняются непосредственно. Однако размер программы увеличивается.
Опция индикатора работает аналогично опции перехода. Расширение содержит те же четыре 4-разрядных поля с теми же возможными значениями. Отличие в том, что вместо перехода при выполнении условия устанавливается индикатор. Индикатор представляет собой переменную в памяти, содержащую десятичные значения 1 или 0. Если в процессе выполнения вычислительной команды условие, заданное 4-разрядным полем, выполнено, то индикатор устанавливается в значение 1, в противном случае —в значение 0. Как и в случае перехода, в команде может быть задано до четырех индикаторов, которые указываются следом за операндами.
Многие читатели узнали в этом описании индикаторы RPG. Возможность установить индикатор и затем, в зависимости от его значения, выполнить некоторое действие восходит к оборудованию обработки единичных записей. Индикаторы RPG поддерживаются набором команд MI непосредственно[ 38 ]. На первый взгляд, эта возможность кажется устаревшей. Однако многие самые современные RISC-процессоры используют прием записи в регистр значения 0 или 1 для индикации результата вычисления. То есть, индикаторы живы и в добром здравии.
 Примеры команд MI
Примеры команд MI
 Рисунок 4.9а Команда арифметического сложения (ADDN)
Рисунок 4.9а Команда арифметического сложения (ADDN)
На рисунках 4.9а, 4.9б и 4.9в показаны форматы трех команд ОРМ MI. Команда арифметического сложения ADDN имеет шестнадцатиричный[ 39 ] код операции 1043, а также три операнда. Это вычислительная команда, и функция сложения в ней имеет код 43.

Рисунок 4.9b Команда перехода (B)

Рисунок 4.9c Копирование байтов с выравниванием влево и заполнителем (CPYBLAP) В таблице 4.27 приведены 11 других форм ADDN. Различные варианты команды получаются путем комбинации опций сокращенной команды, округления, индикатора и перехода. Обратите внимание, что кодом функции по-прежнему остается 43.
| ADDNS | 1143 | Короткая |
| ADDNR | 1243 | С округлением |
| ADDNSR | 1243 | Короткая с округлением |
| ADDNI | 1843 | Индикаторная |
| ADDNIS | 1943 | Индикаторная короткая |
| ADDNIR | 1A43 | Индикаторная с округлением |
| ADDNISR | 1B43 | Идикаторная короткая с округлением |
| ADDNB | 1C43 | С переходом |
| ADDNBS | 1D43 | Короткая с переходом |
| ADDNBR | 1E43 | С оКороткая с округлением и с пере- |
| ходом |
Выводы
Независимость от технологии, обеспечиваемая MI, чрезвычайно важна, так как позволяет избегать изменений в пользовательских приложениях и в OS/400. Все возможности нового оборудования могут быть задействованы сразу же после его установки. Но это не единственное преимущество MI! Вычислительная среда со временем меняется: наглядные примеры — приложения клиент/сервер и концепция сетевых вычислений. Если бы AS/400, первоначально предназначенная для интерактивной работы, не смогла приспособиться к роли сервера, она бы уже давно устарела. MI — мощнейший интерфейс не только в силу своей независимости от технологии, но и благодаря возможностям расширения. Новые инструкции и функции присутствуют почти в каждой версии системы. Интерфейс MI ориентирован на приложения, так как поддерживает необходимые для этого API, и по мере появления новых приложений добавить новые API не составит проблемы. Расширяемость архитектуры MI делает этот интерфейс чрезвычайно долговечным.Глава 5
Объекты
Сетевые вычисления и Интернет сделали тему объектных технологий бестселлером компьютерных новостей. Распространение таких языков программирования, как Java и С++, заставляет разработчиков приложений изменить свое отношение к традициям и признать преимущества новых объектно-ориентированных языков. Подобно другим технологиям, которые мы считаем новыми, объекты используются в программировании уже более 30 лет. Впервые они появились в конце 60-х годов в языках типа Simula 67, применявшихся для программ моделирования. Современные языки программирования, такие как Java, C+ + и Smalltalk — прямые потомки Simula 67. Программы моделирования имитируют поведение объектов реального мира. Аналогично, прикладные программы для бизнеса, содержащие объекты и операции над ними, моделируют реальные деловые отношения. ОС работают с аппаратными и программными объектами, такими как устройства ввода-вывода и программы. Использование объектов в ОС выглядит совершенно естественным. О создании объектно-ориентированной ОС говорят многие фирмы, такие как Microsoft, Apple, Novell/USL (UNIX Systems Laboratory) и Sun Microsystems, однако, лишь немногие из них смогли реализовать свои планы. Одна из таких фирм — Next, уже поставляющая на рынок объектно-ориентированную ОС под названием NextStep. Есть, конечно, и другая объектно-ориентированная ОС. С момента появления System/38 мы строим ОС (CPF и OS/400) по объектно-ориентированной модели[ 40 ]. Более того, мы не остановились на этом, но сделали объекты фундаментальной частью архитектуры машины. Как уже отмечалось в главе 4, MI состоит из двух частей: команд и объектов. В этой главе мы рассмотрим использование объектов в AS/400. Иногда говорят, что AS/400 это не объектно-ориентированная система, а система на основе объектов (object-based). Различие этих двух терминов имеет смысл при обсуждении языков программирования. Например, есть языки на основе объектов, такие как Ada, и объектно-ориентированные языки, такие как Smalltalk-80. Гради Буч (Grady Booch) определил различия между этими двумя типами языков. По Бучу, в языке на основе объектов отсутствует наследование[ 41 ]. Как уже вкратце упоминалось в главе 3, наследование определяет иерархию классов, где подкласс заимствует структуру или поведение одного или нескольких базовых классов. Наследование позволяет создавать новые типы объектов. Так как объекты AS/400 ничего не наследуют от других объектов, и прикладные программисты, пишущие приложения для этой системы, не могут создавать новые типы объектов, то вероятно, правильнее называть AS/ 400 системой на основе объектов. Но какое бы имя мы не выбрали, важно то, что AS/ 400 не просто использует или включает объекты, — они являются фундаментальной частью ее архитектуры. В упрощенном виде объект — это просто контейнер, внутри которого находятся пользовательские и системные структуры данных. Объект инкапсулирован, что означает (как мы условились ранее) невозможность заглянуть внутрь него. Система, построенная на основе объектной модели независима от аппаратуры. Первопричиной использования объектов в System/38 было желание инкапсулировать детали, чтобы позже их можно было изменять без влияния на прикладные программы. Еще одно достоинство объектов — целостность. Оригинальная System/3 была байтовой машиной (то есть все в ней располагалось на границе байта), а ее команды содержали однобайтовый код операции. Они занимали несколько последовательных байтов памяти, но никакого обязательного выравнивания команд не было. Более того, все разряды кода были задействованы для задания типа операции и местоположения операндов. Практически любая комбинация разрядов в байте могла быть интерпретирована как допустимый код операции System/3. Это вызывало проблему, если в программе непреднамеренно происходил переход в область данных: процессор мог продолжать выбирать байты данных и интерпретировать их как команды. Такая программа могла исполняться долгое время, сея хаос внутри системы. Ликвидировать последствия таких ошибок было весьма сложно. В этом плане System/3, ничем не отличалась от большинства других вычислительных систем того времени. Например, в обычной системе цепочка байтов может быть интерпретирована, практически, как угодно. Можно взять байты из одной части программы и перемножить их с байтами из другой ее части. Процессор «не волнует», имеет ли смысл такая операция. Он работает с байтами, а не с тем, что они представляют. Итак, мы были очень обеспокоены проблемами целостности, и сделали все, чтобы таковых не возникало в AS/400. Команды в этой системе могут работать только с теми объектами, для которых предназначены. Некоторые универсальные команды, такие как «Создать объект», применимы ко всем объектам, другие — работают только с объектами определенных типов. Таким образом, в AS/400 нельзя использовать объект не по назначению, как в обычной системе. В результате целостность значительно повышается. На эту проблему можно взглянуть и с другой стороны. В большинстве ОС, все, что находится в постоянной памяти, считается файлом (в MS-DOS или MVS файлом называют набор данных). Файлы могут иметь различное назначение, но такая классификация определяется лишь по соглашению. Вы можете читать объект-программу так, как если бы это был файл. В OS/400 это невозможно (как и создать вирус, по крайней мере, в слое над MI), так как термин «файл» применим лишь к небольшому числу типов объектов, и программа определенно файлом не является. Кстати, с этим связаны некоторые неудобства, присутствовавшие в System/38, где значительная часть информации об объектах была недоступна программам. COMMON (группа пользователей AS/400) многократно просила включить во все команды отображения, такие как, например, «DSPOUTQ» («Display Output Queue»), «DSPJOBQ» («Display Job Queue»), опцию генерации выходного файла, чтобы информация, хранящаяся внутри объектов, могла быть считана программно. В конце концов, мы добавили такую возможность в некоторые команды:, которые первоначально ей не обладали (а в «DSPOUTQ» и «DSPJOBQ» ее нет и сейчас). Но исчерпывающим ответом на эти запросы было создание API, позволяющих поместить информацию об объектах и системе в объект, известный как пользовательское пространство. Этот объект программы могут читать быстрее, чем файлы базы данных.Имена объектов
В System/38 объекты были как в ОС, так и в MI. Определением этих объектов и выбором имен для них занимались две разные группы. Одна разрабатывала объекты CPF, (которая в AS/400 была переименована в OS/400[ 42 ]), другая — разрабатывала набор команд и системные объекты MI. Хорошо, что иногда между объектом OS/400 и объектом MI соотношение один к одному, тогда это тот же самый объект. Все усложняется, когда это разные объекты. Все объекты OS/400 состоят из одного или нескольких системных объектов MI. Другими словами, типы объектов OS/400 и типы системных объектов MI соотносятся как один к одному или как один ко многим, но никогда как многие к одному или многие ко многим. Пример, иллюстрирующий это положение, мы рассмотрим в следующем разделе. А теперь, прежде чем идти дальше, я должен внести ясность еще в одну область. Иногда, объекты OS/400 и системные объекты MI, даже при соотношении между ними один к одному, могут называться по-разному. Например, в OS/400 есть объект «библиотека», в MI эквивалентный объект называется «контекст». Как это могло получиться? Ответ восходит ко времени создания System/38 двумя разными группами проектировщиков с разными подходами к выбору названий. Один подход таков: коль Вы создаете новую систему — то все надо переименовать, и пусть пользователи, видя новые названия вдумаются в новую структуру. По этой логике, если Вы собираетесь реализовать библиотеку и назвали ее библиотекой, то кто-нибудь обязательно скажет: «Я знаю, что такое библиотека; я уже работал с системой, где есть библиотеки». Между тем, библиотека в другой системе может полностью отличаться от Вашей. Если же дать библиотеке другое название, например «контекст», то никто не сможет априори строить о ней какие-либо предположения. Данный подход к именам защищал Гленн Хенри — менеджер программирования System/38 и, следуя подобным взглядам, группа, разрабатывавшая системные объекты MI, породила некоторые весьма странные названия.
Названия же для объектов ОС выбирала другая группа, предпочитавшая подход Томаса Эдисона (Thomas Edison): лучше даже не вполне подходящее, но уже знакомое покупателям имя. Когда Эдисон продвигал идеи использования электроэнергии, он решил выбирать названия, знакомые каждому, использующему природный газ. Он говорил, что к дому подводятся электрические магистрали (main), подобно газовым или водопроводным магистралям, хотя main — это труба или канал, а электроны, обычно, попадают в дом не по трубе. Он также называл нагревательный элемент кухонной плиты электрической горелкой, чтобы электрическая плита казалась чем-то знакомым людям, имевшим дело с газовыми горелками (скажем честно — электричество в нагревающем элементе не «горит»). Наша группа разработчиков ОС понравилась бы Эдисону.
Один подход таков: коль Вы создаете новую систему — то все надо переименовать, и пусть пользователи, видя новые названия вдумаются в новую структуру. По этой логике, если Вы собираетесь реализовать библиотеку и назвали ее библиотекой, то кто-нибудь обязательно скажет: «Я знаю, что такое библиотека; я уже работал с системой, где есть библиотеки». Между тем, библиотека в другой системе может полностью отличаться от Вашей. Если же дать библиотеке другое название, например «контекст», то никто не сможет априори строить о ней какие-либо предположения. Данный подход к именам защищал Гленн Хенри — менеджер программирования System/38 и, следуя подобным взглядам, группа, разрабатывавшая системные объекты MI, породила некоторые весьма странные названия.
Названия же для объектов ОС выбирала другая группа, предпочитавшая подход Томаса Эдисона (Thomas Edison): лучше даже не вполне подходящее, но уже знакомое покупателям имя. Когда Эдисон продвигал идеи использования электроэнергии, он решил выбирать названия, знакомые каждому, использующему природный газ. Он говорил, что к дому подводятся электрические магистрали (main), подобно газовым или водопроводным магистралям, хотя main — это труба или канал, а электроны, обычно, попадают в дом не по трубе. Он также называл нагревательный элемент кухонной плиты электрической горелкой, чтобы электрическая плита казалась чем-то знакомым людям, имевшим дело с газовыми горелками (скажем честно — электричество в нагревающем элементе не «горит»). Наша группа разработчиков ОС понравилась бы Эдисону.
Объекты OS/400 и системные объекты MI
Несколько типов объектов имеются и в OS/400, и в MI. Типы объектов OS/400 перечислены в таблице 5.1. Для сравнения, в таблице 5.2 приведены системные объекты MI. Помните, что в каждой новой версии AS/400 добавляются новые функции и даже новые объекты. Списки объектов таблицах 5.1 и 5.2 достаточно полны для нашего обсуждения в этой и следующей главе, но включить в них все типы объектов невозможно.4| Графический набор символов | Служебная программа |
| Документ | Описание сетевого интерфейса |
| Идеографическая таблица символов | Описание сессии |
| Идеографическая таблица сортировки Описание подсистемы | |
| Идеографический словарь | Словарь правописания |
| Индекс поиска информации | Таблица |
| Класс | Библиотека |
| Класс описания сервиса | Описание линии |
| Команда | Определение меню |
| Область данных | Определение группы панели |
| Описание задания | Пользовательский индекс |
| Описание контроллера | Очередь сообщений |
| Описание редактирования | Программа |
| Описание устройства | Модуль |
| Очередь данных | Определение продукта |
| Очередь заданий | Пользовательский профиль |
| Папка | Справочная таблица трансляции кода |
| Словарь данных | Описание режима |
| Список документов | Выходная очередь |
| Список конфигурации | Файл сообщения |
| Список прав | Журнал |
| Таблица управления формами | Описание машины S/36 |
| Файл | Определение запроса |
| Формат диаграммы | Приемник журнала |
| лок транзакции | Описатель режима |
| Группа доступа | Индекс |
| Индекс пространства данных | Очередь |
| Класс описания сервиса | Описание логического устройства |
| Контекст | Модуль |
| Курсор | Пространство управления процессом |
| Описание контроллера | Описатель сети |
| Пространство дампа | Профиль пользователя |
| Пространство данных | Программа (3 подтипа) |
| Пространство цепочки байтов | Пространство журнала |
| Словарь | Пространство |
| Список прав | Порт журнала |
Некоторые объекты OS/400 из таблицы 5.1 полностью соответствуют системным объектам MI из таблицы 5.2, при этом имена объекта в двух разных наборах могут совпадать, а могут и не совпадать. Пример совпадения имен — «программа», несовпадения — «библиотека» и «контекст».
 Рисунок 5.1 Объекты файла базы данных OS/400
Рисунок 5.1 Объекты файла базы данных OS/400
На рисунке можно видеть набор отдельных компонентов. Один из системных объектов MI — область данных. Она используется базой данных для хранения физических данных вместе с определением полей записей. Еще один системный объект — индекс области данных — содержит описание того, как осуществлять доступ к этим данным. В следующей главе мы увидим, как индекс области данных обеспечивает логическое представление физических данных. Третий объект — курсор, осуществляющий фактический доступ к записям в области данных и использующий индекс области данных для формирования логического представления. Курсор предоставляет управляющие структуры для доступа к данным в области данных, а также содержит пользовательские буферы. Четвертый объект — пространство, в которое помещается результат опе- Другие объекты OS/400 относятся к системным объектам MI как один ко многим. Посмотрите на пример на рисунке 5.1: здесь файл базы данных OS/400 состоит из пяти системных объектов MI, и ему соответствуют четыре разных типа системных объектов MI (в нашем примере два объекта-пространства). Фактически, файл могут составлять намного больше объектов. Для каждого из них существует курсор, и даже однокомпонентный файл объединения (join file) может владеть или ссылаться на 32 индекса области данных. База данных, а также связи между разными системными объектами MI будут рассмотрены в следующей главе. рации над базой данных (по сути дела, это буфер ввода-вывода). Последний, показанный в примере объект, который также является пространством, содержит описание файла. Единственная его функция — поиск других объектов.
Поиск объектов
Найти объект в базе данных оригинальной System/38 было очень легко, так как все они были поименованы: Вы просто отыскивали нужное имя в библиотеке. Библиотека давала возможность организации объектов в группы и обеспечивала их поименный поиск. Эта структура была перенесена и в AS/400.Библиотеки
В OS/400 библиотека — объект, который используется для поиска других объектов в базе данных. В отличие от многоуровневой иерархии каталогов в ОС ПК и Unix, библиотека OS/400 имеет одноуровневую иерархию. Для иллюстрации рассмотрим структуру имен объектов OS/400. Чтобы найти объект OS/400 требуется знать имена библиотеки и объекта (то есть, путь «Библиотека/Объект»), а также его тип (одно и то же имя могут иметь несколько объектов, но все они — объекты разного типа). Другими словами, в библиотеке может содержаться программа SAM и пространство данных SAM, но двух программ с именами SAM быть не может. Кроме того, каждый объект находится в одной и только в одной библиотеке. Библиотека не может ссылаться на другие библиотеки, иначе была бы нарушена одноуровневая иерархия «Библиотека/Объект». Из этого правила есть лишь одно исключение — специальная библиотека с именем QSYS, в которой, и только в которой, находятся некоторые специальные объекты OS/400 например, профили пользователей, определяющие права последних, и объекты конфигурации ввода-вывода, используемые для выполнения соответствующих операций. Подробно эти объекты рассматриваются в последующих главах. Рисунок 5.2 Структура библиотеки OS/400
Рисунок 5.2 Структура библиотеки OS/400
Структура библиотеки OS/400 показана на рисунке 5.2. В данном примере QSYS содержит профиль пользователя (JOHN), библиотеку (LIB1) и описание устройства (DEVD1). Библиотека LIB1 содержит файл базы данных (DB), очередь данных (DQ) и выходную очередь (OQ). Позже мы увидим, что с каждым заданием в системе связан список библиотек. Этот список указывает системе, где следует искать объект, а также задает порядок поиска в библиотеках.
Разделяемые папки
Разделяемые папки были введены в AS/400, главным образом, для поддержки функций Office[ 43 ]. Эту идею мы позаимствовали из System/36, которая была отличной офисной системой. Для поддержки функций Office в AS/400 были добавлены объекты-папки. Интегрированная поддержка обеспечивает систему хранения всех объектов Office, содержащих необходимые данные. Среди традиционных элементов, которые могут храниться там — почта, документы, программы и файлы. Библиотечный способ хранения документов дает пользователям возможность рассматривать эту систему как электронную картотеку, содержащую папки. Средства управления позволяют организовывать объекты, помещая их в папки. Папки могут содержать другие папки и поддерживают интерактивный поиск. Разделяемые папки и в PC Support[ 44 ] на System/36, и в AS/400 помогают обеспечить эффективность офисного использования ПК. В дополнение к упомянутым традиционным элементам Office, в разделяемых папках могут храниться электронные таблицы, диаграммы, рисунки, а также программы и файлы ПК. Доступ к файлам ПК, хранящимся на AS/400, осуществляется так же, как если бы они хранились локально на ПК. Файлы могут пересылаться с ПК и назад, при этом автоматически выполняются преобразования данных. Если ПК поддерживает несколько сессий, то он может взаимодействовать с несколькими системами AS/400, с несколькими заданиями на одной AS/400 или с любой комбинацией этих вариантов. IBM несколько раз модифицировала PC Support, но он быстро «старел» и не соответствовал потребностям новых клиент/серверных приложений. Кроме того, PC Support поддерживал не все ОС ПК, нужные заказчикам. Хотя он и позволял использовать DOS, DOS с расширенной памятью и OS/2, но (что важно!) не мог поддерживать Microsoft Windows. PC Support требовал радикальной замены, и IBM предложила своим заказчикам совершенно новый продукт. Client Access for OS/400 обеспечивает мощную платформу для распределенных клиент/серверных вычислений. Для привлечения новых заказчиков потребовалось также внести изменения и в файловую систему AS/400. Библиотеки для обслуживания базы данных и папки для Office и файлов ПК в целом справлялись с задачей, но им не помешали бы дополнительные возможности. В результате, была создана новая файловая система.Интегрированная файловая система
Что если объединить в одну структуру файловую систему ПК, файловую систему Unix, а также библиотечную систему и разделяемые папки OS/400? Тогда приложение, написанное для использования файловой системы ПК или Unix, могло бы напрямую обращаться к данным, хранящимся на AS/400. Такая интегрированная файловая система появилась в V3R1 и была названа интегрированной файловой системой IFS (integrated file system). Она объединяет все файловые системы на AS/400 общим интерфейсом и общим набором правил. Более того, любой пользователь Client Access, предпочитающий новейшие версии Windows или OS/2, может на своей рабочей станции в графическом режиме работать с библиотеками, папками и всеми новыми файловыми системами. Первой и основной проблемой было — определить конструкцию такой файловой системы. Ведь ее отдельные части не предназначались для функционирования в единой структуре. Решение оказалось проще, чем опасались сначала. Посмотрите еще раз на рисунок 5.2 и обратите внимание на то, что структура библиотеки OS/400 — это, по сути, подмножество структуры, используемой в ОС ПК, таких как DOS и OS/2. Пусть в мире ПК используются другие названия, но структура-то та же! ОС ПК имеют дело с файлами, а не с объектами. Библиотека там называется каталогом, внутри которого хранятся файлы. В отличие от библиотечной структуры OS/400, в каталогах ПК могут находиться другие каталоги, обычно называемые подкаталогами. Таким образом, имена файлов ПК имеют многоуровневую иерархию, в противоположность одноуровневой структуре библиотек OS/400. Имя файла ПК может иметь вид КАТ1\КАТ2\...\КАТп\ИМЯФАЙЛА. За исключением обратной косой черты (\), это — надмножество структуры имен библиотеки OS/400. Файловая структура Unix — также надмножество библиотечной структуры OS/400. Вспомните, что объект OS/400 может находиться только в одной библиотеке, иначе говоря, к любому объекту OS/400 имеется единственный путь. Файловая система Unix поддерживает наличие множественных путей к одному и тому же объекту. Для объединения всех этих файловых систем мы решили взять единый корень из ПК-подобной файловой системы и поместить в него все остальные. На рисунке 5.3 показано, как видится вся AS/400 и ее файловые системы клиенту Windows. AS/400 представлена как один диск, на котором находятся каталоги в стиле ПК, каталоги в стиле Unix, библиотеки OS/400 (QSYS.LIB), разделяемые папки OS/400 (QDLS) и еще несколько файловых систем поддержки новых приложений. В число последних входят: система, полностью совместимая с POSIX (QOpenSys); файловая система для пользователей LANServer (QLANSrv); файловая система для Novell Netware (QNETWARE); Network File System (QNFS) фирмы Sun Microsystems. Поддерживаются и другие файловые системы, а в будущем, по мере того как все больше приложений и их файловых систем будут использовать AS/400, добавятся новые. Соглашение об именах в IFS основано на стандарте ПК. Имя имеет вид КАТ1\КАТ2\...\КАТп\ИМЯФАЙЛА. К радости тех, кто не может запомнить, когда использовать прямую (/), а когда обратную (\) косую черту, новое соглашение допускает обе. Вы даже можете использовать разные разделители в одном и том же имени. В соответствии со стандартом POSIX, длина имен файлов и каталогов увеличена. На AS/400 имена в каталогах IFS хранятся в формате Unicode, который, будучи международным стандартом, поддерживает использование разных языков, включая двухбайтовые наборы символов, используемые в ряде стран. Все RISC-системы теперь позволяют хранить информацию в базе данных в формате Unicode. IFS дает возможность пользователю рассматривать файл, хранящийся на AS/400, как расширение его собственной файловой системы. Пользователи Unix считают, что они имеют дело с файловой системой Unix, а пользователи ПК (см. рисунок 5.3) — что это файлы ПК. К тому же, если оба пользователя могут работать с одними и теми же данными, отпадает необходимость копирования этих данных. Те, кто привык к ПК или к AS/400 продолжают использовать QDLS и QSYS.LIB соответственно, а новые пользователи могут работать со своими приложениями с помощью любой из поддерживаемых файловых систем. Пользователям ПК и Unix даже не требуется изучать CL — язык команд AS/400. Они могут применять любые команды: и утилиты для DOS, Windows или Unix. Рисунок 5.3 Интегрированная файловая система с точки зрения Windows-клиента
Рисунок 5.3 Интегрированная файловая система с точки зрения Windows-клиента
Нельзя забывать, что главная задача IFS — обеспечение доступа к данным. Поэтому либо формат данных должен быть изначально совместим с приложением, которое их запрашивает, либо данные должны быть преобразованы соответствующим образом. OS/400 поддерживает большинство таких преобразований, например, между кодировкой EBCDIC, (Extended Binary Coded Decimal Interchange Code) используемой «родными» приложениями AS/400, и ASCII (American Standard Code for Information Interchange), используемой ПК. Поддержка Unicode в базе данных RISC-систем дает возможность разработчикам приложений использовать универсальный формат данных на разных платформах. При этом отпадает необходимость специальных версий программ для стран, где языки требуют двухбайтового представления. Приложение может быть использоваться по всему миру.
Доступ к объектам
Недостаточно просто найти объект. Чтобы получить к нему доступ или модифицировать объект, пользовательской или системной программе необходимы некоторые средства доступа. Для системных объектов эти средства находятся на уровне MI. OS/400 отвечает за управление своими объектами, каждый из которых состоит из системных объектов, отслеживая последние. Компонент управления объектами в SLIC работает с системными объектами и ничего не «знает» об объектах OS/400. И в этом случае разработчики AS/400 старались поддержать независимость между двумя частями ОС, выше и ниже MI. Единственной плоскостью соприкосновения между ними является MI, и именно здесь обеспечиваться доступ к объектам. Доступ к системному объекту осуществляется посредством системного указателя, который, занимая 16 байтов памяти, содержит адрес системного объекта, а также информацию о его типе. Более подробно формат системного указателя рассматривается в главе 8.Адресация на базе возможностей
Системный указатель может также содержать сведения о типе операций, которые выполнимы над объектом. Обычно, такая информация называется полномочиями (authority). Указатель, содержащий адрес объекта и полномочия, называется возможностью (capability). System/38 использует адресацию на базе возможностей, все системные указатели содержат как адрес, так и полномочия. В AS/400 способ предоставления пользователям полномочий по работе с объектами был изменен. Причина изменений — забота о защищенности системы. Если полномочия хранятся в указателе, то пользователь, обладающий указателем, обладает и полномочиями. Мало того, он даже может передать указатель или его копии другому пользователю. Предположим, мы хотим дать пользователю право выполнения одиночной операции над объектом, то есть предоставить программе пользователя однократный доступ или возможность модификации данных объекта, но не на постоянной основе. Однако после того, как доступ к системному указателю открыт, «закрыть» его невозможно. Для ограничения полномочий пользователя и повышения степени защищенности IBM добавила в AS/400 методы предоставления временных полномочий. Одновременно, мы удалили полномочия из указателей всех пользовательских программ, оставив их только для указателей, используемых ОС в системном состоянии (подробности —в главе 7). Так что говорить об AS/400 как о системе с адресацией на базе возможностей неправильно. За исключением только что указанного случая, такой способ адресации в AS/400 не используется.Разрешение системных указателей
Системный указатель считается разрешенным, если содержит прямой адрес системного объекта. Указатель, содержащий символический адрес, называется неразрешенным. Символический адрес используется для поиска объекта в библиотеке и состоит из имени, типа и подтипа объекта, причем последний для поиска не требуется. Его значение определяется пользователем, и служит лишь для дальнейшей классификации объектов OS/400. На рисунке 5.4 показан процесс разрешения системного указателя по команде «RESOLVE». Команда использует имя и тип системного объекта из неразрешенного указателя, а также запрашиваемые полномочия. Выполняется поочередный просмотр библиотек из списка библиотек, связанного с заданием, выдавшим данную команду. Просмотр длится, пока не будет найден заданный объект. Рисунок 5.4 Разрешение системного указателя
Затем выполняется тройная проверка. Прежде всего, проверяется тип объекта, чтобы гарантировать корректный возврат объекта; затем, есть ли у пользователя права, указанные в команде «RESOLVE» (эта информация хранится в профиле пользователя); и, наконец, выясняется, возможен ли доступ к объекту (не был ли он заблокирован другим пользователем). Если результаты тройной проверки удовлетворительны, то в неразрешенный системный указатель записывается адрес системного объекта. Как отмечалось выше, полномочия могут быть помещены только в указатель, возвращаемый системной программе. После того как указатель разрешен, программа может использовать его при последующих обращениях к объекту; повторять процедуру разрешения при этом не требуется.
Другие типы указателей
Системный указатель обеспечивает доступ к системному объекту, но при выполнении некоторых операций нужно работать с данными, содержащимися внутри таких объектов. Для этого используются другие типы указателей. Но прежде чем рассказать о них, я хочу остановиться на внутренней структуре системного объекта. Итак, системный объект состоит из двух основных частей: функциональной и пространственной. Содержимое функциональной части зависит от типа системного объекта, например, для программы — это последовательность команд. Пространственная часть системного объекта (часто называемая ассоциированным пространством) s просто байтовое пространство, используемое в качестве рабочего. Такая структура характерна для всех системных объектов, за единственным исключением: системный объект «пространство» не имеет функциональной части. Необходимость отдельной пространственной части в объекте объясняется способом представления памяти в MI. Вспомните, что для поддержания независимости от нижележащей технологии, в MI нет понятия памяти в традиционном смысле; только объекты и ничего кроме них. Между тем, указатели и данные пользователей должны где-то храниться. Место для этого s пространственная часть системных объектов. Рисунок 5.5 Системные объекты
Рисунок 5.5 Системные объекты
Так как все системные объекты инкапсулированы, манипуляции с байтами внутри функциональной части невозможны s нельзя даже заглянуть внутрь ее. Очевидно, нужен некий способ доступа к информации, находящейся в пространственной части (рабочем пространстве). Этот способ предоставляет нам пространственный указатель. Пространственный указатель очень похож на системный. Он имеет длину 16 байтов и содержит адрес. Отличие в том, что адрес из пространственного указателя указывает на некоторый байт где-то в пространственной части системного объекта. Таким образом, пространственные указатели можно использовать для доступа и манипуляции содержащимися там байтами. Другое важное различие между двумя типами указателей состоит в операциях с адресом, которые каждый из них может выполнять. Адрес в пространственном указателе может быть изменен программой MI так, чтобы указывать на другой байт в том же пространстве. Адрес в системном указателе лишь указывает на начало объекта и изменить его нельзя. Пользователь, имеющий соответствующие права, может с помощью системного указателя получить пространственный указатель на объект. Второй объект, показанный на рисунке 5.5, также содержит пространственный указатель. Рисунок иллюстрирует, как указатель такого типа предоставляет доступ к байтовому пространству первого объекта. В дополнение к системным и пространственным, в MI есть еще четыре типа указателей. Указатель данных аналогичен пространственному, но содержит описание На рисунке 5.5. Вы можете видеть два системных объекта, каждый из которых имеет функциональную и пространственную части. Пространственная часть может содержать как указатели, так и данные. На рисунке пространственная часть второго объекта содержит системный указатель на первый системный объект. Системные указатели всегда указывают на системные объекты, но лишь на начало, так что с их помощью не много можно сделать. Это и понятно, ведь основное назначение указателя s обеспечить доступ к объектам. Но как быть, если надо проникнуть внутрь объекта и поработать с байтами? типа данных, что позволяет рассматривать цепочку байтов внутри пространства как данные любого типа. В качестве аналогии можно привести указатель языка С. Указатель команд служит для определения места команды в последовательности и используется для выполнения переходов. Четыре рассмотренных типа указателя (системный, пространственный, данных и команд) присутствовали в первом варианте System/38. Позднее для обеспечения доступа к внутренней памяти была добавлена специальная версия пространственного указателя s машинный пространственный указатель. В AS/400 с появлением ILE был добавлен новый процедурный указатель. Процедурные указатели используются воперациях вызова/возврата, рассмотренных в главе 4.
Характеристики системных объектов
Теперь можем, наконец, перечислить основные характеристики всех системных объектов (некоторые из них мы рассмотрим сейчас, а некоторые —в следующих главах). Системные объекты должны быть явно созданы командой MI «Create». Команда «Create» указывает на заданный пользователем шаблон, содержащий атрибуты и данные для объекта. Шаблон содержится в объекте-пространстве. Атрибуты системного объекта могут быть материализованы. Системный объект может быть явно удален. Все системные объекты, встречающиеся в некотором контексте, имеют имена. Системный объект может не иметь имени, если на него нет ссылки в библиотеке или файловой системе. Пример — системный объект, используемый исключительно SLIC. Адресация системных объектов обеспечивается посредством системных указателей. Системные объекты содержат пространство, в котором находятся указатели и данные. Системные объекты создаются либо как временные, либо как постоянные. Постоянный объект (persistence) остается в памяти системы, пока не будет явно уничтожен. Временный объект удаляется при всяком выполнении операции IPL (начальная загрузка). Временные объекты могут быть помещены в группы доступа — системный объект, позволяющий объединять несколько объектов и работать с ними как с целым. Права доступа к системным объектам контролируются аппаратно. Использование объекта синхронизируется посредством механизма замков. Постоянство объекта (часть характеристики 8) требует некоторых дополнительных пояснений. Итак, постоянный объект продолжает существовать в системе, пока не будет специально уничтожен. Присутствуя в памяти, он может легко использоваться совместно разными пользователями. Именно этим AS/400 сильно отличается от других систем, которые требуют располагать разделяемую или предназначенную для длительного хранения информацию в отдельной файловой системе. Позже мы рассмотрим, как одноуровневая память AS/400 поддерживает постоянство объектов. В будущем постоянство объектов очень пригодится для поддержки объектно-ориентированных баз данных. Необходимо, чтобы объекты продолжали существовать, и после того, как их создатель ушел со сцены. И здесь уникальные возможности постоянства объектов AS/400 дают ей существенные преимущества перед другими ОС, вынужденными прибегать к хранению постоянных объектов в отдельной файловой системе. Не каждый объект должен быть постоянным, этот параметр задается при его создании. Постоянные объекты требуют дополнительных расходов, так на всем протяжении своего существования используют системные ресурсы. Пример объекта, который имеет смысл создавать как постоянный — область хранения записей базы данных. Как уже упоминалось, временные объекты исчезают при каждой загрузке системы. В обычной системе области временной памяти связаны с создавшими их заданиями, не могут разделяться пользователями и исчезают, когда задание завершено. В AS/400 вся память, содержит ли она постоянные или временные объекты, может разделяться пользователями и объекты остаются в системе даже после завершения задания. При разработке AS/400 в качестве некоторого, отличного от завершения задания, момента удаления временных объектов была выбрана загрузка системы. Это оказалось удобным, так как снижает накладные расходы. Например, если бы мы разрушали временную библиотеку задания по завершении последнего, то производительность при исполнении остальных заданий несколько снижалась бы. И мы решили перенести накладные расходы на время выполнения загрузки. Примером временного объекта может служить индекс области данных, обеспечивающий проекцию базы данных: если он создается для выполнения единственного запроса к базе данных, то нет смысла делать его постоянным. Обратите внимание, что постоянный объект может пережить крах системы, иногда объекты и создаются постоянными только для того, чтобы не потерять их в случае сбоя системы. Напротив, если для восстановления системы ее потребуется перезагрузить, то все временные объекты будут потеряны. Внутренние детали обработки системой временных и постоянных объектов будут объяснены далее.Программные объекты
До сих пор мы рассматривали только системные объекты и их характеристики. Однако в MI есть другие элементы данных, также называемые объектами, но имеющие очень малое сходство с обычными, что создает еще одну терминологическую проблему. В главе 4 мы рассмотрели содержимое оригинального шаблона программы MI — последовательность команд и таблицу определения объектов ODT. ODT описывает операнды, используемые программой. В результате неудачного выбора имен проектировщики MI для System/38 называли эти операнды объектами, а точнее программными объектами. Таким образом, двухбайтовое двоичное число считается объектом. Программные объекты не имеют с системными объектами MI ничего общего, кроме названия. Но так как программный объект очень легко спутать с системным объектом типа «программа», то мы, для простоты, будем с этого момента использовать слово «объект» только для обозначения системных объектов MI.Внутри системного объекта
Хотя в MI нет концепции памяти, все процессоры AS/400 используют физическую память, включая основную память и диск. Системные объекты, расположенные ниже MI, реализованы как строго определенные структуры, хранящиеся в этой памяти. За создание и управление этими структурами данных отвечает компонент управления объектами в SLIC. Давайте рассмотрим формат этих структур данных и их использование для представления системных объектов MI.Сегментированная память
Понятия памяти и дискового пространства верны только ниже MI. В отличие от OS/ 400, SLIC «знает» о наличии этой памяти и работает с нею. Вся основная память и дисковое пространство в AS/400 находятся внутри большого единого адресного пространства, обычно, называемого одноуровневой памятью. Объем этой памяти равен общему числу байтов, на которое может ссылаться 64-разрядный адрес8. Одноуровневая память — это используемая в AS/400 разновидность виртуальной памяти, обеспечивающая логическое представление памяти, которое не обязательно соответствует ее физической структуре. Достаточно представлять себе одноуровневую память как очень большое адресное пространство, внутри которого все и хранится. Различия между обычными системами виртуальной памяти одноуровневой памятью AS/400 описаны в главе 8. Адресное пространство AS/400 логически разделено на блок последовательных байтов, называемых сегментами. В System/38 и первых AS/400 использовалось два размера сегмента: 64К и 16М. 16-мегабайтный сегмент состоял из 256 сегментов по 64К и иногда назывался сегментной группой. При переходе на 64-разрядную адресацию сегменты меньшего размера были исключены, остался только сегмент размером в 16М. Сегменты не перекрываются и всегда начинаются с границы. Это означает, что 24 младших (самых правых) бита адреса первого байта каждого сегмента размером 16М всегда равны 0. Каждый 16-мегабайтный сегмент уникально задается 40 старшими (самыми левыми) битами 64-разрядного адреса. Отображение адресного пространства AS/400 на физическую основную память и диски осуществляется компонентом управления памятью SLIC с помощью блоков памяти по 4К, называемых страницами9. Сегмент состоит из целого числа таких страниц, которые не обязательно расположены в физической памяти последовательно.Структура системного объекта
На рисунке 5.6 изображен формат системного объекта в одноуровневой памяти. Первые 32 байта содержат заголовок, предоставляющий информацию о самом сегменте. Далее следует заголовок EPA (Encapsulated Program Architecture). ЕРА была создана для спецификации внутренней структуры инкапсулированных объектов System/38, а затем та же внутренняя структура была перенесена в AS/400. Заголовок ЕРА содержит атрибуты (свойства) общие для всех системных объектов, независимо от типа. Заголовок сегмента и заголовок ЕРА вместе занимают первые 256 байтов всякого системного объекта. 9System/38 и первые модели AS/400 использовали размер страницы в 512 байтов. Размер страницы был увеличен до 4К при переходе на 64-разрядную RISC-аппаратуру. 8Число байтов, адресуемых 64-разрядным числом, настолько велико, что большинство людей не могут соотнести его с чем-либо, что можно «пощупать руками». Когда в AS/400 был 48-разрядный адрес, мы, бывало, говорили, что число адресуемых байтов равно расстоянию от Земли до Солнца и обратно в миллиметрах. Для 64-разрядного адреса нужна какая-то новая аналогия. Рисунок 5.6. Структура системного объекта Рисунок 5.6. Структура системного объекта
Рисунок 5.6. Структура системного объекта
Каждый тип объекта содержит свойства, присущие только ему: свойства программы уникальны по сравнению с областью данных, и наоборот. Эти индивидуальные свойства содержатся в специфическом заголовке (customized header) объекта, следующем после заголовка ЕРА. После трех заголовков следуют компоненты, составляющие данный объект: например, за специфическим заголовком программы размещается последовательность команд. Так как все системные объекты имеют пространственную часть, пространственный компонент присутствует всегда. В MI он называется ассоциированным пространством. Конкретный набор компонентов и порядок их следования зависят от типа объекта. Типов системных объектов слишком много, для того чтобы подробно описывать специфические заголовки и компоненты объектов. Однако некоторые примеры мы рассмотрим.
Многосегментные объекты
Как мы уже говорили, системные объекты занимают один или несколько сегментов и всегда начинаются с границы сегмента. Первый сегмент называется базовым — его имеет каждый объект, и на него всегда ссылается системный указатель. В зависимости от типа объекта, он может занимать один или несколько вторичных сегментов, большинство объектов занимают их ассоциированным пространством. Ни один сегмент не может быть частью более чем одного системного объекта. На рисунке 5.7 показан системный объект, занимающий два сегмента, при этом системный указатель ссылается на базовый сегмент. Обратите внимание, что у каждого сегмента — свой заголовок. Заголовок сегмента содержит информацию о сегменте, а не о содержащемся в нем объекте. В заголовке сегмента также содержатся адреса, связывающие сегменты друг с другом. Заголовок ЕРА содержится только в базовом сегменте. За заголовком ЕРА, также только в базовом сегменте, следует специфический заголовок объекта. Рисунок 5.7 Многосегментные объекты Выделение сегментов происходит при создании системного объекта посредством команды «Create xxx», где «xxx» — тип создаваемого объекта. На рисунке 5.8 показаны исходные параметры и результаты команды «Create» на уровне MI. Эта команда использует пространственный указатель для доступа к шаблону объекта, содержащегося в пространственном объекте. Читателю следует иметь в виду, что команды «Create xxx» MI — это не то же самое, что и команды «CRTxxx» OS/400. Например, команда OS/400 «CRTRPGPGM» должна выполнить ряд предварительных шагов, прежде чем дело дойдет до заключительного прохода компиляции программы — вызова «Create» в MI. Исполнение этой команды на уровне MI приводит к созданию в одноуровневой памяти базового и вторичных сегментов.
Выделение сегментов происходит при создании системного объекта посредством команды «Create xxx», где «xxx» — тип создаваемого объекта. На рисунке 5.8 показаны исходные параметры и результаты команды «Create» на уровне MI. Эта команда использует пространственный указатель для доступа к шаблону объекта, содержащегося в пространственном объекте. Читателю следует иметь в виду, что команды «Create xxx» MI — это не то же самое, что и команды «CRTxxx» OS/400. Например, команда OS/400 «CRTRPGPGM» должна выполнить ряд предварительных шагов, прежде чем дело дойдет до заключительного прохода компиляции программы — вызова «Create» в MI. Исполнение этой команды на уровне MI приводит к созданию в одноуровневой памяти базового и вторичных сегментов.
 Рисунок 5.8 Создание объекта
Для отражения наличия нового объекта обновляются различные справочники, поддерживаемые SLIC. Компоненту управления памятью нужен доступ к сегменту, поэтому выполняется обновление одного из справочников компонента. Если объект создается в библиотеке (аналогичный термин ниже MI — контекст), то туда также нужно внести его имя и местоположение. Если библиотека не задана, то объект помещается в текущую библиотеку задания, вызвавшего команду «Create» (одна библиотека из списка для каждого задания всегда обозначается как текущая). Аналогично, следует обновить профиль пользователя или группы, чтобы обозначить владельца нового объекта. Заключительный этап — создание системного указателя на объект и возвращение его пользователю, запросившему о создании.
Рисунок 5.8 Создание объекта
Для отражения наличия нового объекта обновляются различные справочники, поддерживаемые SLIC. Компоненту управления памятью нужен доступ к сегменту, поэтому выполняется обновление одного из справочников компонента. Если объект создается в библиотеке (аналогичный термин ниже MI — контекст), то туда также нужно внести его имя и местоположение. Если библиотека не задана, то объект помещается в текущую библиотеку задания, вызвавшего команду «Create» (одна библиотека из списка для каждого задания всегда обозначается как текущая). Аналогично, следует обновить профиль пользователя или группы, чтобы обозначить владельца нового объекта. Заключительный этап — создание системного указателя на объект и возвращение его пользователю, запросившему о создании.
 Содержимое заголовков
Содержимое заголовков
Теперь, после рассмотрения структуры системных объектов и их отображения на сегменты памяти можно перейти к рассмотрению содержимого заголовков сегмента и ЕРА. Как мы видели на рисунке 5.6, заголовок сегмента занимает первые 32 байта каждого сегмента, составляющего системный объект. Заголовок ЕРА присутствует только в базовом сегменте системного объекта.
 Заголовок сегмента
Заголовок сегмента
Заголовок сегмента содержит следующую информацию: байт типа; биты флагов: существования (постоянный или временный); авторасширения; наличия в сегменте тегов; другие; число выделенных для него страниц; адрес базового сегмента объекта; адрес ассоциированного пространства объекта. Последние два адреса не следует путать с системным указателем и пространственным указателем на системный объект. Они представляют собой 64-разрядные адреса, используемые SLIC. Байт типа определяет, что это за сегмент. Есть две категории типов сегментов: входящие в состав объектов MI, и используемые только SLIC ниже MI. Ранее мы говорили только о сегментах для объектов MI. Однако, есть целая категория сегментов для структур данных SLIC, которые не являются частью системных объектов MI. Эти сегменты, в отличие от объектов, не рассматриваются как единое целое. Мы уже рассмотрели два типа сегментов, входящих в состав системного объекта: базовый и сегмент ассоциированного пространства. Всего же в состав различных системных объектов MI могут входить сегменты более дюжины других типов. О некоторых из них мы поговорим в следующих главах. Примерно 40 типов сегментов используются только SLIC. Все его элементы, начиная от таблиц управления памятью до рабочей области, используемой транслятором, имеют свои типы сегментов. Обсуждение этих типов сегментов также имеет смысл пока отложить. На данный момент важно лишь то, что эти сегменты существуют, и что они создаются и управляются аналогично сегментам, используемым для системных объектов. Заголовок сегмента содержит несколько битов флагов, задающих его характеристики. Три наиболее важных флага — существования, авторасширения и наличия тегов. Бит существования указывает, постоянный это сегмент или временный. Постоянный сегмент остается в системе до тех пор, пока не будет явно удален, тогда как временный исчезает при следующей загрузке системы. При установленном бите авторасширения компонент управления памятью будет распределять сегменту дисковые страницы всякий раз, когда это понадобится. В заголовке сегмента имеется поле, содержащее число дисковых страниц, распределенных для сегмента. Если бит авторасширения сброшен, то сегмент никогда не вырастет сверх своего начального размера. Кстати, в этом случае компонент управления памятью пытается разместить весь сегмент в непрерывной области на диске. Если же бит включен, то сегмент, скорее всего, будет состоять из несмежных страниц диска. Таким образом, отключение данного бита может повысить производительность за счет предварительного распределения всех страниц. Бит наличия тегов указывает на присутствие в сегменте указателей MI. В главе 2 мы рассматривали расширения архитектуры PowerPC и в том числе и этот специальный бит. Напомню, что он связан с каждым адресом MI (16-байтовым указателем) и предотвращает несанкционированное изменение адреса. Биты тега входят в состав основной памяти AS/400, но не видимы программам MI. При перемещении страницы на диск, компонент управления памятью должен также переместить туда скрытые биты тега. Бит наличия тегов сообщает компоненту управления памятью, придется ли тому выполнять обработку тегов для этого сегмента. Подробнее биты тегов рассматриваются в главе 8. Два оставшихся поля заголовка сегмента представляют собой адреса: первый — базового сегмента, второй — следующего вторичного сегмента, которым для системного объекта обычно является адрес ассоциированного пространства. Эти два адреса позволяют связать друг с другом сегменты многосегментного объекта. Обратите внимание, что адреса, используемые ниже MI в заголовках и где-либо еще — 64-разрядные аппаратные. В MI адреса всегда содержатся внутри указателя и занимают 128 бит (16 байтов). Указатели защищают хранящиеся в них адреса от несанкционированного изменения и использования, а также помогают обеспечить независимость MI от технологии. Ниже MI нет ни такой защиты, ни аппаратной независимости. Именно по этой причине все пользователи MI, включая саму OS/400, не допускаются ниже уровня MI.
 Заголовок EPA
Заголовок EPA
Заголовок ЕРА содержится в базовом сегменте всякого системного объекта и содержит следующую информацию об объекте: байт атрибутов: постоянный ли; подвешенный ли; поврежден ли; присутствует ли группа доступа; трассируется ли; участвует ли в транзакции; идентификация объекта: тип; подтип (определяется пользователем); — имя; атрибуты пространства: фиксированной или переменной длины; начальное заполнение; размер; общий размер; номер версии; время создания; адрес профиля пользователя; адрес контекста; адрес группы доступа; адрес специфического заголовка; другая информация и адреса. Атрибуты объекта содержатся в начале заголовка ЕРА. Содержимое байта атрибутов проверяется всякий раз, когда системный указатель используется для обращения к объекту. Первый атрибут указывает, является ли объект постоянным или временным. Этот атрибут, значение которого также задано битом существования в заголовке сегмента, повторяется здесь для облегчения проверки. Биты подвешенности и поврежденности объекта определяют его состояние. Подвешенным считается объект, у которого доступны только заголовки, а содержимого не существует. Предположим, что владелец системного объекта явно удаляет его. Что будет, если кто-либо еще обладает указателем на этот объект и попытается воспользоваться им после того, как объект уничтожен? Он обнаружит подвешенный объект. Система определит, что объект более не существует, и предпримет соответствующие действия. При разрушении постоянного объекта его адресное пространство повторно не используется, что устраняет необходимость поиска всех указателей на удаленный объект, чтобы пометить их как недействительные. Это снимает также проблемы защиты и целостности, которые возникают в тех случаях, когда на место удаленного объекта распределяется новый, а у какого-нибудь пользователя сохранился указатель на старый объект. В других системах применяются сложные схемы «сборки мусора» для поиска указателей на удаленный объект. В AS/400 это не нужно[ 45 ]. При этом дисковое пространство, за исключением занятого заголовками удаленного объекта, очищается. Можно выделить два вида повреждения объекта: жесткое и мягкое. Жесткое означает, что объект невозможно использовать по назначению — он поврежден безвозвратно, его лучше удалить. В случае мягкого повреждения из объекта все же можно извлечь некоторые данные. При обнаружении такого повреждения OS/400 начинает процесс восстановления. Бит поврежденности используется для индикации проблем с объектами в MI. Один из основных определителей повреждения — компонент управления памятью. Источник повреждений — плохие сектора на диске. Если компонент управления памятью не способен считать сектор, он сообщает об этом установкой бита повреждения. Другие биты заголовка ЕРА указывают на наличие группового доступа к данному объекту, на выполнение трассировки объекта и участие его в транзакции. Подробнее эти атрибуты будут рассмотрены в главе 6. Для идентификации объекта в заголовке ЕРА зарезервировано три поля. Одно из них содержит тип объекта, а другое — подтип. Тип объекта — один из типов системных объектов MI. Поле подтипа определяется пользователем, при этом программисты OS/400 рассматриваются как пользователи системных объектов MI. Только для некоторых типов объектов (таких как пользовательское пространство) подтипы могут определяться за пределами Рочестера. Третье поле — поле имени, оно содержит имя объекта в контексте. Атрибуты пространства указывают, является ли размер пространства постоянным или переменным, каково начальное заполнение пространства (было ли оно очищено или обнулено), а также размер пространства. Поле общего размера объекта содержит размер всех сегментов объекта. Номер версии и время создания позволяют определить, когда был создан объект. Некоторые поля заголовка ЕРА содержат адреса. Наиболее важны из них: адрес пользовательского профиля владельца и создателя, адрес контекста, содержащего имя объекта, адрес группы доступа (если объект входит в нее), и адрес специфического заголовка объекта. Заголовок ЕРА содержит и другую информацию, а также адреса, используемые компонентами системы, которые еще будут обсуждаться.
Примеры объектов
На рисунке 5.9 приведено четыре примера системных объектов. Простейшим системным объектом является пространство, занимающее лишь один сегмент. У него есть только заголовки сегмента и ЕРА и пространство для данных пользователя. Пример объекта, занимающего два сегмента — независимый индекс, обычно называемый просто индексом. Его основное назначение — поддержка пользовательского индекса OS/400. Базовый сегмент индекса содержит заголовки сегмента и ЕРА, заголовок (специфический) индекса и двоичное дерево. В следующей главе мы увидим, как двоичное дерево используется в AS/400 для реализации индексов. Второй сегмент индекса — сегмент ассоциированного пространства, то есть байт типа в заголовке этого сегмента указывает, что это ассоциированное пространство. Этот сегмент также содержит пользовательские данные для индекса. Кроме того, на рисунке 5.9 показаны два примера объектов, занимающих три сегмента. Рисунок 5.9 Примеры объектов
Первый из них — программа. Базовый сегмент программы содержит заголовки сегмента и ЕРА, заголовок (специфический) программы, последовательность команд и код инициализации программы. Второй сегмент занят ассоциированным пространством, содержащим пользовательские данные для программы. Третий — это сегмент таблицы определения материализации MDT (materialization definition table), содержащий шаблон и карту объектов программы, необходимые для материализации программы. При удалении пользователем шаблона программы, третий сегмент исчезает, и программа занимает только два сегмента.
Последний объект на рисунке — индекс области данных. Как всегда, базовый сегмент содержит заголовки сегмента и ЕРА, заголовок (специфический) индекса области данных, альтернативную таблицу сортировки для этого индекса, таблицы индекса и двоичное дерево. Второй, как обычно, — сегмент ассоциированного пространства. Третий — сегмент отложенной коррекции. Для индекса области данных можно запросить отложенную коррекцию. В этом случае изменения, такие как добавление или удаление ключа, не вносятся в индекс немедленно. Вместо этого, информация о них записывается в сегмент отложенной коррекции до момента следующего открытия файла. Отложенная коррекция позволяет не ждать завершения операции коррекции, пока индекс используется. Однако прежде чем индекс используют в следующий раз, изменения будут внесены.
Рисунок 5.9 Примеры объектов
Первый из них — программа. Базовый сегмент программы содержит заголовки сегмента и ЕРА, заголовок (специфический) программы, последовательность команд и код инициализации программы. Второй сегмент занят ассоциированным пространством, содержащим пользовательские данные для программы. Третий — это сегмент таблицы определения материализации MDT (materialization definition table), содержащий шаблон и карту объектов программы, необходимые для материализации программы. При удалении пользователем шаблона программы, третий сегмент исчезает, и программа занимает только два сегмента.
Последний объект на рисунке — индекс области данных. Как всегда, базовый сегмент содержит заголовки сегмента и ЕРА, заголовок (специфический) индекса области данных, альтернативную таблицу сортировки для этого индекса, таблицы индекса и двоичное дерево. Второй, как обычно, — сегмент ассоциированного пространства. Третий — сегмент отложенной коррекции. Для индекса области данных можно запросить отложенную коррекцию. В этом случае изменения, такие как добавление или удаление ключа, не вносятся в индекс немедленно. Вместо этого, информация о них записывается в сегмент отложенной коррекции до момента следующего открытия файла. Отложенная коррекция позволяет не ждать завершения операции коррекции, пока индекс используется. Однако прежде чем индекс используют в следующий раз, изменения будут внесены.
Выводы
Объекты предоставляют средства управления и защиты системных ресурсов AS/400. Правила именования и адресации практически всех элементов системы привязаны к объектам. То же самое можно сказать и о защите. Объекты также используются для эффективного разделения информации между пользователями системы. Благодаря инкапсуляции и строгому определению набора возможных операций над объектами, в AS/400 обеспечен такой уровень целостности и независимости от технологий, о котором нельзя и помыслить в других системах. Объекты — основа AS/400. Они не были добавлены поверх существующей системы, как это часто бывает. Объекты были частью AS/400 с самого начала. Многие из объектов, представленных в этой главе, используются компонентами системы, описанными в оставшейся части книги. В следующей главе, мы рассмотрим интегрированную базу данных AS/400. В состав этой базы данных входят многие объекты, с которыми мы уже познакомились.Глава 6
Интегрированная база данных
В сегодняшнем бизнесе конкуренция постоянно усиливается. Чтобы достичь успеха приходится производить больше продукции за меньшую стоимость и быстрее, чем раньше. В нашем стремительном мире остановиться — значит проиграть. Как сказал, однажды американский философ Йоги Берра (Yogi Berra), «рано быстро становится поздно». Очень часто выжить в условиях острой конкуренции помогают оперативные данные. Многие бизнесмены понимают теперь, что информация — возможно, самое ценное, что у них есть. Часто выборка, обновление и сохранение данных повседневной деятельности выполняются некоторой прикладной программой, например, бухгалтерской или приема заказов. Мы, специалисты, обычно, называем программы такого типа приложениями оперативной обработки транзакций OLTP (online transaction processing). Приложение OLTP часто интерактивно, то есть обновление данных происходит в процессе оперативных транзакций. Для легкого и быстрого доступа к оперативной информации сегодня ее обычно хранят в реляционной базе данных. Компьютерная революция позволила легко собирать и дешево хранить большие объемы оперативных данных. Многие компании хранят свои данные за многие годы, веря, что это может когда-нибудь пригодиться. Но у большинства из них остается вопрос: «Мы знаем, что внутри этих данных скрыта бесценная информация о наших рынках сбыта, товарах, услугах и клиентах. Но как извлечь эту информацию?» Традиционно, анализ данных в поисках необходимой информации выполнялся вручную. Но в последние несколько лет стало очевидно, что автоматизация анализа данных не только значительно облегчает этот процесс, но и экономически выгодна. Часто ПО анализа данных называют системами поддержки принятия решений (decision-support), и говорят о преобразовании данных сначала в информацию, а затем в знания. Словосочетания складирование данных (data warehousing) и разработка данных[ 46 ] (datamining), еще несколько лет назад известные лишь узким специалистам, стали частью повседневного словаря делового человека. Рассказы в прессе о компаниях, которым с помощью этих технологий удалось выйти на передовые позиции в своей отрасли, побудили многие фирмы следовать тем же путем. Хранилища данных, где накапливается информация из собранных оперативных данных, — возможно, одна из наиболее быстро распространяющихся информационных технологий для бизнеса. Некоторые консультанты предсказывают, что в следующие несколько лет примерно треть всех расходов на информационные технологии будет связана с ней. Какое отношение все это имеет к AS/400? Вероятно, в ближайшие несколько лет с помощью AS/400 будет реализовано больше хранилищ данных, чем с помощью какой-либо другой системы. Причина проста: именно DB2/400 — база данных AS/400 — наиболее широко используемая многопользовательская база данных во всем мире, и именно под ее управлением сосредоточен наибольший объем оперативных данных. Обычно, этот факт удивляет даже в заказчиков AS/400. IBM не продает DB2/400 как отдельный продукт, поэтому многие просто не знают о ее позициях на рынке и часто считают наиболее широко распространенными базы данных от Oracle, Sybase или Microsoft. Очень немногие знают о DB2/400. Учитывая объем данных, хранящихся в базах DB2/400, можно представить, сколь много хранилищ данных будет создано на AS/400. По оценке IBM более 60 процентов заказчиков AS/400 в следующие несколько лет станут использовать те или иные системы поддержки принятия решений. В этой главе мы рассмотрим все возрастающую роль баз данных и то, как AS/400 удается держать первенство в этой области. Мы остановимся также на истории DB2/400 и на том, как она интегрирована в AS/ 400. Но сначала, давайте разберемся, что такое DB2/400?База данных без имени
Много лет назад мы решили интегрировать мощную реляционную базу данных в каждую System/38. Затем эта идея перекочевала и в AS/400. Мы считали, что способность полнофункциональной системы управления базой данных (СУБД) эффективно и надежно обрабатывать большие объемы информации, станет хорошей основой всех приложений для бизнеса. Вместо того, чтобы делать базу данных отдельным продуктом, мы просто встроили ее, даже не побеспокоившись об отдельном имени. Незаметно для глаз многие годы безымянная база данных тихо делала свое дело. В результате, даже не все наши заказчики (40 процентов, как показали проведенные несколько лет назад исследования) знают, что на них ежедневно работает такая мощная база данных. Это и хорошо, и плохо. Хорошо, что многие заказчики не предпринимали никаких специальных усилий для управления своей базой данных, а просто пользовались, не испытывая при этом никакой потребности в помощи администратора базы данных. (Этим база данных AS/400 отличается от некоторых других, для управления которыми требуется персонал). Плохо же то, что некоторые пользователи в один прекрасный день решили добавить на свои AS/400 базу данных, не зная, что она там уже есть. Действительно, пользователи почти всех современных компьютерах, включая ПК, отдельно покупают и интегрируют в систему реляционные базы данных. Поэтому, решили такие заказчики, несомненно, стоит потратиться и установить реляционную базу данных и на AS/400[ 47 ]. Кроме того, нам, сотрудникам IBM, было трудно объяснить, где собственно находится база данных AS/400, так как она не сосредоточена в одном месте. Интегрированная природа системы ведет к тому, что база распределена по всей системе. С другой стороны, обычные базы данных — это отдельные программные компоненты, работающие поверх ОС. Чтобы добраться до обычной базы данных, программе необходимо пройти через ОС или использовать совершенно отдельный интерфейс. Между тем, интегрированная частично над MI, и частично в SLIC, база данных AS/ 400 более эффективна, чем базы, построенные поверх существующих систем. База данных AS/400 тесно связана с другими компонентами системы и взаимодействует с ними способами, недоступными обычным базам. В 1994 году мы решили дать своей базе данных имя, выбрав «DB2 для OS/400» в отражение того, что наша база данных — часть семейства реляционных баз данных IBM DB2[ 48 ]. Фамильное сходство заключается, в основном, во внешних утилитах и поддержке распределенных баз данных. Внутренне каждый продукт реализован по-своему. Но имя DB2 все помогает устранить впечатление, что у AS/400 нет современной, надежной базы данных. Интегрированная база данных AS/400 решает проблемы бизнеса с помощью новейших информационных технологий. Рост популярности хранилищ данных и средств их обработки среди заказчиков AS/400 — доказательство мощности этой системы. Не приходится удивляться, что среди прочих новых технологий многие пользователи предпочитают именно ее. Давайте рассмотрим, как AS/400 поддерживает хранилища и обработку данных, а затем разберем некоторые фундаментальные концепции DB2/400.Хранилища данных
Итак, мы убедились в важности для современного бизнеса оперативного хранения и использования данных и обсудили, чем в этом случае может помочь реляционная база данных. Оперативные данные динамичны, часто обновляются, оптимизированы для транзакций. Информационные данные — обобщают оперативные, обновляются редко (может быть даже никогда), и хранятся в форме, оптимизированной для принятия решений, отдельно от оперативных, зачастую даже на другой машине. Именно информационные данные и составляют хранилище данных. Следует ясно понимать, что хранилище данных — это концепция, а не конкретный продукт. Это набор средств для систематизации информационных данных, их хранения и анализа для принятия решений. Хранилище данных AS/400 состоит из четырех основных компонентов, а именно: средств трансформации и преобразования данных для заполнения хранилища; сервера базы данных; аналитических средств и программы пользовательского интерфейса; средств управления информацией о самом хранилище.Преобразование оперативных данных в информационные
Создание хранилища данных требует преобразования оперативных данных в информационные. Для этого используются так называемые средства трансформации (transformation tools) или средства преобразования (propagation tools). Их задача — не просто извлечь данные из одной или нескольких оперативных баз, но и преобразовать их в форму, подходящую для хранения. Возьмем, например, оперативные данные оптового дистрибьютора по продажам. Каждая запись содержит информацию о размере партии проданного товара, форме оплаты и о покупателе. Так как данные находятся в формате, удобном для регистрации каждой транзакции, то их анализ посредством запросов может требовать слишком много времени, поскольку большинству аналитических программ не нужна информация по отдельным транзакциям. Программа может проанализировать собранные данные для прогноза потребностей в товарах, или для оценки доходов по сравнению с прошлым годом. Для анализа такого типа — быстрого выявления тенденций и потенциальных проблем — данные должны быть преобразованы. Аналитической программе нужна сводка информации из оперативной базы. Средства преобразования периодически собирают с компьютеров оперативные данные, трансформируют их в сводный формат и помещают в хранилище данных. Обратите внимание, что большинству аналитических программ не требуется постоянная синхронизация данных в хранилище и оперативных. Автоматическое обновление хранилища данных осуществляется с разной периодичностью: раз в неделю, раз в день или каждые 10 минут. Есть много программ как IBM, так и других производителей, позволяющих выбирать данные из баз (DB2 или других) и импортировать их непосредственно в склад данных AS/400.Серверы баз данных
Несколько лет назад IBM представила специальные модели AS/400, названные серверными. Они созданы для работы в качестве серверов баз данных, серверов коммуникаций и пакетной обработки. В эти модели внесены улучшения, специально предназначенные для приложений хранилищ данных. Мы еще вернемся к серверным моделям, а сейчас давайте, подробней поговорим об улучшениях в DB2/400. Итак, два важнейших аспекта поддержки хранилищ данных — параллельная обработка и многомерные базы данных (MDD).Параллельная обработка
Различные приемы параллельной обработки позволяют базе данных полностью задействовать все аппаратные возможности. Выборка и анализ больших объемов информации может требовать очень больших ресурсов. По счастью, при обработке базы данных доступ к ней может осуществляться параллельно, после чего собранные данные можно анализировать независимо и также параллельно. Обработка баз данных — один из примеров практического использования массового параллелизма, который мы вкратце затронули в главе 2. IBM несколько модифицировала AS/400 и DB2/400, что позволило применить массовый параллелизм при работе с базой данных. Впервые поддержка параллельной обработки ввода-вывода появилась в V3R1, что позволило воспользоваться возможностями аппаратной архитектуры AS/400, имеющей как основные процессоры, так и вспомогательные, и ввести параллельную обработку на уровне процессора ввода-вывода (IOP) для одного задания. Мы подробно рассмотрим IOP в главе 10, а сейчас, забегая вперед, скажу, что в мощной AS/400 их может быть установлено несколько сотен, причем к разным IOP подключают множество дисковых накопителей. Параллельный ввод-вывод позволяет обрабатывать пользовательский запрос к базе данных несколькими IOP одновременно. Таким образом, устраняется одна из самых серьезных проблем, мешающих многим системам достичь высокой производительности: задержки при выполнении ввода-вывода. В главе 2 мы говорили о поддержке SMP в AS/400, когда все основные процессоры работают параллельно с общей памятью. При большинстве видов обработки отдельные задания выполняются на разных процессорах, при необходимости используя общие области памяти. При обработке запросов к базе данных каждый основной процессор может обрабатывать часть задачи. Именно так работает средство параллельной обработки DB2/400. Запрос разбивается на отдельные, независимые подзапросы, которые выполняются параллельно несколькими основными процессорами, что позволяет значительно сократить время обработки. Задать использование нескольких процессоров при обработке запроса можно с помощью соответствующей опции команды «CHGQRYA» (Change Query Attribute). Данный метод повышает производительность таких запросов, как поиск в таблице, группирование (group-by), поиск в индексе и соединение (join). Поддержкой параллельной обработки базы данных на системах SMP пользуются также некоторые внутренние функции SLIC, например, построение индекса (подробно об этом мы поговорим в разделе «Машинный индекс»). Параллелизм присутствует на всех системах версий 3 и 4, но параллельное построение индекса — только на RISC-системах. AS/400 также поддерживает конфигурации MPP. При этом несколько систем AS/ 400 с помощью высокоскоростных линий соединяются друг с другом в кластер. Один из способов такого соединения — через волоконно-оптический кабель с помощью продукта OptiConnect. Для объединения машин серии AS/400е подходит также соединение SAN, позволяющее достичь еще больших скоростей. Распределение базы данных по дискам всех систем кластера позволяет создавать очень большие базы, с которыми параллельно работают несколько сотен процессоров. IBM называет такую конфигурацию MPP слабо связанной параллельной системой базы данных, в связи с отсутствием разделения памяти за пределами отдельной системы в кластере. Здесь используется подробно обсуждавшийся в главе 2 подход shared-nothing, похожий на тот, что применяется в SP2. Различие в том, что узлы кластера AS/400 находятся в разных физических корпусах, но, несмотря на это, для пользователя кластер выглядит как единая база данных. Технология слабо связанной параллельной базы данных позволяет разбивать запросы на части, с которыми может справиться отдельный узел. В отличии от SMP-па-раллельной базы данных, у каждого узла — собственные память и дисковое пространство. Каждый узел кластера работает с порцией физического файла или таблицы, и запрос к нему выполняется для соответствующей порции файла. Каждый узел может содержать один или несколько процессоров, ведь узел — это просто AS/400. Приложение, выполняющееся на любом компьютере кластера, может работать с базой так, как если бы она полностью размещалась на этом компьютере. Распределенность базы по узлам кластера делает DB2/400 прозрачной как для приложений, так и для конечного пользователя. Для задания имен системам в группе узлов в CL были введены новые команды, к некоторым командам были добавлены новые параметры для поддержки распределения файлов базы по узлам. После рассредоточения по узлам, файл при выполнении операций вставки, обновления и удаления выглядит как локальный. Главное преимущество слабо связанных параллельных систем — отсутствие верхнего предела количества узлов, что означает практически неограниченный рост производительности и емкости. Возможности расширения концепции кластеров AS/400 в будущем мы рассмотрим в главе 12.Многомерные базы данных (MDD)
Реляционные базы данных организованы в виде двумерных таблиц. В MDD имеется одно или несколько дополнительных измерений. Например, Вам надо оценить свои доходы от продаж, рассмотрев в отдельности сводки по товарам, по регионам и по времени. В этом случае лучшую наглядность Вам обеспечит трехмерная структура данных со шкалой измерения по товарам на одной оси; временем в днях, неделях или месяцах — на второй; и географическими данными — на третьей. В результате получится куб, очень похожий на трехмерную электронную таблицу, в каждой ячейке которой — величина доходов от продажи. Далее можно использовать различные средства анализа продаж товаров в регионах в течение некоторого периода времени. AS/400 поддерживает многомерные структуры данных непосредственно в самой базе данных DB2/400 или с помощью продуктов, разработанных бизнес-партнерами. Преимущество многомерных структур данных состоит в возможности быстро получить ответ на поставленный вопрос в виде среза данных по любому измерению или прохода сквозь структуру для получения данных новых уровней. Поскольку время ответа на запросы обычно очень мало, такой многомерный анализ часто называют оперативной аналитической обработкой OLAP (on-line analytical processing). Иногда различным подразделениям одной организации требуются информационные данные в разных формах. Внутри MDD можно создавать специализированные хранилища данных (data mart), которые содержат информационные данные, соответствующие потребностям конкретного отдела или рабочей группы. В этом случае хранилище данных всей организации состоит из набора таких специализированных хранилищ для отдельных структурных единиц[ 49 ].Анализ данных и инструментарий конечных пользователей
Термином «интеллектуальный бизнес» (business intelligence) обозначают методы обработки информации, применяемые для принятия решений в бизнесе. Средства интеллектуального ведения бизнеса — это программные пакеты, используемые для анализа данных в хранилище данных на AS/400. Обычно, эти программы работают на ПК и способны обращаться к хранилищу данных на AS/400 напрямую. Есть три основных категории бизнес-информационных средств: программы поддержки принятия решений DSS (decision support system); управленческие информационные системы EIS (executive information system); средства разработки данных. Программы DSS позволяют конечному пользователю строить гипотезу и затем генерировать запросы для ее проверки. Приэтом предполагается, что у пользователя есть некое общее представление о том, что нужно найти в хранилище данных, и это позволяет ему выдавать произвольные запросы и генерировать отчеты. Это средства простейшего типа, так как они просто возвращают информацию по запросу пользователя. EIS объединяют средства поддержки принятия решений с некоторыми расширенными возможностями анализа. Обычно, они имеют доступ к средствам за пределами хранилища данных, например, могут использовать оперативные новости из Интернета для получения информации с мировых рынков. Как и DSS, EIS предполагает наличие у спрашивающего некоторого представления о том, что именно следует искать. И EIS, и DSS обеспечивают поиск нужной пользователю информации путем проверок. Но как быть, если Вы не можете четко сформулировать вопрос? Вы знаете, что в базе данных скрыта важная информация, но не можете придумать, как до нее добраться. Тогда Вам нужна разработка данных — средство принятия решений на основе открытий. Разработка данных позволяет отыскивать информацию при незначительном объеме указаний от пользователя или вовсе без таковых. Система выполняет поиск шаблонов и связей. На практике существует бесконечное множество вариантов такого способа поиска. Например, розничный торговец может использовать разработку данных для того, чтобы определить, какие товары покупаются вместе. Анализ и оценка привычек покупателей очень полезны при оценке спроса на товар, или выявлении групп покупателей с наивысшим потенциалом. Разработка данных используется также в банковском деле для выявления подделок кредитных карт: путем «просеивания» больших объемов информации можно выявлять отклонения от нормы. Технология разработки данных пришла из мира искусственного интеллекта. Средства IBM для поиска шаблонов и взаимосвязей данных комбинируют нейронные сети и статистические алгоритмы. Нейронная сеть поддерживает основной шаг разработки данных в процессе открытия знаний. Соответствующая технология была разработана в Рочестере в период проекта Fort Knox (подробнее об этом — в Приложении) и впервые появилась на рынке в начале 90-х годов в виде утилиты для AS/400. Теперь же она — основа всей разработки данных в IBM.Управление хранилищем данных
Метаданные — это данные о данных. Они используются для управления хранилищем данных. Существуют две формы метаданных — технические и бизнес-данные. Первые содержат описания оперативной базы данных и хранилища данных, что позволяет перемещать данные из оперативной базы в хранилище. Бизнес-данные необходимы конечному пользователю для поиска информации в хранилище данных. Легче всего представить их себе как каталог информации о хранилище, в том числе об актуальности и источниках поступления этой информации. Бизнес-данные пользователь видит в терминах, принятых в его отрасли деятельности, и может позволить себе забыть о сложности нижележащей базы данных. Теперь, после рассмотрения способов использования новых технологий баз данных AS/400, мы можем перейти к фундаментальным концепциям DB2/400. Сначала рассмотрим историю этой замечательной базы данных.Эволюция реляционной базы данных
Первая коммерческая база данных с реляционными возможностями появилась в System/38. Эта уникальная технология опережала другие реляционные базы примерно на три года, что позволило System/38 выйти на передовые позиции на рынке. Разработчики System/38 искали более эффективный способ обработки записей, по сравнению с System/3. Первая System/3 была разработана как машина единичных записей. Она поддерживала только пакетную обработку, то есть приложение должно было обработать все записи в файле одну за другой. Первые записи размещались на перфокартах, колода перфокарт составляла файл. Позднее, появилась возможность хранения файлов на диске, хотя обрабатывались они по-прежнему с помощью перфокарт. Типичное приложение единичных записей сначала сортировало записи в файле. Записи могли иметь несколько полей, содержащих такую информацию, как имя клиента, номер счета, номер детали и так далее. Выбиралось одно из этих полей, называемое ключом, и все записи сортировались по значению ключевого поля в определенном порядке. Механический сортировщик перфокарт в большинстве машин единичных записей использовался очень интенсивно. После сортировки файл обрабатывался последовательно, запись за записью, до конца. Позднее в System/3 была добавлена интерактивная обработка. Применение дисков позволило обращаться к записям в произвольном порядке. Поиск нужной записи осуществлялся с помощью индекса — небольшого файла, в котором каждой записи основного файла соответствуют лишь два поля. Первое содержит значение ключа, а второе — дисковый адрес записи с совпадающим значением. Для сортировки записей индекса по значениям ключа использовалась особая программа. Затем индекс сохранялся на диске вместе с основным файлом. Для поиска записи с заданным значением ключа система вначале просматривала индекс. После этого для выборки полной записи использовался дисковый адрес, хранящийся вместе с этим значением. Так как размер памяти System/3 был очень небольшим, хранить в памяти объемные индексы целиком было невозможно. Это снижало эффективность поиска из-за необходимости нескольких обращений к диску. System/34 была первой моделью семейства System/3, предназначенной для работы в интерактивном, а не в пакетном режиме. Размеры памяти в System/34 были также невелики, так что IBM решила ускорить поиск нужной записи в индексе, а для этого — устранить необходимость считывать индекс с диска. Часть дорожек диска была зарезервирована для индекса, для контроллера диска была разработана специальная аппаратура. Желаемое значение ключа процессор передавал дисковому контроллеру. Затем контроллер начинал считывать информацию дорожки, отыскивая значение ключа. Обнаружив искомое, аппаратура контроллера считывала следующее поле адреса и возвращала его процессору. Процессор использовал полученный адрес для считывания целой записи из некоторой другой части диска. Эта операция была названа сканированием. Функция сканирования значительно повысила эффективность интерактивной обработки, благодаря полному устранению этапа обращения к диску для считывания индекса. Но при этом потребовалось встроить в памяти еще один небольшой индекс. Индекс в памяти указывал, на какой индексной дорожке диска следует выполнять поиск. Позднее аналогичная операция сканирования была реализована в System/36 для обработки файлов. Для System/38 также была важна очень высокая эффективность интерактивной обработки. Недостатком описанной процедуры сканирования была ее слишком тесная привязка к аппаратуре. Были также и другие ограничения: максимально возможное число индексов, ограничение способов их обработки и др. Так как System/38 должна была иметь одноуровневую память, разработчики решили поместить все файлы и индексы в эту большую память. Если вернуться назад к только что описанной файловой структуре, то мы увидим двумерную таблицу, где строки —это записи, а столбцы — поля записей. Разработчики посчитали, что наиболее эффективным будет организовать файл System/38 просто как двумерную таблицу в памяти. Они также полагали, что производительность обработки повысится, если таблицу обрабатывать «на месте» без сортировки записей. Чтобы добиться этого, они встроили индекс в таблицу так, что сортировка просто не требуется (подробнее об этом — далее, в разделе «Машинные индексы»). По сути, предполагалось, что в System/38 никогда не будет программы сортировки. Однако, такая программа была и есть. Ее написал Дик Бэйнс, назвав «Conversion Reformat Utility», вероятно, чтобы скрыть ее сущность и предотвратить использование прикладными программистами в новых проектах[ 50 ]. Эта программа, тем не менее, была — а, может быть, есть и по сей день — самым быстрым способом сортировки и выборки записей из больших файлов. Джим Слоан (Jim Sloan), бывший разработчик и проектировщик, участвовавший в создании компилятора CL, разработал в составе своего набора QUSRTOOL утилиту для пользователей, интерфейс которой к этой программе сортировки позволял использовать внешние имена полей. В процессе разработки базы данных Перри Тейлор (Perry Taylor) случайно наткнулся на технический отчет Е. Ф. Кодда (E. F. Codd). Кодд, который считается создателем реляционной базы данных, работал над проектом System/R (R — реляционная) в исследовательском центре IBM в Калифорнии. Базой в определении Кодда была двумерная таблица, над которой можно было выполнять четыре элементарных операции. Первая операция — упорядочение (order) — позволяла обрабатывать строки или столбцы в определенном порядке по ключевому полю; вторая — выборка (selection) — выбирать записи по значению ключевого поля; третья — проекция (projection) — осуществлять выборку из таблицы заданных полей; и наконец, четвертая — соединение (join) —рассматривать несколько таблиц как одну большую. Таким образом, реляционная база данных представляла собой просто двумерную таблицу с операциями упорядочения, выборки, проекции и соединения. Перри сразу же понял, что разработчики System/38 строят очень похожую базу данных, за исключением того, что в ней нет соединения. Он позвонил Кодду, чтобы сообщить о работах в Рочестере и предложить свою поддержку. Но Кодд ответил, что, по его мнению, реляционные базы данных предназначены только для больших систем; а малым нужны только функции сортировки и слияния. По словам Перри, разговор не был сердечным. Тон Кодда он сравнил с тоном полицейских во время перекрестного допроса их защитниками на процессе О. Дж. Симпсона (O. J. Simpson) — вежливый, но холодный. Кодд и Тейлор больше никогда не разговаривали. Через три года после объявления System/38 база данных System/R была объявлена как DB2 и признана в качестве первой реляционной базы данных[ 51 ]. Так как первоначально System/38 не поддерживала операции соединения, то она считается первой коммерческой базой данных с реляционными возможностями.Двуликая база данных
Говоря о базе данных, мы имеем в виду не просто некоторое место для размещения данных. Мы говорим о системе управления базой данных. СУБД — среда для хранения и выборки данных, включающая определения данных, правила обеспечения их целостности и механизмы поддержания, а также операции сохранения и выборки данных. СУБД должна иметь интерфейс, чтобы пользователи могли работать с ней. В этом разделе мы представим два интерфейса СУБД AS/400: DDS (Data Description Specifications) и SQL (Structured Query Language), в следующих разделах — детально рассмотрим саму СУБД. Когда IBM начинала проект System/38, стандартных интерфейсов к реляционной базе данных не существовало. Поэтому проектировщикам пришлось разработать собственный уникальный интерфейс для этой системы. Не удивительно, что этот интерфейс DDS очень похож на файловую систему, которую должен был заменить. Создатели интерфейса ограничились несколькими системными командами и функциями управления базой данных, а также ввели в MI команды для таких операций как чтение, запись, обновление и удаление. Программисты могли непосредственно использовать эти команды из таких языков как RPG и Cobol. Например, многие используют DDS-RPG: DDS для определений данных, RPG для доступа к ним. Интерфейс DDS перешел из System/38 в AS/400, и многие по-прежнему предпочитают его. Бывшим пользователям мэйнфреймов, перешедшим на AS/400, он также нравится, поскольку очень похож на интерфейс базы данных для больших систем IBM — IMS (Information Management System). Примерно в то же время, когда разрабатывалась AS/400, в IBM и других фирмах выполнялись проекты по стандартизации SQL (из System/R) в качестве языка реляционных баз данных. Проект продвигался не слишком гладко, на создание стандарта потребовалось около десятилетия. Ingres многие годы использовала язык-соперник QUEL, пока, наконец, тоже не поддалась общей тенденции. Появившаяся в 1988 году AS/400 поддерживала и собственный интерфейс DDS, и SQL. Операторы SQL могут включаться непосредственно в программы на RPG, Cobol и С, заменяя «родные» команды, такие как чтение, запись и обновление. Для трансляции этих операторов SQL DB2/400 содержит прекомпиляторы. При более внимательном взгляде становится видно, что DB2/400 состоит из двух отдельных частей. Собственно СУБД и язык DDS входят в состав OS/400. Query Manager and SQL Development Kit — особый продукт, приобретаемый отдельно. Как следует из названия, этот продукт содержит Query Manager — ПО AS/400 для конечного пользователя, позволяющее выдавать запросы на SQL. В состав продукта входят кроме того интерактивный пользовательский интерфейс к SQL (Interactive SQL), а также прекомпиляторы для различных языков, используемые при вставке операторов SQL в ЯВУ. К несчастью сложилось так, что IBM требует от Вас платить за SQL отдельно, тогда как DDS входит в состав OS/400. Такая ситуация — основная причина непопулярности SQL у многих пользователей AS/400, считающих его внешним продуктом, каковым он на самом деле не является. Сегодня большинство разработчиков баз данных в Рочестере думают в терминах SQL, а не DDS. Интерфейс DDS будет поддерживаться и далее, но новые функции, скорее всего, будут в SQL. Хотя AS/400 и поддерживает два разных интерфейса к базе данных, крайне важно понимать, что сама база данных только одна. Доступ к данным, определение данных и манипуляции с ними на AS/400 возможны как посредством DDS, так и посредством SQL. Так как интерфейс SQL использует те же команды MI, что и DDS, каждый из интерфейсов может работать с объектами данных, созданных посредством другого интерфейса. Эта возможность смешения двух интерфейсов обеспечивает базе данных AS/400 дополнительные мощь и гибкость. Самая большая проблема двух интерфейсов состоит в путанице, вызываемой терминологическими различиями. Как и в случае различий имен между объектами OS/ 400 и системными объектами MI, имена для разных интерфейсов базы данных подбирались разными группами. Например, в интерфейсе DDS имеются физические файлы, содержащие данные. Как мы видели ранее, физический файл — это двумерная таблица. В интерфейсе SQL тот же самый физический файл называется таблицей, что больше подходит для этой структуры. Логический файл в интерфейсе DDS не содержит данные, а указывает на реальные данные и дает программе некоторую их проекцию. В SQL логический файл называется проекцией (view). Аналогично, то, что в терминологии DDS — запись и поле, в интерфейсе SQL — строка и столбец (чтобы отразить концепцию таблицы).Как функционирует база данных
В этом разделе мы рассмотрим различные компоненты базы данных AS/400. Я не ставил здесь перед собой задачу проинструктировать Вас, как использовать эту базу данных. Уже есть целый ряд хороших книг, посвященных внешним аспектам базы данных и использованию двух ее интерфейсов в программах[ 52 ]. А я лишь хочу предложить Вам обзор характеристик СУБД и основ ее функционирования. Раздел состоит из двух частей. В первой содержится описание основных функций, которые должны присутствовать в каждой СУБД, и их реализации в AS/400. Во второй — обзор других характеристик базы данных, некоторые из которых имеют отношение к производительности, а другие обеспечивают поддержку использования AS/400 в качестве сервера базы данных. После этого мы поговорим о внутренней реализации некоторых фундаментальных функций базы данных.Функции СУБД
Есть много способов реализации реляционной базы данных, но любая система управления ею должна предоставлять следующие семь функций: определение и описание таблиц базы данных; операции управления данными (вставка, выборка, обновление и удаление); возможность определить, что представляют собой данные независимо от программы; возможность создавать новые проекции данных для удовлетворения изменяющихся требований прикладных программ; множественные проекции данных для разных прикладных программ; защита данных; целостность данных. Теперь посмотрим, как эти функции реализованы в AS/400.Описание данных и создание файлов
Для описания физических и логических файлов базы данных можно использовать «родной» язык СУБД AS/400 — DDS. Он содержит операторы, ключевые слова и параметры, позволяющие описывать как атрибуты самого файла, так и полей записей базы данных. DDS можно также применять для описания файлов устройств, используемых AS/400. Эти файлы устройств содержат информацию о формате и типах данных, используемых подключенными к системе физическими устройствами. DDS позволяет определить несколько атрибутов полей записей базы данных. Среди них имя поля, его длина и род данных (текстовые или числовые). В зависимости от типа данных поля можно задать некоторые другие специфические атрибуты. Например, если поле содержит десятичные данные, можно задать общее число десятичных цифр и число цифр справа от запятой. Операторы DDS помещаются в разделах исходных файлов, которые затем превращаются в файловые объекты с помощью команд OS/400 «CRTPF» («Create Physical File») и «CRTLF» («Create Logical File»). Для описания атрибутов файлов базы данных можно использовать и SQL. В отличие от DDS, представляющего собой только язык описания данных, один оператор SQL и описывает, и создает таблицы и проекции (view). В SQL определение файла неотделимо от команды создания. Например, оператор SQL «Create table» задает имя таблицы, имена столбцов (полей) и их атрибуты. Кроме того, при исполнении этого оператора создается и сама таблица.Создание физических файлов и таблиц
Физические файлы или, в терминологии SQL, таблицы содержат собственно данные. Запись физического файла имеет фиксированный набор полей. Каждое поле может иметь (хотя и не часто) переменную длину. В терминологии SQL таблица содержит строки фиксированной длины со столбцами переменной длины[ 53 ]. Физический файл состоит из двух частей. В первой находятся атрибуты файла и описания полей. В набор атрибутов файла входят его имя, владелец, размер, число записей, ключевые поля и некоторые другие характеристики. Описания полей задают атрибуты для каждого поля записей. Вторая часть физического файла содержит собственно данные. Она может состоять из одного или нескольких разделов, позволяющих подразделять файл. Все записи во всех разделах обязательно имеют один и тот же формат. Это удобный способ разделения записей: например, информацию текущего месяца можно поместить в один раздел, а информацию прошлого — в другой. Каждый раздел имеет уникальное имя, которое можно использовать для доступа к записям. Таблицы SQL могут состоять только из одного раздела, что соответствует самой сути реляционной модели: все данные хранятся в двумерных таблицах. Файлы же имеющие несколько разделов — трехмерные. Для создания физического файла используется системная команда «CRTPF». Она создает физический файл по операторам из исходного файла. Вновь созданный физический файл не содержит записей данных, для их добавления необходимо использовать отдельную программу или утилиту. Как было отмечено ранее, оператор определения данных SQL также создает таблицу. Оператор «Create table» можно выполнить с помощью Query Manager, Interactive SQL, или вставив его в программу на ЯВУ. Таблица, созданная этим оператором, является физическим файлом, идентичным созданному с помощью «родного» интерфейса.Создание логических файлов и проекций
Логические файлы дают возможность доступа к данным в формате, отличном от использующегося для их хранения в одном или нескольких физических файлах. Логические файлы обеспечивают независимость данных и программ, которая будет обсуждаться в следующем разделе. Они не содержат записей данных, а лишь относительный номер записи (индекс) данных в физическом файле. Часто говорят, что логический файл задает путь доступа к данным. Структура логического файла может быть как очень простой, так и очень сложной. Логические файлы и проекции можно подразделить на четыре категории. Перечислю их. Простые логические файлы и проекции, которые отображают данные из одного физического файла или таблицы на другое описание логических записей. Многоформатные логические файлы, обеспечивающие доступ к нескольким физическим файлам, каждый из которых имеет собственный формат записей. Данный тип логического файла может быть создан только с помощью «родного» интерфейса; с помощью SQL его создать нельзя. Логические файлы объединения (join), задающие одно определение логической записи, построенное из любой комбинации полей двух или более физических файлов, таблиц, логических файлов или проекций. При этом общее число физических файлов и таблиц не должно превышать 32. Проекции SQL (view), которые похожи на логические файлы объединения и дают те же результаты, но реализованы совершенно иначе. Файлы объединения хранят путь доступа для каждого объединения. Проекции же SQL определяют пути доступа во время исполнения, руководствуясь хранящимся внутри шаблоном определения запроса (Query Definition Template). Подобно физическому, логический файл состоит из двух частей. Первая — точно такая же, как и у физического файла. Она содержит атрибуты файла и описания полей. Вторая часть содержит относительные номера записей данных физического файла. Программе, использующей логический файл, видимы только те данные физического файла, которые соответствуют описанию полей логического файла. Для создания логического файла используется системная команда «CRTLF». Она использует операторы DDS в исходном файле для создания логического файла. Операторы DDS в исходном файле задают имена одного или нескольких физических файлов, служащих основой для логического. Созданный логический файл содержит относительные номера записей данных из одного или нескольких физических файлов. Оператор SQL «Create view» задает таблицу, представляемую проекцией, вместе с описанием столбцов проекции. Результат создания проекции — логический файл, идентичный создаваемому при использовании «родного» интерфейса. Логические файлы выполняют три операции: форматирование, включая проекцию, объединение и создание производных полей (field derivation); выборку записей; упорядочение. Логический файл, созданный с помощью DDS, может осуществлять все три операции. Файл, созданный с помощью SQL, может выполнять либо форматирование (проекция SQL), либо упорядочение (индекс SQL), но не обе сразу. На SQL нельзя создать проекций, выделяющих подмножество записей физического файла. Проекция SQL может быть создана с помощью DDS, но DDS обычно не используется для создания файлов, имеющих только возможности проекций SQL.Словарь данных и каталоги
Описания компонентов всех физических и логических файлов содержатся на каждой AS/400 в одном месте. В терминах «родного» интерфейса это место называется словарем данных. Словарь данных — это специальный объект OS/400, который обслуживается менеджером базы данных и к которому могут обращаться пользователи для поиска информации о структуре и местах использования файлов. Менеджер базы данных автоматически обновляет информацию в словаре данных всякий раз при создании нового объекта СУБД. Словарь данных позволяет разработчикам приложений и пользователям получить представление о структуре базы данных на любой системе. «Каковы форматы записей?», «Каковы атрибуты данных?», «Где в системе используется некое имя?», — с помощью словаря данных можно найти ответы на эти и другие вопросы. В интерфейсе SQL словарь данных называется общесистемным каталогом. SQL также позволяет разработчикам создавать другие каталоги. Каждая коллекция (collection) SQL (библиотека в «нормальной» терминологии) может (хоть и необязательно) иметь собственный каталог.Независимость данных и программ
Использование комбинации физических и логических файлов в AS/400 позволяет достичь независимости программ от используемых ими данных. Отделение описания данных от программ достигается тем, что прикладные программы рассматривают данные в формате, отличном от того в каком они хранятся физически. Концепция отделения программ и данных — одна из основ технологической независимости архитектуры System/38 и AS/400. Рассмотрим структуру физического файла, содержащего помимо самих данных их описание, часто называемое внешним описанием файла. Как System/38, так и AS/ 400 имеют внешне описанные данные, которые не надо помещать в программу. Это означает, что программа не определяет, как данные должны физически храниться. Кроме того, одна прикладная программа может работать с файлами, содержащими данные в разных форматах. Формат логического файла, так же как и формат физического — внешний, так что с помощью логических файлов можно переопределить формат записи программы. На рисунке 6.1 показан очень простой пример, иллюстрирующий некоторые функции логических файлов: использование программой логического файла для получения иного представления данных физического файла. Рисунок 6.1. Независимость данных и программ
Обратите внимание на выделенные поля. Каждая запись физического файла содержит шесть полей; в то же время программа, посредством логического файла, «видит» только четыре из них. Возможность исключения полей из логического файла позволяет реализовывать защиту на уровне полей. Пользователи имеют доступ только к тем полям, которые им позволено видеть. Это лишь один прием защиты в AS/400. Более подробно тема защиты рассматривается в главе 7.
Другая функция, отображенная на рисунке — возможность переупорядочения полей записи. Порядок следования в логической записи полей общего дохода (gross) и федерального подоходного налога (FIT) изменен на обратный. Другими словами, программа независима от порядка следования полей.
Кроме того, рисунок 6.1 иллюстрирует переопределение полей записи. В физическом файле поле общего дохода представляет собой упакованное десятичное число, содержащее 7 цифр, две из которых расположены справа от запятой. Однако программа написана так, что поле общего дохода должно иметь зонный десятичный формат с 8 цифрами, две из которых расположены справа от запятой. Логический файл обеспечивает нужное программе представление, а также осуществляет преобразование между упакованным и зонным десятичным форматами.
Использование множественных логических файлов, построенных над одним и тем же физическим файлом, предоставляет альтернативные пути доступа к данным и обеспечивает разделение данных между программами. На рисунке 6.2 показан еще один логический файл для другой программы, который был добавлен к первому примеру. Теперь каждая программа имеет свое представление записей, хранящихся в физическом файле, и доступ только к тем полям, к которым он разрешен. Поля, присутствующие в обоих логических файлах, позволяют программам совместно использовать данные.
Рисунок 6.1. Независимость данных и программ
Обратите внимание на выделенные поля. Каждая запись физического файла содержит шесть полей; в то же время программа, посредством логического файла, «видит» только четыре из них. Возможность исключения полей из логического файла позволяет реализовывать защиту на уровне полей. Пользователи имеют доступ только к тем полям, которые им позволено видеть. Это лишь один прием защиты в AS/400. Более подробно тема защиты рассматривается в главе 7.
Другая функция, отображенная на рисунке — возможность переупорядочения полей записи. Порядок следования в логической записи полей общего дохода (gross) и федерального подоходного налога (FIT) изменен на обратный. Другими словами, программа независима от порядка следования полей.
Кроме того, рисунок 6.1 иллюстрирует переопределение полей записи. В физическом файле поле общего дохода представляет собой упакованное десятичное число, содержащее 7 цифр, две из которых расположены справа от запятой. Однако программа написана так, что поле общего дохода должно иметь зонный десятичный формат с 8 цифрами, две из которых расположены справа от запятой. Логический файл обеспечивает нужное программе представление, а также осуществляет преобразование между упакованным и зонным десятичным форматами.
Использование множественных логических файлов, построенных над одним и тем же физическим файлом, предоставляет альтернативные пути доступа к данным и обеспечивает разделение данных между программами. На рисунке 6.2 показан еще один логический файл для другой программы, который был добавлен к первому примеру. Теперь каждая программа имеет свое представление записей, хранящихся в физическом файле, и доступ только к тем полям, к которым он разрешен. Поля, присутствующие в обоих логических файлах, позволяют программам совместно использовать данные.
 Рисунок 6.2. Совместное использование данных
Рисунок 6.2. Совместное использование данных
Очень важно подчеркнуть, что обе программы работают с теми же самыми физическими данными, — копирования данных нет. Обновление данных, выполненное одной программой, становится немедленно «видимо» другой. Эта возможность работы программ с текущими значениями данных, а не с копиями, используется в System/38 и AS/400 на протяжении уже почти 20 лет.
Защита данных
Итак, логические файлы позволяют защищать данные на уровне записей и полей. Мы увидели на примере, что поля можно защитить, просто не включая их в описание логического файла. Рассмотренные нами примеры просты, и в них не показана возможность выборки записей. Достичь защиты на уровне поля можно с помощью выборки и пропуска на уровне логического файла. В результате, пользователи получат доступ только к данным, удовлетворяющим критериям выборки. Если у пользователя нет доступа к какому-либо файлу, то данный файл защищен. Если пользователь, не имеющий прав на доступ, например, к общему доходу, попробует запустить программу, использующую данный путь, то программа не будет работать. Все логические и физические файлы AS/400 — это системные объекты, и для доступа к ним необходимы соответствующие права. Защита данных обеспечивается путем комбинации логических файлов и компонента управления доступом операционной системы. Мы можем предоставить конкретному пользователю следующие виды доступа к какому-либо физическому файлу: доступ ко всему файлу (с помощью средств управления доступом); разрешить некоторые типы операций с файлом, например, чтение, но не обновление (с помощью средств управления доступом); доступ к некоторым полям (с помощью логического файла); доступ к некоторым записям (с помощью логического файла).Целостность и восстановление данных
Целостность данных, хранящихся в базе крайне важна. Между тем, при одновременном чтении и изменении данных многими пользователями существует вероятность их разрушения. База данных AS/400 предоставляет надежные средства обеспечения целостности данных. Средства восстановления данных необходимы на тот случай, если данные все же разрушатся или станут недоступными. Часто полагают, что такое может произойти лишь вследствие аппаратных сбоев. В AS/400 есть даже несколько средств предотвращения порчи данных при аппаратном сбое — это так называемые средства обеспечения доступности (availability). Но хотя аппаратный сбой — наиболее распространенная причина порчи данных, программы также могут содержать ошибки, после которых требуется восстановление данных. Подробное обсуждение целостности данных и их последующего восстановления потребовало бы отдельной книги. А мы сможем лишь кратко описать средства, предоставляемые базой данных AS/400, а также то, как некоторые из этих средств реализованы аппаратно.Журнал
Журнал — это хронологическая запись изменений данных, предназначенная для восстановления предыдущей версии набора данных. В AS/400 поддерживаются журналы различных типов, в том числе журнал базы данных. При внесении изменения в запись журналируемого файла базы данных, в журнал помещается копия записи вместе с информацией, описывающей причину изменения. Ведение записей поддерживается двумя объектами OS/400: журналом и приемником журнала. Журнал идентифицирует журналируемые объекты, а приемник содержит записи журнала. Для гарантии сохранения информации приемники журнала могут немедленно записываться на диск. Помимо прочего, запись журнала содержит следующую информацию: имена файла, библиотеки и программы, относительный номер записи, дату и время изменения; а также идентификацию задания, пользователя и рабочей станции. Вместе с этой информацией в приемник журнала записывается копия измененной записи. AS/400 может также записать в журнал копию записи перед выполнением изменения. Журналы базы данных используются для восстановления, как при сбоях системы, так и в случаях ошибок в программах. При аварийной остановке системы из-за аппаратного или программного сбоя файлы базы данных, для которых велся журнал, автоматически восстанавливаются при перезагрузке и будут обновлены в соответствии с информацией, записанной в приемниках журнала. Если программа ввела в файл, для которого ведется журнал, ошибочные данные, то AS/400 может восстановить такой файл как прямым, так и обратным способом. В первом случае сначала восстанавливается резервная версия файла, затем к нему применяются записи журнала, сделанные до того момента времени, когда произошел сбой. При обратном восстановлении ошибочные изменения удаляются из файла, но для этого в журнале должны быть копии записей как до, так и после изменения.Системная защита пути доступа SMAPP
В прошлом пользователи AS/400 были вынуждены мириться с долгим временем перезагрузки после аварийной остановки: пути доступа[ 54 ], открытые для обновления файла, должны были быть построены заново. Вспомните, что в главе 5 мы упомянули возможность отложенной коррекции логического файла. Вследствие этого целостность логического файла при аварийной остановке может нарушиться. В зависимости от числа и размера открытых путей доступа по ключу, временной промежуток, требуемый для их восстановления, может быть значительным, для больших систем — несколько часов. Как мы только что говорили, в AS/400 имеются средства журналирования, в том числе и для логических файлов. Если пользователь задействует ведение журнала для путей доступа, то время перезагрузки системы может быть значительно сокращено. Потенциальная трудность состоит в том, что пользователь должен сначала определить, для каких файлов следует вести журнал, оценить размер приемников журнала и дать команду активизации журналирования. Некоторые так и поступают, но, увы, таких пользователей меньшинство. Для автоматического ведения журнала IBM разработала SMAPP (System-Managed Access Path Protection). Система сама вычисляет максимальное время, требуемое на восстановление путей доступа после сбоя и соответственно определяет необходимый объем журналирования путей доступа. Пользователь всегда может увеличить или уменьшить вычисленное системой время. Чем время меньше, тем больше системных ресурсов потребуется для ведения журнала. Таким образом, ведение журнала предполагает выбор между системными ресурсами, предназначенными для нормальной работы, и мерами предосторожности на случай аварийной перезагрузки. После вычисления или задания пользователем максимально допустимого времени, система просматривает все пути доступа по ключу, существующие в базе данных; затем вычисляет общее время, требуемое для восстановления всех этих путей. Если время превышает максимально допустимое, то система автоматически начинает ведение журнала для отдельных путей доступа, чтобы гарантировать минимизацию времени на восстановление. SMAPP использует специальную область ведения журнала, не требующую действий со стороны пользователя. Эта область — циклическая, то есть по достижении конца запись продолжается с начала. Система всегда поддерживает в этой области достаточное число записей.Управление транзакциями
Иногда целостность данных может быть нарушена, особенно, если с записями физического файла работают несколько пользователей. Предположим, что один пользователь считывает запись, собираясь обновить какое-то ее поле. Что произойдет, если то же самое поле записи одновременно обновляет и другой пользователь? Если второй пользователь изменит поле после того, как значение поля считано первым пользователем, нарушится ли целостность данных? К счастью, этого не произойдет, так как база данных обеспечивает защиту от параллельного обновления. Однако, при более сложных вариантах одновременного изменения нескольких записей, система не гарантирует автоматической защиты. Допустим, что необходимо одновременно изменить несколько взаимосвязанных записей. Часто, для описания такой ситуации используется пример с банкоматом. Пользователь банковского терминала запускает транзакцию: вставляет в машину кредитную карту, вводит идентификационный код и выбирает тип транзакции. В результате этого клиентская запись считывается из базы данных центрального компьютера, который может располагаться на другом конце города или земного шара. Если клиент запрашивает выдачу наличности, то по содержимому записи проверяется, достаточен ли остаток денег на счете. Затем остаток уменьшается на затребованную величину и банкомату посылается команда на выдачу денег. Что если случилась поломка, и банкомат не может выдать наличность? Прежде чем эта неудавшаяся транзакция завершится, следует отменить изменение остатка на счете клиента. Средство, используемое для этого в AS/400, — управление транзакциями (commitment control). Так как все изменения невозможно выполнить одновременно, система обязана защитить группу взаимосвязанных записей и не освобождать ее до тех пор, пока все изменения не будут внесены. Команда «Commit» позволяет изменить группу записей так, чтобы она выглядела как одна операция. Если нельзя выполнить какое-либо изменение, то вся группа изменений может быть отменена по команде «Rollback». Для этих операций управление транзакциями использует журналирование.Триггеры
Триггер — действие, выполняемое автоматически всякий раз, когда содержимое физического файла изменяется — удобный способ связать одну операцию с другой. Триггеры — разновидность пользовательского средства обеспечения целостности базы данных, встроенная в определение файла. Часто изменение базы данных, например, добавление или удаление записи, требует некоторых дополнительных действий. В этих случаях триггер может запустить соответствующую программу. В других случаях, при изменении записи может требоваться запустить программу проверки нового значения поля записи: например, если при обновлении данных в файле инвентарной описи число учитываемых предметов упадет ниже допустимого уровня. Триггер для такого файла может при каждом обновлении запускать программу, проверяющую значение и отправляющее поставщику в случае необходимости дополнительный заказ. При добавлении к физическому файлу триггера необходимо определить три атрибута. Первый — событие, приводящее к запуску триггера: вставка, обновление или удаление записи из файла. Второй атрибут задает, когда следует запустить триггер — до или после события. Наконец, третий атрибут задает программу запуска триггера. Обычно это пользовательская программа, написанная на любом ЯВУ, поддерживаемом AS/400. Таким образом, для каждого физического файла можно назначить до шести триггеров: по два триггера для обновления, вставки и удаления записей, так чтобы один триггер запускался до события, второй — после. Триггеры добавляют командой «ADDPFTRG» (Add Physical File Trigger), а удаляют командой «RMVPFTRG» (Remove Physical File Trigger).Ссылочная целостность
На практике данные одного физического файла часто зависят от данных другого. Если программа обновляет один файл независимо от другого, то целостность данных может быть нарушена. Часто ответственность за поддержку таких зависимостей ложится на прикладную программу. Ссылочная целостность — это средство, встроенное в базу данных AS/400 и позволяющее снять эту ответственность с прикладных программ. Ссылочная целостность обеспечивает непротиворечивость данных двух физических файлов. Она определяет правила или ограничения, гарантирующие, что каждой записи в одном файле будет соответствовать запись в другом. Программа не сможет изменить запись, если такое изменение нарушит заданные правила. В качестве простого примера предположим, что у нас имеется главный файл, содержащий запись для каждого клиента. В качестве ключа в этом файле используется ID клиента. Внутри базы данных имеются также другие файлы, использующие в качестве ключа ID клиента. В подобных случаях целесообразно, используя ссылочную целостность, ввести такое ограничение для каждого из зависимых файлов, которое не позволит прикладным программам добавлять в файлы ID клиента, если такого ID нет в главном файле. Очевидно, что могут быть и гораздо более сложные сценарии реализации ссылочной целостности.Дисковые системы высокой доступности
Диски — это механические устройства, а механические устройства могут ломаться. Стандартная форма защиты для любой вычислительной системы — периодическое сохранение данных с дисков на другой носитель, обычно, ленту. Эта резервная копия содержит слепок базы данных или некоторой ее части на определенный момент времени. Если с данными на диске что-то произошло, то копия данных на ленте поможет восстановить потерянную информацию. Ранее мы рассматривали прямое восстановление базы данных с помощью журнала. Первым шагом этого процесса было восстановление резервной копии данных. Затем к этой копии применяются записи журнала, сделанные с момента ее создания, до тех пор, пока база данных не будет восстановлена. У AS/400 мощные средства сохранения/восстановления. Но иногда для восстановления данных при сбое диска требуется неприемлемо большое время. Обычно, в процессе восстановления система недоступна пользователям. Это может доставить большие затруднения, особенно, если необходимо физически заменить диск перед восстановлением данных. Альтернатива такой процедуры — дисковая подсистема, которая может так переносить сбои диска, чтобы система не становилась недоступной. AS/400 поддерживает два типа защиты дисков для обеспечения высокой доступности: зеркалирование дисков и дисковые массивы. Зеркалирование требует чтобы у каждого диска был «напарник». Всякий раз по команде записи на диск все данные дублируются на оба парных диска. Если один из дисков сломается, то доступ к данным со второго диска даст системе возможность продолжать работать. Для еще большей надежности диски в паре могут быть подключены к разным дисковым контроллерам, на разных процессорах ввода-вывода и на разных шинах. Путем подключения зеркальных дисков к оптической шине ввода-вывода их можно разместить даже в другом помещении (структура и взаимодействие компонентов ввода-вывода AS/400 описаны в главе 10). Зеркалирование обеспечивает наивысший уровень надежности, но дороговата, поскольку требует полного дублирования дисков. Другой подход — использование дисковых массивов. В этом случае диски объединяются в наборы, и данные записываются на все диски набора. Сектор — это фиксированный блок данных на диске. Страница памяти обычно хранится в нескольких екторах диска, и операция записи распределяет сектора по всем дискам набора. Добавление к массиву избыточного диска позволяет обнаруживать место сбоя и втоматически восстанавливать потерянную информацию. При этом используется перация <исключающего или> (XOR) над данными всех секторов набора . любой з операндов может быть восстановлен путем выполнения операции XOR над результатом и другим операндом. Данная технология известна как RAID (redundant arrays of nexpensive disks). Пример операции XOR показан на рисунке 6.3. Результат операции . <истина> то есть, 1) . достигается тогда и только тогда, когда один из операндов <истина> (1), другой . <ложь> (0). В противном случае, если оба операнда являются <истиной> ли оба <ложью>, значением операции является <ложь> (то есть 0). Рисунок 6.3. Пример операцииисключающее ИЛИ
Рисунок 6.3. Пример операцииисключающее ИЛИ
Операция XOR выполняется с данными соответствующих секторов на всех дисках, а ее результат операции сохраняется в секторе на избыточном диске. В случае сбоя диска, данные испорченного сектора восстанавливаются путем операции XOR над данными соответствующих секторов всех исправных дисков набора. Чтобы избежать перегрузки одного из дисков, контрольная информация (результаты операций XOR) распределяется на несколько дисков входящих в массив. Таким образом, любой диск содержит часть данных базы и часть результатов XOR. Целостность данных, восстановление и надежность — важнейшие характеристики любой вычислительной системы. В этом разделе мы рассмотрели лишь основные аспекты этой поддержки.
Другие функции базы данных
DB2/400 поддерживает и несколько дополнительных функций. Некоторые из них расширяют возможности применения AS/400 в клиент/серверных системах и средах распределенных баз данных, другие призваны повысить производительность базы данных. В этом разделе мы затронем только самые важные.Хранимые процедуры
Один из самых действенных способов повысить производительность клиент/серверных приложений для AS/400 — хранимые процедуры. Оператор CALL в SQL позволяет приложению вызывать хранимую процедуру, которая исполняется на сервере AS/400. Таким образом, в результате одного обращения к серверу выполняется це лая транзакция. Без хранимых процедур для этого потребовалось бы множество таких обращений. В качестве хранимой процедуры может использоваться, за небольшими исключениями, любая программа AS/400, в том числе написанная на ЯВУ и даже содержащая операторы SQL. Доступ к хранимым процедурам возможен только через интерфейс SQL с использованием оператора CALL.Поддержка национальных языков
Первый шаг в реализации Unicode на AS/400 был сделан в V3R1, где с его помощью кодировались имена объектов некоторых компонентов интегрированной файловой системы. Unicode поддерживает одновременное использование множества наборов символов (национальных алфавитов) в одной кодировке. В RISC-моделях эта поддержка была расширена, чтобы обеспечить хранение в файлах базы данных в Unicode (UCS2, уровень 1). Например, в одном файле базы данных может находиться информация на французском, немецком, английском, иврите, китайском, русском и других языках. SQL поддерживает преобразование в Unicode и обратно, что делает возможным работу старых приложений с данными в этой кодировке. Кроме того, имеется поддержка локализации (locale) — стандарт X/Open, дающий программистам возможность создавать приложения, самостоятельно адаптирующиеся к различным национальным особенностям (символ денежной единицы, формат даты и времени, формат чисел, порядок сортировки, преобразование регистров символов и др.).Предсказывающий регулятор запросов
В большинстве реляционных баз данных присутствует регулятор запросов (query governor) гарантирующий, что единичный запрос не будет выполняться слишком долго. По истечении заданного времени такой регулятор останавливает выполнение запроса. DB2/400 же экономит системные ресурсы, используя предсказывающий регулятор запросов: если, выполнение запроса потребует столь много времени, что все равно будет прервано, то оно просто не начинается. Оптимизатор запросов предварительно анализирует способ, который будет применен при выполнении запроса для доступа к базе, и необходимое для этого время. Предсказанное время сравнивается с предельным временем запроса для данного пользователя. Если предсказанное время превосходит предельное, то пользователю посылается сообщение и тот может либо прекратить выполнение запроса, либо все-таки выдать запрос, отдавая себе отчет в том, что лимит будет исчерпан.Повышение производительности базы данных
Для увеличения производительности различных операций в базе данных DB2/400 есть несколько механизмов. Например, команда «Explain» применяется для предсказания или просмотра характеристик исполнения запроса. Эта функция собирает информацию о том, как SQL используется в программе. Затем пользователь на основе полученной информации может вносить повышающие производительность изменения, как в базу данных, так и в сам запрос. Другие функции позволяют осуществлять операции выборки и вставки поблочно, то есть манипулировать массивами данных одной командой. Кроме того, существуют и расширенные механизмы кэширования. Пользователи могут активизировать экспертный кэш, размер которого в памяти автоматически увеличивается или уменьшается на основании текущей загрузки, предсказанной активности базы данных и выделенных ресурсов. Экспертный кэш использует этого алгоритмы искусственного интеллекта. Пользователь может также назначить статический кэш, чтобы поместить в резидентную область памяти целую таблицу или ее часть.Распределенные базы данных
AS/400 позволяет прикладной программе работать с базой данных как на локальной, так и на удаленной системе; местоположение данных для приложения прозрачно. Это означает, что приложению доступна обработка файла базы данных без информации о том, где он находится. Кроме того, части базы данных могут быть перенесены на другую систему без изменения прикладных программ. Возможность доступа к базе данных на удаленной системе и доступа удаленных систем к данным AS/400 достигается благодаря реализации двух ключевых архитектур: DRDA (Distributed Relational Database Architecture) и DDM (Distributed Data Management). Для доступа к удаленным данным интерфейс SQL использует DRDA. Сначала устанавливается связь с удаленной базой при помощи оператора SQL CONNECT, в котором указывается имя базы. Для поиска имени удаленной базы данных и определения системы, на которой она расположена, используется справочник на локальной системе. После установки соединения между двумя системами возможна посылка запросов SQL к удаленной базе данных. Менеджер базы данных на удаленной системе отвечает на запрос и возвращает ответ на локальную систему. «Родной» интерфейс базы данных AS/400 использует архитектуру DDМ. Файл DDМ задает имя файла на удаленной системе и имя самой этой системы. Когда прикладной программе требуются удаленные данные, файл DDМ связывается с удаленной системой, после чего прикладная программа может работать с удаленным файлом. В отличие от DRDA, где обработка выполняется удаленной системой, использование DDМ означает, что обработка будет вестись на локальной системе. DDМ пересылает с удаленной системы на локальную все записи файла, тогда как DRDA — только результат уже выполненного запроса. Потенциально DRDA может обеспечить лучшую производительность приложений за счет меньших расходов на обслуживание коммуникаций.Шлюзы к другим базам данных
AS/400 работает с базами данных, поддерживающими описанные архитектуры DRDA и DDМ, а также предоставляет интегрированный подход для доступа к другим базам данных. Это позволяет ей работать непосредственно с базой данных любого производителя на другом компьютере в сети. В дополнение к каталогу распределенной базы данных (Distributed Database Directory) в OS/400 присутствует менеджер драйверов (Distributed Database Driver Manager). Он работает с драйверами для других баз данных или файловых систем. Драйверы для баз данных Unix и ПК позволяют приложению AS/400 работать с этими базами так же, как и с любой базой DRDA.Трансформация данных с помощью DataPropagator
Ранее, при обсуждении хранилищ данных мы упоминали о средствах трансформации данных, использующихся для их перемещения данных из оперативной базы в информационную. DataPropagator — одно из таких средств. Его можно использовать не только для хранилищ данных, но и для связи между любыми базами данных типа DB2. В распределенной среде на разных компьютерах могут существовать множественные копии одного и того же файла базы данных. Изменение одной копии не отражается на другой немедленно, поэтому один и тот же файл на разных системах может быть в разной степени актуален. DataPropagator предоставляет механизм репликации изменений файла на все системы через некоторый, определяемый пользователем, интервал времени. Так как при этом используется технология репликации IBM, то изменения могут реплицироваться в сети на любую базу данных семейства DB2.Соединение при помощи OptiConnect
Если компьютер работает не в сети, и сами данные, и средства их обработки располагаются на нем самом. Одиночная система AS/400 поддерживает очень большие, в том числе многопроцессорные, конфигурации, что вполне удовлетворяет нужды большинства крупных заказчиков. Однако, среди наших заказчиков есть такие, чьи требования к производительности и объемам данных превосходят возможности одиночной AS/400. Даже при работе компьютеров в сети накладные расходы на передачу данных ограничивают прирост производительности, который достигается путем распределения приложения между несколькими компьютерами. В этом случае может помочь OptiConnect. В главах 10 и 11 мы рассмотрим новейшие высокоскоростное межсистемное соединение — SAN. Но SAN поддерживается только линией AS/400е, так что OptiConnect еще будет какое-то время использоваться для объединения AS/400. OptiConnect — это продукт, позволяющий соединять друг с другом компьютеры AS/400 с помощью волоконной оптики для большей скорости обработки транзакций. Часто, крупные заказчики AS/400 отделяют обработку баз данных от обработки приложений и размещают базу данных на серверной модели AS/400. В этом случае разные системы объединяются в кластер, в котором некоторые машины выделяются для обработки базы данных, а другие — для приложений. OptiConnect использует DDM, но здесь важно отметить следующее. DDM на сети применяет коммуникационные протоколы на линиях связи (ЛВС). При таком способе связи обычны сильные шумы, и коммуникационный протокол вставляет в передачу слои избыточности и проверок, что приводит к замедлению передачи. Оптическая шина обеспечивает соединение, достаточно чистое, чтобы устранить большую часть избыточности, в результате производительность существенно возрастает. При использовании OptiConnect время, необходимое для доступа к базе на удаленной системе увеличивается лишь на 3 миллисекунды по сравнению с временем доступа к локальной базе данных, то есть удаленные диски работают почти со скоростью локальных. Рост производительности в результате разделения приложений и базы данных зависит от множества факторов, например, от степени использования базы данных. Однако то, что кластер OptiConnect может объединять до 32 машин, позволяет уверенно говорить, что с помощью этого соединения реально создание очень больших конфигураций. OptiConnect применяется не только для наращивания. Система на волоконно-оптических линиях может заменить существующие ЛВС, использующие DDM, что сделает сетевые соединения более быстрыми и надежными. Соединение с помощью OptiConnect дублированных систем позволяет создавать конфигурации с высоким уровнем доступности и возможностей восстановления важнейших приложений и данных. А теперь пришла пора спуститься на уровень ниже и рассмотреть, как функционирует база данных «изнутри». Затем мы поговорим об использовании машинного индекса для поддержки уже рассмотренных нами операций.Внутренняя реализация функций базы данных
Как мы уже говорили в главе 3, функции базы данных AS/400 реализуются по разные стороны MI. В предыдущих разделах обсуждалась, в основном, база данных, реализованная как часть DB2/400 поверх MI. Давайте теперь рассмотрим некоторые системные объекты MI, используемые в DB2/400, а также то, как некоторые из операций над этими системными объектами реализованы в SLIC ниже MI. В этой книге нет места для детального описания всех средств и функций базы данных, и мы остановимся только на самых важных. Далее мы рассмотрим машинный индекс, используемый базой данных и другими компонентами AS/400. Особое внимание уделяется этой теме не только потому, что машинный индекс важен для многих функций AS/400, но и потому что он интересен сам по себе. SLIC поддерживает большие базы данных. Приведем некоторые предельные величины: до 240 ГБ на физический файл; более 2 миллиардов записей на физический файл; до 4 ГБ на индекс; до 2048 байтов на ключ. Следует отметить, что эти ограничения размеров связаны с текущей реализацией SLIC. Для MI нет какого-либо ограничения размеров системных объектов, так как он независим от технологии. SLIC же зависит от технологии, то есть размеры полей некоторых внутренних структур данных предопределены, что, в свою очередь, задает ограничения сверху. Мы обсудим некоторые из этих ограничений при рассмотрении внутренней реализации. Впрочем, как и в любой хорошей системе, здесь остается возможность модификаций, если таковые понадобятся, и об этом мы тоже поговорим. А сейчас, начнем с рассмотрения системных объектов MI, поддерживающих базу данных.
 Объекты базы данных
Объекты базы данных
Ранее мы рассмотрели три основных системных объекта для поддержки базы данных: области данных, индексы областей данных и курсоры. Как и остальные системные объекты, они занимают несколько сегментов в одноуровневой памяти. Каждый из них имеет базовый сегмент, содержащий заголовок сегмента, заголовок ЕРА и специфический заголовок объекта; а кроме того — сегмент ассоциированного пространства.
 Области данных
Области данных
Области данных содержат записи базы данных. Все записи одной области данных схожи: однородны и имеют фиксированную длину. Записи хранятся в порядке их поступления, и все удаленные записи по-прежнему занимают место.
Объект «область данных» состоит из сегментов трех типов. Кроме базового сегмента и сегмента ассоциированного пространства, в его состав может входить до 120 сегментов записей области данных. Каждый элемент сегмента содержит байты состояния и записи базы данных. Байт состояния содержит информацию о нынешнем состоянии записи, или о том, была ли она удалена.
Каждая запись в сегменте области данных записей имеет номер, называемый порядковым номером. Порядковый номер задает положение записи в сегменте. Не путайте порядковые номера, отсчет которых начинается в каждом сегменте заново, с относительным номером записи (возможно, последний Вам лучше знаком, так как находится на уровне OS/400). Относительные номера записей, хранящиеся в логическом файле или проекции, указывают местоположение данных в физическом файле или таблице. Те же самые номера иногда называются в MI номерами элементов области данных.
Начинающийся с нуля порядковый номер указывает, является ли запись первой, второй или n-ной в сегменте. Так как длина всех записей одинакова, необходимости хранения в сегменте порядковых номеров нет. Зная порядковый номер и длину каждой записи можно найти стартовый байт любой записи сегмента. Далее будет рассказано, как порядковый номер используется для поиска записей в базе данных.
Базовый сегмент не содержит информации об области данных, его основная роль — хранить адреса сегментов области данных. Базовый сегмент также содержит адреса индексов, используемых с этой областью данных.
Ассоциированное пространство содержит таблицу описателей полей с описанием каждого поля записи. Там также размещается рабочая область, используемая компонентами базы данных OS/400. Например, в ассоциированном пространстве хранятся указатели на логические курсоры.
Индексы области данных
Индекс области данных задает альтернативный порядок записей в области данных. Для альтернативного упорядочения используется дерево с двоичным основанием. В разделе «Деревья с двоичным основанием» мы рассмотрим такое дерево и его использование для поддержки ряда функций AS/400, включая индекс области данных. Индекс области данных задействован во множестве операций. Так, он поддерживает ключи переменной длины. Значения ключей могут вычисляться с помощью различных операций, таких как конкатенация, сложение, вычитание и умножение. Один такой индекс может обслуживать до 32 областей данных. Есть несколько вариантов упорядочения индекса: по возрастанию, убыванию, числовому и абсолютному значениям. Существуют также варианты выполнения коррекции: обновления могут вноситься в индекс немедленно, либо быть отложены. Откладывание обновления индекса позволяет избежать накладных расходов, если изменение в области данных происходит, а индекс не используется. В главе 5 были приведены примеры объектов, включая индекс области данных. Мы видели, что последний состоит из сегментов трех типов: базового, ассоциированного пространства и отложенной коррекции. Последние два сегмента уже были подробно рассмотрены, теперь остановимся на базовом сегменте. Базовый сегмент содержит атрибуты альтернативной сортировки, обеспечиваемой индексом, а также таблицу, описывающую как индекс «видит» каждое поле записей в области данных. Это описание логического представления. Базовый сегмент также содержит до 32 адресов областей данных. Наконец, в базовом сегменте находится дерево с двоичным основанием. Дерево с двоичным основанием может не умещаться в базовый сегмент целиком. Для размещения очень больших деревьев можно подключать сегменты четвертого типа. На практике, к индексу области данных можно присоединить до 64 сегментов дерева. Каждый ключ, хранящийся в сегменте дерева, состоит из цепочки байтов, содержащих его фактическое значение, за которым следует пара полей суффикса ключа. Обычно, такая пара называется относительным адресом. Первое поле содержит номер области данных и идентификацию сегмента записей области, второе — порядковый номер записи в сегменте. Эти два числа уникально идентифицируют запись с ключом аналогично относительному номеру записи в логическом файле или проекции.
 Курсоры
Курсоры
Курсоры — механизм просмотра данных в области данных; через них осуществляется весь доступ к данным. Курсор, о котором мы сейчас говорим, — системный объект MI. DB2/400 поддерживает позиционируемые (scrollable) и последовательные файловые курсоры в соответствии со стандартом SQL 1992. Курсор SQL — это не то же самое, что и системный объект MI «курсор», хотя последний и используется для реализации первого.
Как уже упоминалось, записи физического файла хранятся внутри разделов. Физический файл может состоять из одного или нескольких разделов. Это удобный способ разделения на части данных внутри физического файла. Логические файлы используют ту же концепцию множества разделов. Мы также оговорили, что таблицы и проекции SQL ограничены одним разделом на таблицу или проекцию.
Курсор связан с каждым разделом файла. Он может обеспечить доступ к записям области данных как в порядке их поступления, так и в порядке ключей индекса. Другими словами, курсор может указывать на область данных либо непосредственно, либо «сквозь» индекс области данных. Один курсор может использоваться для нескольких областей данных, а для одной области — несколько курсоров. Курсор отслеживает текущее положение в пути доступа, принадлежащем программе (или заданию, или группе активации). Кстати, это помогает понять, почему он так называется.
С помощью курсора также происходит проецирование в область данных и оттуда, что позволяет рассматривать данные иначе, чем когда они хранятся в области данных. Примеры проецирования — переименование полей, арифметические и строковые выражения и преобразования типов данных.
Курсор позволяет осуществлять выборку записей, используя для этого функции арифметического и строкового проецирования. Обычно, критерий выборки записей задается в предложении WHERE оператора SQL (в DDS использовать арифметические выражения нельзя). С помощью курсоров (то есть, путей доступа), которые выбирают лишь некоторые записи, можно предотвратить нежелательный просмотр пользователем остальных записей. Иными словами, курсор обеспечивает защиту базы данных.
Курсор состоит из двух сегментов: базового и ассоциированного пространства. Базовый сегмент содержит два набора адресов для указания областей данных и индексов областей данных, которые могут использоваться курсором; и тех и других может быть по 32. Единственный случай, когда может потребоваться более одного индекса области данных — логический файл объединения (join-logical file, а не проекция SQL). Базовый сегмент также содержит код проецирования и код выборки, используемые курсором. Ассоциированное пространство курсора содержит текст описания раздела и его атрибуты. Связи на уровне раздела поддерживаются компонентом базы данных в OS/400.
Теперь, изучив каждый из трех основных системных объектов поддержки базы данных, можно говорить о том, как пользователь обращается к файлам базы данных в AS/400.
Доступ пользователя к данным
Все пути доступа пользователя к базе данных идут через OS/400 и MI, прямой доступ к данным — только у SLIC. С точки зрения пользователя, доступ к файлу базы данных OS/400 осуществляется с помощью открытия файла. На уровне MI эта функция реализована командой «Activate cursor». Когда пользователь закрывает файл, аналогично используется команда MI «Deactivate cursor». При доступе к области данных пользователь может задать несколько опций команды открытия файла. В их состав входят тип операции (чтение, запись, обновление и удаление) и число записей. Если курсор оперирует с несколькими областями данных, пользователь может отобрать для работы подмножество этих областей. Определение этого подмножества задается при создании файла командой «CRTLF». В процессе работы это подмножество может быть переопределено командой «OVRDBF» (Override with Database File), выданной перед открытием файла. При создании файла пользователь также может задать время ожидания заблокированной записи, и также переопределить это время перед открытием файла. Пользователь осуществляет доступ к области данных в произвольном или последовательном режиме. В режиме последовательного доступа возможна пересылка нескольких страниц с диска в основную память операцией переноса (bring). Пользователь задает размер переноса с помощью опции «число записей» в команде «OVRDBF» или «OPNQRYF» (Open Query File). В режиме произвольного доступа обычно считы-вается одна страница. Произвольный режим возможен только в том случае, если у области данных есть индекс, тогда код базы в SLIC использует схему просмотра для переноса в память следующей логической страницы индекса. Для доступа к данным в области данных нужен курсор. Поэтому для начала работы можно использовать команду MI открытия курсора «Activate cursor», а по завершении закрыть курсор командой «Deactivate cursor». Эти функции работы с курсором на уровне MI эквивалентны открытию и закрытию файла в OS/400. Ассоциированное пространство активного курсора содержит информацию об открытом пути данных ODP (Open Data Path) для открытого раздела. Исполнение команды: MI «Activate cursor» присоединеняет курсор к активизировавшему его процессу (единица работы в системе), а точнее — к связанному с процессом блоку управления (этот объект MI будет подробно рассмотрен позднее). Если процесс активизирует более одного курсора, то к блоку управления процессом присоединяется двусвязный список курсоров. Теперь никакой другой процесс не сможет использовать эти курсоры. Если тот же самый курсор потребуется другим пользователям, то при активизации ими курсора будет создана его копия. Получается, что курсор может быть постоянным и временным. Постоянный курсор связан с каждым разделом файла, а каждый раздел файла имеет один и только один постоянный курсор. Если курсор активизируется для предоставления ODP к разделу файла, но он уже был активизирован другим процессом, то создается временный курсор-копия. В целях экономии места коды проецирования и выборки во временном курсоре не хранятся. Адреса во временном курсоре указывают на постоянный курсор, содержащий соответствующие коды. По принятому соглашению, OS/400 всегда создает временную копию постоянного курсора с помощью команды «CRTDUPOBJ» (Create Duplicate Object) и затем активизирует только временные курсоры. Благодаря этому, постоянный курсор может быть представлением раздела файла, так как помимо него объекта-раздела на уровне MI нет. Более того, все ODP — это временные курсоры, что также результат соглашений принятых в OS/400, а не ограничение MI.
По принятому соглашению, OS/400 всегда создает временную копию постоянного курсора с помощью команды «CRTDUPOBJ» (Create Duplicate Object) и затем активизирует только временные курсоры. Благодаря этому, постоянный курсор может быть представлением раздела файла, так как помимо него объекта-раздела на уровне MI нет. Более того, все ODP — это временные курсоры, что также результат соглашений принятых в OS/400, а не ограничение MI.
Журналы SLIC
Ранее мы рассматривали ведение журналов базы данных. Базовые функции для протоколирования изменений базы данных реализованы ниже MI. Соответствующая поддержка предоставляется двумя системными объектами MI: порт журнала и область журнала. Порт журнала управляет определением журнала, а область журнала представляет собой контейнер для записей в него. Эти два объекта поддерживают объекты OS/400 журнал и приемник журнала соответственно. Обратите внимание, что на границе MI имена снова меняются. Порт журнала, как и почти все другие системные объекты, состоит из двух сегментов. Базовый сегмент содержит адреса объектов, для которых ведется журнал, а также адреса текущих журнальных пространств. Компонент базы данных, реализованный в OS/400, использует сегмент ассоциированного пространства. Область журнала — это специальный системный объект MI, состоящий из множества сегментов. Базовый сегмент содержит адреса порта журнала, а также адреса до 120 сегментов данных журнала. Сегмент данных журнала — это сегмент еще одного типа, который может быть частью системного объекта «область журнала». В сегментах данных журнала хранятся записи журнала. Записи журнала имеют переменную длину. Каждая запись содержит: поле длины, последовательный номер, поле типа, отметки времени и даты, идентификацию пользователя, программы и задания, а также информацию, заносимую в журнал. Важно отметить, что эти записи не могут обновляться или удаляться. Задачей журнала является просто хранение копий изменений базы данных на тот случай, если потребуется восстановление.Управление транзакциями в SLIC
Ранее мы обсуждали базовые функции подтверждения и отката изменений. Эти функции поддерживаются и в MI, и в компоненте базы данных на уровне SLIC. В MI такую поддержку предоставляет системный объект блок транзакции (commit block). Он фиксирует изменения объекта, участвующего в транзакции. Блоки транзакции связаны с процессами. Объекты добавляются к блоку транзакции и удаляются из него. Блок транзакции также содержит информацию о блокировках записей. Эти блокировки освобождаются командой MI <<Cornrnrt>>. Команда <<Decornrnrt>>, которая практически во всех ЯВУ (включая набор команд OS/400) называется «Rollback», откатывает все изменения, сделанные в процессе транзакции, освобождает блокировки и устанавливает курсор в положение, нормальное на момент начала транзакции.Машинные индексы
Перейдем к последней теме, связанной с нижним уровнем поддержки базы данных в AS/400 — к индексам. Мы уже обсуждали два вида индексов: независимый (в главе 5) и индекс области данных (в этой главе). Повторю, что оба этих системных объекта содержат дерево с двоичным основанием. Итак, что такое индекс? На мой взгляд, наиболее удачное определение таково: индекс — организованный набор информации для быстрого поиска в наборе элементов, например в большой таблице. Индексация играет важную роль в реализации многих компонентов AS/400 и любой другой системы. Поэтому еще при проектировании System/38 было принято решение встроить ниже MI максимально эффективный индекс таким образом, чтобы все системные компоненты могли при необходимости использовать его, а не создавать свои собственные. Этот встроенный индекс и называется машинным индексом. Машинный индекс полезен различным компонентам AS/400 при поиске в таблицах, адресации областей, сортировке и т. д. База данных применяет его при индексации области данных, работе со списком транзакций журнала и т. п.; компонент управление памятью — для многих своих справочников. Машинные индексы используются и в контекстах, и для поиска прав доступа. OS/400 использует объекты типа «независимый индекс» для нескольких целей, включая обработку сообщений, защиту и спулинг. Основные характеристики машинного индекса таковы: обеспечивает обобщенный поиск, позволяя находить группы связанных элементов; управляет используемым пространством; позволяет минимизировать случаи отсутствия нужной страницы в памяти (страничные ошибки); поддерживает ключи переменной длины до 2048 байтов; использует алгоритм двоичного поиска; хранит элементы в виде фрагментированного дерева с двоичным основанием (подробнее — в разделе «Внутренняя организация дерева с двоичным основанием» этой главы).Двоичный поиск
Проще всего понять, что такое двоичный поиск, можно на примере игры в угадывание чисел. Смысл игры в том, что один игрок задумывает число внутри некоторого диапазона, например между 1 и 1000, а второй — пытается угадать это число за минимально возможное количество попыток. При каждой попытке второму игроку сообщается, является ли названное им число большим, меньшим или равным задуманному. Прием быстрого угадывания чисел в этой игре основан на двоичной системе счисления. Чтобы угадать число между 1 и 1000, при первой попытке следует назвать 512 (29 = 512). Если нам скажут, что это число слишком велико, то задуманное число больше нуля и меньше 512, поэтому далее мы называем 256 (28= 256) — следующую меньшую степень двойки. Если же сказано, что названное число меньше задуманного, то задумано число большее 512 и для следующей попытки нужно прибавить 256 к 512 и назвать 768, и при каждой следующей попытке прибавлять следующую меньшую степень двойки. Если названное число больше задуманного, мы вычитаем эту степень двойки и прибавляем следующую меньшую степень. Предположим, что первый игрок задумал 700. Отгадывающему следует называть такую последовательность чисел: 512, 768, 640, 704, 672, 688, 696 и, наконец, 700. При этом ему будет сообщаться, что первое число меньше, второе больше, третье меньше и т. д. На основании этой информации он будет вычислять следующее значение и, в конце концов, задуманное число будет отгадано за восемь попыток. Если мы посмотрим на последовательность ответов первого «больше/меньше» из приведенного примера, то заметим интересную закономерность. Эта последовательность выглядит так: «меньше», «больше», «меньше», «больше», «меньше», «меньше», «меньше» и «равно». Если на место каждого ответа «больше» подставить 0, а на место каждого ответа «меньше» — 1, то мы получим двоичное число. Учитывая, что для задания любого числа между 1 и 1000 требуется 10 разрядов, можно представить 700 как 1010111100. Мы угадали это число, двигаясь слева направо и используя ответы «больше/меньше» для определения двоичной цифры в текущей позиции. С использованием данного метода задуманное число всегда может быть найдено не более чем за 10 попыток. В нашем примере потребовалось только восемь попыток,так как число делится на 4 — степень двойки. Обратите внимание, что любое нечетное число потребует 10 попыток, по одной на разряд. Максимальное число попыток можно вычислить как логарифм 1000 по основанию 2. Иначе это значение можно определить, учитывая, что 2 = 1024. Для угадывания числа между единицей и миллионом по данному методу требуется лишь 20 или менее попыток. Приведенный пример иллюстрирует алгоритм двоичного поиска, который применяется для нахождения элемента индекса. Структура, в которой все записи заполнены, считается сбалансированной. При поиске по сбалансированному индексу с n элементами требуется выполнить сравнение лишь для log2 n элементов. Наш пример с угадыванием чисел был сбалансированным, так как в последовательности присутствуют все числа. Но даже для сильно несбалансированных структур среднее число попыток возрастает менее чем на 10 процентов. Алгоритм двоичного поиска отлично работает для большого числа элементов, но обычно не рекомендуется, если их число меньше 50.Деревья с двоичным основанием
 Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в качестве следующего выбирается один из двух узлов следующего уровня. Начиная с вершины дерева[ 55 ], первый узел проверяет первый разряд числа (самый левый). Второй слой дерева содержит два текстовых узла, один из которых выбирается, если первый разряд был равен 0, а другой — если первый разряд был равен 1. На третьем уровне имеется четыре узла, на четвертом — восемь и так далее вплоть до десятого узла, на котором расположено 512 тестовых узлов. Одиннадцатый уровень — последний для данного дерева и содержит 1024 окончательных узла. Окончательный узел содержит точное значение искомого числа.
Итак, для поиска числа мы начинаем с вершины дерева и проверяем разряды: слева направо. На каждом уровне дерева проверяется один из разрядов. После десяти проверок мы оказываемся в одном из окончательных узлов и можем точно назвать число.
Мы только что описали двоичное дерево. Оно сбалансированное, так как присутствуют все узлы. При поиске по таблице могут присутствовать не все узлы, так как в таблице присутствуют не все возможные элементы. Следовательно, и проверяются не все разряды числа, некоторые уровни могут отсутствовать. Такое дерево в отличии от двоичного дерева, где присутствуют все узлы, называется деревом с двоичным основанием (binaryradix tree).
Использование деревьев с двоичным основанием в AS/400 для реализации машинных индексов мы рассмотрим на примере рисунка 6.4. На нем показан простой файл из девяти записей, упорядоченных в порядке поступления. Каждая запись имеет несколько полей, на рисунке показаны лишь некоторые. Одно из полей — поле имени — предназначено для использования в качестве ключа. Для файла построен индекс, который также показан на рисунке. Каждая запись индекса имеет только два поля: поле ключа и логический адрес записи. Девять элементов индекса отсортированы по порядку значений ключа. В данном случае, ключи отсортированы по алфавиту, и первым элементом является Baker, а последним Wu. Поле логического адреса записи задает относительную позицию соответствующей записи в исходном файле, логическая адресация всегда начинается с 0 (для первой записи). Элемент для Baker указывает, что запись Baker является в файле седьмой.
Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в качестве следующего выбирается один из двух узлов следующего уровня. Начиная с вершины дерева[ 55 ], первый узел проверяет первый разряд числа (самый левый). Второй слой дерева содержит два текстовых узла, один из которых выбирается, если первый разряд был равен 0, а другой — если первый разряд был равен 1. На третьем уровне имеется четыре узла, на четвертом — восемь и так далее вплоть до десятого узла, на котором расположено 512 тестовых узлов. Одиннадцатый уровень — последний для данного дерева и содержит 1024 окончательных узла. Окончательный узел содержит точное значение искомого числа.
Итак, для поиска числа мы начинаем с вершины дерева и проверяем разряды: слева направо. На каждом уровне дерева проверяется один из разрядов. После десяти проверок мы оказываемся в одном из окончательных узлов и можем точно назвать число.
Мы только что описали двоичное дерево. Оно сбалансированное, так как присутствуют все узлы. При поиске по таблице могут присутствовать не все узлы, так как в таблице присутствуют не все возможные элементы. Следовательно, и проверяются не все разряды числа, некоторые уровни могут отсутствовать. Такое дерево в отличии от двоичного дерева, где присутствуют все узлы, называется деревом с двоичным основанием (binaryradix tree).
Использование деревьев с двоичным основанием в AS/400 для реализации машинных индексов мы рассмотрим на примере рисунка 6.4. На нем показан простой файл из девяти записей, упорядоченных в порядке поступления. Каждая запись имеет несколько полей, на рисунке показаны лишь некоторые. Одно из полей — поле имени — предназначено для использования в качестве ключа. Для файла построен индекс, который также показан на рисунке. Каждая запись индекса имеет только два поля: поле ключа и логический адрес записи. Девять элементов индекса отсортированы по порядку значений ключа. В данном случае, ключи отсортированы по алфавиту, и первым элементом является Baker, а последним Wu. Поле логического адреса записи задает относительную позицию соответствующей записи в исходном файле, логическая адресация всегда начинается с 0 (для первой записи). Элемент для Baker указывает, что запись Baker является в файле седьмой.
| Файл | Индекс | ||||
| Адрес | |||||
| Имя | Дата рождения | Должность | Имя | логической записи 0 | |
| JONES | 082140 | A | BAKER | 006 | |
| SMITH | 122750 | K | BARNS | 007 | |
| WU | 041259 | Z | CARSON | 008 | |
| MARKLY | 111163 | T | JOHNSON | 005 | |
| PETERS | 070457 | C | JONES | 000 | |
| JOHNSON | 062753 | A | MARKLY | 003 | |
| BAKER | 031747 | C | PETERS | 004 | |
| BARNS | 090959 | B | SMITH | 001 | |
| CARSON | 013147 | B | WU | 002 |

Теперь с помощью двоичного представления ключей можно создать дерево с двоичным основанием. При построении дерева ключи добавляются по одному. Сначала последовательность битов каждого нового ключа просматривается слева направо в поисках первого, отличающего данный ключ от всех ключей, уже вставленных в дерево. Предположим, что единственным элементом дерева является Baker и мы хотим добавить элемент Barns. Взглянув на рисунок 6.5, можно увидеть, что первым отли чающимся битом (сканирование всегда идет слева направо) будет пятый в третьем байте. Если в дереве только два элемента Baker и Barns, то чтобы отличить один от другого, достаточно проверить пятый разряд третьего байта. Если разряд равен 0, то это элемент Baker, а если 1, то Barns. Допустим, теперь мы хотим добавить к дереву Carson. Тогда первым битом, отличающимся и от Baker, и от Barns, будет восьмой первого байта. Последовательность построения дерева показана на рисунке 6.6. На первом шаге в дереве есть единственный окончательный узел для Baker. Окончательный узел содержит некоторый текст (в данном случае «Baker») и логический адрес записи 006. На втором шаге к дереву добавляется Barns. Здесь к дереву непосредственно над Baker добавляется тестовый узел для проверки пятого разряда третьего байта. Тестовый узел содержит общий текст ключей (BA) и номер бита, который должен проверяться в следующем байте. В нашем примере с двумя байтами совпадающего текста (ВА) ясно, что бит, нуждающийся в проверке, находится в следующем (третьем) байте, задавать который явно не обязательно. При выборе следующего узла всегда берется левый, если проверяемый бит равен 0, и правый — в противоположном случае. Справа от первого окончательного узла добавлен второй окончательный узел для Barns с логическим адресом записи 007. Обратите внимание, что после удаления общего текста, терминальные узлы содержат только остатки имен (KER и RNS для Baker и Barns соответственно).
 Шаг 1: В дереве только BAKER
Шаг 1: В дереве только BAKER
 Шаг 2: Добавляем BARNES
Шаг 2: Добавляем BARNES
 Шаг 3: Добавляем CARSON
Рисунок 6.6. Построение дерева с двоичным основанием
На шаге 3 к дереву добавляется Carson. Создается новый тестовый узел для проверки восьмого бита первого байта. В новом тестовом узле нет общего текста. Если при проверке восьмой бит первого байта равен 0, то далее следует проверить расположенный левее тестовый узел для Baker/Barns. Если же восьмой бит первого байта равен 1, то следующим будет окончательный узел справа для Carson. Данный узел содержит текст (CARSON) и логический адрес записи 008.
На рисунке 6.7 дерево показано полностью, со всеми девятью элементами. Тестовый узел наверху дерева называется корневым узлом. Хотя в данном примере представлен относительно небольшой индекс, он иллюстрирует многие характеристики дерева с двоичным основанием.
Шаг 3: Добавляем CARSON
Рисунок 6.6. Построение дерева с двоичным основанием
На шаге 3 к дереву добавляется Carson. Создается новый тестовый узел для проверки восьмого бита первого байта. В новом тестовом узле нет общего текста. Если при проверке восьмой бит первого байта равен 0, то далее следует проверить расположенный левее тестовый узел для Baker/Barns. Если же восьмой бит первого байта равен 1, то следующим будет окончательный узел справа для Carson. Данный узел содержит текст (CARSON) и логический адрес записи 008.
На рисунке 6.7 дерево показано полностью, со всеми девятью элементами. Тестовый узел наверху дерева называется корневым узлом. Хотя в данном примере представлен относительно небольшой индекс, он иллюстрирует многие характеристики дерева с двоичным основанием.
 Рисунок 6.7. Пример дерева с двоичным основанием
Рисунок 6.7. Пример дерева с двоичным основанием
Любое имя в дереве может быть найдено уже описанным методом. Но как быть с именами, которых в дереве нет? Предположим, что мы пытаемся найти там имя Soltis. Проверяем третий бит первого байта и видим, что он равен 1, затем — шестой бит первого байта, который равен 0. Это приводит нас к окончательному узлу для Smith. Теперь понятна причина хранения текста в окончательных узлах — на один и тот же окончательный узел может отображаться много имен. При достижении окончательного узла необходимо сравнить хранящийся там текст с остатком имени, поиск которого мы ведем. Если они совпали — мы нашли правильный окончательный узел, если нет — искомое имя отсутствует в дереве. Другая характеристика дерева связана со способом добавления к нему элементов. Мы всегда просматриваем строку битов для каждого нового элемента слева направо в поиске первого бита нового ключа, отличающего его от всех, уже находящихся в дереве. Таким образом, гарантируется, что при проходе по любому пути в дереве биты проверяются слева направо. В тестовом узле никогда не приходится возвращаться к началу имени: мы всегда движемся вперед. Метод, используемый для вставки элементов, также гарантирует, что дерево всегда будет иметь одну и ту же конфигурацию, независимо от порядка добавления элементов. Более того, окончательные узлы всегда упорядочены в соответствии со значениями ключей слева направо. В нашем примере, окончательные узлы расположены в алфавитном порядке имен в ключевом поле. Это не случайность, а свойство дерева. Дерево само по себе обеспечивает логическую последовательность ключей, так что сортировка физических записей не нужна. Элемент дерева можно также удалить. Это простая операция, так как на окончательный узел может указывать один и только один тестовый узел. Возьмите имя, подлежащее удалению, отыщите в дереве соответствующий ему окончательный узел, удалите его, вернитесь к расположенному выше тестовому узлу и объедините его со вторым окончательным узлом в новый окончательный узел.
Внутренняя организация дерева с двоичным основанием
Внутренняя форма хранения дерева с двоичным основанием оптимизирована как с точки зрения производительности, так и занимаемого пространства. Первая базовая структура для дерева с двоичным основанием была создана инженером Филом Хо-вардом (Phil Howard) в 70-х годах. В его схеме правый и левый потомки тестового узла вместе с возможным общим текстом объединены вкластер. Такие кластеры располагались в памяти один за другим, и для ссылки на кластер использовалось его положение в цепочке. Это устраняло необходимость учета адресов для ссылки на следующий узел. Фил изобрел очень элегантный механизм перемещения от одного узла дерева к другому. Кластер не содержал адресов следующего или предыдущего узла. Вместо этого, их положения определялись с помощью операции XOR, что позволяло перемещаться по дереву в обоих направлениях. Этим достигалась еще и экономия памяти, поскольку не нужно было хранить прямые и обратные ссылки на предыдущие и последующие узлы. Чтобы найти следующий узел дерева, операция XOR выполняется над значением, хранящимся в текущем узле, и позицией предыдущего узла. Ясно, что значение, хранящееся в текущем узле, — результат XOR над позициями следующего и предыдущего узлов. Таким образом, чтобы вычислить местоположение следующего узла, нужно знать лишь текущее значение и позицию предыдущего узла. Предположим, что мы хотим пройти по дереву в обратном направлении. Выполнив операцию XOR над значением в текущем узле и позицией следующего узла, мы получаем позицию предыдущего узла. Таким образом, из любой точки дерева, зная предыдущую, текущую и следующие позиции, а также содержимое текущего узла, можно перемещаться вверх и вниз без ссылок. Для хранения нужных нам трех позиций годится простой стек. Реализация дерева с двоичным основанием минимизирует число страничных ошибок путем разделения дерева на поддеревья. Формально, такую структуру следовало бы называть фрагментированным деревом с двоичным основанием. При переполнении страницы, выше по дереву выполняется разделение, и к индексу добавляются новые поддеревья. Предположим, мы решили разделить дерево из нашего примера на рисунке 6.7. Разумно поместить на одну страницу все терминальные узлы от Baker до Peters вместе с их тестовыми узлами, а на вторую — терминальные узлы от Smith до Wu, а также один указывающий на них тестовый узел. Однако, здесь нас подстерегает неприятность. В узлах нет адресов для связи с другими узлами — вместо этого используются относительные номера позиций. Чтобы попасть на другую страницу памяти, необходим адрес. Решение состоит в создании узла нового типа, который будет содержать адрес и позволит ссылаться на другую страницу дерева. Если верхний узел нашего примера — корневой узел — поместить на третью страницу и разместить в нем указатели на две другие, то мы получим фраг-ментированное дерево. Верхние узлы на всех трех страницах теперь являются корневым узлами для своих страниц, и мы значительно увеличили максимальный объем памяти, которая может использоваться для хранения данного дерева. Другое преимущество фрагментирования — то, что, попав в процессе поиска на некоторую страницу памяти, содержащую фрагмент дерева, мы остаемся на ней на всех уровнях тестирования. Перед переходом на следующую страницу все тестовые узлы данной страницы на пути поиска будут просмотрены. Кроме того, поскольку для поиска в очень больших индексах требуется относительно немного проверок (вспомните, что при поиске в индексе из миллиона записей требуется, в среднем, только 20 проверок), то лишь в редких случаях придется затронуть более одной-двух страниц. В результате, данная схема обеспечивает наивысшую производительность по сравнению со всеми иными известными схемами индексации.Выводы
Интегрированная база данных дает AS/400 целый ряд преимуществ, обеспечивая недостижимый для других систем уровень эффективности и производительности. Многие из этих преимуществ были нами рассмотрены. Так как база данных AS/400 не «сидит» поверх ОС, ею могут пользоваться все компоненты системы. База данных AS/ 400 не изолирована от других компонентов, как на обычных системах. База данных AS/400 позволяет приложениям, написанным для различных интерфейсов, сосуществовать и работать с одними и теми же данными, обеспечивая непосредственную реализацию на AS/400 внешних интерфейсов и инструментария других баз данных. Следовательно, и приложения, написанные для иных баз данных, уже сейчас могут работать прямо на AS/400, используя данные совместно с остальными приложениями. В будущем эти возможности станут еще более значимы. Интегрированная защита AS/400 защищает базу данных и другие компоненты системы от несанкционированного доступа и предотвращает разрушение данных. В следующей главе, мы рассмотрим эту интегрированную защиту, а также управление доступом в SLIC.Глава 7
Защита от несанкционированного доступа
Хакеры и вирусы на AS/400? Это невозможно. Они пиратствуют только на Unix и ПК. Я вспоминаю фильм «Парк юрского периода», в конце которого девочка подходит к компьютеру, на котором была совершена диверсия, приведшая к выходу динозавров на свободу. «Это Unix!» — восклицает она, вскрывает его защиту и немедленно устраняет неполадки. Тут я сказал про себя: «Конечно, чего же Вы хотели от Unix». А в фильме «День независимости» вирус был запущен в компьютер космического корабля пришельцев. Большинство зрителей до этого и не подозревали, что инопланетяне используют компьютеры Apple Macintosh. Но, слава Богу, это оказалось именно так, вирус сработал, и наш мир был спасен.
Вообще, в фильмах часто злодеи проникают в чужие компьютеры, или недовольный сотрудник внедряет вирус в компьютерную сеть фирмы. Приятно сознавать, что ничего подобного на AS/400 произойти не может. Или все-таки может?
Как и многие другие функции, в AS/400, в отличие от большинства иных систем, защита была встроена с самого начала, а не добавлена уже после создания,. Однако никакие средства защиты не помогут, если их не использовать, а многие пользователи AS/400 так и делают. Например, в среде клиент/сервер необходимо принимать специальные меры для защиты данных AS/400 от незащищенных клиентов, таких как Windows 95 и Windows NT. Более того, в современном сетевом мире многие AS/400 подключены к Интернету, в этом случае также следует применять определенные средства защиты информационных ресурсов. По счастью, интегрированные средства защиты AS/400 обеспечивают крепкий фундамент безопасности всей системы. В этой главе мы рассмотрим средства защиты AS/400 и обсудим, как лучше использовать их.
Я вспоминаю фильм «Парк юрского периода», в конце которого девочка подходит к компьютеру, на котором была совершена диверсия, приведшая к выходу динозавров на свободу. «Это Unix!» — восклицает она, вскрывает его защиту и немедленно устраняет неполадки. Тут я сказал про себя: «Конечно, чего же Вы хотели от Unix». А в фильме «День независимости» вирус был запущен в компьютер космического корабля пришельцев. Большинство зрителей до этого и не подозревали, что инопланетяне используют компьютеры Apple Macintosh. Но, слава Богу, это оказалось именно так, вирус сработал, и наш мир был спасен.
Вообще, в фильмах часто злодеи проникают в чужие компьютеры, или недовольный сотрудник внедряет вирус в компьютерную сеть фирмы. Приятно сознавать, что ничего подобного на AS/400 произойти не может. Или все-таки может?
Как и многие другие функции, в AS/400, в отличие от большинства иных систем, защита была встроена с самого начала, а не добавлена уже после создания,. Однако никакие средства защиты не помогут, если их не использовать, а многие пользователи AS/400 так и делают. Например, в среде клиент/сервер необходимо принимать специальные меры для защиты данных AS/400 от незащищенных клиентов, таких как Windows 95 и Windows NT. Более того, в современном сетевом мире многие AS/400 подключены к Интернету, в этом случае также следует применять определенные средства защиты информационных ресурсов. По счастью, интегрированные средства защиты AS/400 обеспечивают крепкий фундамент безопасности всей системы. В этой главе мы рассмотрим средства защиты AS/400 и обсудим, как лучше использовать их.
Интегрированная защита
В прошлом защитить вычислительную систему было относительно легко. Обычно, было достаточно вставить замок в дверь машинного зала и заставить конечных пользователей вводить при входе в систему пароль. Современный мир уже не так прост. Наибольшей степени опасности подвергаются AS/400, включенные в вычислительную сеть: во внутрифирменную ЛВС или в глобальную сеть, например в Интернет. В любом случае, AS/400 предоставляет средства для минимизации или полного устранения риска несанкционированного доступа. Проблемы защиты вычислительной системы очень похожи на те, что возникают при защите дома или автомобиля: Вы должны правильно рассчитать соотношение цены и допустимой степени риска. Очевидно, что в разных ситуациях AS/400 нужен разный уровень защиты. У пользователя должна быть возможность самостоятельного выбрать этот уровень. Хорошая система защиты разработана так, чтобы компьютер мог работать вообще без защиты, с ограниченной защитой или с полной защитой, но во всех случаях система защиты должна быть активна. И сейчас есть системы, запертые в помещениях, куда доступ строго ограничен. Понятно, что им не нужен такой уровень защиты, как компьютеру, подключенному к Интернету. Но с течением времени требования к защите и этих систем могут повыситься. Интегрированная защита AS/400 достаточно гибка, чтобы перестроиться по мере изменения требований к ней. Защита AS/400 представляет собой комбинацию средств защиты в OS/400 и в SLIC. В OS/400 реализованы уровни общесистемной защиты, при этом OS/400 полагается на функции защиты объектов на уровне MI. Например, как упоминалось в главе 5, MI выполняет проверку прав доступа при каждом обращении к объекту. За действия MI по защите объектов ответственен SLIC. Реализуемый им тип защиты называется авторизацией и предназначен для предохранения объекта от несанкционированного доступа или изменения. Некоторые компоненты защиты AS/400 расположены полностью поверх MI в OS/400, например, задание системных параметров защиты. Другие, такие как контроль за доступом к объектам, полностью реализованы ниже MI в SLIC. Третьи компоненты защиты реализованы частично над, а частично под MI. Пример — поддержка привилегированных команд и специальных прав доступа. Давайте подробнее рассмотрим компоненты, лежащие и выше и ниже MI.Уровни защиты
AS/400 предназначены для широкого применения в различных областях человеческой деятельности. Соответственно, и требования к их защищенности варьируются от уровня ее полного отсутствия до уровня защиты, сертифицированной правительством. Задавая соответствующие системные параметры, можно выбрать одну из пяти степеней: отсутствие защиты, парольная защита, защита ресурсов, защита ОС и сертифицированная защита. При конфигурировании AS/400 должны быть заданы четыре системных параметра, относящихся к защите: QAUDJRL, QMAXSIGN, QRETSVRSEC и QSECURITY. Системным параметром, определяющим уровень защиты, является QSECURITY. В System/38 и первых AS/400 было только три уровня системной защиты, в версии V1R3 OS/400 к ним добавился четвертый, а в V2R3 — пятый, высший уровень защиты. Допустимые значения QSECURITY — 10, 20, 30, 40 и 50. AS/400 поддерживает также дополнительную функцию аудита. Если эта функция задействована, то определенные события, связанные с защитой, заносятся в журнал., То, какие конкретно события протоколировать в журнале аудита защиты, определяет значение системного параметра QAUDJRL и текущий уровень защиты. Могут протоколироваться такие события, как попытки несанкционированного доступа, удаление объектов, идентификация программ, использующих привилегированные команды и др. Содержимое журнала защиты анализирует администратор защиты. Максимальное количество неудачных попыток входа в систему задает системный параметр QMAXSIGN. Если число таких попыток превысит значение этого параметра, то терминал или устройство, с которого они были предприняты, отключаются от системы и связь между ними и системой разрывается. Такой метод позволяет предотвратить попытки подобрать пароль для входа в систему. Значение параметра QMAXSIGN для каждого устройства сбрасывается после успешного входа в систему. Системный параметр QRETSVRSEC (Retain Server Security Data) определяет, может ли информация, необходимая AS/400 для аутентификации пользователя на другой системе через интерфейсы клиент/сервер, запоминаться сервером. Если информация запоминается, то сервер ее использует. Если нет, то сервер будет запрашивать идентификатор и пароль пользователя для другой системы. Системный параметр QRETSVRSEC используется для клиент/серверных интерфейсов TCP/IP, Novell NetWare и Lotus Notes. Теперь давайте рассмотрим каждый из пяти уровней защиты, начиная с самого низкого.Отсутствие защиты (уровень 10)
Уровень 10 означает самую низкую степень защищенности — отсутствие таковой. Для доступа к системе не требуется пароля и любому пользователю разрешен доступ ко всем системным ресурсам и объектам без ограничений. Единственное условие — нельзя влиять на задания других пользователей системы. Системный уровень защиты 10 обычно применяется тогда, когда достаточно только физической защиты системы, например, замка на двери машинного зала. Любой пользователь, имеющий физический доступ к машине, может войти в систему. При этом он не обязан регистрироваться. Регистрация пользователя предполагает наличие где-либо в системе профиля пользователя. Такой профиль при использовании уровня защиты 10 создается автоматически, если еще не существует.Парольная защита (уровень 20)
Если Вам нужна только защита при входе в систему, используйте уровень 20. При этой степени защиты требуется, чтобы пользователь AS/400 был зарегистрирован и знал правильный пароль. После того, как разрешение на вход в систему получено, пользователь имеет доступ ко всем ее ресурсам без ограничений. Как видите отличие от уровня 10 незначительно. Только в одном особом случае доступ пользователя к системе при уровне 20 ограничивается: если в профиле пользователя это специально оговорено. Пользователь с ограниченными возможностями может только выбирать пункты меню. Большинство системных меню имеют строку ввода команд, и упомянутое средство ограничивает использование системных команд. Предположим, что в организации есть группа работников, в чьи обязанности входит прием заказов на товары и ввод соответствующих данных в систему. Для таких пользователей целесообразно создать специальное меню и разрешить им действовать только в этих рамках, для чего их следует зарегистрировать как пользователей с ограниченными возможностями и задать в их профилях меню, доступ к которому им разрешен. Но даже пользователю с ограниченными возможностями разрешено исполнять четыре необходимых команды: для отправки сообщений, для отображения сообщений, для отображения состояния задания и для выхода из системы. То, какие именно команды открыты для пользователя с ограниченными возможностями, можно задать индивидуально. Ограничение возможностей также определяет, какие поля пользователь может изменять при входе в систему. Уровни 20 и 10, не обеспечивают системе защищенность, так как после регистрации пользователя в системе, он может производить там любые операции. Я бы не рекомендовал ограничиваться столь низкими степенями защиты за исключением особых случаев, когда сама система практически недоступна извне.Защита ресурсов (уровень 30)
Минимальным рекомендуемым уровнем защиты является уровень 30. На этом уровне, так же как и на уровне 20, для входа в систему пользователь должен быть зарегистрирован и знать правильный пароль. После входа в систему проверяется, обладает ли пользователь правами доступа к системным ресурсам; несанкционированный доступ не разрешается. На уровне 30 пользователь также может быть зарегистрирован с ограниченными возможностями. Отдельным пользователям могут быть предоставлены права доступа к системным объектам, таким как файлы, программы и устройства. Обеспечивают такую возможность профили пользователя, и вскоре мы поговорим подробнее о том, каким образом они это делают. Мы также рассмотрим другие варианты наделения пользователя правами доступа к системным объектам: с помощью групповых или общих прав. Уровень защиты 30 был наивысшим в System/38. Но на нем не различаются пользовательские объекты и объекты, используемые только ОС. В связи с доступностью на System/38 ассемблера MI и наличия определенной информации о внутренней структуре объектов возникла серьезная проблема. ISV стали писать прикладные пакеты, зависящие от внутренней структуры объектов, что нарушало технологическую независимость MI. В первых моделях AS/400 использовались те же самые уровни защиты. Хотя в AS/ 400 не было ассемблера MI, и мы не публиковали информацию о внутренних структурах, специалисты довольно скоро поняли, что AS/400 — это System/38. Поэтому программы, зависимые от внутренней структуры объектов, работали и на AS/400. Мы понимали, что при переходе к клиент/серверным вычислениям, AS/400 нужна более надежная защита, блокирующая доступ к большинству внутренних объектов. В связи с переходом на RISC-процессоры изменениям подверглась и внутренняя структура. Но если бы мы просто реализовали новый, повышенный, уровень зашиты, то программы, зависимые от внутренней структуры объектов, перестали бы работать, что вызвало бы недовольство заказчиков. Мы объявили о том, что собираемся встроить в V1R3 новый уровень защиты, и что на этом уровне доступа к внутренним объектам не будет. Мы также начали искать тех ISV, кто использовал внутренние объекты, чтобы предоставить им стандартные системные API, с информацией, необходимой для их программ. Большая часть таких программ были утилитами, использовавшими информацию некоторых полей внутри системного объекта. Например, системе управления магнитной лентой могли понадобиться некоторые данные о заголовке ленты. Такую информацию можно было получить единственным способом — проникнув в системный объект. Мы создали сотни API для предоставления подобной информации через MI (по сути дела, эти API были новыми командами MI) и гарантировали, что они будут работать во всех последующих версиях ОС. Таким образом мы развязали себе руки и начали вносить изменения во внутренние структуры. С защитой связана еще одна серьезная тема: тема открытости AS/400. Довольно долго многие ISV не только использовали внутренние объекты, но и настаивали, чтобы IBM сделала внутреннее устройство ОС открытым и дала тем самым «зеленый свет» разработчикам ПО. В ответ IBM утверждала, что при неправильном использовании команд MI велика вероятность программных сбоев, за которые она не может нести ответственность. Компромисс (управляемая открытость через API) был достигнут, частично в результате серии заседаний группы COMMON, начатых по инициативе ISV и других пользователей. Работу с ISV и определение новых API возглавил Рон Фесс (Ron Fess) — один из основных разработчиков ПО с большим опытом работ по CPF и OS/400. Результат это работы — реализация на AS/400 Single UNIX Specification и других стандартных API. AS/400 стала более открытой для пользователей.Защита ОС (уровень 40)
Уровень 40 появился в версии V1R3 OS/400. Сегодня все новые AS/400 поставляются именно с этим уровнем защиты, а не 10, как ранее. Но старые версии OS/400 и при модернизации сохраняют текущий уровень, установленный заказчиком. Теперь пароль начальника защиты (пользователь, обладающий правами доступа наивысшего уровня) становится недействительным после первого ввода в систему и он должен его изменить. Ранее заказчики AS/400 часто не утруждали себя изменением пароля, установленного в системе по умолчанию, что создавало явную «дыру» в защите. При уровне 40 пользователь AS/400 также должен быть зарегистрирован, должен знать правильный пароль для входа в систему и иметь права на доступ к системным ресурсам. Впрочем, пользователи с ограниченными возможностями при этом уровне защиты тоже поддерживаются. В отличие от уровней 10 — 30, при уровне защиты 40 доступ к нестандартным интерфейсам блокирован. Пользователю теперь доступны далеко не все команды MI, а лишь их разрешенный набор, включая сотни API, разработанных для ISV. Остальные же команды блокированы, то есть система не будет исполнять их в пользовательской программе. Тем не менее, команды из блокированного набора по-прежнему доступны OS/400. Для различия программ OS/400 и пользовательских, были введены понятия системного и пользовательского состояния, к которым можно отнести любой процесс на AS/ 400. Использование заблокированных команд и доступ, таким образом, к некоторым объектам системы разрешены только в системном состоянии. Для большей надежности защиты в V1R3 была также устранена адресация на базе возможностей, а из системных указателей, предоставляемых пользователям, убраны все права доступа.Защита C2 (уровень 50)
Уровень 40 обеспечивает системе достаточную степень защищенности в большинстве случаев. Однако, некоторым фирмам, выполняющим государственные заказы, необходим уровень защиты, сертифицированный правительством США. Таких сертификатов несколько, включая, так называемый, уровень С2. Они включают такие положения, как защита ресурсов пользователя от других пользователей и предотвращение захвата одним пользователем всех системных ресурсов, например, памяти. Кстати, подобные требования сейчас применяются и во многих неправительственных организациях. Для заказчиков, нуждающихся в правительственных сертификатах, мы дополнили уровень защиты 40 на AS/400 до соответствия упомянутому уровню С2. Так в версии V2R3 появилась защита уровня 50. Но прежде чем система будет признана соответствующей стандарту С2, она должна пройти всеобъемлющую проверку. В настоящее время такая проверка идет. Уровень 50 включает все возможности защиты уровня 40, хотя некоторые интерфейсы были изменены под государственный стандарт. Кроме того, добавлена возможность аудита. Министерство обороны США определяет уровень защиты класса С2, как обеспечивающий «селективную защиту и, путем включения возможностей аудита, ответственность субъектов за их действия»[ 56 ]. Иначе говоря, при этом уровне защиты владелец ресурса вычислительной системы должен иметь право решать, кому предоставить доступ к данному ресурсу. Нужно также, чтобы система «помнила», кто и когда обращался к ресурсу. Средства аудита, задаваемые системным параметром QAUDJRL, позволяют администратору анализировать собранную информацию. Правительством США определены уровни защиты от А до D, где А — наивысший уровень защиты, а D — самый низкий. Классы B и С имеют несколько подуровней. Уровень защиты С2 — уровень, наивысший из обычно используемых в бизнесе. В будущем, если возникнет такая необходимость, мы сможем включить в AS/400 поддержку и более высоких уровней защиты.Профили пользователей
Профиль пользователя это и объект OS/400, и системный объект MI, служащий для идентификации пользователя в системе. Профиль должен быть у каждого пользователя, хотя и не обязательно уникальный: как мы скоро увидим, профили могут быть разделяемыми. Даже при отключенной защите (уровень 10), если у пользователя нет профиля, то система его создаст. Профили пользователя содержат информацию относящуюся к защите, они применяются и компонентами защиты OS/400, и компонентами контроля за доступом SLIC. Упомянутые компоненты управляют использованием объектов, ресурсов, некоторых команд и атрибутов машины. Профиль пользователя определяет следующие параметры: класс пользователя — категорию, в зависимости от принадлежности к которой пользователь имеет особые права; принадлежащие и доступные объекты — список объектов, которыми пользователь владеет и к которым имеет доступ; права на объекты — права доступа к объектам из вышеуказанного списка; привилегированные команды и специальные права — информация о всех привилегированных командах и специальных правах пользователя; пароль — код, обязательный для входа в систему при всех уровнях защиты, кроме 10; текущая библиотека — место, куда по умолчанию помещается новый объект, созданный пользователем; начальная программа и меню — поле, задающее программу и меню, активизируемые сразу после входа пользователя в систему; ограничение возможностей — параметр, запрещающий пользователю ввод команд и ограничивающий его возможности выбором пунктов меню; ограничение сессий для устройства — параметр, ограничивающий устройство пользователя одной сессией; максимальный объем памяти — поле, задающее общий объем дискового пространства для объектов, которыми владеет пользователь; максимальный приоритет — поле, задающее максимальный приоритет планировщика, который может применяться пользователем (более подробно будет обсуждаться в главе 9); специальная среда — поле, задающее среду, в которой будет работать пользователь (например, System/36). Назначение большинства приведенных атрибутов очевидно, но первые четыре требуют некоторых пояснений.Класс пользователя
Какой именно уровень доступа к системе разрешен пользователю, определяют пять классов пользователей. От класса зависит, какие функции пользователь может выполнять, какие пункты меню и привилегированные команды ему доступны. Перечислим все пять классов, начиная с максимального уровня доступа: начальник защиты — наивысший уровень пользователя системы; его обладатель выполняет все операции, связанные с защитой, включая разграничение других пользователей на классы; администратор защиты отвечает за регистрацию пользователей и защиту системных ресурсов; системный программист разрабатывает приложения для системы; системный оператор выполняет функции обслуживания системы, например резервное копирование; пользователь рабочей станции — пользователь прикладных программ, имеющий минимальный доступ к системе. В новой AS/400 для каждого класса пользователей имеется по одному профилю. Заказчик сам решает, кто в его организации будет отвечать за каждой из участков работы. Очевидно, что один и тот же человек может совмещать несколько обязанностей.Объекты, принадлежащие и доступные
Профиль пользователя содержит два списка. Первый — список всех объектов, которыми владеет данный пользователь, а второй — список объектов, к которым он имеет доступ. Владелец объекта — это пользователь, создавший его. Если профиль пользователя — член профиля группы (подробно будет обсуждаться далее), то в профиле может быть задано, что все созданные пользователем объекты принадлежат группе. Право владения объектом может передаваться. Владелец объекта или любой пользователь, имеющий права на управление этим объектом, может назначать явные (private) права доступа к объекту, а также установить общие (public) права на объект. В профиле пользователя перечислены только принадлежащие ему объекты и объекты со специальными правами.Права доступа к объектам
К каждому объекту AS/400 может быть предоставлено восемь видов доступа, а именно: •право на оперирование объектом разрешает просматривать описание объекта и использовать объект соответственно имеющимся у пользователя правам[ 57 ]; право на управление объектом разрешает определять защиту объекта, перемещать или переименовывать его, а также добавлять (но не удалять!) разделы в файлы баз данных; право определять существование объекта разрешает удалять объект, освобождать его память, выполнять операции сохранения/восстановления и передавать право на владение объектом; право на управление списком прав разрешает добавлять, удалять и изменять права пользователей в списках прав к объекту; право на чтение разрешает доступ к объекту; право на добавление разрешает добавлять записи к объекту; право на удаление разрешает удалять записи из объекта; право на обновление разрешает изменять записи объекта. Эти восемь прав объединены OS/400 в четыре комбинации, чтобы их было легче применять. Конечные пользователи могут использовать и другие сочетания, но большинство все же предпочитает следующие стандартные комбинации: «все» (all) — объединяет все восемь прав; «изменение» (change) — объединяет права на оперирование объектом, чтение, добавление, удаление и обновление; «использование» (use) — объединяет права на оперирование объектом и чтение; «исключение» (exclude) — не дает никаких прав на использование объекта; перекрывает наличие общих или групповых в связи с порядком проверки прав доступа (рассматривается далее).Привилегированные команды и специальные права
Каждый профиль пользователя содержит информацию о привилегированных командах и специальных правах пользователя. Некоторые привилегированные команды MI могут выполняться только теми пользователями, профили которых разрешают это делать. Например, профиль для начальника защиты создается с возможностью исполнять команду «PWRDWNSYS» (Power Down System), останавливающую работу машины. По очевидным причинам эта привилегированная команда не доступна обычным пользователям. Также есть набор специальных прав, которые могут быть предоставлены лишь избранным пользователям. Эти специальные права связаны с такими операциями, как подвешивание объектов, управление процессами, выполнение операций загрузки/дампа и использование низкоуровневых сервисных средств. Хотя все привилегированные команды и специальные атрибуты могут быть заданы в профиле пользователя по отдельности, OS/400 объединяет команды и права в шесть групп специальных прав: «все объекты» — разрешает доступ к любому системному ресурсу, независимо от того, оговорены ли особо права пользователя на такой доступ; «администратор защиты» — разрешает создание и изменение профилей пользователя; «сохранение системы» — разрешает сохранять, восстанавливать и освобождать память для любого объекта в системе, независимо от того, имеет ли пользователь право определять существование этого объекта; «управление заданиями» — разрешает изменять, отображать, задерживать, возобновлять, отменять и удалять все задания, которые исполняются в системе, а также находятся в очередях заданий или в выходных очередях; « обслуживание» — разрешает выполнять сервисные операции отображения/изменения/дампа. «управление спулом» — разрешает удалять, отображать, задерживать и отпускать спул-файлы, владельцами которых являются другие пользователи. Профиль пользователя — это сердце системы защиты AS/400. Он управляет доступом практически ко всем ресурсам системы. Но даже если профиль пользователя не дает последнему прав на некоторый объект или ресурс системы, такие права можно получить иными способами. Далее мы рассмотрим два способа получения дополнительных прав: заимствование прав программой и права группы.Заимствование прав программой
Во время исполнения программы профиль пользователя — владельца программы может служить дополнительным источником прав. Возможность заимствования прав позволяет программе выполнять операции, требующие полномочий, которыми пользователь непосредственно не обладает. Вместо того, чтобы предоставлять дополнительные права пользователю, пользовательская прикладная программа вызывает другую программу, владелец которой имеет соответствующие права. Таким образом, заимствование прав программой требует использования концепции стека вызовов. Такое заимствование всегда аддитивно и никогда не уменьшает прав доступа. Заимствование — атрибут программы, задаваемый при ее создании. Если вызываемая программа допускает заимствование прав, то любая вызывающая программа может использовать права владельца во время выполнения вызываемой программы. Программы, работающие в системном состоянии, могут сами задать запрет на заимствование. Программа может также запретить дальнейшее распространение прав. Это означает, что вызывающая программа будет заимствовать права, но эти права не сохранятся для программ, расположенных дальше по цепи вызовов. Ранее мы рассматривали только случаи, когда один пользователь имеет права на один объект. Однако, иногда нужно предоставить одинаковые права группе пользователей, или права на группу объектов.Группирование прав
На AS/400 есть три метода группирования прав. Списки прав и профили групп упрощают администрирование защиты, устраняют необходимость индивидуального подхода к пользователям или объектам. Держатели прав (authority holders) были введены IBM еще в среде System/36. Список прав позволяет назначать права на множество объектов нескольким пользователям. Кроме того, каждый пользователь может иметь различные права доступа ко всем объектам в списке. Список прав с тремя пользователями и тремя объектами показан на рисунке 7.1. Каждый из трех пользователей имеет права на все три объекта в списке; но во всех случаях — разные. Для добавления, удаления или изменения пользователей и их прав в списке требуется право на управление списком прав, описанное выше. На уровне MI список прав реализован как системный объект. Профили групп дают пользователям возможность применять общий профиль в дополнение к своим собственным. Пользователи — члены группы (например, сотрудники отдела предприятия) могут работать с общими объектами. Управление правами доступа всех членов группы может выполняться посредством профиля группы. Рисунок 7.1. Пример списка прав
Рисунок 7.1. Пример списка прав
Доступ к профилю группы осуществляется через профили отдельных пользователей. Если профиль пользователя дает ему права на объект, то эти явные права переопределяют права группы. Это позволяет предоставлять отдельным членам группы меньшие или большие права по сравнению с остальными. Профиль пользователя может быть членом до 16 профилей групп. Одна из таких групп может быть назначена первичной, что позволяет ускорить алгоритм поиска прав. Право первичной группы на объект хранится в самом объекте, тогда как права других групп — в профилях этих групп. При использовании первичной группы производительность повышена, так как алгоритму поиска не приходится обращаться к профилю группы — достаточно лишь информации в объекте. Приложения System/36 могут предоставлять пользователям заранее заданные права на еще несуществующие, не созданные файлы. Приложение System/36 может даже продолжать обладать правами на удаленный файл. В System/38 такой возможности нет. Права не могут быть предоставлены, пока объект не создан, а при удалении объекта вся информация о правах на него также удаляется из системы. Для поддержки прав доступа к несуществующим файлам в среде System/36 на AS/ 400 были добавлены держатели прав, нужные только для миграции. Их использование ограничено несколькими типами программно-описанных файлов; для других типов файлов и объектов держатели прав не поддерживаются. В связи с этим, ни в MI, ни в OS/400 нет объекта типа «держатель прав».
Алгоритм поиска прав
Теперь, когда мы определили все типы прав и различные способы, которыми пользователь может их получить, рассмотрим алгоритм поиска и попытаемся понять, как фактически происходит предоставление прав. Поиск прав всегда осуществляется в строго определенном порядке, что дает возможность регулировать объем прав пользователя по сравнению общими правами, правами профиля группы или правами списка прав. Алгоритм поиска прав выполняется SLIC при первом обращении пользователя к объекту. Это часть операции разрешения указателя, рассмотренной в главе 5. Работа алгоритма останавливается при обнаружении запрошенных прав на объект. Если информации о правах не найдено, доступ не предоставляется.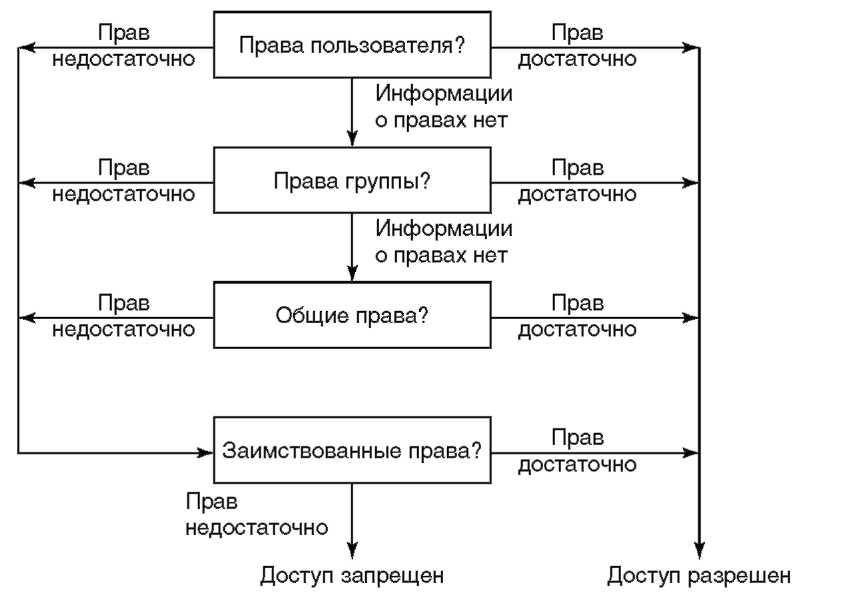 Рисунок 7.2. Алгоритм поиска прав
Рисунок 7.2. Алгоритм поиска прав
Последовательность алгоритма поиска запрошенных прав показана на рисунке 7.2. Предположим, что мы запрашиваем право на изменение (change) для некоторого объекта в системе. Порядок поиска таков[ 58 ]: 1.В индивидуальном профиле пользователя ведется поиск: специального права на все объекты, или права на объект (владельца и явного), или права из списка, если объект присутствует в этом списке (явного права). Доступ к объекту разрешен, если данный пользователь имеет специальное право на все объекты или, по крайней мере, право на изменение (change) для объекта в профиле пользователя (право владельца или явное право на объект) или в списке прав. Если найденное право меньше, чем право на изменение (change) — например, «использование» (use) или «исключение» (exclude), — то алгоритм переходит к поиску заимствованного права. Если право не обнаружено, то проверяются профили групп. 2.В профиле группы ведется поиск: специального права на все объекты, или права первичной группы, или права на объект для других групп (явного права), или права из списка, если объект присутствует в этом списке (явного права). Доступ к объекту разрешен, если группа имеет специальное право на все объекты или, по крайней мере, право на изменение (change) для объекта в первичной группе, других группах или в списке прав. Если найденное право меньше, чем право на изменение (change) — например, «использование» (use) или «исключение» (exclude), — то алгоритм переходит к поиску заимствованного права. Если право не обнаружено, то проверяются общие права. 3.В общих правах ведется поиск: специального права на все объекты, или права из списка, если объект присутствует в этом списке (явного права). Доступ к объекту разрешен, если имеется, по крайней мере, общее право на изменение (change) либо в объекте, либо в списке прав. Если найденное право меньше, чем право на изменение (change) — например, «использование» (use) или «исключение» (exclude), — то алгоритм переходит к поиску заимствованного права. 4.В заимствованном профиле ведется поиск. Доступ к объекту разрешен, если в заимствованном профиле пользователя имеется, по крайней мере, право на изменение (change). В противном случае доступ запрещается. Так как индивидуальный профиль пользователя просматривается первым и всегда выбирается первое встретившееся право на объект, пользователю могут быть предоставлены большие или меньшие права на объект по сравнению с общими правами и правами профиля группы. Если поместить право на исключение (exclude) в профиль индивидуального пользователя, а право на изменение (change) в заимствованный профиль, то доступ к объекту данному пользователю будет заблокирован. Однако, пользователь по-прежнему сможет выполнять над объектом операции изменения с помощью заимствованных прав, приобретаемых при выполнении соответствующей программы. Такой способ наиболее распространен для ограничения доступа к системному объекту. Для ускорения алгоритма поиска при проверке прав используются две быстрых ветви. Обе этих ветви производят быструю проверку на основе информации, хранящейся в объекте. Если быстрая проверка дает положительный результат, то серия проверок, требуемых полным алгоритмом, не нужна и выполнение запрошенной операции разрешается. В противном случае выполняется обычный алгоритм поиска.
Дополнительная защита в сетевом мире
Давайте кратко рассмотрим вопросы защиты, возникающие при подключении к AS/400 любой незащищенной системы, будь это ПК на ЛВС или другой компьютер через Интернет (подробнее о переходе к сетевым вычислениям и связанными с этим изменениями в AS/400 — в главе 11). Надеюсь, это поможет Вам лучше использовать защиту AS/400 для сохранения своих информационных ресурсов. Мы начнем с рассмотрения клиент/серверных приложений и подключения ПК к AS/400.Подключение ПК к AS/400
Многие организации и фирмы используют клиент/серверные приложения, или собственные, или приобретенные у ISV. Часто при этом ПК подключаются к AS/400 через ЛВС, а приложение разбивается между ПК и AS/400. Очень часто пользователи полагают, что в подобных клиент/серверных средах их данные на AS/400 защищены от несанкционированного доступа. К сожалению, это не всегда так. Защита данных зависит от того, как написано приложение и как защищена система. Той части клиент/серверного приложения, которая работает на ПК, необходим способ доступа к базе данных AS/400. Обычно, для этого используется доступ на уровне файлов. Весьма распространенный подход при этом — использование интерфейсов ODBC (Open Database Connectivity). Но если на ПК исполняется приложение ODBC, то на AS/400 дополнительное приложение не нужно. Следовательно, невозможно использовать для защиты файлов базы данных такие средства, как заимствование прав программой. Вместо этого программа на ПК получает непосредственный доступ к файлам базы данных посредством общих, групповых или явных прав. Но вот проблема: как быть, если конечный пользователь ПК не должен иметь полного доступа к базе данных? Ограничение доступа пользователя возлагается на приложение ПК, где оно, обычно, не работает и в системе защиты возникает брешь. ПК, как и многие другие, подключенные к AS/400, системы, никак не защищены. И я утверждаю, что нельзя полагаться ни на какой код, предназначенный для ограничения доступа к AS/400, если он выполняется на незащищенной системе. Вот что я имею в виду. Например, любое ПО на ПК, включая ПО ОС Windows 95 и Windows NT Workstation, может быть легко изменено достаточно компетентным пользователем, после чего будет работать не так, как изначально предполагалось. Это означает, что ни одна прикладная программа на ПК не может обеспечить какой-либо серьезной защиты данных на AS/400, да и данных на самом ПК. Выход из описанной ситуации очень прост. Просто запретите всякий доступ к файлам базы данных и заставьте приложение ODBC вызывать на AS/400 описанную в главе 6 хранимую процедуру, которая заимствует права на операции с файлами. Имеются также и другие приемы, позволяющие контролировать кто, и что делает с помощью ODBC. ODBC не единственный потенциально опасный (с точки зрения защиты информации) интерфейс, который можно использовать для работы с AS/400. TCP/IP FTP (File Transfer Protocol), передача файлов с помощью Client Access и DDM — вот лишь несколько примеров удаленных интерфейсов к AS/400, использование которых может вызывать те же проблемы защиты. Многие клиент/серверные приложения, включая написанные ISV, создаются без должной защиты данных. Ключевой момент защиты данных AS/400 — обеспечить, чтобы любой код, отвечающий за контроль доступа, выполнялся на защищенной системе. Для пользователей AS/400 это обычно означает установку защиты, предусматривающей, по меньшей мере, защиту ресурсов (уровень 30), а также осторожность при разработке или приобретении клиент/серверных приложений. В последнее время многие клиенты AS/400 стали подумывать об использовании вместо ПК СК (сетевых компьютеров; подробно мы рассмотрим их в главе 11). СК обладает многими преимуществами ПК, может похвастаться отсутствием некоторых потенциальных проблем последнего, да и дешевле. СК также обеспечивает лучшую защищенность.Вирусы, черви, троянские кони и другие мерзкие твари
Вирусы настолько распространены, что сегодня серьезный бизнес может опираться на ПК только при использовании какого-либо антивирусного ПО. Новые вирусы создаются каждый день, поэтому и программы проверки должны постоянно обновляться. Вирусам подвержены системы Unix и даже мэйнфреймы, что связано с наличием в них определенных возможностей системного программирования. Ведь чтобы заразить систему, код вируса должен присоединиться к некоторому исполняемому коду на двоичном машинном уровне. Так как в AS/400 видима лишь незначительная часть внутренних компонентов, внедрение вируса в нее маловероятно. И все же, это может произойти, если система не защищена надлежащим образом. Наилучший способ предохранения от вирусов на AS/400 — защита объектов-программ и команд. Например, пользователь может изменить команду с помощью команды «CHGCMD» (Change Command) только в том случае, если у него есть право управлять объектами. Дополнительную страховку обеспечивает команда «RVKOBJAUT» (Revoke Object Authority): с ее помощью Выможете отозвать, или, по крайней мере, отследить, чрезмерный доступ к командам, в том числе и к самой команде «CHGCMD». Кроме того, в AS/400 хакер может использовать для модификации или создания исполняемых программ лишь несколько средств и команд. Следовательно, доступ к ним нужно ограничить. Таким образом, если устранить возможность несанкционированного создания программ и изменения объектов-программ, то возможность внедрения вируса равна нулю. Средства аудита, отслеживая, кто именно использует такие изменяющие программы команды, не позволяют злоумышленнику остаться необнаруженным. Черви похожи на вирусы, но в отличие от них не заражают другие программы. Вместо этого, червь постоянно дублируется и оттягивает на себя системные ресурсы. Например, программа-червь для AS/400 могла бы постоянно посылать себя на выполнение как новое задание. Это не вызовет повреждений, но может сильно снизить общую производительность системы. Чтобы предотвратить такую узурпацию большей части ресурсов, следует ограничить доступ к командам, изменяющим задание или его класс, и установить лимиты очереди заданий для ограничения числа параллельно исполняющихся заданий (задания, очереди заданий и классы мы рассмотрим в главе 9). С этой целью IBM изменила в V3R7 установку по умолчанию общего права на большинство таких команд с «использование» (use) на «исключение» (exclude). Общее право на многие описания заданий также было переназначено с «изменение» (change) или «использование» (use) на «исключение» (exclude). Компьютерные троянские кони пытаются пробраться в Вашу систему незаметно, подобно античным грекам, вошедшим в Трою, скрыв своих солдат в огромном подарке — деревянном коне. Обычно, имя «троянской» программы совпадает с именем «хорошей» программы. Пользователь может поместить «троянского коня» в такое место системы, что при ее выполнении он получит более высокий уровень прав, чем имеет при исполнении «законной» программы. Проще всего поместить «троянскую» программу в библиотеку. В главе 5 мы говорили, что система просматривает библиотеки в списке одну за другой, пока не будет найден нужный объект. Если кто-то поместит «троянскую» программу в библиотеку, предшествующую библиотеке, содержащей «хорошую» программу с тем же именем, то «троянская» программа будет найдена первой и ее автор сможет (потенциально) получить более высокую степень доступа к системе. В качестве примера рассмотрим предоставляемую IBM библиотеку QUSRSYS, которая поставляется вместе с системой. Допустим, QUSRSYS имеет общее право доступа «изменение» (change). Эта библиотека просматривается системой перед просмотром других пользовательских библиотек в списке задания. Обращение к пользовательской библиотеке вызвало бы одноименную «троянскую» программу, предварительно помещенную хакером в QUSRSYS. Обратите внимание, на слово «допустим», с которого начинается вторая фраза этого абзаца. Именно для страховки от «троянских коней» с версии V3R7 QUSRSYS и другие библиотеки IBM поставляются с общим правом «использование» (use). Тогда же и с той же целью —.повысить защищенность системы и затруднить несанкционированный доступ к системным ресурсам — в специальные права для различных классов пользователей были внесены и другие изменения. В отличие от ПК и систем Unix средства для защиты AS/400 от тварей, которых мы только что рассмотрели, уже присутствуют в самой системе. Как я уже сказал, в последних версиях были изменены значения параметров по умолчанию, что делает защиту системы еще надежней. И все же пользователь по-прежнему должен предпринять определенные действия по активизации всех этих форм защиты. Немного предусмотрительности — и Ваша AS/400 станет абсолютно непроницаемой для вирусов и прочей нечисти!Безопасный сервер WWW
По мере того, как все больше компаний подключают свои AS/400 к WWW (World Wide Web), вопрос сетевой защиты серьезно обостряется. Многие только что рассмотренные нами приемы защиты AS/400 в клиент/серверной среде применимы также и при подключении ее к открытым сетям любого рода. Но Интернет стоит особо. Прежде чем мы займемся вопросами защиты, не помешает краткий исторический экскурс в поддержку Интернета на AS/400. В состав Internet Connection, появившегося в начале 1996 в составе OS/400, входят сервер WWW, шлюз 5250-в-НТМL[ 59 ] (Hypertext Markup Language) и средства работы с базами данных из HTML. Сервер WWW получил название Internet Connection Server: он взаимодействует с пользователями WWW посредством протокола HTTP (Hypertext Transport Protocol). Шлюз HTML «на лету» преобразует поток данных 5250 в HTML, что позволяет приложениям 5250 работать в Интернете. Средства HTML для баз данных создают запросы для DB2/400 с помощью HTML и SQL. Эти расширения, добавленные в последующие версии, превратили AS/400 в полноценный сервер Интернета. HTML задает формат потока данных между сервером WWW и средством просмотра на компьютерах, подключенных к сети. HTML не язык программирования; это мощный язык описания страниц, подобный PostScript. Его основой послужил полиграфический язык SGML (Standard Generalized Markup Language), описывающий взаиморасположение текста и графики на экране. Браузер на пользовательской машине передает на сервер запрос в форме URL (universal resource locator). Запрос URL имеет вид «http://имя-сервера/имя-документа-HTML». HTTP — это просто транспортный протокол, использующий соединение TCP/IP между сервером WWW на AS/400 и пользователями WWW. Внешними связями могут быть выделенные линии или доступ TCP/IP по асинхронным телефонным линиям, известный как SLIP (Serial Link Internet Protocol). Имеется также поддержка протокола PPP (point-to-point protocol). Кроме сервера WWW, сетевые клиенты могут использовать для доступа к интегрированной файловой системе AS/400 протокол FTP (File Transfer Protocol). Поддержка «анонимного» пользователя обеспечивает доступ к системе любому сетевому пользователю. Пользователь WWW на сетевом компьютере может запросить у сервера на AS/400 исполнение программы CGI (Common Gateway Interface). CGI — это стандартный протокол сервера WWW, позволяющий серверным программам непосредственно взаимодействовать с браузером на сетевом компьютере. При запуске такая программа получает информацию из вызывающего документа HTML, имя пользователя, адрес TCP/ IP и любые заданные пользователем данные. С помощью команд SQL в HTML, пользователь также может непосредственно обращаться к DB2/400 из браузера. Программа CGI выполняет запрошенные операции, включая обращения к DB2/400, и генерирует текст HTML, который WWW-сервер на AS/400 возвращает браузеру. Для обеспечения защиты данных на AS/400 сервер WWW использует системные средства защиты. Набор новых профилей пользователя и некоторые другие параметры обеспечивают закрытость данных и предоставляют доступ только к тем файлам, для которых это разрешено. Обычно, сервер WWW AS/400 работает под управлением профиля пользователя QTMHHTTP. Используя этот профиль, сервер WWW работает в системном состоянии. Чтобы ограничить набор файлов, к которым имеет доступ сервер, и таким образом доступ пользователей WWW к файлам DB2/400, можно ограничить права доступа к объектам для профиля QTMHHTTP. Когда пользователь WWW запрашивает у сервера выполнение программы CGI, используется другой профиль. Сервер WWW переключается на профиль QTMHHTTP1, понижает состояние системы до пользовательского и не передает заимствованные права сервера программе CGI. Профиль пользователя QTMHHTTP1 не имеет никаких прав и может работать только с объектами, имеющими общие права. Так как пользователи Интернета обычно не зарегистрированы на AS/400, сервер WWW вообще не проверяет прав пользователей. Некоторые системы AS/400 могут требовать введения идентификатора и пароля для доступа к определенным страницам URL; однако, чаще всего страницы WWW открыты для всех пользователей Интернета. Следовательно, такой пользователь Интернета имеет доступ ко всему, к чему есть доступ у сервера WWW. Так что следует тщательно следить за назначением общих прав объектам системы. Например, если в некоторой библиотеке содержится важная информация, имеет смысл установить для нее общий доступ «исключение» (exclude) и разрешить доступ только в соответствии с явными или групповыми правами. Тогда у сервера WWW не будет доступа к такой библиотеке. Если Вы хотите назначить для библиотеки более высокий уровень общего доступа, рекомендуем вариант явного запрета на доступ к ней для QTMHHTTP и QTMHHTP1. Тогда она станет недоступной пользователям WWW. Сервер WWW может использовать библиотеки, на которые у него есть права, но не использует списки библиотек. Как обсуждалось ранее, использование списка библиотек дает возможность поместить «троянскую» программу перед библиотекой, содержащей «хорошую» программу. Не используя списки библиотек, мы устраняем эту возможность. Другой способ защиты системы — использование программ выхода (exit program). Так называется в AS/400 программа, написанная пользователем. Например, всякий раз, когда сетевой пользователь, пытается применить FTP для пересылки файла на или AS/400 с нее, перед началом операции с файлом вызывается программа выхода. Эта программа может запретить выполнение определенных операций в зависимости от профиля пользователя или файла, к которому производится обращение. Так же программы выхода могут запускаться при получении запроса на другие операции, такие как подключение пользователя к серверу. Программы выхода также могут применяться для ПК, подключенных удаленно, или при доступе к системе через шлюз HTML. Для коммерческой безопасности электронных операций по незащищенной сети, нужна защищенная пересылка данных и поддержка защищенных финансовых транзакций. В обоих случаях AS/400 использует стандартные сетевые протоколы: SSL (Secure Sockets Layer) — как средство защищенной пересылки (будет рассмотрен в главе 11); и SET (Secure Electronics Transaction) — для защиты финансовых транзакций. SET представляет собой протокол, определенный Visa/MasterCard для выполнения операций с кредитными картами по Интернету. Вдобавок, когда нужно, AS/400 предоставляет очень мощные аппаратные средства шифрования данных[ 60 ]. В завершение рассмотрения темы сетевой защиты рассмотрим брандмауэры. Брандмауэр — это отдельная от AS/400 система, используемая для защиты шлюза в Интернет. В нормальной ситуации и AS/400, и все другие компьютеры никогда не соединяются с Интернетом напрямую. Вместо этого все обращения сначала поступают к брандмауэру. Брандмауэры защищают частные сети от несанкционированного доступа, как внутреннего, так и внешнего. В соответствии с правилами защиты в данной организации, брандмауэр разрешает или запрещает доступ к ее защищенным компьютерам. Свое название брандмауэры получили потому, что они не дают огню (незащищенной сети) проникнуть в защищенную внутреннюю сеть (буквально: firewall — огнеупорная стена). В большинстве случаев брандмауэры реализуются на ПК либо на Unix. Так как их использование предполагает наличие отдельного компьютера и, соответственно администратора, это сильно не вписывалось в интегрированную сущность AS/400. Поэтому в V4R1 был реализован скрытый брандмауэр. Для этого защищенного сетевого шлюза мы использовали IPCS (Integrated PC Server). Использование IPCS и других скрытых машин приложений подробно рассматривается в главе 11, а сейчас скажем лишь, что IPCS — отличный брандмауэр, позволяющий избежать расходов на управления дополнительным компьютером. Наш брандмауэр находится в том же корпусе (физически), не находясь в нем логически.Выводы
Защита — одна из важнейших функций любой многопользовательской системы. По мере того, как все большее число компьютеров подключается к Интернету, необходимость защиты систем только возрастает. Компонент защиты OS/400 и компонент SLIC контроля за доступом к объектам составляют механизм, удовлетворяющий сегодняшним требованиям и, вместе с тем, достаточно гибкий для расширений в будущем. По мере ужесточения требований к защите, необходимые средства могут быть легко добавлены в AS/400. Кроме общей системной защиты AS/400, мы подробно обсудили общие способы управления правами пользователей, включая: доступ к меню; заимствованные права; групповые права; явные права. В процессе разрешения указателя выполняется алгоритм поиска прав. Но от прав доступа к объекту мало толку, если Вы не можете его адресовать. В следующей главе мы рассмотрим адресацию и управление одноуровневой памятью. Одноуровневая память, хотя обычно и не рассматривается как часть системы защиты, тем не менее, играет главную роль в защите пользователей и их данных.Глава 8
Одноуровневая память
Сегодня в компьютерной индустрии модны длинные адреса (в данном случае, «длинный» означает больше 32 разрядов). Практически все производители аппаратуры и ОС начали использовать их в своих продуктах, а в качестве стандарта для следующего поколения предусматривают 64 разряда. Переход на адреса большего размера стимулируется новыми приложениями, такими как хранилища данных, а также снижением цен на основную память. Заказчики отмечают значительное повышение производительности при использовании памяти большого размера, и размеры памяти, измеряемые гигабайтами, становятся обычным делом. 32-разрядный адрес, способный поддерживать размеры памяти только до 4 ГБ, быстро устаревает. Довольно долго процессоры AS/400 и их предшественники — процессоры System/38 — использовали 48-разрядные адреса. С переходом на RISC-процессоры размер адреса возрос до 64 разрядов. Одноуровневая память с большими адресами — вероятно, один из самых известных компонентов AS/400, и редко какая презентация обходится без упоминания о ней. Это даже странно — ведь одноуровневая память не видима никому и ничему выше уровня MI: ни OS/400, ни прикладным программам, ни даже компиляторам. Она доступна только SLIC, а MI работает с объектами, используя для ссылок на них имена. Пространство — эквивалент памяти на уровне MI, но пространство не очень напоминает одноуровневую память. Программы, и прикладные, и системные адресуют объекты при помощи 16-байтовых указателей; которые точнее было бы называть 128-разрядными (их используют все прикладные программы с момента появления System/38 в 1978 году). Но не все разряды: этого указателя используются, поэтому AS/400 обычно не называют 128-разрядным компьютером. Указатель содержит 64-разрядный адрес одноуровневой памяти, а также несколько разрядов дескриптора и неиспользуемые разряды, зарезервированные для будущих расширений. Возможно, нам следует называть AS/400 128-разрядной системой — согласитесь, это было бы неплохой рекламой. Ведь называет же Digital свой процессор Alpha 64-разрядным, хотя он реализует лишь 41-разрядные адреса! HP также не использует для адреса все 64 разряда в своем процессоре PA RISC 2.0. И все же, я полагаю, мы лучше будем пока говорить о 64 разрядах — по крайней мере, до тех пор, пока до уровня IBM не подтянутся остальные. Кроме того, 64 разряда уже и так дают очень большое адресное пространство. «Но насколько большое?» — спросите Вы.Сколько байтов адресуют 64 разряда
Ответ: 16 экзабайтов, что равно примерно 18,4 квинтиллионам байтов (или точнее 18 446 744 073 709 551 616 байтов). Большинство людей не в состоянии представить себе такое число. Как я уже упоминал, число байтов, которые могут быть адресованы с помощью 48 разрядов, примерно равно числу миллиметров расстояния от Земли до Солнца и обратно. Но для 64 разрядов нужна новая аналогия. Ричард Рубин, чьи замечания чрезвычайно помогли в работе над этой книгой, напомнил мне историю, рассказанную Джорджем Гамовым (George Gamow) в книге «One, Two, Three, Infinity». Однажды индийский шах Ширхам пожелал вознаградить своего великого визиря Сисса Бен Дахира за изобретение шахмат. Визирь попросил шаха положить на первую клетку шахматной доски одно зерно пшеницы, на вторую — два, на третью — четыре, на четвертую — восемь и так далее, удваивая число на каждой клетке, пока все 64 клетки не будут заполнены. Общее число зерен должно было бы составить 264 — 1. Гамов подсчитал, что если бушель[ 61 ] пшеницы содержит 5 миллионов зерен, то для покрытия всей доски потребовалось бы 4 триллиона бушелей. Когда Гамов писал свою книгу в 1946 году, мировое производство пшеницы составляло 2 миллиарда бушелей в год. При сохранении производства на том же уровне, всему миру потребовалось бы две тысячи лет, чтобы вырастить требуемое количество зерен. Для тех, кто предпочитает аналогию с миллиметрами, 18 квинтиллионов — это примерно вдвое больше числа миллиметров в световом годе, и всего лишь немногим меньше половины расстояния до Альфы Центавра (ближайшей к Солнечной системе звезде). Ясно, что если мы начнем измерять астрономические расстояния в миллиметрах, то нам потребуется более 64 разрядов. А 128-разрядный указатель дает нам... Так что какие бы аналогии мы не проводили, и как бы себе все это не представляли, 64-разрядная адресация предоставляет огромные возможности.Виртуальная память
Одноуровневая память AS/400 получила свое имя в честь первопроходцев разработки виртуальной памяти в 60-х годах. Чтобы понять происхождение этого термина, необходимо углубиться в историю. Впервые виртуальная память появилась в компьютере Atlas, созданном в 1961 в английском городе Манчестере (Manchester). В те годы для изготовления памяти использовалась очень дорогостоящая технология магнитных сердечников. Большим программам требовалось много памяти, зачастую больше, чем было на компьютере. Чтобы программа могла поместиться в памяти, приходилось разбивать ее на малые фрагменты и хранить на магнитных дисках или барабанах. Магнитные барабаны были популярны в начале 60-х годов. Барабан похож на жесткий диск, но у него по одной головке чтения/записи на каждую дорожку. В то время барабаны обеспечивали более высокую производительность по сравнению с дисками, так как исключалось время позиционирования головки на дорожку. С сокращением времени позиционирования барабаны вышли из употребления. При разбиении больших программ на малые фрагменты управление памятью требовало от программиста больших усилий. Если фрагмент программы, который должен был исполняться, находился вне памяти, то программист вставлял команды считывания этого фрагмента в память с диска или барабана. Фрагменты программы назывались оверлеями (overlays), и значительная часть программирования заключалась в создании и управлении ими. Виртуальная память смогла устранить эту проблему. Память увеличилась, и программисты могли больше не беспокоиться о том, поместится ли в нее программа. Управление перемещением данных и программ в большой виртуальной памяти взяла на себя ОС. В 1962 году Т. Д. Килбурн (T.D. Kilburn) с соавторами написал свою статью, посвященную системе памяти компьютера Atlas. В статье были такие слова: «. Система представляет программисту комбинацию память-барабан в виде одноуровневой памяти. Необходимое перемещение данных выполняется автоматически»[ 62 ].Виртуальная память для систем разделения времени
В связи с появлением в конце 60-х годов систем разделения времени — раннего этапа эволюции мультипрограммных ОС — многие производители компьютеров приняли виртуальную память на вооружение. При мультипрограммировании системная память разделена на несколько порций, в каждой из которых находится некоторая программа. Пока одна из программ ожидает завершения операции ввода-вывода, другая может использовать процессор. Если в памяти находится достаточное количество программ, то можно обеспечить постоянную загруженность процессора. Мультипрограммные ОС занимались тогда преимущественно пакетной обработкой. Разделение времени — это разновидность мультипрограммирования, когда у каждого пользователя есть подключенный к компьютеру терминал. Так как при этом пользователи интерактивны (то есть программа управляется командами пользователя за терминалом), то на «раздумья» пользователей уходит какое-то время. Соответственно снижается загрузка процессора. Компьютер такого типа поддерживает больше пользователей, так что в памяти одновременно находится довольно много фрагментов программ. Интерактивным пользователям требуется быстрое время отклика, так что эффективное управление множеством фрагментов программ критически важно. Именно его и должна была обеспечить виртуальная память. В основе систем разделения времени лежала возможность аренды времени центрального компьютера отдельными пользователями из разных организаций. Такой подход был популярен, так как большинство малых фирм не могли позволить себе собственный компьютер. Разделение времени предоставляло им ресурсы большого компьютера за часть цены. Так как пользователи компьютера представляли разные организации, совместное использование информации ими не требовалось. Поддерживая разделение времени, системы виртуальной памяти предоставляли каждому пользователю отдельное адресное пространство. Адресные пространства разных пользователей были изолированы друг от друга, что в определенной степени обеспечивало защиту. При переключении ресурсов компьютера на выполнение программы другого пользователя использовалось новое адресное пространство. Такая операция называлась переключением процессов, где процесс рассматривался как единица работы в системе, выполняемая для пользователя. В прошлом переключение процессов было связано с большими накладными расходами. Нужно было изменить таблицы памяти, очистить регистры и загрузить новые данные. Выполнение всех этих действий требовало большого числа команд процессора, и явно чрезмерных затрат времени. Тогда, в конце 60-х, многие искали способы упростить эту операцию и повысить ее эффективность[ 63 ]. К сожалению, разработчики систем разделения времени решили вынести файловую систему за пределы виртуальной памяти. Они создали два места хранения данных и программ: виртуальную память и файловую систему. В подобной архитектуре данные и программы могут использоваться или изменяться, только если находятся в виртуальной памяти. То есть, прежде чем что-либо сделать, данные и программы нужно переместить в виртуальную память. Менеджер файлов обычной системы поддерживает каталог, связывающий имена файлов с местоположением на диске данных, которые в них содержатся. Менеджер файлов предоставляет некий интерфейс, позволяющий программе открыть файл. Затем данные копируются в буферы памяти, обычно являющиеся частью виртуальной памяти. После этого данные могут использоваться и обрабатываться. Когда программа завершает работу с данными, выполняется операция закрытия, переносящая данные из виртуальной памяти обратно в файловую систему. Простой и знакомый большинству из нас пример подобного механизма — использование текстового процессора на ПК. Сначала пользователь открывает файл, содержащий нужный документ, а затем наблюдает мигание индикатора жесткого диска, пока документ считывается в память. На самом деле, документ сначала переносится в виртуальную память, а затем частично — в реальную память. Когда-то раньше, при конфигурировании ОС нашего ПК, мы определяли размер места на жестком диске, зарезервированный для виртуальной памяти. В мире ПК это пространство иногда называется файлом подкачки. Прокручивая текст на экране, пользователь снова видит, как мигает индикатор жесткого диска. По мере необходимости, новые фрагменты документа считываются в память из зарезервированного пространства на диске. Операция открытия файла создает копию документа. Оригинал же по-прежнему находится на жестком диске в неизменном виде. Копия располагается в дисковом пространстве, зарезервированном под виртуальную память. Менеджер виртуальной памяти и ОС автоматически переносят фрагменты документа по мере необходимости из зарезервированной дисковой области в память, а когда надобность в них отпадает — возвращают обратно. Фактически, если учесть копию в памяти, некоторые фрагменты документа существуют в трех копиях. Когда пользователь заканчивает редактирование и сохраняет документ, текстовый процессор запрашивает, сохранить ли изменения. Другими словами, нужно ли записать обновленную в виртуальной памяти копию обратно в файл на диске для постоянного хранения. Если ответ утвердительный, то копия из виртуальной памяти замещает копию на диске.Одноуровневая виртуальная память
В только что описанной реализации виртуальной памяти программист имеет дело с двумя уровнями хранилища: файловая система и виртуальная память разделены. Двухуровневая система хранения вызывает дополнительные накладные расходы. Открытие файла связано с записью на диск в файлы подкачки, а закрытие — требует записи обратно на место постоянного хранения. Сам собой напрашивается альтернативный вариант — работать только с одной копией файла. Ведь если нет двух отдельных копий, то не нужно резервировать пространство на диске для файла подкачки. При таком подходе вся файловая система становится частью виртуальной памяти. Менеджер файлов по-прежнему ведет справочник, но теперь он связывает имя файла с местом в памяти, где находятся данные файла. При открытии и закрытии файла не требуется копировать весь файл из его постоянной области хранения на диске. В буфер памяти копируется только та порция (или запись) с которой пользователь в данный момент работает. Часто говорят и так: файлы всегда используются там же, где хранятся. Все это позволяет повысить общую производительность системы. Одноуровневая память — это именно то, что ставили своей целью создатели первой виртуальной памяти, и именно эта модель была реализована в System/38. В честь первооткрывателей мы решили назвать нашу виртуальную память одноуровневой памятью. И двухуровневая виртуальная память, и одноуровневая используются как буфер. Процессоры могут работать только с данными в памяти, но не на диске. Отличие одноуровневой схемы в том, что память в ней — кэш для всего дискового пространства, а не только для зарезервированной области диска. Кроме того, после изменения файла одним пользователем, это изменение немедленно становится видимым всем остальным, работающим с тем же файлом. Недостаток одноуровневой памяти — большой размер адреса. Адрес должен быть достаточно велик, чтобы покрывать все подключенное к системе дисковое пространство. Возьмем 32-разрядный адрес, используемый во многих современных системах. С его помощью можно адресовать до 4 ГБ, что совершенно недостаточно для адресации всего дискового пространства даже на большом ПК. Таким образом, обычные системы просто вынуждены копировать дисковые данные в свои относительно небольшие виртуальные памяти и обратно. Чтобы устранить это ограничение, в System/38 и первые модели AS/400 был включен 48-разрядный адрес. Теперь AS/400 использует 64-разрядный адрес и для будущих расширений предусмотрены дополнительные разряды адреса. Хоть все это и связано с аппаратными затратами, последние вполне компенсируются возможностями по совместному использованию данных и ростом производительности.Постоянная виртуальная память
Размер адреса AS/400 значительно превышает необходимый для покрытия всего дискового пространства. Причина такого положения — другая характеристика одноуровневой памяти, называемая постоянством (persistence). Мы уже говорили об этом в главе 5, посвященной объектам. Объект, обладающий постоянством, остается в памяти системы вечно, даже после своего разрушения, и виртуальное адресное пространство такого постоянного объекта никогда не используется повторно. При разрушении постоянного объекта освобождается все занятое им дисковое пространство, за исключением заголовков. Освобожденное дисковое пространство затем используется для других объектов. То, что виртуальное адресное пространство повторно не используется, устраняет многие проблемы защиты и целостности. Если постоянный объект разрушен и его адресное пространство использовано повторно другим объектом, то любой, у кого был разрешенный указатель на старый объект, сможет адресовать новый объект. Так как указатели могут храниться в памяти где угодно, то большинство схем «сборки мусора» для поиска указателей уничтоженных объектов слишком сложны. В AS/400 же применяется достаточно большой адрес и адресное пространство постоянных объектов повторно не используется. Так что «сборка мусора» в этой системе не нужна. Большинство обычных систем виртуальной памяти борются со «сборкой мусора» другим способом. В ранних схемах виртуальной памяти (по-прежнему используемых некоторыми ОС ПК), каждому пользователю выделяется отдельное виртуальное адресное пространство. Когда пользовательский процесс прекращает свое существование, то же происходит и с его виртуальной памятью. Сохранить адрес где-либо в системе нельзя. Единственное место разделения данных — файловая система, где виртуальная адресация не используется. Для большинства многопользовательских ОС, таких как Unix, подобная реализация неприемлема. Вместо того, чтобы предоставить пользовательской программе возможность прямой адресации виртуальной памяти, такие системы передают программе адрес, который перед использованием транслируется в виртуальный аппаратно. В архитектуре PowerPC такой адрес называется эффективным. Как мы увидим далее, эффективный адрес позволяет добиться некоторого уровня разделения памяти, но за счет больших накладных расходов. Виртуальная память в таких системах логически подразделяется на сегменты — блоки последовательных байтов памяти. Эффективный адрес задает один из таких сегментов. Обычно трансляция эффективного адреса в виртуальный использует несколько (от 4 до 16) регистров микросхемы процессора, которые называются сегментными регистрами. Каждый сегментный регистр содержит виртуальный адрес одного из сегментов памяти. Часть старших разрядов эффективного адреса задают один из сегментных регистров. Остальные же задают байт внутри сегмента (и называются смещением в сегменте). Так как эффективный адрес содержит смещение внутри сегмента виртуального адреса, то данный тип адресации иногда называется адресацией относительно сегмента. Проще всего представить себе эффективный адрес как подмножество виртуального адреса большего размера. Пользовательская программа может напрямую адресовать лишь несколько сегментов виртуальной памяти — те, чьи адреса загружены в сегментные регистры. Программа может запросить у ОС перезагрузку системных регистров, что позволит ей получить доступ к другим сегментам, но по-прежнему будет работать лишь с небольшой частью виртуальной памяти. Например, на некоторых процессорах Intel — лишь четыре сегментных регистра, что позволяет работать только с четырьмя сегментами одновременно, тогда как некоторые ранние процессоры RS/6000 использовали 16 таких регистров, но все равно могли адресовать лишь небольшую часть общей памяти. В архитектуре PowerPC мы избавились от сегментных регистров и заменили их специальной таблицей в памяти, так называемой таблицей сегментов. Это дает пользовательским программам доступ к гораздо большему числу сегментов, чем регистровая реализация. Каждая запись таблицы сегментов по-прежнему содержит виртуальный адрес одного из сегментов виртуальной памяти. Эффективный адрес, используемый программой, теперь задает запись таблицы сегментов и байтовое смещение в сегменте. Две программы могут использовать совместно один и тот же виртуальный адрес, если они обращаются к одной и той же записи в таблице сегментов, или если тот же самый виртуальный адрес хранится в нескольких записях таблицы. В случае адресации относительно сегмента, пользовательской программе виден только эффективный адрес, и таким образом, она не может сохранить где-либо виртуальный адрес. Трансляция эффективного адреса в виртуальный требует дополнительных накладных расходов, но зато виртуальные адреса защищены и не нужна «сборка мусора». Так как только ОС может изменять значения сегментных регистров, то в определенной степени контролируется, какие сегменты пользовательская программа может использовать и разделять с другими программами. Поскольку эффективный адрес содержит только идентификацию записи таблицы сегментов и смещение адреса, постольку эффективный адрес имеет меньше разрядов, чем виртуальный. Именно благодаря тому, что виртуальный адрес не ограничен размером регистров процессора, 32-разрядный процессор с 32-разрядным виртуальным адресом может поддерживать большее виртуальное адресное пространство. Но даже и в этом случае, эффективный адрес может адресовать лишь подмножество адресного пространства без перезагрузки ОС сегментных регистров. Кроме того, хотя виртуальный адрес может иметь длину более 32 разрядов, отдельная операция по-прежнему использует только 32 разряда адреса. Таким образом, ограничение в 4 ГБ по-прежнему сохраняется, независимо от того, сколько разрядов в виртуальном адресе. Это объясняет, почему даже системы, поддерживающие большие виртуальные адреса, переходят с 32- на 64-разрядные процессоры. Теперь сопоставим рассмотренную нами адресацию относительно сегмента с одноуровневой памятью AS/400. Одноуровневая память и виртуальные адреса располагаются ниже MI и не видны пользователю. Таким образом, для защиты адресов не требуется дополнительный уровень трансляции (эффективного адреса в виртуальный), она осуществляется с помощью указателей. Защищая указатели (с помощью разрядов тега), не надо идти на дополнительные накладные расходы, связанные с загрузкой и сохранением таблиц сегментов для каждой программы. Как уже упоминалось при обсуждении структуры объектов, в AS/400 одноуровневая память также разделена на сегменты. Важно то, что при использовании одноуровневой памяти большой адрес AS/400 (48 и 64-разрядный) позволяет программе ниже MI адресовать любой сегмент всего адресного пространства, а не только подмножество сегментов, как в модели адресации относительно сегмента. Программа может обращаться ко всей виртуальной памяти, а сама виртуальная память может быть разделяемой без каких-либо накладных расходов.Что такое одноуровневая память
Прежде чем погрузиться внутрь одноуровневой памяти, давайте попытаемся осмыслить общую картину, рассмотрев ее концепции и компоненты. Затем обсудим, почему одноуровневая память столь важна для AS/400 и разберем некоторые детали ее работы, взяв в качестве примера программу, выполняющую последовательное чтение индексированного файла базы данных (READ на ЯВУ или FETCH в SQL). В рамках этого примера мы разберем использование нескольких объектов: программы, индекса, курсора, области данных и др. Некоторые из них находятся в памяти, а некоторые нет. Начнем с краткого обзора адресации этих и любых других объектов. Над MI нет различий между памятью и диском (или другим вспомогательным хранилищем). OS/ 400 работает только с объектами, их именами и открытым содержимым. MI работает со своими объектами — декомпозицией объектов OS/400 — с помощью их идентификаторов (указателей). Других способов задания объектов на уровне MI нет. Программы, курсоры, области данных и другие объекты могут быть найдены простым указанием их имени. Чтобы использовать объект как ресурс, исполняющейся программе нужно «знать» только его имя и тип (как Вы помните, указание библиотеки необязательно, так как если она не задана, то будет просматриваться список библиотек). Имя объекта сразу же отображается в виртуальный адрес. Виртуальные адреса всех поименованных объектов находятся в библиотеках. Данный адрес помещается в указатель в процессе операции разрешения (описывалась в главе 5). Таким образом, системный указатель содержит виртуальный адрес заголовка объекта, который, в свою очередь, может содержать указатели на другие части данного объекта OS/400 и связанных с ним объектов MI. Для обращения к данным объекта, или для исполнения команд программы, они должны быть перенесены в память. В нашем примере последовательного чтения базы данных, фрагмент программы, содержащий команды на выполнение чтения, должен быть перенесен с диска в память, прежде чем команды исполнятся. Такой перенос с диска в память происходит ниже уровня MI, так как MI не различает диск и память. Можно считать, что все объекты находятся в памяти. То, что размер физической памяти слишком мал для хранения всех объектов — ограничение современных аппаратных технологий. Когда требуется фрагмент объекта, которого в памяти нет, этот отсутствующий фрагмент переносится и замещает некоторую неиспользуемую часть памяти. Можно также для наглядности представлять себе память как набор экранов, используемых для просмотра огромного пространства, содержащего все объекты. Процесс переноса страниц в память и из нее тогда будет выглядеть как изменения изображений на одном или нескольких экранах. Рисунок 8.1 иллюстрирует отображение объектов на виртуальные адреса ниже уровня MI. Физическое расположение разных фрагментов объектов здесь показано на примере двух: программы и пространства. Для простоты восприятия даны очень маленькие объекты, но концепция неизменна для объектов любого размера. Кроме того, на рисунке изображены два основных компонента управления памятью SLIC: управление вспомогательной памятью и управление основной памятью. Вкратце, их функции таковы: управление вспомогательной памятью распределяет виртуальным адресам объекта дисковое пространство, а управление основной памятью руководит перемещениями между дисковой и основной памятью. Рисунок 8.1. Объекты в одноуровневом хранилище
Рисунок 8.1. Объекты в одноуровневом хранилище
На рисунке видно, что память состоит из соответствующих экранам из предыдущей аналогии, страничных фреймов (их называют так, потому что они содержат страницы), размер которых на машинах IMPI был равен 512 байтам, а теперь на PowerPC — 4 КБ (4 096 байтов). Объект на диске разделен на страницы того же размера, что и страницы памяти. Со страницей диска связан виртуальный адрес объекта. Он может обозначать любой байт в пространстве объекта, и следовательно, указывать в середину страницы. Большой объект может занимать несколько страниц, но система спроектирована так, что на странице не могут содержаться части более чем одного объекта. Удивительно, но мне часто задают вопрос: «Для чего нужна виртуальная адресация до байта? Почему не адресовать просто объекты, как это делают команды MI?». Для полного ответа, необходимо начать с того, что AS/400 (как CISC, так и RISC-мо-дели) работают на самых обычных процессорах, получающих команды и данные из памяти. Механизм адресации процессора, показанный на рисунке 8.1, ничего «не знает» об объектах. Системные объекты MI находятся в памяти, и процессор использует побайтную адресацию для получения информации о них: записей файла, команд программы и т. д. Процессор IMPI использует для доступа к памяти 48-разрядный виртуальный адрес, транслируя его в реальный; процессор PowerPC — эффективные адреса, которые транслирует сначала в виртуальные, а потом в реальные адреса. В обоих процессорах адреса следующей команды и используемых данных хранятся в аппаратных регистрах. Страница, перенесенная в память одним процессом (заданием), становится доступной любому другому. Множество заданий могут использовать команды программ совместно. Записи, считанные из базы данных последними, вероятно, все еще находятся в памяти. Объем дискового ввода-вывода значительно сокращается при многократном считывании одних и тех же записей. Предположим, что в нашем примере чтения базы данных используется индекс, разделяемый с другими пользователями системы. Если этот индекс был недавно считан одним из них, то часть или весь индекс, вероятно, все еще в памяти, и не нужно ждать выборки страниц индекса с диска. В обычной системе с более ограниченными возможностями разделения данных в память пришлось бы перенести новую копию индекса, несмотря на то, что одна там уже есть. Получив виртуальный адрес, аппаратура сначала проверяет, не присутствует ли уже соответствующая страница в памяти. Если она там, то она и используется. Если нет, то отсутствующая страница будет считана с диска. Трансляция виртуального адреса в реальный состоит в поиске в страничной таблице, расположенной в памяти, страничного фрейма, соответствующего виртуальному адресу. Аппаратный просмотр таблицы страниц в поисках группы записей PTEG (page table entry group) ведется с помощью алгоритма хеширования (описывается далее в этой главе). Каждая PTEG содержит восемь записей таблицы страниц, которые просматриваются по одной. Если заданная страница не найдена, то происходит страничная ошибка — аппаратное прерывание, по которому управление основной памятью SLIC определяет дисковый адрес, соответствующий виртуальному, и обращается к процессору ввода-вывода с просьбой прочитать страницу с диска. Для ускорения поиска страниц, использовавшихся последними, процессор содержит набор регистров, называемый справочным буфером трансляции TLB (translation lookaside buffer), где запоминаются последние использовавшиеся записи таблицы страниц. Так как регистры TLB встроены в процессор, то загрузка из памяти, где расположена таблица страниц, при обращении виртуальному адресу недавно использованной страницы, не требуется. Если же виртуального адреса в TLB нет, то на следующей стадии процесса трансляции аппаратура обращается к таблице страниц. Процессоры PowerPC, используемые в последних моделях AS/400, могут также работать в режиме неактивных тегов. Данный режим никогда не используется OS/400, но для полноты описания поговорим и о его адресации. Итак, если процессор PowerPC работает в режиме неактивных тегов, то аппаратура сначала обращается к справочному буферу сегментов SLB (segment lookaside buffer) — другому набору регистров микросхемы процессора, содержащему использованные последними фрагменты таблицы сегментов. Если совпадения в регистрах SLB не найдено, то аппаратура обращается к таблице сегментов в памяти перед тем, как обратиться к регистрам TLB и таблице страниц. Другими словами, в режиме неактивных тегов процесс трансляции адресов трехшаговый: эффективный — виртуальный — реальный. Для сообщения процессору ввода-вывода о страничной ошибке SLIC использует адрес другого типа, называемый адресом прямого сохранения (direct store address). Такие адреса употребляются при взаимодействии с любым внешним устройством. Они начинаются с шестнадцатиричного значения 801. Часть адреса прямого сохранения передается непосредственно процессу, управляющему внешним устройством. Когда страница переносится с диска, она замещает в памяти страницу,которая давно не использовалась. С любой страницей связаны специальные разряды, которые устанавливаются при каждом обращении к ней. Измененные страницы также помечаются, чтобы в случае замещения в памяти они были записаны обратно на диск. Память содержит команды программ, данные и указатели. Под данными здесь понимается все, что не является исполняемой командой или указателем: все объекты OS/400, кроме объектов-программ, а также неисполняемые части объектов-программ. Сравните этот подход с подходом команды «WRSYSSTS» (Work With System Status), которая различает только страничные ошибки, связанные с работой базы данных, и все остальные. Страничные ошибки базы данных относятся только к физическим и логическим файлам. Прочие страничные ошибки, такие как ошибки для программы, курсора или любого пространства из нашего примера последовательного чтения относятся ко все остальным. Ранее мы рассмотрели страничные ошибки. Для считывания страницы с диска не обязательно ждать, пока такая ошибка произойдет. Любой компонент SLIC или любая транслированная программа MI может запросить у управления главной памятью SLIC явный перенос (считывание) в память диапазона виртуальных страниц (одной или более). Функционально явный перенос страниц в память не нужен, так как требуемые страницы всегда будут перенесены по страничной ошибке, но тогда процесс, вызывавший ее, ожидает завершения чтения с диска. Запрос на операцию переноса до того, как страницы фактически потребуются, позволяет выполнять операции дискового чтения параллельно с другой обработкой. Таким образом, явные переносы снижают временные затраты и повышают производительность. Возможно также явное создание очищенных страничных фреймов в памяти. Запрос на очистку, переданный управлению главной памятью, расписывает один или несколько страничных фреймов в памяти двоичными нулями. Эта операция полезна, например, в тех случаях, когда буфер заполняется новыми данными и текущее содержимое диска Вас не интересует. Вместо чтения страниц буфера, как в результате отдельных страничных ошибок, так и с помощью переноса, операция очистки позволяет обнулить страничные фреймы без обращения к диску. При запросе на перенос или очистку может быть выбран параметр обмена. Он задает диапазон виртуальных страниц, которые компонент управления главной памятью SLIC может использовать для замещения вместо выбранных по нормальному алгоритму. Обмен применяется для того, чтобы не удалять из памяти страницы, к которым постоянно обращаются, и не заменять их страницами, которые вряд ли будут нужны больше одного раза. Обмен полезен и в том случае, когда значительное число страниц переносится в небольшую память или небольшой пул памяти. (Память часто разделяется на несколько пулов меньшего размера и вся подкачка страниц для данного процесса выполнятся в одном пуле. Подробнее о пулах — в главе 9.). В запросе на перенос или очистку также можно указать, что одну или несколько страниц следует зафиксировать в памяти. Фиксированная страница становится резидентной и не будет удалена из памяти или записана обратно на диск вплоть до отмены этого распоряжения. Некоторые структуры данных SLIC, такие как элементы диспетчеризации, используемые в управлении процессами, всегда резидентные. Для ввода-вывода на виртуальную страницу и обратно, они должна быть зафиксированы, так как при перемещении данных по шине ввода-вывода используется реальный адрес фрейма страницы. Режим фиксации снимается отдельным запросом к управлению памятью. Дополняет перенос и очистку страниц возможность сбросить (переписать) одну или нескольких страниц на диск. Сброс имеет смысл только тогда, когда страница в памяти были изменена, то есть копия страницы на диске неактуальна. В отличие от переноса и очистки, которые не являются функционально необходимыми (эти задачи выполнит обработка страничной ошибки), сброс иногда необходим, например, при журналировании базы данных. В этом случае компонент базы данных в SLIC должен гарантировать, что записи журнала в журнальном пространстве записаны на диск, причем он обязан использовать функцию сброса, не дожидаясь, пока страницы журнального пространства будут записаны на диск в результате страничных ошибок. Кроме того, сбросом можно снять фиксацию в памяти одной или нескольких страниц. Наконец, страничные фреймы могут быть удалены из памяти без записи обратно на диск. Функциональных причин для удаления страниц нет, но это полезно, так как устраняет последующие операции записи на диск, например, если буфер памяти был опустошен и данные в нем больше не нужны. Процессор PowerPC имеет отдельные кэши данных и команд, играющие роль буфера между основной памятью и процессором. По сути дела кэши — это регистры на микросхеме процессора, обеспечивающие быстрый доступ к недавно использовавшимся командам или данным. В AS/400 часть виртуальных адресов используется для доступа к кэшам. Указатели должны быть защищены от повреждений. Программа пользователя, работающая на уровне MI, вполне способна изменить указатель, так как указатели хранятся в ассоциированном пространстве объектов MI вместе с другими структурами, к которым программа должна иметь доступ. Значения указателей также могут быть разрушены физическими явлениями, такими как флуктуации напряжения. Если указатель изменен «незаконно» (то есть не процедурой SLIC с помощью команды, недоступной непосредственно в MI), а каким-либо иным способом, то аппаратура сбрасывает разряд тега, делая тем самым указатель недействительным. Все временные и постоянные объекты подлежат страничному обмену (переносу их на диск и обратно в память по мере необходимости). Некоторые структуры (таблица страниц) и программы SLIC не откачиваются; они загружаются в процессе IPL и должны находиться в памяти постоянно. Их адреса не требуют трансляции, так как виртуальные адреса подобных структур или команд — реальные адреса памяти. Такого рода адреса всегда начинаются с шестнадцатиричного 800. Теперь, после краткого обзора, перейдем к детальному рассмотрению этих тем: разберем подробно влияние одноуровневой памяти на производительность, работу указателей, трансляцию адреса, и, наконец, управление дисками. Внимание! Для индикации «горячих» тем, будет использоваться «перечная» система.
Одноуровневая память и производительность
Как уже отмечалось, основное достоинство одноуровневой памяти — в сокращении числа команд, требуемых для выполнения определенных функций ОС. Можно привести множество примеров функций, производительность которых повышается благодаря одноуровневому хранилищу. Значительно упрощается за счет ненужности перемещения файлов файловая система, эффективней работает база данных. Но одно преимущество сразу бросается в глаза — это резкий рост производительности AS/ 400 при работе в интерактивном режиме, непосредственно зависящей от времени на переключение процессов. Рассмотрим пример, иллюстрирующий, как переключение процессов влияет на общую производительность AS/400. В обычной ОС, использующей адресацию относительно сегмента, при переключении процессов требуется изменение содержимого сегментных регистров. Если этого не сделать, то меньшие эффективные адреса в новой программе будут ошибочно транслироваться в виртуальные, принадлежащие программе предыдущего процесса. Проблема возникает потому, что каждый процесс в системах такого типа имеет собственную эффективную память, которая начинается с адреса 0. Данный тип адресации используется большинством современных версий Unix, а также AIX IBM. Роль сегментных регистров в системах такого типа — в отображении эффективных адресов в виртуальную память большего размера. Для этого содержимое сегментных регистров должно сохранятся где-то в памяти при всяком переключении с данного процесса на другой, и снова восстанавливаться, когда первый процесс опять начинает выполняться. Использование в процессорах PowerPC таблицы сегментов вместо сегментных регистров делает ненужным сохранение содержимого регистров в памяти — там уже и так находится таблица сегментов. Однако при переключении процессов необходимо очистить регистры SLB от информации предыдущего процесса. При трансляции эффективных адресов в виртуальные с использованием таблицы сегментов, регистры SLB обновляются по одному. Использование таблицы в памяти до заполнения всех регистров SLB может привести к увеличению числа тактов процессора на каждое обращение к памяти. В результате, производительность процесса снизится, пока не будет загружено некоторое число регистров. Если, например, процесс, на который происходит переключение — последовательное чтение из базы данных, потребуется протранслировать, по крайней мере, четыре адреса (по одному для программы, индекса, курсора и пространства данных) лишь для того, чтобы начать работу. Более того, так как каждый из таких объектов имеет несколько сегментов (со своими виртуальными адресами), вероятно, потребуется протранслировать с помощью таблицы в памяти от 8 до 12 адресов, прежде чем регистры SLB можно будет эффективно использовать. Как мы уже говорили, одноуровневая память AS/400 не использует ни таблицу сегментов, ни регистры SLB. Эффективный адрес соответствует виртуальному, и никакого преобразования не требуется, так как вся виртуальная память адресуется программой напрямую. Следовательно, при переключении процессов не происходит спада производительности, связанного с таблицей сегментов. И это еще не все! Возьмем трансляцию виртуального адреса в реальный с помощью таблицы страниц. В обычной системе каждый пользовательский процесс может иметь свою собственную виртуальную память с уникальной таблицей страниц. Пример — Microsoft Windows NT. В этой ОС компонент управления памятью предоставляет каждому процессу большое отдельное виртуальное адресное пространство. Это означает, что при переключении процессов нужно не только изменить таблицу страниц, чтобы обеспечить корректное отображение адресного пространства нового процесса, но также и очистить все регистры TLB. После переключения процессов адреса транслируются из виртуальных в реальные с помощью новой таблицы страниц, и содержимое регистров TLB обновляется по одному. Подобно перезагрузке регистров SLB, перезагрузка регистров TLB после переключения процессов снижает производительность. В AS/400 только одна виртуальная память, поэтому имеется только одна таблица страниц, которую используют все. Следовательно, при переключении процессов не нужна очистка TLB, и размер TLB больше, чем у других систем. Регистры TLB содержат использованные последними записи таблицы страниц. С течением времени самые старые записи заменяются новыми. При большем числе регистров выше вероятность того, что виртуальный адрес, транслированный в отдаленном прошлом, все еще будет в TLB. TLB большего размера означает, что при повторном переключении на ранее выполнявшийся процесс, некоторые или все его адреса уже доступны, что невозможно, если регистры TLB очищать при всяком переключении процессов. И здесь единая виртуальная память AS/400 позволяет сохранить значительный объем процессорного времени. Наконец, современные процессоры не выбирают информацию из памяти и не записывают ее туда непосредственно. Кэш-память содержит порции основной памяти и имеет собственный справочник. В зависимости от архитектуры кэш-памяти на данном компьютере и от того, есть ли разряды виртуального адреса в справочнике кэша, при переключении процесса может потребоваться очистка кэша. А при использовании одноуровневой памяти это не нужно. Операционные системы, предназначенные для работы с обычной виртуальной памятью, чаще всего пытаются избежать большого числа переключений процессов из-за неизбежных накладных расходов. Но если это не удается, для эффективной работы таким системам нужен высокопроизводительный процессор. По сравнению с другими системами, переключение процессов на AS/400 выполняется очень быстро, так как требует лишь нескольких действий. Спад производительности при старте нового процесса в AS/400 также не столь резкий. В результате, части как OS/400, так и SLIC, спроектированы для выполнения большого числа переключений процессов. Несколько лет назад сотрудники подразделения IBM Research обнаружили в ходе исследований, что в типичной пользовательской среде AS/400 переключение процессов происходит примерно через каждые 1200 команд. В это даже трудно поверить, ведь некоторым системам нужно выполнить 1000 или более команд только для самого переключения процессов. Но не AS/400! Благодаря способности быстро переключаться между процессами, производительность AS/400 в интерактивном режиме очень высока. Еще System/38 и первые AS/ 400 были оптимизированы для интерактивных приложений обработки транзакций. К AS/400 могут быть подключены любые терминалы. Одна такая большая система легко может поддерживать несколько тысяч параллельных пользователей, далеко превосходя в этом своих конкурентов, таких как Unix или Windows NT. Работая с приложениями, требующими частых переключений процессов, AS/400 способна превзойти по производительности системы с более быстрыми процессорами, так как выполняет меньше команд. Теперь рассмотрим среду, не требующую частых переключений процессов, например, среду пакетной обработки, где один процесс исполняется в течение долгого времени. Здесь скорость переключения процессов не играет существенной роли. Ранние системы AS/400 не очень хорошо работали в пакетном режиме — сказывалась недостаточная производительность процессора[ 64 ]. Дело в том, что в ранних версиях рочестерских систем никогда не использовались высокопроизводительные процессоры. Доходило даже до того, что при описании характеристик различных моделей AS/400, не указывались скорости процессоров в MIPS (миллион команд в секунду) или МГц. Подобно тому, как MIPS указывает, сколько команд процессор может выполнить в секунду, МГц задает число тактов за секунду. Если два разных процессора должны для выполнения одной и той же задачи выполнить одинаковое количество команд, и по всем остальным параметрам наблюдается такое же равенство, то значения MIPS или МГц могут дать некоторое представление о производительности процессоров. Но если для выполнения одной и той же работы процессорам нужно разное число команд, то ни MIPS, ни МГц не имеют никакого значения. В Рочестере всегда настаивали на оценке объема работ, который может выполнить AS/400, в таких показателях, как число транзакций в секунду. Лаборатория IBM в Ро-честере — лидер в создании промышленных тестов для обработки транзакций. Здесь в тесном контакте с Transaction Processing Performance Council измеряются показатели TPC для вычислительных систем. Эти показатели также призваны отражать стоимость каждой транзакции, рассчитанную на основании цен на аппаратуру и ПО для данной конфигурации. Все это дает пользователю возможность сравнивать разные вычислительные системы как по цене, так и по производительности. Так вот, в соответствии с этими тестами, AS/400 — один из лидеров как по показателю цена/производительность, так и по чистой производительности. Да и что здесь удивительного — ведь она создавалась именно для решения задач такого типа. Интерактивная обработка подразумевает присоединение к AS/400 терминалов, таких как 5250. Такие функции, как обновление полей на экране требуют много переключений процессов, особенно в случае подключения сотен или тысяч терминалов. При переходе в начале 90-х годов к клиент/серверным вычислениям, большая часть экранной обработки стала выполняться на ПК (клиент). Тем самым число переключений процессов на AS/400 (сервер) сократилось. Но многие характеристики клиент/серверных вычислений по-прежнему напоминают интерактивную обработку. Когда сотни или тысячи пользователей одновременно нажимают клавиши на клавиатуре или щелкают мышью, обращаясь к базе данных и ожидая затем ответа, быстрое переключение процессов AS/400 просто необходимо. AS/400 гармонично сочетает одновременную поддержку многочисленных пользователей (процессов) с требованиями клиент/серверной среды к пересылке данных. Но есть серверные приложения, специально предназначенные для интенсивных вычислений. Пример — приложения для поддержки принятия решений, где для генерации отчета требуется анализ больших объемов данных. Пользователи могут создавать сложные запросы, спрашивать «что если», выполнять поиск взаимосвязей в данных и т. д. Для такого приложения необходим тип обработки, больше похожий на пакетную, чем на интерактивную среду. Для таких серверных приложений AS/400 были нужны мощные процессоры. И вот, несколько лет назад мы впервые представили специальные модели AS/400, предназначенные именно для высокопроизводительных серверов. В этих моделях мощные процессоры и большая память. Результаты различных клиент/серверных тестов показывают, что модели Advanced Server весьма конкурентоспособны, как по цене, так и по производительности. Не удивительно, что многие заказчики признали их лучшими и для обычных пакетных приложений. Переключение процессов интенсивно используется как в интерактивных, так и в клиент/серверных приложениях. Быстрое переключение процессов всегда лучше медленного. Путем сокращения числа необходимых команд одноуровневая память повышает производительность не только переключения процессов, но и ряда других функций. Вернемся, например, к уже обсуждавшейся операции с файлами. Обычный сервер многократно выполняет операции открытия-закрытия файлов, что ведет к повышенной дисковой активности и снижает общую производительность системы. AS/400 обрабатывает такие файлы «на месте», устраняя излишние накладные расходы. Производительность процессора важна, но следует помнить, что каждая команда, которую не нужно выполнять, эквивалентна наличию для этой команды процессора с бесконечной скоростью. RISC-процессоры быстры, но не настолько.Указатели и теги
После роста производительности, самое большое достоинство одноуровневой памяти — всеобъемлющая возможность совместного доступа. Впрочем, это и самый большой ее недостаток. Если каждый пользователь системы имеет доступ к большому единому адресному пространству, требуются гарантии от несанкционированного доступа к тем объектам или информации, на которые у этих пользователей нет прав. В главе 5 мы говорили, что такая защита осуществляется в AS/400 указателями. Давайте теперь рассмотрим указатели и их функции более подробно. Итак, доступ к объекту MI обеспечивается путем разрешения указателя. Указатели имеют длину 16 байт (128 бит). Разрешенный системный указатель содержит возможность прямой адресации системного объекта, то есть в нем находится 64-разрядный виртуальный адрес. Указатели других типов (пространства, данных, команд и процедур) также содержат виртуальные адреса. Указатели находятся в ассоциированном пространстве системного объекта. В этом же пространстве содержатся данные, к которым имеет доступ и которые может изменить программа MI. Доступ и модификация данных в ассоциированном пространстве законны; изменение указателя — нет. Если бы программа MI могла изменять содержимое указателя, то была бы нарушена защита. Адрес в указателе мог бы быть изменен так, чтобы указывать на еще какой-нибудь объект или структуру, доступ к которой запрещен. Конечно, все это касается пользовательских программ, в которых команды MI заданы непосредственно; и не имеет отношение к программам на ЯВУ, таких как RPG или Cobol. Когда разрабатывалась структура указателя, способами защиты были избраны устранение ассемблера MI, перевод некоторых команд в разряд привилегированных и удаление из указателей полномочий. Как говорилось в главе 7, все эти усиления уровней защиты привносились в AS/400 с течением времени. Но даже такая степень защищенности не дает стопроцентной уверенности в том, что содержимое указателя не подвергнется несанкционированным изменениям. В главе 5 отмечалось, что ассоциированное пространство, содержащее указатели, занимает отдельный сегмент системного объекта. Первоначально в System/38 мы хотели использовать два сегмента: один — для данных, а второй —для указателей. Но такой подход снижал производительность системы. При использовании объекта было необходимо считывать с диска страницы, как сегмента данных, так и сегмента указателей, что повышало накладные расходы. Кроме того, два сегмента требовали некоторого увеличения размеров памяти. Единственным плюсом ассоциированного сегмента указателей была надежда, что он может защитить указатели от модификации пользователями. Но оказалось, что это не так. Скоро выяснилось, что мы не можем защитить ассоциированный сегмент указателей от изменений. При той степени защиты, которая планировались для System/38 (уровень 30), пользователь, имевший право доступа к объекту, мог работать с его содержимым с помощью ассемблера MI. Помещение указателей в отдельную часть объекта не предоставляло дополнительной защиты. Пришлось искать другое решение.Аппаратная защита указателей
 Мы понимали, что необходима некоторая форма аппаратной защиты памяти для указателей. Многие из больших систем того времени, такие как System/370, использовали для защиты памяти специальные аппаратные разряды, разрешавшие или запрещавшие пользователю доступ к некоторому блоку байтов памяти. Биты защиты обычно помещались в отдельном аппаратном массиве памяти, где пользователь не мог до них добраться. При каждом обращении к памяти этот массив проверялся, чтобы определить, имеет ли пользователь право на доступ к данному блоку памяти. Обычно такая защита устанавливалась на физический блок памяти размером в одну страницу.
Первоначально использовать в аппаратуре System/38 такой тип защиты памяти не планировалось: никто не думал, что он понадобится, ведь защита проектируемой системы выполнялась на уровне объектов. Однако, когда стало понятно, что некая форма аппаратной защиты все же нужна, мы рассмотрели возможность защиты блока размером в одну страницу. Но, во-первых, это было дорого, а, кроме того, такой подход не вполне соответствовал планам разработчиков. В идеале, нам виделась защита для каждых 16 байтов памяти, так как указатель занимает именно столько. Но чтобы сделать систему производительной, хотелось иметь возможность размещать указатели где угодно, но тогда отдельный аппаратный массив разрядов защиты для каждых 16 байтов памяти становился неприемлем по стоимости. Наконец, нашлось решение: использовать для защиты памяти дополнительные разряды, предназначенные для кода коррекции ошибок ECC (error correcting code).
Иногда, в памяти компьютера возникают ошибки из-за перепадов напряжения в электросети или по другим причинам. Для защиты от ошибок в большинстве памятей используются коды обнаружения ошибок и коды исправления ошибок. Действуют они так: к каждому слову памяти добавляются дополнительные разряды. Слово памяти содержит столько разрядов, сколько может быть считано за одну операцию. При считывании данных из памяти эти дополнительные разряды проверяются, чтобы определить, не произошла ли ошибка.
Простейшая форма обнаружения ошибок — добавление к слову памяти одного разряда четности. Его значение выбирается так, чтобы число разрядов 1 в слове памяти, включая разряд четности, всегда было четным. Если в памяти происходит ошибка, вызывающая изменение значения любого из битов с 1 на 0 или наоборот, то она будет обнаружена, когда при следующем считывании слова окажется, что число разрядов 1 нечетно. Четность позволяет определить одиночную ошибку, но не говорит, в каком разряде она произошла. С помощью такого механизма, обычно применяемого на ПК, можно определить нечетное число ошибок в слове памяти. Но если число ошибок четное, он не поможет.
Большинство компьютеров, используемых для коммерческих задач, в частности AS/400, как для обнаружения, так и для исправления ошибок применяют дополнительные разряды кодов коррекции. Эти дополнительные разряды могут определять все однократные и многократные ошибки, и даже указать, в каком именно разряде они произошли. Таким образом, аппаратура может исправить ошибку и продолжить работу. Значение коррекции ошибок очевидно для каждого, кому приходилось видеть на экране ПК сообщение «memory parity error». С таким сломанным ПК ничего нельзя сделать до тех пор, пока неисправный модуль памяти не заменен. По этой причине многие старшие модели современных ПК используют памяти ECC.
Оригинальная аппаратура System/38 имела 32-разрядное (4-байтовое) слово памяти. ECC требовал дополнительных 7 разрядов, то есть для каждого слова памяти было нужно 39 разрядов. Технология тогда позволяла увеличивать размер слова только приращениями по 8 разрядов, то есть, фактически, слово памяти имело размер 40 разрядов. Для каждого 4-байтового слова памяти предусматривался дополнительный разряд, который и должен был осуществлять функции защиты памяти. Мы назвали его разрядом тега.
Указатель занимает 16 байтов памяти. Мы решили всегда помещать указатели на 16-байтовые границы (все четыре младшие разряда адреса памяти равны 0). Такую конфигурацию обычно обозначают термином четверное слово (quadword), или, иначе говоря, 16-байтовое поле, выровненное на 16-байтовую границу. Есть и двойные слова, а кроме того, слова, выровненные на 8-ми и 4-байтовые границы. Обычно, под термином слово понимается 4 байта.
Указатель в оригинальной System/38 занимал четыре последовательных 4-байтовых слова памяти, каждое со своим разрядом тега. Мы решили, что для каждого слова памяти этот разряд будет равен 1, если слово содержит любую из четырех частей указателя; и 0 — если не содержит. Для самого указателя нужен только один разряд, так что если все четыре разряда в четырех последовательных словах памяти установлены в 1, то значение логического тега указателя равно 1. Если любой из четырех разрядов был равен 0, то и логический тег указателя равнялся 0.
Последующие версии AS/400 имеют 64-разрядное (8-байтовое) слово памяти. Такое слово требует 8 разрядов ЕСС; так что с учетом разряда тега, слова памяти AS/ 400 упакованы по 73 разряда. Мы по-прежнему размещаем указатели на 16-байтовых границах, и у каждого указателя есть один логический разряд тега. Если в AS/400 с 64-разрядным словом, два разряда тега в двух последовательных словах, содержащих указатель, оба равны 1, то и логический тег указателя равен 1. Если же любой из разрядов равен нулю, то и указатель имеет логический тег 0. Чтобы оставаться в рамках принятой терминологии, мы называем 64-разрядное слово памяти двойным словом.
Всякий раз, когда в AS/400 происходит запись в память, аппаратура управления памятью строит ЕСС и сохраняет его вместе со словом памяти. В процессе операции записи эта аппаратура также отключает разряд тега в слове памяти (устанавливает его в 0). Так что в результате выполнения любой стандартной команды записи в память, разряды тега записанных слов всегда будут сброшены в 0.
Мы понимали, что необходима некоторая форма аппаратной защиты памяти для указателей. Многие из больших систем того времени, такие как System/370, использовали для защиты памяти специальные аппаратные разряды, разрешавшие или запрещавшие пользователю доступ к некоторому блоку байтов памяти. Биты защиты обычно помещались в отдельном аппаратном массиве памяти, где пользователь не мог до них добраться. При каждом обращении к памяти этот массив проверялся, чтобы определить, имеет ли пользователь право на доступ к данному блоку памяти. Обычно такая защита устанавливалась на физический блок памяти размером в одну страницу.
Первоначально использовать в аппаратуре System/38 такой тип защиты памяти не планировалось: никто не думал, что он понадобится, ведь защита проектируемой системы выполнялась на уровне объектов. Однако, когда стало понятно, что некая форма аппаратной защиты все же нужна, мы рассмотрели возможность защиты блока размером в одну страницу. Но, во-первых, это было дорого, а, кроме того, такой подход не вполне соответствовал планам разработчиков. В идеале, нам виделась защита для каждых 16 байтов памяти, так как указатель занимает именно столько. Но чтобы сделать систему производительной, хотелось иметь возможность размещать указатели где угодно, но тогда отдельный аппаратный массив разрядов защиты для каждых 16 байтов памяти становился неприемлем по стоимости. Наконец, нашлось решение: использовать для защиты памяти дополнительные разряды, предназначенные для кода коррекции ошибок ECC (error correcting code).
Иногда, в памяти компьютера возникают ошибки из-за перепадов напряжения в электросети или по другим причинам. Для защиты от ошибок в большинстве памятей используются коды обнаружения ошибок и коды исправления ошибок. Действуют они так: к каждому слову памяти добавляются дополнительные разряды. Слово памяти содержит столько разрядов, сколько может быть считано за одну операцию. При считывании данных из памяти эти дополнительные разряды проверяются, чтобы определить, не произошла ли ошибка.
Простейшая форма обнаружения ошибок — добавление к слову памяти одного разряда четности. Его значение выбирается так, чтобы число разрядов 1 в слове памяти, включая разряд четности, всегда было четным. Если в памяти происходит ошибка, вызывающая изменение значения любого из битов с 1 на 0 или наоборот, то она будет обнаружена, когда при следующем считывании слова окажется, что число разрядов 1 нечетно. Четность позволяет определить одиночную ошибку, но не говорит, в каком разряде она произошла. С помощью такого механизма, обычно применяемого на ПК, можно определить нечетное число ошибок в слове памяти. Но если число ошибок четное, он не поможет.
Большинство компьютеров, используемых для коммерческих задач, в частности AS/400, как для обнаружения, так и для исправления ошибок применяют дополнительные разряды кодов коррекции. Эти дополнительные разряды могут определять все однократные и многократные ошибки, и даже указать, в каком именно разряде они произошли. Таким образом, аппаратура может исправить ошибку и продолжить работу. Значение коррекции ошибок очевидно для каждого, кому приходилось видеть на экране ПК сообщение «memory parity error». С таким сломанным ПК ничего нельзя сделать до тех пор, пока неисправный модуль памяти не заменен. По этой причине многие старшие модели современных ПК используют памяти ECC.
Оригинальная аппаратура System/38 имела 32-разрядное (4-байтовое) слово памяти. ECC требовал дополнительных 7 разрядов, то есть для каждого слова памяти было нужно 39 разрядов. Технология тогда позволяла увеличивать размер слова только приращениями по 8 разрядов, то есть, фактически, слово памяти имело размер 40 разрядов. Для каждого 4-байтового слова памяти предусматривался дополнительный разряд, который и должен был осуществлять функции защиты памяти. Мы назвали его разрядом тега.
Указатель занимает 16 байтов памяти. Мы решили всегда помещать указатели на 16-байтовые границы (все четыре младшие разряда адреса памяти равны 0). Такую конфигурацию обычно обозначают термином четверное слово (quadword), или, иначе говоря, 16-байтовое поле, выровненное на 16-байтовую границу. Есть и двойные слова, а кроме того, слова, выровненные на 8-ми и 4-байтовые границы. Обычно, под термином слово понимается 4 байта.
Указатель в оригинальной System/38 занимал четыре последовательных 4-байтовых слова памяти, каждое со своим разрядом тега. Мы решили, что для каждого слова памяти этот разряд будет равен 1, если слово содержит любую из четырех частей указателя; и 0 — если не содержит. Для самого указателя нужен только один разряд, так что если все четыре разряда в четырех последовательных словах памяти установлены в 1, то значение логического тега указателя равно 1. Если любой из четырех разрядов был равен 0, то и логический тег указателя равнялся 0.
Последующие версии AS/400 имеют 64-разрядное (8-байтовое) слово памяти. Такое слово требует 8 разрядов ЕСС; так что с учетом разряда тега, слова памяти AS/ 400 упакованы по 73 разряда. Мы по-прежнему размещаем указатели на 16-байтовых границах, и у каждого указателя есть один логический разряд тега. Если в AS/400 с 64-разрядным словом, два разряда тега в двух последовательных словах, содержащих указатель, оба равны 1, то и логический тег указателя равен 1. Если же любой из разрядов равен нулю, то и указатель имеет логический тег 0. Чтобы оставаться в рамках принятой терминологии, мы называем 64-разрядное слово памяти двойным словом.
Всякий раз, когда в AS/400 происходит запись в память, аппаратура управления памятью строит ЕСС и сохраняет его вместе со словом памяти. В процессе операции записи эта аппаратура также отключает разряд тега в слове памяти (устанавливает его в 0). Так что в результате выполнения любой стандартной команды записи в память, разряды тега записанных слов всегда будут сброшены в 0.
Режим активных тегов
 В главе 2 мы говорили о расширениях архитектуры PowerPC. Одно из таких расширений — режим активных тегов. Когда процессор PowerPC работает в данном режиме, доступны дополнительные команды, которых нет в режиме неактивных тегов. Всего для AS/400 было добавлено 25 команд, доступных только в режиме активных тегов. Сюда входят команды множественной загрузки и сохранения четверных слов в регистрах, а также команды, обратные им. Есть также команды десятичной арифметики, системные функции вызова/возврата и команды выделения для проверки значений разрядов в управляющих регистрах. Шесть новых команд поддерживают теги.
Некоторые из этих специальных теговых команд используются для установки или проверки значений разрядов тега. Одна из них, команда «Сохранить четверное слово» («stq»), сохраняет в памяти 16 байтов данных из двух 64-разрядных регистров и включает два разряда тега. Другая —«Загрузить четверное слово» («lq»), загружает 16 байтов памяти в два 64-разрядных регистра и устанавливает разряд в регистре управления в 1, если оба теговых разряда в считанных словах равны 1 (в противном случае этот разряд устанавливается в 0). Еще одна команда позволяет считывать теги из памяти в специальный регистр процессора. Использование этой команды будет рассмотрено в следующем разделе.
Теговые команды: используются только в SLIC; они не генерируются транслятором для программ MI. Это означает, что любое сохранение в памяти, сгенерированное для программы MI, всегда использует стандартные команды и отключает разряды тега. Когда в процессе разрешения создается указатель, SLIC строит его в двух 64-разрядных регистрах и использует команду «stq» для включения теговых регистров в памяти. При всякой попытке использовать указатель программой MI, SLIC загружает его содержимое командой «lq» в регистры и затем проверяет, установлены ли разряды: тега. Если разряды тега сброшены, значит, кто-то изменил указатель, и он теперь неверен.
Разряды тега AS/400 не предотвращают изменения указателей, а лишь определяют, производились ли эти изменения. Такой подход отличается от большинства схем защиты памяти. Обычно, защита памяти не допускает изменений, и такая защита на уровне страниц в AS/400 имеется. Однако указатели распознают лишь уже произошедшие модификации, что по сравнению с ранними версиями системы сокращает объем аппаратуры, но по-прежнему обеспечивает нужный уровень защиты.
Указатели нельзя подделать. Теги гарантируют, что указатель создан ОС (SLIC), и что он не изменялся чем-либо, кроме SLIC. Недобросовестный пользователь, попытавшись создать, скопировать или изменить указатель, не сможет включить разряды тега и получит в результате бесполезные 16 байт. Именно поэтому AS/400 всегда работает в режиме активных тегов, несмотря на то, что процессоры PowerPC, используемые в ней, могут действовать и в режиме неактивных тегов.
В главе 2 мы говорили о расширениях архитектуры PowerPC. Одно из таких расширений — режим активных тегов. Когда процессор PowerPC работает в данном режиме, доступны дополнительные команды, которых нет в режиме неактивных тегов. Всего для AS/400 было добавлено 25 команд, доступных только в режиме активных тегов. Сюда входят команды множественной загрузки и сохранения четверных слов в регистрах, а также команды, обратные им. Есть также команды десятичной арифметики, системные функции вызова/возврата и команды выделения для проверки значений разрядов в управляющих регистрах. Шесть новых команд поддерживают теги.
Некоторые из этих специальных теговых команд используются для установки или проверки значений разрядов тега. Одна из них, команда «Сохранить четверное слово» («stq»), сохраняет в памяти 16 байтов данных из двух 64-разрядных регистров и включает два разряда тега. Другая —«Загрузить четверное слово» («lq»), загружает 16 байтов памяти в два 64-разрядных регистра и устанавливает разряд в регистре управления в 1, если оба теговых разряда в считанных словах равны 1 (в противном случае этот разряд устанавливается в 0). Еще одна команда позволяет считывать теги из памяти в специальный регистр процессора. Использование этой команды будет рассмотрено в следующем разделе.
Теговые команды: используются только в SLIC; они не генерируются транслятором для программ MI. Это означает, что любое сохранение в памяти, сгенерированное для программы MI, всегда использует стандартные команды и отключает разряды тега. Когда в процессе разрешения создается указатель, SLIC строит его в двух 64-разрядных регистрах и использует команду «stq» для включения теговых регистров в памяти. При всякой попытке использовать указатель программой MI, SLIC загружает его содержимое командой «lq» в регистры и затем проверяет, установлены ли разряды: тега. Если разряды тега сброшены, значит, кто-то изменил указатель, и он теперь неверен.
Разряды тега AS/400 не предотвращают изменения указателей, а лишь определяют, производились ли эти изменения. Такой подход отличается от большинства схем защиты памяти. Обычно, защита памяти не допускает изменений, и такая защита на уровне страниц в AS/400 имеется. Однако указатели распознают лишь уже произошедшие модификации, что по сравнению с ранними версиями системы сокращает объем аппаратуры, но по-прежнему обеспечивает нужный уровень защиты.
Указатели нельзя подделать. Теги гарантируют, что указатель создан ОС (SLIC), и что он не изменялся чем-либо, кроме SLIC. Недобросовестный пользователь, попытавшись создать, скопировать или изменить указатель, не сможет включить разряды тега и получит в результате бесполезные 16 байт. Именно поэтому AS/400 всегда работает в режиме активных тегов, несмотря на то, что процессоры PowerPC, используемые в ней, могут действовать и в режиме неактивных тегов.
Указатели и теги на диске
 Разработчики System/38 столкнулись с и другой проблемой. Допустим, потребуется переместить страницу из памяти на диск. В памяти есть дополнительные разряды для ЕСС и тегов, а на диске нет. Там используется другая форма кода коррекции ошибок, называемая циклическим избыточным контролем CRC (cyclic redundancy check), который не добавляет дополнительных разрядов к каждому слову памяти. Значит, нужен способ сохранения разрядов тега вместе с указателями при перемещении страницы, содержащей указатели, на диск. Короче говоря, нужно найти дополнительное место на диске.
Магнитный диск представляет собой набор плоскостей, имеющих по две поверхности для записи. Поверхность каждого диска разделена на концентрические окружности, называемые дорожками. В свою очередь, дорожки разделены на сектора, которые и содержат информацию. Размер сектора для System/38 и AS/400 равен 520 байтам. Каждый сектор содержит 8-байтовый заголовок сектора и область данных в 512 байт. Размер сектора был выбран так, чтобы 512-байтовая страница System/38 умещалась в него.
В System/38 было определено несколько специальных команд IMPI для работы с тегами. Одна из таких команд— «Извлечь теги» — использовалась для сбора тегов со страницы памяти. При записи страницы на диск, теги также записывались на диск. Другая команда IMPI — « Вставить теги»— применялась для помещения тегов обратно в память после считывания страницы с диска.
Многие ISV и пользователи, знавшие о разрядах тега System/38, считали, что они хранятся на диске в 8-байтовых заголовках секторов. Но это не так. Информация на самой странице сохранялась в 512-байтной области данных сектора. Заголовок сектора содержал информацию о странице, но наиболее важной его задачей было хранение виртуального адреса страницы. Этот адрес нужен был для восстановления. Даже в случае потери таблицы в памяти, связывавшей виртуальные адреса с местами на диске, она могла быть восстановлена: достаточно считать заголовки каждого сектора и определить, с каким виртуальным адресом этот сектор связан. Так что большая часть пространства в заголовке сектора была занята виртуальным адресом страницы, места для тегов не оставалось.
Это подтверждает простой расчет. Одна страница может содержать 32 указателя (16 байтов Г32 = 512), что означает 32 бита тегов на страницу. Виртуальный адрес в System/38 занимал 48 разрядов, но для идентификации страницы использовались не все из них. Младшие 9 разрядов виртуального адреса задавали байт на 512-байтной странице (29 = 512). Следовательно, для уникальной идентификации страницы нужно хранить только 39 старших разрядов виртуального адреса (48 — 9 =39). Однако даже без разрядов состояния потребовался бы минимум 71 разряд для хранения виртуального адреса страницы и всех битов тега (39 +32 =71), в заголовке же сектора было только 64 разряда. Хранить биты тега в заголовках секторов оказалось невозможно.
Разработчики System/38, проявив недюжинную смекалку, нашли для тегов место внутри страницы. Дело в том, что некоторое пространство в указателе не используется. Если на странице есть хотя бы один указатель, то есть и некоторое неиспользуемое пространство, в котором можно хранить биты тега. Если указателей на странице нет, то все биты тега для нее равны 0, поэтому и хранить их незачем. Заголовок сектора в System/38 содержал информацию о том, есть ли на странице теги, и если есть, то где именно.
До появления RISC-процессоров мы продолжали использовать на AS/400 и размер страницы, равный 512 байтам, и только что описанный метод хранения битов тега. Но уже несколько лет нас мучило желание увеличить размер страницы.
Размер страницы в 512 байт был выбран для System/38 по причине ограниченности размеров основной памяти[ 65 ]. Но для увеличенной памяти AS/400 512-байтовая страница была слишком мала, страниц получалось слишком много, и таблицы страниц достигали гигантских размеров. Кроме того, уже многие годы мы «упаковывали» маленькие страницы в «логические» страницы большего размера для сокращения объема дисковых операций. Для новых процессоров было решено увеличить размер страницы до 4 КБ (4 096 байтов).
В новых моделях был сохранен размер сектора на диске в 520 байт. Четырехкило-байтовая страница теперь хранится в восьми последовательных секторах. При наличии восьми 8-байтовых заголовков на каждой странице в 4 КБ больше чем достаточно места для хранения 256 теговых битов.
Для извлечения тегов из памяти к архитектуре процессора PowerPC был добавлен специальный регистр тегов. Когда процессор выполняет специальную теговую команду, «Множественная загрузка двойных слов» («lmd»), в 16 регистров может быть считано из памяти до 16 двойных слов (восемь четверных слов). При выполнении команды в регистре тега сохраняется восемь теговых регистров четверных слов памяти. Обратите внимание, что в регистре тега сохраняются 8 логических битов тега, а не 16 физических, как в памяти. Вспомним, что четверное слово это два 64-разрядных (8-байтовых) слова памяти; следовательно, в четверном слове два физических бита тега, так что в восьми четверных словах — 16 физических битов тега. С помощью команды «lmd» биты тегов страницы могут быть собраны для последующей записи на диске вместе с данными. Эта команда также доступна только в режиме активных тегов.
Разработчики System/38 столкнулись с и другой проблемой. Допустим, потребуется переместить страницу из памяти на диск. В памяти есть дополнительные разряды для ЕСС и тегов, а на диске нет. Там используется другая форма кода коррекции ошибок, называемая циклическим избыточным контролем CRC (cyclic redundancy check), который не добавляет дополнительных разрядов к каждому слову памяти. Значит, нужен способ сохранения разрядов тега вместе с указателями при перемещении страницы, содержащей указатели, на диск. Короче говоря, нужно найти дополнительное место на диске.
Магнитный диск представляет собой набор плоскостей, имеющих по две поверхности для записи. Поверхность каждого диска разделена на концентрические окружности, называемые дорожками. В свою очередь, дорожки разделены на сектора, которые и содержат информацию. Размер сектора для System/38 и AS/400 равен 520 байтам. Каждый сектор содержит 8-байтовый заголовок сектора и область данных в 512 байт. Размер сектора был выбран так, чтобы 512-байтовая страница System/38 умещалась в него.
В System/38 было определено несколько специальных команд IMPI для работы с тегами. Одна из таких команд— «Извлечь теги» — использовалась для сбора тегов со страницы памяти. При записи страницы на диск, теги также записывались на диск. Другая команда IMPI — « Вставить теги»— применялась для помещения тегов обратно в память после считывания страницы с диска.
Многие ISV и пользователи, знавшие о разрядах тега System/38, считали, что они хранятся на диске в 8-байтовых заголовках секторов. Но это не так. Информация на самой странице сохранялась в 512-байтной области данных сектора. Заголовок сектора содержал информацию о странице, но наиболее важной его задачей было хранение виртуального адреса страницы. Этот адрес нужен был для восстановления. Даже в случае потери таблицы в памяти, связывавшей виртуальные адреса с местами на диске, она могла быть восстановлена: достаточно считать заголовки каждого сектора и определить, с каким виртуальным адресом этот сектор связан. Так что большая часть пространства в заголовке сектора была занята виртуальным адресом страницы, места для тегов не оставалось.
Это подтверждает простой расчет. Одна страница может содержать 32 указателя (16 байтов Г32 = 512), что означает 32 бита тегов на страницу. Виртуальный адрес в System/38 занимал 48 разрядов, но для идентификации страницы использовались не все из них. Младшие 9 разрядов виртуального адреса задавали байт на 512-байтной странице (29 = 512). Следовательно, для уникальной идентификации страницы нужно хранить только 39 старших разрядов виртуального адреса (48 — 9 =39). Однако даже без разрядов состояния потребовался бы минимум 71 разряд для хранения виртуального адреса страницы и всех битов тега (39 +32 =71), в заголовке же сектора было только 64 разряда. Хранить биты тега в заголовках секторов оказалось невозможно.
Разработчики System/38, проявив недюжинную смекалку, нашли для тегов место внутри страницы. Дело в том, что некоторое пространство в указателе не используется. Если на странице есть хотя бы один указатель, то есть и некоторое неиспользуемое пространство, в котором можно хранить биты тега. Если указателей на странице нет, то все биты тега для нее равны 0, поэтому и хранить их незачем. Заголовок сектора в System/38 содержал информацию о том, есть ли на странице теги, и если есть, то где именно.
До появления RISC-процессоров мы продолжали использовать на AS/400 и размер страницы, равный 512 байтам, и только что описанный метод хранения битов тега. Но уже несколько лет нас мучило желание увеличить размер страницы.
Размер страницы в 512 байт был выбран для System/38 по причине ограниченности размеров основной памяти[ 65 ]. Но для увеличенной памяти AS/400 512-байтовая страница была слишком мала, страниц получалось слишком много, и таблицы страниц достигали гигантских размеров. Кроме того, уже многие годы мы «упаковывали» маленькие страницы в «логические» страницы большего размера для сокращения объема дисковых операций. Для новых процессоров было решено увеличить размер страницы до 4 КБ (4 096 байтов).
В новых моделях был сохранен размер сектора на диске в 520 байт. Четырехкило-байтовая страница теперь хранится в восьми последовательных секторах. При наличии восьми 8-байтовых заголовков на каждой странице в 4 КБ больше чем достаточно места для хранения 256 теговых битов.
Для извлечения тегов из памяти к архитектуре процессора PowerPC был добавлен специальный регистр тегов. Когда процессор выполняет специальную теговую команду, «Множественная загрузка двойных слов» («lmd»), в 16 регистров может быть считано из памяти до 16 двойных слов (восемь четверных слов). При выполнении команды в регистре тега сохраняется восемь теговых регистров четверных слов памяти. Обратите внимание, что в регистре тега сохраняются 8 логических битов тега, а не 16 физических, как в памяти. Вспомним, что четверное слово это два 64-разрядных (8-байтовых) слова памяти; следовательно, в четверном слове два физических бита тега, так что в восьми четверных словах — 16 физических битов тега. С помощью команды «lmd» биты тегов страницы могут быть собраны для последующей записи на диске вместе с данными. Эта команда также доступна только в режиме активных тегов.
Внутри указателя
 Указатель используется в AS/400 для доступа к объектам. В этом разделе мы сосредоточимся исключительно на формате разрешенного указателя. У разрешенного указателя две функции: он описывает объект и полномочия пользователя на этот объект; а также задает адрес объекта в одноуровневом хранилище. Иначе говоря, 16-байтовый указатель разделен на две 8-байтовые части: первая —описание объекта, а вторая — виртуальные адрес.
В первой части разрешенного указателя находятся биты состояния, которые, кроме всего прочего, задают, что это за указатель: системный, пространственный, данных, команд или процедуры. В этой же части содержится информация об объекте и данных, доступных через этот указатель. Например, системный указатель задает для объекта тип системного объекта MI и подтип, определенный OS/400; а указатель данных описывает тип данных. Прочая информация первой части указателя касается полномочий пользователей на операции с объектом. Как отмечалось ранее, поле полномочий используется, только если указателем оперирует сама ОС в системном состоянии. В указателях, созданных пользовательскими программами в пользовательском режиме, поле полномочий не заполнено.
Информация первой части указателя не занимает все 8, а лишь 4 байта. Это означает, что 4 байта указателя не используются. Они зарезервированы для будущих расширений адреса. Дополнительные 32 разряда вместе с 64 адресными разрядами указателя дают возможность расширить адрес AS/400 до 96 разрядов (12 байтов) без изменений каких-либо программ поверх MI. Если потребуется еще большее пространство, то можно будет удалить из указателя информацию типа и полномочий, и увеличить длину адреса сверх 96 разрядов.
Вторая часть разрешенного указателя содержит 64-разрядный адрес. Так было всегда, и многие годы это вызывало путаницу: каков все же размер виртуального адреса System/38 и AS/400, 48- или 64-разрядный? С появлением новых RISC-моделей AS/400 путаница прекратилась: теперь адрес 64-разрядный. А в System/38 и ранних моделях AS/400 он был и таким, и таким. В MI адрес всегда был 64-разрядным, а аппаратура работала с 48-разрядным адресом. Как они уживались вместе — тема следующего раздела.
Указатель используется в AS/400 для доступа к объектам. В этом разделе мы сосредоточимся исключительно на формате разрешенного указателя. У разрешенного указателя две функции: он описывает объект и полномочия пользователя на этот объект; а также задает адрес объекта в одноуровневом хранилище. Иначе говоря, 16-байтовый указатель разделен на две 8-байтовые части: первая —описание объекта, а вторая — виртуальные адрес.
В первой части разрешенного указателя находятся биты состояния, которые, кроме всего прочего, задают, что это за указатель: системный, пространственный, данных, команд или процедуры. В этой же части содержится информация об объекте и данных, доступных через этот указатель. Например, системный указатель задает для объекта тип системного объекта MI и подтип, определенный OS/400; а указатель данных описывает тип данных. Прочая информация первой части указателя касается полномочий пользователей на операции с объектом. Как отмечалось ранее, поле полномочий используется, только если указателем оперирует сама ОС в системном состоянии. В указателях, созданных пользовательскими программами в пользовательском режиме, поле полномочий не заполнено.
Информация первой части указателя не занимает все 8, а лишь 4 байта. Это означает, что 4 байта указателя не используются. Они зарезервированы для будущих расширений адреса. Дополнительные 32 разряда вместе с 64 адресными разрядами указателя дают возможность расширить адрес AS/400 до 96 разрядов (12 байтов) без изменений каких-либо программ поверх MI. Если потребуется еще большее пространство, то можно будет удалить из указателя информацию типа и полномочий, и увеличить длину адреса сверх 96 разрядов.
Вторая часть разрешенного указателя содержит 64-разрядный адрес. Так было всегда, и многие годы это вызывало путаницу: каков все же размер виртуального адреса System/38 и AS/400, 48- или 64-разрядный? С появлением новых RISC-моделей AS/400 путаница прекратилась: теперь адрес 64-разрядный. А в System/38 и ранних моделях AS/400 он был и таким, и таким. В MI адрес всегда был 64-разрядным, а аппаратура работала с 48-разрядным адресом. Как они уживались вместе — тема следующего раздела.
Сказка о двух размерах адреса
 Появление новых RISC-моделей с полностью 64-разрядными аппаратными адресами устранило большинство проблем, связанных со смешением 64- и 48-разрядной адресации в предыдущих моделях. Чтобы понять, почему 64-разрядный аппаратный адрес так важен, рассмотрим первоначальную 48-разрядную реализацию.
48-разрядный адрес появился в результате компромисса. Проектировщики ОС System/38 планировали адрес размером в 64 бита. После того, как размер указателя был определен в 16 байтов, для 64-разрядного адреса появилось достаточно места. Проблемы возникли на аппаратном уровне. Чем больше разрядов в адресе, тем больше размер регистров процессора. Больший размер регистров требовал большего числа цепей и повышал стоимость аппаратных средств.
Появление новых RISC-моделей с полностью 64-разрядными аппаратными адресами устранило большинство проблем, связанных со смешением 64- и 48-разрядной адресации в предыдущих моделях. Чтобы понять, почему 64-разрядный аппаратный адрес так важен, рассмотрим первоначальную 48-разрядную реализацию.
48-разрядный адрес появился в результате компромисса. Проектировщики ОС System/38 планировали адрес размером в 64 бита. После того, как размер указателя был определен в 16 байтов, для 64-разрядного адреса появилось достаточно места. Проблемы возникли на аппаратном уровне. Чем больше разрядов в адресе, тем больше размер регистров процессора. Больший размер регистров требовал большего числа цепей и повышал стоимость аппаратных средств.
 Техническим менеджером System/38 был Рей Клотц, не видевший надобности в таком большом адресе. Его многократно пытались уговорить, но Рей так и не поддался на уверения, что 64-разрядного адреса хватит навечно. В середине 70-х годов подразделение IBM по мэйнфреймам собиралось объявить о новом большом адресе для System/370, получившем название расширенной адресации (XA). С применением ХА адрес System/370 должен был вырасти с 24 до 31 разряда. Рей обвинял нас в желании непременно превзойти System/370 и утешал тем, что 32 разряда все равно больше чем 31. «Вы побьете их и одним разрядом, а больше и не надо», — как бы говорил он. Мы, в свою очередь, утверждали, что 32-разрядный адрес не будет работать с одноуровневой памятью System/38, и что нужны 64 разряда. Когда стало очевидным, что спор зашел в тупик, мы поступили так, как будто торговались о цене подержанной машины: поделили пополам разницу между 32 и 64. Таким образом, получился 48-разрядный адрес.
Для поддержки сегментированной памяти 48-разрядный адрес разделяется надвое. Старшие разряды задают сегмент, а младшие, называемые смещением — байт внутри сегмента. Мы решили использовать для задания сегмента старшие 32 разряда, а для смещения — младшие 16, назвав все это адресом 32/16. 16 разрядов смещения означали размер сегмента в 64 КБ (216 = 64 КБ).
Оригинальная аппаратура процессора System/38 имела 16-разрядный тракт данных и 16-разрядный сумматор для вычислений. Смысл использования адреса форматом 32/16 был в том, чтобы смещение адреса не выходило за размер тракта данных, так как очень часто обновлялось. Мы решили обрабатывать 32-разрядный идентификатор сегмента не в тракте данных процессора, а вне его, в отдельном наборе сегментных регистров. К этим сегментным регистрам был возможен доступ со стороны процессора, но они не могли обновляться «на месте».
Программисты, отвечавшие за ПО ОС ниже MI (первоначально VMC) не были согласны с такой адресацией (32/16), так как считали, что размер сегмента в 64 КБ слишком мал. Первоначально они предполагали создать сегментные группы, каждая из которых содержала бы один или несколько таких 64-килобайтных сегментов, но, в конце концов, решили, что сегментная группа всегда должна состоять из 256 сегментов. При выделении нового сегмента как части вновь создаваемого объекта его размер всегда будет равен 16 МБ (256 Г 64 КБ = 16 МБ). С этого момента мы говорили о 64-килобайтных и 16-мегабайтных сегментах, впрочем, называя иногда вторые сегментной группой. Этот разнобой в терминологии продолжался до появления процессоров PowerPC и SLIC. Если Вы возьмете в руки калькулятор или таблицу степеней двойки, то поймете, почему программисты VMC, имевшие дело с 16-мегабайтными сегментами, рассматривали 48-разрядный адрес как имеющий 24-разрядный идентификатор сегмента и 24-разрядное смещение (ведь 224 = 16 МБ).
Представление адреса 24/24, использовавшееся VMC, не совпадало с представлением 32/16, использовавшимся аппаратурой. Возник вопрос: каким способом обрабатывать переполненное поле смещения адреса? Рассматривая объекты, мы говорили, что они состоят из одного или нескольких несмежных сегментов, и что ни один сегмент не может содержать части более чем одного объекта. Очевидно, что смещение адреса за границу сегмента в следующий сегмент нежелательно, так как последний может относиться к другому объекту. Следовательно, такое смещение, например, адреса в пространственном указателе за пределы ассоциированного пространства объекта, надо предотвратить. Определяется такое переполнение адреса следующим способом: после каждого увеличения адреса проверяется, не было ли переноса из разрядов смещения в разряды идентификатора сегмента. Такой перенос и означает попытку обратиться к следующему сегменту.
Подобные ошибки переполнения могут легко отслеживаться аппаратно, для чего используется механизм прерываний[ 66 ]. Прерывания будут рассмотрены в главе 9, но одно из них мы обсудим прямо сейчас: переполнение эффективного адреса (ЕАО).
Разберем ситуацию, возникавшую в System/38 при переполнении 16-разрядного смещения. В этом случае аппаратура не увеличивала 32-разрядную сегментную часть адреса. Вместо этого об исключительной ситуации сообщалось VMC, который в каждом конкретном случае заново оценивалситуацию. VMC рассматривал сегменты, как имеющие длину 16 МБ и состоящие из 256 аппаратных сегментов меньшего размера, и поэтому переполнение 64-килобайтного сегмента в середине 16-мегабайтного сегмента переполнением не считал. С его точки зрения — представления адреса 24/ 24 — переполнением считался только перенос из младших 24 разрядов в старшие 24.
При каждом прерывании по ЕАО VMC увеличивал 32-разрядный аппаратный идентификатор сегмента, проверял, нет ли переноса в старшие 24 разряда, и если обнаруживал, что все в порядке, управление возвращалось аппаратуре. Таким образом, мы постоянно сталкивались с несовпадением схем 32/16 и 24/24.
Когда с течением времени ширина тракта данных процессора выросла с первоначальных 16 до 32, а затем до 48 разрядов, разделение регистров сегмента и смещения в аппаратуре стали менее важны. В IMPI-моделях AS/400 были добавлены команды для поддержки адреса 24/24, что исключило необходимость программной обработки переполнений. Однако в целях совместимости с оригинальным VMC, представление 32/ 16 было в IMPI сохранено.
Эта проблема с адресами была не единственной в оригинальном VMC. Он должен был поддерживать 64-разрядный адрес в указателе MI на аппаратуре с 48-разрядным адресом. Можно было бы попытаться рассматривать 64-разрядные адреса как виртуальные адреса большего размера, которые каким-то образом отображаются в меньшие 48-разрядные виртуальные адреса, но такое решение было отвергнуто. Вместо этого, старшие 16 разрядов 64-разрядного адреса стали рассматриваться как отдельное значение. Мы назвали это 16-разрядное поле расширением идентификатора сегмента, обозначив его номером IPL. При всякой перезагрузке системы номер IPL увеличивался на единицу, что каждый раз давало новое 48-разрядное адресное пространство. На рисунке 8.2 показаны поля, составляющие 64-разрядный адрес в указателе MI.
Техническим менеджером System/38 был Рей Клотц, не видевший надобности в таком большом адресе. Его многократно пытались уговорить, но Рей так и не поддался на уверения, что 64-разрядного адреса хватит навечно. В середине 70-х годов подразделение IBM по мэйнфреймам собиралось объявить о новом большом адресе для System/370, получившем название расширенной адресации (XA). С применением ХА адрес System/370 должен был вырасти с 24 до 31 разряда. Рей обвинял нас в желании непременно превзойти System/370 и утешал тем, что 32 разряда все равно больше чем 31. «Вы побьете их и одним разрядом, а больше и не надо», — как бы говорил он. Мы, в свою очередь, утверждали, что 32-разрядный адрес не будет работать с одноуровневой памятью System/38, и что нужны 64 разряда. Когда стало очевидным, что спор зашел в тупик, мы поступили так, как будто торговались о цене подержанной машины: поделили пополам разницу между 32 и 64. Таким образом, получился 48-разрядный адрес.
Для поддержки сегментированной памяти 48-разрядный адрес разделяется надвое. Старшие разряды задают сегмент, а младшие, называемые смещением — байт внутри сегмента. Мы решили использовать для задания сегмента старшие 32 разряда, а для смещения — младшие 16, назвав все это адресом 32/16. 16 разрядов смещения означали размер сегмента в 64 КБ (216 = 64 КБ).
Оригинальная аппаратура процессора System/38 имела 16-разрядный тракт данных и 16-разрядный сумматор для вычислений. Смысл использования адреса форматом 32/16 был в том, чтобы смещение адреса не выходило за размер тракта данных, так как очень часто обновлялось. Мы решили обрабатывать 32-разрядный идентификатор сегмента не в тракте данных процессора, а вне его, в отдельном наборе сегментных регистров. К этим сегментным регистрам был возможен доступ со стороны процессора, но они не могли обновляться «на месте».
Программисты, отвечавшие за ПО ОС ниже MI (первоначально VMC) не были согласны с такой адресацией (32/16), так как считали, что размер сегмента в 64 КБ слишком мал. Первоначально они предполагали создать сегментные группы, каждая из которых содержала бы один или несколько таких 64-килобайтных сегментов, но, в конце концов, решили, что сегментная группа всегда должна состоять из 256 сегментов. При выделении нового сегмента как части вновь создаваемого объекта его размер всегда будет равен 16 МБ (256 Г 64 КБ = 16 МБ). С этого момента мы говорили о 64-килобайтных и 16-мегабайтных сегментах, впрочем, называя иногда вторые сегментной группой. Этот разнобой в терминологии продолжался до появления процессоров PowerPC и SLIC. Если Вы возьмете в руки калькулятор или таблицу степеней двойки, то поймете, почему программисты VMC, имевшие дело с 16-мегабайтными сегментами, рассматривали 48-разрядный адрес как имеющий 24-разрядный идентификатор сегмента и 24-разрядное смещение (ведь 224 = 16 МБ).
Представление адреса 24/24, использовавшееся VMC, не совпадало с представлением 32/16, использовавшимся аппаратурой. Возник вопрос: каким способом обрабатывать переполненное поле смещения адреса? Рассматривая объекты, мы говорили, что они состоят из одного или нескольких несмежных сегментов, и что ни один сегмент не может содержать части более чем одного объекта. Очевидно, что смещение адреса за границу сегмента в следующий сегмент нежелательно, так как последний может относиться к другому объекту. Следовательно, такое смещение, например, адреса в пространственном указателе за пределы ассоциированного пространства объекта, надо предотвратить. Определяется такое переполнение адреса следующим способом: после каждого увеличения адреса проверяется, не было ли переноса из разрядов смещения в разряды идентификатора сегмента. Такой перенос и означает попытку обратиться к следующему сегменту.
Подобные ошибки переполнения могут легко отслеживаться аппаратно, для чего используется механизм прерываний[ 66 ]. Прерывания будут рассмотрены в главе 9, но одно из них мы обсудим прямо сейчас: переполнение эффективного адреса (ЕАО).
Разберем ситуацию, возникавшую в System/38 при переполнении 16-разрядного смещения. В этом случае аппаратура не увеличивала 32-разрядную сегментную часть адреса. Вместо этого об исключительной ситуации сообщалось VMC, который в каждом конкретном случае заново оценивалситуацию. VMC рассматривал сегменты, как имеющие длину 16 МБ и состоящие из 256 аппаратных сегментов меньшего размера, и поэтому переполнение 64-килобайтного сегмента в середине 16-мегабайтного сегмента переполнением не считал. С его точки зрения — представления адреса 24/ 24 — переполнением считался только перенос из младших 24 разрядов в старшие 24.
При каждом прерывании по ЕАО VMC увеличивал 32-разрядный аппаратный идентификатор сегмента, проверял, нет ли переноса в старшие 24 разряда, и если обнаруживал, что все в порядке, управление возвращалось аппаратуре. Таким образом, мы постоянно сталкивались с несовпадением схем 32/16 и 24/24.
Когда с течением времени ширина тракта данных процессора выросла с первоначальных 16 до 32, а затем до 48 разрядов, разделение регистров сегмента и смещения в аппаратуре стали менее важны. В IMPI-моделях AS/400 были добавлены команды для поддержки адреса 24/24, что исключило необходимость программной обработки переполнений. Однако в целях совместимости с оригинальным VMC, представление 32/ 16 было в IMPI сохранено.
Эта проблема с адресами была не единственной в оригинальном VMC. Он должен был поддерживать 64-разрядный адрес в указателе MI на аппаратуре с 48-разрядным адресом. Можно было бы попытаться рассматривать 64-разрядные адреса как виртуальные адреса большего размера, которые каким-то образом отображаются в меньшие 48-разрядные виртуальные адреса, но такое решение было отвергнуто. Вместо этого, старшие 16 разрядов 64-разрядного адреса стали рассматриваться как отдельное значение. Мы назвали это 16-разрядное поле расширением идентификатора сегмента, обозначив его номером IPL. При всякой перезагрузке системы номер IPL увеличивался на единицу, что каждый раз давало новое 48-разрядное адресное пространство. На рисунке 8.2 показаны поля, составляющие 64-разрядный адрес в указателе MI.
 Рисунок 8.2. Оригинальный формат адреса указателя MI
Рисунок 8.2. Оригинальный формат адреса указателя MI
Первоначально заголовок сегмента, описанный в главе 5, содержал поле с 16-разрядным расширением идентификатора этого сегмента. Когда программа MI пыталась использовать указатель на System/38 и на ранних моделях AS/400, для проверки битов тега и загрузки 48-разрядного адреса в процессорный регистр, использовалась специальная команда IMPI под названием «Загрузить и проверить теги» («lvt»). Команда «lvt» аналогична «lq» на RISC-процессорах, но у первой была дополнительная задача. Она должна была сравнить старшие 16 разрядов адреса в указателе с полем расширения идентификатора в заголовке сегмента и гарантировать их совпадение с адресом сегмента. После первого обращения для доступа к сегменту использовался только 48-разрядный адрес. Как уже говорилось, всякий раз при увеличении номера IPL мы получали новое адресное пространство для временных объектов. Временные объекты разрушаются при выполнении IPL, в отличие от постоянных, продолжающих существовать и после перезагрузки. Так как аппаратура использовала только 48 разрядов, один и тот же 48-разрядный адрес не мог быть задействован для постоянных объектов повторно, за исключением случая, когда постоянный объект по этому адресу был явно удален во время предыдущего сеанса работы ОС. Тогда от него оставались только заголовки, что обнаруживалось при первом использовании полного 64-разрядного адреса, начальные 16 разрядов которого содержат номер IPL. Так как номера IPL различались, то при повторном использовании 48-разрядного адреса конфликтов не возникало. Еще раз подчеркну, что заголовки сохраняются только при разрушении постоянных объектов — при разрушении временного объекта не остается ничего.

Переполнение адреса
Так как мы решили не использовать на System/38 48-разрядный адрес повторно до следующей перезагрузки, встал вопрос о том, что однажды все доступные адреса могут быть исчерпаны. В поисках ответа на него, мы провели некоторые интересные подсчеты. В соответствии с их результатами, если выполнять одну IPL в день 365 дней в году, то повторное использование номера IPL потребуется через 180 лет. Итак, опасности, что расширения идентификаторов сегментов будут повторяться, не существовало. Зная проектируемую производительность будущих процессоров, мы могли вычислить максимальное число 64-килобайтных сегментов, которое будет сгенерировано в интервале между ежедневными IPL. Эти расчеты также показали, что проблемы нет. И все же прогноз оказался неверным — некоторые большие AS/400 стали выходить за границы адресов[ 67 ]. Что же случилось? Во-первых, одна IPL в день — это неплохое допущение для ранних System/38, но после того как многие заказчики стали использовать свои компьютеры 24 часа в сутки, времени на перезагрузку не осталось. Кроме того, наши системы сильно увеличились в размерах, и время IPL стало слишком большим. С тех пор мы внесли существенные изменения в AS/400, что позволило сократить время IPL до нескольких минут. Но даже при этом одна IPL в день была неверным допущением. Второй ошибкой в вычислениях было предположение о 64-килобайтном сегменте. Используя представление адреса 24/24 оригинальный VMC всегда создавал 16-мегабайтные сегменты. Ситуация усугублялась тем, что компонент управления основной памятью в оригинальном VMC разделял полное 48-разрядное виртуальное адресное пространство на квадранты. Старшие два разряда адреса задавали квадрант в зависимости от назначения последнего. Один квадрант был зарезервирован для адресов постоянных объектов, так что у всех постоянных адресов два старших разряда были одинаковы. Другой квадрант был выделен адресам для временных объектов, третий — для адресов временных объектов групп доступа[ 68 ]. Так как постоянные объекты не могут входить в группу доступа, то четвертый квадрант не использовался. Такое решение было принято в предположении, что 48-разрядное адресное пространство настолько велико, что на одну его четверть можно безболезненно «закрыть глаза». Из 256 ТБ (248 байтов) виртуальной памяти, которыми мы так любили похваляться, 64 ТБ никогда не использовались в System/38 и первых моделях AS/400. Проблема, возникшая в некоторых больших системах AS/400, состояла в выходе за пределы диапазона временных адресов. Эта проблема получила название переполнения идентификатора сегмента, так как все идентификаторы сегментов, доступные в интервалах между перезагрузками, были использованы. При разделении адресного пространства на квадранты на каждую IPL приходилось лишь по 4 миллиона 16-мегабайтных временных сегментов. Вследствие этого, большие системы с приложениями, использовавшими много временных объектов, выходили за пределы диапазона временных идентификаторов сегментов, если не перегружались по несколько дней. С точки зрения пользователя, положение можно было исправить довольно просто — перезагрузить систему[ 69 ]. Но причин происшедшего это паллиативное решение не устраняло. 8первые версии ОС для AS/400 были внесены изменения, позволявшие уменьшить проблему переполнения адресов. Компоненты стали использовать 64-килобай-тные сегменты вместо 16-мегабайтных, везде, где было возможно. Был также задействован ранее выброшенный квадрант адресного пространства. Разумеется, эти изменения не решили проблему, но они позволили нам продержаться до появления новых RISC-процессоров. Проблема касалась и постоянных адресов. Их максимальное число ограничено объемом дискового пространства на подключенных к системе устройствах, поскольку даже удаленные объекты продолжают занимать некоторое место на диске. Мы ограничили общий объем дискового пространства, которое могло быть подключено к AS/ 400, чтобы пользователь не мог исчерпать постоянные адреса. Ведь выход за пределы постоянных адресов нельзя исправить с помощью IPL, здесь потребуется полная переустановка системы, что, разумеется, совершенно неприемлемо. Я потратил несколько разделов на описание структуры адресации System/38 и первых моделей AS/400, чтобы показать причины, заставившие IBM перейти на RISC-процессоры. Еще до выпуска первой AS/400 мы знали, что 48-разрядный адрес ограничивает будущий рост системы. По мере увеличения размеров и скорости работы, системы начинали использовать все больше временных адресов. Заказчики же хотели подключать все больший объем дисков. Нам потребовалось некоторое время, чтобы убедить руководство в невозможности использовать 48-разрядный адрес в будущих системах. В Рочестере всегда была популярна старая поговорка: «Не надо чинить то, что не ломается». И вот, наконец, мы убедили менеджеров, что то, что сломалось, сломалось безвозвратно. Хорошо еще то, что поломка случилась внутри системы. Независимость AS/400 от технологии защитила наших заказчиков. Если в вычислительной архитектуре изменяются адреса, то приходится менять и все остальное. Мы восприняли случившееся как шанс избавиться от IMPI и перейти на RISC. Наш первый RISC-процессор, который мы начали разрабатывать в 1990 году и назвали С-RISC («С» — обозначает коммерческий), имел 96-разрядный адрес. У нас появилось место для такого большого адреса в указателях, и мы не стали стесняться. Когда в 1991 году было принято решение использовать архитектуру PowerPC, размер адреса был сокращен до 64 разрядов.Трансляция адреса
Перед обращением в память виртуальный адрес в любой вычислительной системе должен быть транслирован в реальный. Ранее мы говорили, что в архитектуре PowerPC есть еще один уровень адресов, которые называются эффективными и используются программами. Эффективный адрес должен быть сначала транслирован в виртуальный, и только после этого — в реальный. В этом разделе мы рассмотрим, как выполняются эти трансляции. Приготовьтесь, некоторые детали могут показаться Вам слишком «острыми».Характеристики модели памяти
Мы уже познакомились с некоторыми характеристиками памяти AS/400. Приведем снова список этих характеристик вместе с другими, которые мы еще пока не рассматривали, но обязательно сделаем это. Размер страницы — 212 байта (4 Диапазон эффективных адресов — 264 байта: число эффективных сегментов — 240; размер эффективного сегмента — 224 байта (16 MБ). •Два специальных типа эффективных адресов, отменяющих трансляцию, для идентификации которых используются 12 старших разрядов (3 шестнадцатиричные цифры): 800h — эффективный=реальный (E=R) отображают всю реальную память, для них выделено 228 эффективных сегментов; 801h — эффективный=прямое-сохранение (E=DS) отображают пространство ввода-вывода, для них выделено 228 эффективных сегментов. •Диапазон виртуальных адресов — 264 байта: число виртуальных сегментов — 240 -229; размер виртуального сегмента — 224 байта (16 MБ). •Диапазон реальных адресов — 252 байта. Все характеристики приведены для используемого в AS/400 режима активных тегов 64-разрядных процессоров.
Все характеристики приведены для используемого в AS/400 режима активных тегов 64-разрядных процессоров.
Регистр состояния машины
Процесс трансляции адресов управляется режимом активных и неактивных тегов и состоянием процессора. Состояние процессора определяется специальным регистром, называемым регистром состояния машины MSR (Machine State Register). Разряды этого регистра управляют некоторыми операциями процессора, в том числе трансляцией адреса. В главе 9 мы рассмотрим этот регистр и способ изменения его разрядов. А пока, чтобы лучше понять трансляцию адреса, затронем лишь несколько разрядов MSR, а именно: •Разряд 64-разрядного режима (MSRSF): — процессор работает 32-разрядном режиме; — процессор работает 64-разрядном режиме. •Разряд перемещения команд (MSRIR): — трансляция адреса команды отключена; — трансляция адреса команды: включена. •Разряд перемещения данных (MSRDR): — трансляция адреса данных отключена; — трансляция адреса данных включена. •Разряд защиты C2 (MSRC2): — защита C2 отключена; — защита C2 включена. •Проблемное состояние (MSRPR): — процессор может исполнять любые команды; — процессор может исполнять только непривилегированные команды. •Пользовательское состояние (MSRUS): — исполняется код ОС; — исполняется пользовательский код. Для определения размера адреса в процессе его трансляции используется разряд 64-разрядного режима (MSRSF). Например, в 32-разрядном режиме архитектура PowerPC определяет, что эффективный адрес имеет длину лишь 32 разряда. В режиме активных тегов процессоров AS/400 аппаратура поддерживает только 64-разрядный режим. Таким образом, SLIC, управляющий значениями разрядов MSR, будет устанавливать только 64-разрядный режим. Разряды перемещения команд (MSRIR) и данных (MSRDR) позволяют процессору работать в режиме реальной адресации. Когда SLIC отключает перемещение, механизмы трансляции адреса не используются, и младшие 52 разряда эффективного адреса передаются как реальный адрес непосредственно подсистеме памяти. Подсистема памяти состоит из памятей кэша и основной. В архитектуре PowerPC для команд и данных — раздельные кэши, и соответственно отдельные разряды перемещения. Такая модель называется гарвардским кэшем[ 70 ]. Первоначально бит защиты С2 (MSRC2) предназначался для того, чтобы вынуждать механизм трансляции адреса использовать сегментные регистры для всех пользовательских обращений, если процессор работает в режиме активных тегов и защита С2 включена. Использование системных таблиц гарантировало, что при включенной защите С2 ОС может контролировать и регистрировать доступ пользователей к любым объектам. Хотя данный разряд по-прежнему присутствует в некоторых процессорах PowerPC, он не используется для аудита С2. Вместо этого на уровне защиты 50 (защита С2) мониторинг и регистрацию пользовательского доступа компонент защиты SLIC осуществляет непосредственно, без использования сегментных регистров. Разряд проблемного состояния (MSRPR) используется в процессе трансляции адреса и для защиты памяти. Он определяет, может ли процессор исполнять привилегированные команды PowerPC. Не следует путать эти привилегированные команды с привилегированными командами MI (такими как «PWRDWNSYS,» с которой мы встречались в главе 7) — привилегированные команды PowerPC исполняет только SLIC. Примером привилегированных команд PowerPC могут служить команды работы с тегами, например «lq». Разряд пользовательского состояния (MSRUS) поддерживает уровни защиты AS/ 400 от 40 и выше. Он позволяет различать системное и пользовательское состояние процесса. Разряд пользовательского состояния определяет, могут ли полномочия быть помещены в указатель, и может ли процесс выполнять привилегированные команды MI. Данный разряд используется также для защиты памяти. Обратите внимание, что разряд пользовательского состояния также задействован только в режиме активных тегов.
Обзор трансляции адреса
На рисунке 8.3 показана трансляция адреса PowerPC в режиме активных тегов. Аппаратура определяет, является ли 64-разрядный адрес, используемый программой, транслируемым адресом, адресом E = R или адресом E = DS. Для классификации используются старшие 12 разрядов (3 шестнадцатиричные цифры) эффективного адреса. Если эти три старшие цифры равны 800, то это адрес E = R. Некоторые компоненты SLIC, которым нужен доступ ко всем частям памяти, работают с реальными адресами, как и большая часть кода управления памятью. Часть пространства эффективных адресов зарезервирована для адресов E = R. Не случайно именно 252 этих адресов (64 разряда — 12 старших разрядов для 800 = 252) соответствуют диапазону реальных адресов. Рисунок 8.3. Трансляция адреса в режиме активных тегов
Рисунок 8.3. Трансляция адреса в режиме активных тегов
Когда аппаратура обнаруживает адрес E=R, она проверяет разряд проблемного состояния, чтобы определить, может ли процесс, сгенерировавший такой адрес, выполнять привилегированные команды: PowerPC (MSRPR = 0). Если это так, то остальные 52 разряда адреса E=R передаются непосредственно основной памяти как реальный адрес. Если MSRPR = 1, то в зависимости от версии процессора, он будет либо генерировать прерывание, либо рассматривать адрес как транслируемый — разные процессоры PowerPC реагируют по-разному. Если использование адреса E=R допустимо, то накладных расходов при трансляции адреса не возникает. Мы любим говорить, что число 800 — ключ, открывающий бесплатный доступ к памяти. Для доступа к пространству ввода-вывода, которое мы кратко обсудили в главе 2, в архитектуре PowerPC используется диапазон адресов, называемых адресами прямого сохранения. Это внешнее адресное пространство, которое для процессора выглядит как часть памяти. На самом деле, оно, конечно, таковым не является; эти адреса используются для обозначения подключенных к системе устройств ввода-вывода. Обычно, устройства в любой системе подключены к шине ввода-вывода. В главе 10 мы расскажем, что устройства AS/400 подключены к процессорам ввода-вывода, которые, в свою очередь, подключены к шинам ввода-вывода. Таким образом, адрес прямого сохранения используется в AS/400 для идентификации как шины ввода-вывода, так и подключенного к ней процессора ввода-вывода. В архитектурах данного типа, которые часто называют вводом-выводом, отображенным в память, специальный набор команд процессора для работы с устройствами не требуется. Взамен для передачи команд и данных применяют любые команды загрузки или сохранения в это внешнее адресное пространство. Если старшие три шестнадцатиричные цифры эффективного адреса равны 801, то это адрес E = DS. Обнаружив этот адрес, аппаратура проверяет разряд проблемного состояния, чтобы определить, может ли процесс, сгенерировавший адрес, выполнять привилегированные команды PowerPC (MSRPR= 0). Если это так, то остальные 52 разряда адреса E = DS передаются непосредственно пространству ввода-вывода. Как и адреса E = R, адреса E = DS имеют 228 эффективных сегмента. Если MSRPR = 1, то в зависимости от версии процессора, он будет либо генерировать прерывание, либо рассматривать адрес как транслируемый. Если три старшие шестнадцатиричные цифры не равны ни 800, ни 801, то это транслируемый адрес. Так как система находится в режиме активных тегов, то эффективный адрес является виртуальным. Для трансляции виртуального адреса в реальный используется таблица страниц.
 Рисунок 8.4. Этапы трансляции адреса (режим активных тегов)
Рисунок 8.4. Этапы трансляции адреса (режим активных тегов)
На рисунке 8.4 представлены этапы трансляции адреса в режиме активных тегов. Старшие 40 разрядов эффективного адреса называются идентификатором эффективного сегмента (ESID), а младшие 24 — смещением. Как показано на рисунке, смещение подразделяется на страничное и байтовое. Каждое из полей смещения имеет длину 12 разрядов. Страничное смещение задает страницу сегмента, а байтовое — байт страницы. Первый шаг процесса трансляции — создание идентификатора виртуального сегмента (VSID). В режиме активных тегов это просто ESID. Виртуальный адрес, как и эффективный, имеет размер 64 разряда и включает 24-разрядное смещение. VSID и страничное смещение виртуального адреса составляют номер виртуальной страницы (VPN). На рисунке 8.4 видно, что VPN имеет длину 52 разряда. VPN используется для определения номера реальной страницы (RPN) по таблице страниц. RPN — это номер страничного фрейма в памяти, а не номер страницы на диске. Байтовое смещение всегда передается от эффективного адреса виртуальному и затем реальному без изменений. Оно задает байт на 4-килобайтной странице и никогда не участвует в процессе трансляции. Для сравнения на рисунке 8.5 показаны этапы трансляции адреса в режиме неактивных тегов. Данный механизм трансляции не используется в AS/400, но все же полезно представлять себе как сходство, так и различие трансляции адреса в AS/400 и в таких ОС, как AIX. В данном случае, ESID используется для обращения к таблице сегментов, из которой извлекается VSID. Обращение к таблице страниц, которое мы скоро рассмотрим, в режимах активных и неактивных тегов выполняется одинаково. Следует также отметить размер полей адреса. В режиме неактивных тегов порции смещения (поля страницы и байта) эффективного и виртуального адреса равны 28 разрядам, в режиме активных тегов — 24. 28 разрядов были выбраны в соответствии с числом разрядов смещения в прежней 32-разрядной архитектуре Power и по-прежнему используются на некоторых процессорах RS/6000.
 Рисунок 8.5. Этапы трансляции адреса (режим неактивных тегов)
Рисунок 8.5. Этапы трансляции адреса (режим неактивных тегов)
Мы не станем подробно рассматривать таблицу сегментов и сосредоточим свое внимание на таблице страниц. Ее реализация очень похожа на реализацию таблицы сегментов, где для поиска записи применяется тот же общий подход. В AS/400 трансляция виртуального адреса в реальный, использующая таблицу страниц, более важна, чем трансляция сегментов, так как большинство эффективных адресов обходят таблицу сегментов.
Трансляция адреса виртуальный—реальный
 Таблица страниц — структура данных в памяти, содержащая RPN. При построении таблицы страниц в большинстве отличных от AS/400 реализаций виртуальной памяти, каждой странице виртуальной памяти соответствует одна запись в таблице. Номер виртуальной страницы — VPN — используется как индекс в таблице страниц для выбора одной из записей. Выбранная запись содержит номер реальной страницы — RPN, который затем становится частью реального адреса.
Описанная структура страничных таблиц используется многими системами, например System/370. Предположим, что у нас есть компьютер с 32-разрядным виртуальным адресом и 4-килобайтной страницей. Размер VPN для этого адреса — 20 разрядов. Если далее предположить, что одна запись страничной таблицы занимает 4 байта, то размер всей таблицы составит 4 МБ. Такая таблица очень велика, но все-таки приемлема для систем с большими объемами памяти. Однако, если виртуальный адрес больше 32 разрядов (48 или 64), то размер обычной страничной таблицы становится неприемлемо большим.
System/38 была первой из массовых вычислительных систем, где использовалась инвертированная таблица страниц. В такой таблице содержится по одной записи на каждую реальную страницу (страничный фрейм) памяти, а не на каждую виртуальную страницу памяти, расположенную на диске. Общий размер такой инвертированной таблицы прямо зависит от размера памяти. Чем больше память, тем больше размер таблицы, но доля памяти, занятая таблицей остается неизменной.
Самое сложное в инвертированной таблице страниц — нахождение нужной записи. Теперь нельзя напрямую использовать VPN как индекс в таблице, так как нет однозначного соответствия между VPN и записью таблицы. Необходим какой-то иной способ. Прием, используемый в AS/400, заключается в применении к VNP для определения записи страничной таблицы хеш-функции.
Таблица страниц — структура данных в памяти, содержащая RPN. При построении таблицы страниц в большинстве отличных от AS/400 реализаций виртуальной памяти, каждой странице виртуальной памяти соответствует одна запись в таблице. Номер виртуальной страницы — VPN — используется как индекс в таблице страниц для выбора одной из записей. Выбранная запись содержит номер реальной страницы — RPN, который затем становится частью реального адреса.
Описанная структура страничных таблиц используется многими системами, например System/370. Предположим, что у нас есть компьютер с 32-разрядным виртуальным адресом и 4-килобайтной страницей. Размер VPN для этого адреса — 20 разрядов. Если далее предположить, что одна запись страничной таблицы занимает 4 байта, то размер всей таблицы составит 4 МБ. Такая таблица очень велика, но все-таки приемлема для систем с большими объемами памяти. Однако, если виртуальный адрес больше 32 разрядов (48 или 64), то размер обычной страничной таблицы становится неприемлемо большим.
System/38 была первой из массовых вычислительных систем, где использовалась инвертированная таблица страниц. В такой таблице содержится по одной записи на каждую реальную страницу (страничный фрейм) памяти, а не на каждую виртуальную страницу памяти, расположенную на диске. Общий размер такой инвертированной таблицы прямо зависит от размера памяти. Чем больше память, тем больше размер таблицы, но доля памяти, занятая таблицей остается неизменной.
Самое сложное в инвертированной таблице страниц — нахождение нужной записи. Теперь нельзя напрямую использовать VPN как индекс в таблице, так как нет однозначного соответствия между VPN и записью таблицы. Необходим какой-то иной способ. Прием, используемый в AS/400, заключается в применении к VNP для определения записи страничной таблицы хеш-функции.
Хеширование
 Хеширование всегда было концепцией, трудной для объяснения. Хеш-функция AS/ 400 сначала выполняет над несколькими старшими и младшими разрядами VPN операцию «Исключающее или». Затем между полученным значением и разрядами маски из специального регистра, содержащего размер страничной таблицы, выполняется операция «И». Наконец, для результата и реального адреса страничной таблицы выполняется операция «Или», которая и дает 52-разрядный реальный адрес в страничной таблице. Очень мало людей по-настоящему понимает, зачем и как работает хеш-функция. Тем не менее, желающих проникнуть в ее секреты всегда было достаточно.
Несколько лет назад, раздумывая нет тем, как объяснить хеширование раз-вв" работчикам System/38, я бродил по магазину Sears в Рочестере. Чуть раньше ш я отправил заказ в отдел продаж по каталогу и хотел узнать, был ли он полу-
чен. Когда я поинтересовался об этом в столе заказов, у меня спросили две последние цифры моего телефона. Я назвал: «83». На стене за спиной служа-
щего располагалось сто отделений, пронумерованных от 00 до 99. Работник магазина вытащил стопку бумаги из отделения 83 и начал искать мой заказ. После того как заказ был найден, мне сказали, что выписанный товар еще не
получен. Я немедленно выпалил в ответ: «У Вас только что произошла страничная ошибка». Сотрудник Sears ничего не понял и был несколько удивлен. Зато я внезапно осознал, как объяснить хеширование.
Sears использовал хеш-функцию для отслеживания полученных заказов, точно так же, как мы отслеживаем, какие страницы находятся в памяти. Было решено уникально идентифицировать клиента по имени и номеру телефона. Вместо того, чтобы хранить запись о каждом клиенте, который мог бы сделать заказ, компания решила хранить записи только о тех клиентах, которые сделали заказ, но еще не забрали его. Для ускорения поиска сотрудник выбрал только часть полной идентификации клиента — две последние цифры телефонного номера. Таким образом, все сделанные заказы были отсортированы по этим двум последним цифрам. Чтобы получить информацию о выполнении заказа, необходимо было в поисках имени заказчика просмотреть лишь одно из 100 отделений.
Функция, использовавшаяся Sears (выбор двух последних цифр телефонного номера), давала достаточно равномерное распределение заказов по ста отделениям, то есть для поиска в каждом из отделений требовалось примерно одинаковое количество времени. Если бы, например, Sears использовал первые две цифры телефонного номера, то некоторые отделения были бы просто забиты, а остальные — пусты (почти в каждой местности большинство телефонов начинается одинаково), так что выбор первых двух цифр дал бы плохое распределение. Аналогично, комбинация операций, используемых для создания хеш-кода в AS/400, гарантирует равномерное распределение по «отделениям» таблицы страниц.
В AS/400 эквивалент отделения Sears — группа записей страничной таблицы (PTEG). Каждая PTEG содержит восемь записей таблицы (PTE). Алгоритм хеширования определяет одну из таких PTEG. Затем, необходимо просмотреть восемь записей группы, чтобы найти VPN, совпадающий с VPN транслируемого виртуального адреса. Данный поиск необходим, так как на одну и ту же PTEG отображается много виртуальных адресов. Аналогичная ситуация в Sears — одни и те же две цифры могут быть последними в телефонных номерах нескольких клиентов. Номер отделения говорит лишь о том, что все заказы в данном отделении принадлежат людям, телефонные номера которых заканчиваются на две эти цифры. Для того чтобы найти заказ конкретного клиента, необходимо просмотреть все заказы в отделении.
Число сделанных, но не полученных клиентами заказов может изменяться в течение дня, и Sears пришлось это учесть. Они использовали фиксированное число отделений с переменным числом записей в каждом. AS/400 тоже использует фиксированное число отделений, но как мы только что видели, число записей в отделении также фиксировано. Данный VPN может быть, а может и не быть найден в одном из восьми PTE. Если число записей не умещается в PTEG, то используется вторичная таблица страниц, которая содержит переменное число записей.
В большинстве реализаций AS/400 количество PTEG равно, как минимум, половине общего количества реальных страниц памяти. Учитывая, что в каждой PTEG 8 записей, таблица данного размера способна отображать в четыре раза больше страниц, чем может поместиться в память. Другими словами, среднее число используемых PTE на PTEG равно лишь двум. Это среднее значение подразумевает, что функция хеширования обеспечивает равномерное распределение по всем PTEG. Впрочем, могут возникнуть и ситуации, когда на одну или несколько PTEG будет приходиться более восьми записей. В таких случаях, дополнительные записи хранятся во вторичной таблице страниц. Представьте себе, что одно из отделений Sears слишком переполнено, и все заказы в нем не помещаются. Тогда некоторые из заказов необходимо хранить не в отделении, а где-то еще. Это «где-то еще» и есть эквивалент вторичной таблицы страниц.
В AS/400 если PTE не найдена ни в первичной, ни во вторичной таблице страниц, значит в памяти ее нет, и мы имеем дело со страничной ошибкой. Компонент управления памятью SLIC должен обратиться к диску и перенести запрошенную страницу в память. Необходимо также обновить таблицу страниц, чтобы отразить присутствие новой страницы в памяти. Конечно, для освобождения места под новую страницу компонент управления памятью должен удалить какую-то другую страницу.
Следующие три раздела содержат по-настоящему «острую» информацию, так что я пометил их тремя перцами.
В первом рассматривается процесс трансляции виртуального адреса в реальный и использование для этого записей таблицы страниц. Этот раздел предназначается тем читателей, которые любят «играть» с битами.
Следующий раздел описывает, как SLIC или транслятор могут управлять доступом к памяти каждой страницы. Такое управление требуется многоканальным RISC-процессорам с многоуровневой памятью, выполняющим операции с памятью не в том порядке, в какой они следуют в потоке команд. В архитектуре PowerPC имеется четыре бита управления режимами, которые могут использоваться программами, и я кратко опишу их, несмотря на то, что тема может показаться очень сложной.
Наконец, третий раздел касается защиты доступа к странице. Каждая страница может рассматриваться как страница чтения/записи, страница только для чтения или недоступная страница, в зависимости от текущего состояния процессора и ключей защиты в таблице сегментов и страничной таблице. Это тема также крайне сложна.
Итак, если Вам хочется чего-то более «острого», чем предыдущие несколько разделов. то попробуйте один из следующих трех или их все.
Хеширование всегда было концепцией, трудной для объяснения. Хеш-функция AS/ 400 сначала выполняет над несколькими старшими и младшими разрядами VPN операцию «Исключающее или». Затем между полученным значением и разрядами маски из специального регистра, содержащего размер страничной таблицы, выполняется операция «И». Наконец, для результата и реального адреса страничной таблицы выполняется операция «Или», которая и дает 52-разрядный реальный адрес в страничной таблице. Очень мало людей по-настоящему понимает, зачем и как работает хеш-функция. Тем не менее, желающих проникнуть в ее секреты всегда было достаточно.
Несколько лет назад, раздумывая нет тем, как объяснить хеширование раз-вв" работчикам System/38, я бродил по магазину Sears в Рочестере. Чуть раньше ш я отправил заказ в отдел продаж по каталогу и хотел узнать, был ли он полу-
чен. Когда я поинтересовался об этом в столе заказов, у меня спросили две последние цифры моего телефона. Я назвал: «83». На стене за спиной служа-
щего располагалось сто отделений, пронумерованных от 00 до 99. Работник магазина вытащил стопку бумаги из отделения 83 и начал искать мой заказ. После того как заказ был найден, мне сказали, что выписанный товар еще не
получен. Я немедленно выпалил в ответ: «У Вас только что произошла страничная ошибка». Сотрудник Sears ничего не понял и был несколько удивлен. Зато я внезапно осознал, как объяснить хеширование.
Sears использовал хеш-функцию для отслеживания полученных заказов, точно так же, как мы отслеживаем, какие страницы находятся в памяти. Было решено уникально идентифицировать клиента по имени и номеру телефона. Вместо того, чтобы хранить запись о каждом клиенте, который мог бы сделать заказ, компания решила хранить записи только о тех клиентах, которые сделали заказ, но еще не забрали его. Для ускорения поиска сотрудник выбрал только часть полной идентификации клиента — две последние цифры телефонного номера. Таким образом, все сделанные заказы были отсортированы по этим двум последним цифрам. Чтобы получить информацию о выполнении заказа, необходимо было в поисках имени заказчика просмотреть лишь одно из 100 отделений.
Функция, использовавшаяся Sears (выбор двух последних цифр телефонного номера), давала достаточно равномерное распределение заказов по ста отделениям, то есть для поиска в каждом из отделений требовалось примерно одинаковое количество времени. Если бы, например, Sears использовал первые две цифры телефонного номера, то некоторые отделения были бы просто забиты, а остальные — пусты (почти в каждой местности большинство телефонов начинается одинаково), так что выбор первых двух цифр дал бы плохое распределение. Аналогично, комбинация операций, используемых для создания хеш-кода в AS/400, гарантирует равномерное распределение по «отделениям» таблицы страниц.
В AS/400 эквивалент отделения Sears — группа записей страничной таблицы (PTEG). Каждая PTEG содержит восемь записей таблицы (PTE). Алгоритм хеширования определяет одну из таких PTEG. Затем, необходимо просмотреть восемь записей группы, чтобы найти VPN, совпадающий с VPN транслируемого виртуального адреса. Данный поиск необходим, так как на одну и ту же PTEG отображается много виртуальных адресов. Аналогичная ситуация в Sears — одни и те же две цифры могут быть последними в телефонных номерах нескольких клиентов. Номер отделения говорит лишь о том, что все заказы в данном отделении принадлежат людям, телефонные номера которых заканчиваются на две эти цифры. Для того чтобы найти заказ конкретного клиента, необходимо просмотреть все заказы в отделении.
Число сделанных, но не полученных клиентами заказов может изменяться в течение дня, и Sears пришлось это учесть. Они использовали фиксированное число отделений с переменным числом записей в каждом. AS/400 тоже использует фиксированное число отделений, но как мы только что видели, число записей в отделении также фиксировано. Данный VPN может быть, а может и не быть найден в одном из восьми PTE. Если число записей не умещается в PTEG, то используется вторичная таблица страниц, которая содержит переменное число записей.
В большинстве реализаций AS/400 количество PTEG равно, как минимум, половине общего количества реальных страниц памяти. Учитывая, что в каждой PTEG 8 записей, таблица данного размера способна отображать в четыре раза больше страниц, чем может поместиться в память. Другими словами, среднее число используемых PTE на PTEG равно лишь двум. Это среднее значение подразумевает, что функция хеширования обеспечивает равномерное распределение по всем PTEG. Впрочем, могут возникнуть и ситуации, когда на одну или несколько PTEG будет приходиться более восьми записей. В таких случаях, дополнительные записи хранятся во вторичной таблице страниц. Представьте себе, что одно из отделений Sears слишком переполнено, и все заказы в нем не помещаются. Тогда некоторые из заказов необходимо хранить не в отделении, а где-то еще. Это «где-то еще» и есть эквивалент вторичной таблицы страниц.
В AS/400 если PTE не найдена ни в первичной, ни во вторичной таблице страниц, значит в памяти ее нет, и мы имеем дело со страничной ошибкой. Компонент управления памятью SLIC должен обратиться к диску и перенести запрошенную страницу в память. Необходимо также обновить таблицу страниц, чтобы отразить присутствие новой страницы в памяти. Конечно, для освобождения места под новую страницу компонент управления памятью должен удалить какую-то другую страницу.
Следующие три раздела содержат по-настоящему «острую» информацию, так что я пометил их тремя перцами.
В первом рассматривается процесс трансляции виртуального адреса в реальный и использование для этого записей таблицы страниц. Этот раздел предназначается тем читателей, которые любят «играть» с битами.
Следующий раздел описывает, как SLIC или транслятор могут управлять доступом к памяти каждой страницы. Такое управление требуется многоканальным RISC-процессорам с многоуровневой памятью, выполняющим операции с памятью не в том порядке, в какой они следуют в потоке команд. В архитектуре PowerPC имеется четыре бита управления режимами, которые могут использоваться программами, и я кратко опишу их, несмотря на то, что тема может показаться очень сложной.
Наконец, третий раздел касается защиты доступа к странице. Каждая страница может рассматриваться как страница чтения/записи, страница только для чтения или недоступная страница, в зависимости от текущего состояния процессора и ключей защиты в таблице сегментов и страничной таблице. Это тема также крайне сложна.
Итак, если Вам хочется чего-то более «острого», чем предыдущие несколько разделов. то попробуйте один из следующих трех или их все.
Запись страничной таблицы
 Каждая PTE занимает 16 байтов, как показано на рисунке 8.6. Первое поле каждой записи состоит из 57 разрядов и называется сокращенным номером виртуальной таблицы AVPN (abbreviated virtual page number). Внимательные читатели помнят по рисунку 8.4, что полный VPN содержит только 52 разряда. Как же сокращенная форма может быть длиннее? Дело в том, что архитектура PowerPC разработана для поддержки виртуальных адресов длиной до 80 разрядов. Для 80-разрядного виртуального адреса VPN должен состоять из 68 разрядов, так что 57 разрядов — это действительно сокращенная форма. AVPN может использоваться вместо полного VPN, так как, по крайней мере, 11 младших разрядов VPN применяются хеш-функцией и их повторения не требуется. Вспомните пример с магазином: Sears не был обязан включать последние две цифры номера телефона клиента в форму заказа, так как эти цифры используются хеш-функцией и их не нужно заново проверять при поиске. AVPN для 64-разрядного виртуального адреса в AS/400 составляет лишь 41 разряд, а его старшие 16 разрядов установлены в 0.
Каждая PTE занимает 16 байтов, как показано на рисунке 8.6. Первое поле каждой записи состоит из 57 разрядов и называется сокращенным номером виртуальной таблицы AVPN (abbreviated virtual page number). Внимательные читатели помнят по рисунку 8.4, что полный VPN содержит только 52 разряда. Как же сокращенная форма может быть длиннее? Дело в том, что архитектура PowerPC разработана для поддержки виртуальных адресов длиной до 80 разрядов. Для 80-разрядного виртуального адреса VPN должен состоять из 68 разрядов, так что 57 разрядов — это действительно сокращенная форма. AVPN может использоваться вместо полного VPN, так как, по крайней мере, 11 младших разрядов VPN применяются хеш-функцией и их повторения не требуется. Вспомните пример с магазином: Sears не был обязан включать последние две цифры номера телефона клиента в форму заказа, так как эти цифры используются хеш-функцией и их не нужно заново проверять при поиске. AVPN для 64-разрядного виртуального адреса в AS/400 составляет лишь 41 разряд, а его старшие 16 разрядов установлены в 0.
 Рисунок 8.6. Формат записи страничной таблицы
Рисунок 8.6. Формат записи страничной таблицы
Все PTE в PTEG последовательно просматриваются для сравнения VPN с виртуальным адресом. Если в одной из PTE обнаружен нужный AVPN и разряд действительности установлен (V=1), то 40-разрядный RPN из этой записи передается аппаратуре адресации памяти, где к нему присоединяется 12-разрядное смещение для получения реального адреса. Другие биты PTE предоставляют дополнительную информацию о странице. Биты SW зарезервированы для использования компонентом управления памятью SLIC. Бит H определяет, находится ли данная запись в первичной или во вторичной страничной таблице страниц, которые используют несколько различающиеся хеш-функции. Бит TS задает, содержит ли данная страница указатели и, таким образом, имеет некоторые биты тега равными 1. Бит AC, если он включен, приводит в действие механизм сравнения адреса, который позволяет обнаруживать загрузки и сохранения в блок памяти. Аппаратура устанавливает биты R и C в 1 всякий раз при обращении к данной странице (бит R) или при ее изменении (бит C). Оставшиеся биты имеют отношение к режимам доступа и защите страницы (мы рассмотрим их несколько позже). Следует несколько задержаться на битах R и С. Управление памятью использует их значения для определения страницы, которую следует удалить из памяти, когда возникает страничная ошибка и в память необходимо считать новую страницу. Управление памятью также использует эти разряды: всякий раз, когда другой компонент SLIC или транслированная программа MI запрашивает операции переноса, очистки или сброса. Для ускорения поиска кандидата на замещение, управление памятью поддерживает «список поиска» всех страничных фреймов, которые могут быть замещены. При страничной ошибке (или при выполнении операций переноса и очистки) управление памятью вначале ищет в этом списке страничный фрейм, для которого оба бита R и С равны 0. Данная комбинация означает, что в недавнем прошлом страница не использовалась и не была изменена — значит, это лучший кандидат на замещение. После замещения страницы все биты R устанавливаются в значение 0. Таким образом, биты R позволяют определить, к каким страницам происходило обращение после последнего замещения страницы. Для тех страниц, которые не использовались недавно, значения R равны 0. Если алгоритм замещения страницы в процессе просмотра списка поиска обнаруживает страничный фрейм, который был изменен, но давно не использовался (R=0, C=1), то такой фрейм помещается в «список изменений». Когда в этом списке набирается достаточное число страниц, запускаются одна или несколько задач откачки страниц. Страницы записываются на диск и возвращаются в список поиска (с С равным 0), где становятся кандидатами на замещение, если будут снова востребованы. Откачка страниц предотвращает заполнение памяти измененными страницами, к которым давно не было обращений. Ясно, что поиск по таблице страниц занимает много времени — настолько много, что выполнять его при каждом обращении к памяти слишком накладно. По счастью, если страница недавно была востребована, велика вероятность, что в ближайшем будущем обращение к ней последует снова. Этот принцип лежит в основе использования справочных буферов: если Вы хотите снова использовать данную запись таблицы страниц, храните ее в регистре, чтобы обращение к ней происходило быстро. Для высокой производительности аппаратно поддерживается справочный буфер трансляции (TLB), содержащий PTE, использованные недавно. Поиск в TLB выполняется перед поиском в таблице страниц. Время поиска в TLB очень мало по сравнению с временем поиска в таблице страниц. Обычно, размер TLB достаточно велик, с расчетом, чтобы не менее 95 процентов трансляций выполнялось без необходимости обращения к таблице страниц.
Режимы доступа к памяти
 Все обращения к памяти в AS/400 выполняются под управлением четырех битов режима: «Сквозная запись» W (Write Through), «Кэширование запрещено» I (Caching Inhibited), «Когерентность памяти» M (Memory Coherence ) и «Отслеживаемая память» G (Guarded Storage). Одна из характеристик RISC-процессоров — способность программ контролировать аппаратуру. Значения этих четырех разрядов устанавливаются SLIC для обеспечения части такого контроля на уровне страниц. При всех транслируемых обращениях значения разрядов берутся из PTE. Для всех реальных адресов (E=R или при отключенном перемещении) подразумевается, что биты имеют значения 0, 0, 1 и 1. Биты W и I управляют тем, как процессор использует свой кэш данных. Бит M (обычно используется на многопроцессорных системах) задает, должен ли процессор гарантировать когерентность памяти. Бит G контролирует выборку данных и команд вне порядка их следования.
Приведем некоторую дополнительную информацию о назначении каждого из этих разрядов:
1.W (Write Through)— сквозная запись.
Если W=1, то любое изменение кэша данных записывается и в основную память. Этот разряд устанавливается, если данные в основной памяти должны быть постоянно в актуальном состоянии, например, потому что они используются несколькими процессорами. Команды загрузки будут использовать копию данных из кэша, если она там есть. При сохранении будут обновляться копии в кэше и основной памяти.
2.I (Caching Inhibited)— кэширование запрещено.
Если I=1, то доступ выполняется непосредственно к основной памяти. Во время обращения ни данные по этому адресу, ни содержащий их блок памяти не копируются в кэш. Отключение кэширования может быть полезно при последовательной обработке больших блоков данных, которая иначе будет вызывать постоянную смену содержимого кэша.
3.M (Memory Coherence) — когерентность памяти.
Если M=1, то процессор должен гарантированно обеспечивать когерентность данных. Под когерентностью понимают упорядочение операций записи по данному адресу памяти. Дело в том, что для повышения производительности аппаратура управления памятью иногда может записывать данные в память не в том порядке, в котором процессор выдает команды сохранения. Такой механизм может вызвать проблемы, если область памяти совместно используется несколькими процессорами и порядок операций записи в данную область памяти важен. Установка данного бита для страницы упорядочивает операции записи в эту страницу, выполняемые всеми процессорами.
4.G (Guarded Storage) — отслеживаемая память.
Если G=1, то выборка данных и команд вне порядка их следования с данной страницы запрещена. Для более высокой производительности некоторые процессоры могут выполнять команду до того, как это потребуется при последовательном выполнении. Предположим, например, что у некоторого процессора имеется конвейер команд, не занятый в течение данного цикла. Если далее в потоке команд есть подходящая для конвейера, то процессор начнет ее выполнять. Это называется выполнением вне порядка следования. Конечно, машина должна вести себя в соответствии с моделью последовательного выполнения. Если до того момента, когда процессор в нормальном случае дошел бы до команды, выполненной вне порядка следования, происходит переход или прерывание, то состояние процессора должно быть восстановлено так, как если бы он никогда не выполнял эту команду. Иногда поведение области памяти может не соответствовать модели опережающего выполнения. Например, если область памяти используется устройством ввода-вывода, то опережающая запись в нее может вызвать выполнение ошибочной операции. Если SLIC необходимо гарантировать, что подобного не произойдет, то для соответствующей страницы можно включить бит G.
Все обращения к памяти в AS/400 выполняются под управлением четырех битов режима: «Сквозная запись» W (Write Through), «Кэширование запрещено» I (Caching Inhibited), «Когерентность памяти» M (Memory Coherence ) и «Отслеживаемая память» G (Guarded Storage). Одна из характеристик RISC-процессоров — способность программ контролировать аппаратуру. Значения этих четырех разрядов устанавливаются SLIC для обеспечения части такого контроля на уровне страниц. При всех транслируемых обращениях значения разрядов берутся из PTE. Для всех реальных адресов (E=R или при отключенном перемещении) подразумевается, что биты имеют значения 0, 0, 1 и 1. Биты W и I управляют тем, как процессор использует свой кэш данных. Бит M (обычно используется на многопроцессорных системах) задает, должен ли процессор гарантировать когерентность памяти. Бит G контролирует выборку данных и команд вне порядка их следования.
Приведем некоторую дополнительную информацию о назначении каждого из этих разрядов:
1.W (Write Through)— сквозная запись.
Если W=1, то любое изменение кэша данных записывается и в основную память. Этот разряд устанавливается, если данные в основной памяти должны быть постоянно в актуальном состоянии, например, потому что они используются несколькими процессорами. Команды загрузки будут использовать копию данных из кэша, если она там есть. При сохранении будут обновляться копии в кэше и основной памяти.
2.I (Caching Inhibited)— кэширование запрещено.
Если I=1, то доступ выполняется непосредственно к основной памяти. Во время обращения ни данные по этому адресу, ни содержащий их блок памяти не копируются в кэш. Отключение кэширования может быть полезно при последовательной обработке больших блоков данных, которая иначе будет вызывать постоянную смену содержимого кэша.
3.M (Memory Coherence) — когерентность памяти.
Если M=1, то процессор должен гарантированно обеспечивать когерентность данных. Под когерентностью понимают упорядочение операций записи по данному адресу памяти. Дело в том, что для повышения производительности аппаратура управления памятью иногда может записывать данные в память не в том порядке, в котором процессор выдает команды сохранения. Такой механизм может вызвать проблемы, если область памяти совместно используется несколькими процессорами и порядок операций записи в данную область памяти важен. Установка данного бита для страницы упорядочивает операции записи в эту страницу, выполняемые всеми процессорами.
4.G (Guarded Storage) — отслеживаемая память.
Если G=1, то выборка данных и команд вне порядка их следования с данной страницы запрещена. Для более высокой производительности некоторые процессоры могут выполнять команду до того, как это потребуется при последовательном выполнении. Предположим, например, что у некоторого процессора имеется конвейер команд, не занятый в течение данного цикла. Если далее в потоке команд есть подходящая для конвейера, то процессор начнет ее выполнять. Это называется выполнением вне порядка следования. Конечно, машина должна вести себя в соответствии с моделью последовательного выполнения. Если до того момента, когда процессор в нормальном случае дошел бы до команды, выполненной вне порядка следования, происходит переход или прерывание, то состояние процессора должно быть восстановлено так, как если бы он никогда не выполнял эту команду. Иногда поведение области памяти может не соответствовать модели опережающего выполнения. Например, если область памяти используется устройством ввода-вывода, то опережающая запись в нее может вызвать выполнение ошибочной операции. Если SLIC необходимо гарантировать, что подобного не произойдет, то для соответствующей страницы можно включить бит G.
Защита страниц
 С трансляцией адреса связан еще один вопрос — защита памяти. Механизм защиты памяти AS/400 обеспечивает защиту для блоков размером в одну страницу, в отличие от битов тега, защищающих указатели в 16-байтовых блоках памяти. Разница и в том, что теги не предотвращают доступа к указателю, а лишь определяют факт модификации после того, как она уже произошла. Механизм защиты страниц может предохранить страницу от чтения или записи.
С трансляцией адреса связан еще один вопрос — защита памяти. Механизм защиты памяти AS/400 обеспечивает защиту для блоков размером в одну страницу, в отличие от битов тега, защищающих указатели в 16-байтовых блоках памяти. Разница и в том, что теги не предотвращают доступа к указателю, а лишь определяют факт модификации после того, как она уже произошла. Механизм защиты страниц может предохранить страницу от чтения или записи.
 Рисунок 8.7. Защита страниц
Рисунок 8.7. Защита страниц
PTE содержит два бита защиты страниц (PP), которые вместе с битом MSRUS используются для определения разрешенного типа доступа к странице. Вспомним, что бит MSRUS установлен в 1 при исполнении пользовательского кода, и в 0 — при исполнении кода ОС. На рисунке 8.7 показаны типы доступа, разрешенные для каждого сочетания. Доступ «чтение/запись» означает, что исполняющаяся программа может читать и изменять страницу; доступ «только чтение» — что программа может читать, но не изменять страницу; и «нет доступа» — что программа не может ни читать, ни изменять страницу. На рисунке также показано основное назначение режимов защиты и разрешенные типы доступа к странице по значению ключа и разрядов PP. Например, весь сгенерированный MI код и константы хранятся на страницах, доступных только для чтения. Ну, вот, мы и выбрались из этих «наперченных» разделов. Давайте теперь рассмотрим управление дисками, и то, как оно сочетается с одноуровневой памятью. Эта тема должна быть для большинства читателей значительно более удобоваримой.
Управление дисками
Компонент SLIC, отвечающий за управление дисками AS/400, называется управлением вспомогательной памятью (auxiliary storage management). В его обязанности входит: управление пулами вспомогательной памяти ASP (набор из одного или нескольких дисковых устройств); создание, расширение, усечение и разрушение сегментов на диске; управление свободным пространством на каждом диске; управление справочниками, связывающими виртуальные адреса с областями на диске.Пулы вспомогательной памяти
В основе System/38 лежала мысль: локализовать все сведения о дисковых устройствах ниже границы MI. Никакой код выше MI, будь то прикладная программа, или ОС, не должны были владеть какой-либо информацией, даже о том, подключены ли к системе диски. Независимость от технологии предполагает, что никакое ПО не должно зависеть от особенностей устройств ввода-вывода. Однако ПО, конечно, необходимо иметь информацию о таких устройствах, как терминалы и принтеры. Так почему диски должны быть исключением? Дело в том, что некоторые из нас, разработчиков System/38, были тогда, середине 70-х, твердо убеждены, что у дисков нет будущего. В конце концов, сколько еще может продержаться технология, занимающаяся покрытием пластин ржавчиной? Мы полагали, что диски скоро и неизбежно будут вытеснены какими-нибудь новыми полупроводниковыми устройствами: цилиндрическими магнитными доменами, или приборами с зарядовой связью... А может быть, технологии основной памяти станут настолько дешевы, что никакой иной формы хранилища и не потребуется[ 71 ] Так вот, для того, чтобы эти новые технологии по мере готовности можно было легко встроить в System/38, мы изолировали все сведения о дисках ниже MI. Однако, это «незнание» о дисках, привело к возникновению проблем[ 72 ]. Если диск в System/ 38 выходил из строя, и восстановление было невозможно, то нигде выше MI не сохранялось сведений, что же было на этом диске. После ремонта или замены диска, приходилось заново восстанавливать данные на всей дисковой подсистеме из последней резервной копии — не очень приятное занятие. Поэтому мы решили, что в OS/400 все же нужны некоторые сведения и возможности управления дисками. Так появились пулы вспомогательной памяти (ASP). ASP — это набор дисковых устройств. Вся дисковая память пула выглядит как одна непрерывная область в памяти. Отдельные устройства невидимы. Минимальный размер ASP — один диск, а вся дисковая память AS/400 может быть разделена максимум на 16 ASP. Первый ASP — всегда системный. OS/400 и некоторые типы системных объектов, управляемые ею, должны располагаться всистемном ASP. Кроме того, может быть определено до 15 пользовательских ASP. Объект, который не обязан находиться в системном ASP, может быть помещен в любой пользовательский ASP, на котором должен уместиться целиком. Объекты не могут пересекать границу ASP. Благодаря такому разделению дисковой памяти, любой сбой диска изолирован внутри одного ASP, что позволяет значительно сократить время восстановления, если таковое потребуется. Некоторые типы объектов, например, приемники журналов, также могут быть изолированы от других частей системы. Управлением ASP занимается компонент управления дисками в SLIC.Сегменты памяти
Каждый объект состоит из одного или нескольких не перекрывающихся сегментов. При создании сегмента должны быть заданы несколько характеристик. Одна из них — начальный размер. На основании начального размера компонент управления дисками выделяет страницы для сегмента. Как мы отмечали в главе 5, бит авторасширения в заголовке сегмента указывает, может ли сегмент быть расширен. Если это так, то его размер может увеличиваться до максимального размера в 16 МБ.Дисковые экстенты
При создании нового сегмента дисковое пространство выделяется для него в виде одного или нескольких экстентов. Дисковый экстент — это набор последовательных 520-байтовых секторов диска. Минимальное число секторов в экстенте равно восьми, так как минимальным участком выделяемой памяти является 4-килобайтная страница. Число страниц экстента всегда выражено степенью двойки. Таким образом, возможны размеры экстентов 4, 8, 16, 32, 64 КБ, и т. д. до 16 МБ. Использование экстентов упрощает управление свободным пространством на диске, так как ограничивает число размеров фрагментов. Управление вспомогательной памятью использует машинный индекс, чтобы отследить свободные экстенты каждого диска и объединяет смежные экстенты в экстент большего размера. Такое объединение очень просто и быстро. Так как величина любого экстента всегда наполовину меньше размера следующего, то при освобождении экстента простая проверка позволяет определить, свободна ли другая половина. Если это так, то обе половины объединяются в экстент большего размера. Процесс продолжается до тех пор, пока дальнейшее слияние не окажется невозможным. Виртуальный сегмент, особенно расширенный, может состоять из нескольких физически несмежных экстентов диска. Когда сегмент нужно расширить, компонент управления памятью находит комбинацию экстентов, размер которой позволяет хранить запрошенное число страниц. Такие экстенты могут располагаться даже на разных дисковых устройствах, но обязательно в одном ASP.Выводы:
Объект может состоять из одного или нескольких сегментов. Сегмент может состоять из одного или нескольких экстентов. Экстент состоит из одной или нескольких страниц (их число всегда — степень 2). Страница состоит из восьми секторов диска. Сектор состоит из 520 байтов диска (512 байтов данных и 8 байтов заголовка)[ 73 ].Сегменты группы доступа
Ранее мы говорили, что сегменты создаются либо как постоянные, либо как временные. Временный сегмент может быть также создан как часть группы доступа. На этих группах доступа мы остановимся немного подробней. Назначение группы доступа — повышение производительности при считывании в память и переписывании на диск временных сегментов, связанных с каким-либо пользовательским заданием. Типична ситуация, когда с таким заданием связаны десятки временных объектов. Если бы работа с ними велась как с обычными объектами, то каждый занимал бы один или несколько временных сегментов, состоящих, по меньшей мере, из одного экстента. Перемещение всех страниц данного задания на диск потребовало бы минимум по одной операции ввода-вывода на экстент. Те же накладные расходы: требовались бы и при считывании всех страниц задания обратно в память. Группа доступа — это системный объект, введенный для устранения большей части описанных накладных расходов. Группа доступа состоит из двух сегментов: первый, базовый, включает в себя таблицу содержимого (ТОС); второй — сегмент данных. Каждая запись ТОС содержит эффективный адрес одной из страниц в сегменте данных. При создании временного объекта в группе доступа, его сегменты будут размещены на следующих доступных местах сегмента данных группы доступа, и ТОС будет соответствующим образом модифицирована. Таким образом, несколько физически небольших временных сегментов могут быть упакованы внутри одного экстента сегмента данных на диске, и их чтение/запись можно будет выполнять одной операцией ввода-вывода. Обратите внимание, что группы доступа работают только с физически небольшими объектами и их маленькими сегментами. Все сегменты имеют 16 МБ адресного пространства, но большинство временных сегментов задания занимают лишь несколько страниц физической памяти. Группы доступа очень хороши для таких маленьких временных сегментов. Для постоянных объектов они не используются, так как постоянные объекты обычно имеют больший размер.Каталоги вспомогательной памяти
Теперь рассмотрим каталоги, которые поддерживаются и используются компонентом управления вспомогательной памятью для контроля за дисковым пространством. Каталог свободного пространства — это машинный индекс (описанный в главе 6), каждая запись которого показывает расположение на диске одного экстента свободного пространства. Статический каталог представляет собой список экстентов, выделенных предопределенным постоянным сегментам. Статический каталог используется для поиска виртуальных сегментов, которые необходимы для работы системы, когда использование нормальных (постоянного и временного) каталогов невозможно. Постоянный каталог — машинный индекс, каждая запись которого показывает расположение на диске от одного до четырех экстентов, выделенных постоянному виртуальному сегменту. Временный каталог — машинный индекс, каждая запись которого указывает расположение на диске от одного до четырех экстентов, выделенных временному виртуальному сегменту. Справочный каталог — содержит список экстентов из постоянного и временного каталогов, которые недавно были востребованы. Фактически, справочный каталог — это кэш для постоянного и временного каталога. Он предназначен для того, чтобы избежать относительно долгого поиска в этих каталогах. Каталог членов группы доступа — машинный индекс, каждая запись которого содержит адрес группы доступа, к которой относится данный член (сегмент) группы доступа. Таблица содержимого группы доступа (TOC)— как уже говорилось, такую таблицу имеет каждая группа доступа. ТОС представляет собой список, каждый элемент которого задает расположение на диске страницы некоторого члена (сегмента) группы. Так как каталог свободного пространства и постоянный каталог — это машинные индексы, то в результате сбоя системы они могут быть разрушены. При каждой IPL управление вспомогательной памятью проверяет состояние этих каталогов. Если каталоги разрушены, то запускается процедура восстановления каталогов: сканируется содержимое всех дисков и собирается информация, хранящаяся в заголовках секторов и сегментов. Поскольку временные объекты, включая группы доступа, во время IPL исчезают, то восстановление других каталогов не требуется.Выводы
В 1976 году Белл (Bell) и Стрекер (Strecker) опубликовали работу с критикой Digital PDP-11. По их словам: «При проектировании компьютера только одну ошибку трудно исправить — недостаточное количество адресных разрядов»[ 74 ]. Они описали несколько причин, по которым Digital пришлось отказаться от архитектуры PDP, имевшей лишь 16-разрядный адрес, и перейти на архитектуру VAX с 32-разрядным адресом. В последние годы Digital перешла на 64-разрядную архитектуру Alpha. Архитекторы System/38 и AS/400 поклялись, что их архитектура никогда не потерпит неудачу из-за недостатка адресных разрядов. Они определили для хранения адресов 128-разрядный указатель и обеспечили достаточно места для расширения. С точки зрения адресации, у AS/400 — большой запас прочности. В будущем значение большой одноуровневой памяти AS/400 только усилится. Многие производители компьютеров только сейчас открывают для себя важность постоянства объектов. По мере того как все больше ОС становятся объектно-ориентированными, специалисты осознают, что для совместного использования объектов для последних должна быть возможность существовать вне процесса. В объектно-ориентированном мире системы виртуальной памяти, которые разрушают все объекты процесса после его завершения — не самый лучший вариант. Постоянные объекты AS/400 — элегантное решение этой проблемы. В следующей главе мы рассмотрим процессы AS/400 и увидим, как связаны друг с другом многие из уже обсужденных нами тем.Глава 9
Управление процессами
Время — это средство, с помощью которого Природа не дает всему происходить сразу. В компьютерах таким средством служат процессы. Процесс — это исполняющаяся программа. Он состоит из исполняемой программы, данных программы и некоторой информации состояния (определяется ниже), необходимой для ее выполнения. Любая ОС имеет средства поддержки процессов. Ранее мы говорили, что процесс можно считать единицей работы системы. Это положение по-прежнему остается в силе. Вероятно, наиболее четкое интуитивное представление о процессе можно получить, если представить себе систему с разделением времени. Разделение времени, как отмечалось в главе 8, означает одновременное совместное использование процессора и памяти несколькими пользователями. Разделение времени создает у пользователя иллюзию собственного компьютера. Если в компьютере всего один процессор, то в каждый конкретный момент времени программу может исполнять только один пользовательский процесс. Управление процессами — это компонент SLIC, который не дает всему происходить сразу, переключая между процессами ресурсы единственного процессора. Периодически ОС принимает решение прекратить один процесс и начать другой, например, если первый использовал весь выделенный ему интервал времени процессора. Если по этой причине процесс временно приостанавливается, то позднее он будет продолжен, начиная в точности с того места, где прекратился. Следовательно, вся информация о процессе, называемая информацией состояния, должна быть на время приостановки процесса где-то сохранена. Компонент распределения работ OS/400 имеет те же самые функции, но на более высоком уровне. Возможность эффективно распределять работы в системе, важна для производительности широкого класса приложений. Мы начнем с основ управления процессами, а затем обсудим взаимосвязи между управлением процессами и распределением работ.Лучшая в мире структура задач
Конкурентоспособность вычислительной системы часто достигается лишь благодаря нескольким базовым идеям. Идеи, принесшие заслуженную славу AS/400 — это независимость от технологии, обеспечиваемая MI, и высокая производительность, поддерживаемая одноуровневой памятью. Но есть столь же важные, хотя намного менее известные находки разработчиков. Одна из них — структура задач AS/400, которая пока еще так широко не обсуждалась. IBM, в соответствии с общепринятыми правилами бизнеса, всегда стремилась запатентовать важные идеологические новшества в своей продукции. Патенты, защищая исключительные права на новые идеи, дают компании-владельцу преимущества перед конкурентами, которые не могут их копировать на законных основаниях. Большую прибыль приносят также продажи прав на использование новых технологий другим компаниям. Поэтому появлению AS/400 на рынке предшествовало исследование, целью которого было выбрать наиболее интересные запатентованные технологические новшества для этой системы. Наиболее важным был Патент США № 4 177 513, защищавший структуру задач System/38 и AS/400[ 75 ]. Структура задач — основа построения ОС AS/400. На ней базируются компонент управления процессами SLIC и компонент распределения работ OS/400. В предшествующих главах при обсуждении большинства разделов ОС мы начинали с самого «верхнего» уровня системы и постепенно спускались «вниз». Теперь же я намерен изменить привычный порядок и начать обсуждение «снизу». Причина — фундаментальная важность для AS/400 структуры задач. Но, прежде всего, хотелось бы сказать несколько слов о будущих направлениях развития операционных систем. Надеюсь, это поможет Вам понять, почему структура задач так важна,Технологии микроядра
Микроядро — одна из наиболее горячо обсуждаемых сегодня тем в информатике. Сторонники микроядра утверждают, что эта небольшая центральная часть ОС — основа для модульных, переносимых ОС. Оппоненты же говорят, что микроядро ограничивает возможности многопользовательской ОС. Чуть ли не каждый специалист имеет свою собственную точку зрения на то, как сервисы ОС должны быть распределены относительно микроядра. И все же по одному из положений критики, кажется, договорились — это используемая микроядром схема взаимодействия на основе передачи сообщений. Большинство экспертов считает, что это направление — будущее всех ОС, независимо от того, используют они микроядро или нет. Чтобы лучше понять схему взаимодействия на основе передачи сообщений, рассмотрим кратко, как традиционно осуществлялось взаимодействие в ОС. Отличным примером может служить ОС Unix. И первоначальная версия Unix, и большинство современных ее вариантов используют слоеную архитектуру. Группы функций ОС, такие как файловая подсистема, подсистема управления процессами и подсистема ввода-вывода, разделены в ней на слои. Само по себе подобное деление не так уж необычно: большинство ОС, включая ОС AS/ 400, состоят из слоев ПО. Различия между ОС заключаются в способах обмена информацией и взаимодействия между слоями. В системах Unix каждый слой взаимодействует только со слоями, расположенными непосредственно под и над ним. Преимущество такой структуры, на первый взгляд, очевидно: каждый слой «знает» только непосредственных «соседей» снизу и сверху; запросы и отклики передаются от слоя к слою вверх и вниз, как по лестнице. Именно таким образом приложения и сама ОС взаимодействуют с различными компонентами. Такой подход хорошо работает. Лучшее доказательство тому — число Unix-подобных ОС, доживших до сегодняшних дней. Однако такое решение усложняет введение новых или изменение существующих элементов структуры — мешает монолитность конструкции. Иерархия слоев объединяет систему в единое целое. Нелегко вынуть один слой и заменить его новым, так как интерфейсов между слоями много, и они разные. Так что изменения требуют глубокого знания ОС и массы времени. Кроме того, многие API между слоями не документированы, что ставит под вопрос корректность работы кода после внесения изменений. То есть добавить новые функции или перенести их с одного уровня на другой становится настоящей проблемой. Микроядро заменяет описанную вертикальную иерархию взаимосвязей горизонтальной. Все компоненты ОС выше микроядра взаимодействуют друг с другом напрямую, используя проходящие через микроядро сообщения. Микроядро проверяет сообщения, обеспечивает их передачу от одного компонента к другому, контролирует доступ к аппаратным ресурсам. ОС на основе микроядра имеет очень большие возможности расширения. Такая модульная архитектура дает возможность легко подключать новые компоненты, о которых даже и не думали разработчики ОС. При этом работа остальных частей системы не будет нарушена. Однако все имеет свою цену. В ОС на основе микроядра даже тщательно оптимизированная передача сообщений выполняется не столь быстро, как вызов функции в типичной системе Unix. Но производительность системы все равно может быть выше, если удастся избежать прохода через лишние уровни. Все, что было сказано о характере взаимодействий в архитектуре микроядра, применимо и к AS/400. Структура задач как System/38, так и AS/400 использует сообщения, точно так же, как и микроядро. Сообщения хорошо знакомы пользователям OS/ 400: с их помощью взаимодействуют приложения и компоненты системы, в результате этих взаимодействий осуществляется все распределение работ. Подобно микроядру, структура задач AS/400 реализована на самом нижнем уровне системы. В System/38 и ранних моделях AS/400 управление задачами было реализовано в HLIC, а на RISC-системах AS/400 для достижения оптимальной производительности — в SLIC. В основе SLIC — не микроядро, но аналогичные архитектурные концепции. История микроядра началась в середине 80-х в Университете Карнеги-Меллон с разработки микроядра Mach. Технологию микроядра используют многие ОС, созданные в последние годы, например, Windows NT, но впервые она появилась в System/ 38, а затем — в AS/400. Важно отметить, что микроядро — это гораздо больше, чем просто основанный на передаче сообщений механизм взаимодействия и диспетчеризации. Чтобы лучше это понять, мы начнем изучать управление процессами в AS/400 с нижних уровней системы.Начинаем снизу
Ранее мы определили процесс как единицу работы в системе. То же самое можно сказать и о задаче. Но по сравнению с задачей, процесс в SLIC — понятие более высокого уровня, он построен над задачей. Имеется и третья, еще более значимая единица работы в OS/400, называемая заданием. Мы увидим далее, как связаны между собой эти три единицы работы в AS/400. Термины «задача» и «процесс» появились в двух разных проектных группах System/38. Инженеры говорили о задачах, а программисты — о процессах. Многие полагали, что поскольку имена разные, то ими обозначают фундаментально разные понятия, но это не так. В начале разработки System/38 мы пытались определить механизм, с помощью которого ОС смогла бы выполнять свою основную обязанность — распределять работы и ресурсы внутри системы. Мы хотели быть уверены, что все делаем правильно. Тогда, в начале 70-х, идея процесса как единицы работы в системе только-только начала использоваться. Но мы полагали, что она подойдет нашей ОС. Развитие процессоров в течение 60-х годов шло довольно бурно. И все же в те дни процессоры ничего не «знали» о процессах, а «понимали» только прерывания. Прерывание — это изменение нормальной последовательности исполнения команд, вызванное либо ошибкой команды, либо чем-то за пределами исполняющейся программы, обычно вводом-выводом. Процессор запускал операцию ввода-вывода, которая затем выполнялась без его участия. Когда ввод-вывод завершался, нужно было как-то сообщить эту информацию процессору, и в качестве такого механизма использовались прерывания. Прерывание останавливает исполняющуюся программу и передает управление обработчику прерываний, который предпринимает нужные действия. После этого управление возвращается прерванной программе. Обработчик прерываний обязан возобновить исполнение прерванной программы в точности с того же момента, на котором оно было прервано. Это означает возвращение всех внутренних регистров в состояние, предшествовавшее прерыванию. Некоторые процессоры имеют несколько наборов регистров, и при возникновении прерывания обработчик использует другой набор. Возвращение управления прерванной программе подразумевает переключение обратно на старый набор регистров. Большинство схем обработки прерываний используют идею приоритета. Приоритет располагает прерывания в порядке их важности, от наиболее к наименее важным. При возникновении прерывания процессор переключается на другую программу только в том случае, если эта программа приоритетней той, что исполняется в данный момент. Большинство процессоров поддерживают ограниченное число приоритетов прерываний. Для поддержки процессов ПО ОС использует механизм прерываний и надстраивает над ним процессы. В 70-х годах, работая над новым микропрограммируемым процессором для System/38, мы надеялись, что, построив структуру процессов непосредственно над аппаратурой и устранив некоторые накладные расходы прерываний, сможем достичь высокой эффективности системы. Такая структура процессов могла бы использоваться даже вводом-выводом без отдельного механизма прерываний. Это также сократило бы число схем процессора — цель, близкая и дорогая сердцу каждого разработчика. Фактически, нужно было создать структуру процессов системы и написать для ее поддержки микрокод.
Но попытки объяснить кому-либо из инженеров-аппаратчиков, что мы делаем, давали весьма интересные результаты.
Я очень хорошо помню одну такую дискуссию с техническим менеджером Реем Клотцем и его подчиненными. Я объяснял, что благодаря новой структуре мы не будем ограничены лишь несколькими уровнями прерываний. Мы сможем поддерживать сотни процессов, каждый из которых будет иметь свой уровень приоритета. При желании, даже каждое устройство ввода-вывода может иметь свой собственный приоритет, так как наша система будет поддерживать множественные процессы. Рэй прервал меня вопросом:
Вы хотите сказать, что разрабатываете мультипроцессор?
Нет, — ответил я, — мы строим систему для поддержки множественных процессов, а не множественных процессоров.
В чем же разница?
Процесс — это то же самое, что и задача, — сказал я, а затем повторил, — Мы строим систему для поддержки множественных задач, а не множественных аппаратных процессоров. После краткого молчания Рэй поинтересовался:
Но тогда, почему вы не называете их просто задачами? С этого дня мы так и стали их называть.
В 70-х годах, работая над новым микропрограммируемым процессором для System/38, мы надеялись, что, построив структуру процессов непосредственно над аппаратурой и устранив некоторые накладные расходы прерываний, сможем достичь высокой эффективности системы. Такая структура процессов могла бы использоваться даже вводом-выводом без отдельного механизма прерываний. Это также сократило бы число схем процессора — цель, близкая и дорогая сердцу каждого разработчика. Фактически, нужно было создать структуру процессов системы и написать для ее поддержки микрокод.
Но попытки объяснить кому-либо из инженеров-аппаратчиков, что мы делаем, давали весьма интересные результаты.
Я очень хорошо помню одну такую дискуссию с техническим менеджером Реем Клотцем и его подчиненными. Я объяснял, что благодаря новой структуре мы не будем ограничены лишь несколькими уровнями прерываний. Мы сможем поддерживать сотни процессов, каждый из которых будет иметь свой уровень приоритета. При желании, даже каждое устройство ввода-вывода может иметь свой собственный приоритет, так как наша система будет поддерживать множественные процессы. Рэй прервал меня вопросом:
Вы хотите сказать, что разрабатываете мультипроцессор?
Нет, — ответил я, — мы строим систему для поддержки множественных процессов, а не множественных процессоров.
В чем же разница?
Процесс — это то же самое, что и задача, — сказал я, а затем повторил, — Мы строим систему для поддержки множественных задач, а не множественных аппаратных процессоров. После краткого молчания Рэй поинтересовался:
Но тогда, почему вы не называете их просто задачами? С этого дня мы так и стали их называть.
Диспетчеризация задач в AS/400
С каждой задачей AS/400 связан блок управления в памяти, который называется элементом диспетчеризации задач TDE (task dispatching element). TDE — это фундаментальная структура данных, лежащая в основе управления задачами. Структура TDE не видима над MI, так как расположена ниже него. Эта структура не системный объект, но важный компонент некоторых из них. Далее в этой главе мы рассмотрим процесс MI и увидим, каким образом TDE включена в этот системный объект. TDE содержит всю информацию, необходимую для управления выполнением задачи. Задача — это исполняющаяся программа, а TDE отвечает и за программу и за состояние ее выполнения.Состояния задачи

состояние характеризует способность задачи выполняться процессором. Любая задача в системе может находиться в одном из четырех состояний. Обратите внимание, что каждое состояние может обозначаться несколькими терминами. В данном разделе мы используем имена состояний SLIC. Итак, четыре состояния задачи — это: Подвешенность — задача находится в этом состоянии, когда начинается или завершается. Такая задача не может исполняться процессором. Готовность — состояние задачи, которая готова к выполнению, но еще не выполняется. За пределами SLIC данное состояние также иногда называется «не избранным», то есть вместо данной задачи исполняется некоторая другая.

Рисунок 9.1. Состояния задачи
Исполнение — состояние задачи, называемое вне SLIC активным. В любой момент времени на одном процессоре может исполняться только одна задача. Ожидание — задача чего-либо ожидает, обычно, завершения ввода-вывода, и при этом не может исполняться. Четыре состояния задачи и возможные переходы между ними показаны на рисунке 9.1. Всего возможно 12 переходов из одного состояния в другое, но в AS/400 разрешены только шесть, а именно: Инициирование задачи (подвешенность — готовность): работа начата, и задача переводится в состояние готовности к исполнению. Запуск задачи (готовность — исполнение): перевод задачи в исполняющееся (активное) состояние. Подвешивание задачи (исполнение —подвешенность): по завершении работы задача переводится в подвешенное состояние. Вытеснение задачи (исполнение — готовность): еще не завершенная задача переводится обратно в готовое состояние. Данный переход предполагает наличие в системе других задач, которые более важны (приоритетны). Ожидание (исполнение — ожидание):некоторая операция, запущенная задачей, например, ввода-вывода, заставляет задачу ожидать своего завершения. Сигнализация (ожидание — готовность): операция, окончания которой ждала задача, завершилась, и задача переходит в состояние готовности (не избранности). Некоторые из этих переходов знакомы тем, кто работал с командой «WRKSYSSTS». Она показывает частоту выполнения следующих переходов: «исполнение — ожидание», «исполнение — готовность» и «ожидание — готовность». Данные значения используются при настройке уровня активности в пуле памяти. (На уровнях активности и пулах памяти мы подробно остановимся далее в этой главе). Текущее состояние задачи определяется местом связанного с ней TDE. TDE перемещаются в системе, но не физически, а логически. Все TDE расположены в памяти AS/400. TDE содержит поля адресов, связывающие его с другими структурами данных. Когда говорят о перемещении TDE, имеют в виду, что адреса в структурах данных изменяются для логического перемещения TDE в другую структуру данных. Операции, выполняемые SLIC для связывания различных адресов памяти — вставка TDE в структуру данных и удаление его оттуда — называются постановкой в очередь и удалением из очереди. Эти операции связывания выполняются очень быстро по сравнению с физическим перемещением TDE.
Очередь диспетчеризации задач
 TDE всех задач, которые могут выполняться на процессоре в любой данный момент времени, объединены в структуру данных, называемую очередью диспетчеризации задач TDQ (task dispatching queue). TDQ реализована как связный список в памяти, в котором TDE упорядочены по приоритетам, как показано на рисунке 9.2. Каждый TDE содержит поле приоритета, которое используется для упорядочения. TDE для приоритетной задачи открывает список.
Находящийся в SLIC диспетчер задач выбирает приоритетный (первый в списке) TDE и передает ему управление процессором. Таким образом, первый TDE связан с задачей, которая в данный момент исполняется процессором. Все остальные TDE в TDQ связаны с задачами в готовом состоянии. Текущая задача продолжает исполняться до тех пор, пока ей не придется отдать управление процессором.
Причин тому может быть несколько. Исполняющаяся задача может запустить операцию, которая заставит ее отдать управление, например ожидание завершения ввода-вывода. Отдать управление также приходится, когда задача полностью использует выделенное ей время процессора. Кроме того, может случиться, что исполняющаяся задача будет вытеснена другой, более важной (приоритетной).
Всякий раз, когда исполняющаяся задача отдает управление, оно передается задаче, следующей по важности в TDQ, которая и становится новой исполняющейся задачей. Таким образом, любой TDE в TDQ находится по определению либо в исполняющемся, либо в готовом состоянии.
TDE всех задач, которые могут выполняться на процессоре в любой данный момент времени, объединены в структуру данных, называемую очередью диспетчеризации задач TDQ (task dispatching queue). TDQ реализована как связный список в памяти, в котором TDE упорядочены по приоритетам, как показано на рисунке 9.2. Каждый TDE содержит поле приоритета, которое используется для упорядочения. TDE для приоритетной задачи открывает список.
Находящийся в SLIC диспетчер задач выбирает приоритетный (первый в списке) TDE и передает ему управление процессором. Таким образом, первый TDE связан с задачей, которая в данный момент исполняется процессором. Все остальные TDE в TDQ связаны с задачами в готовом состоянии. Текущая задача продолжает исполняться до тех пор, пока ей не придется отдать управление процессором.
Причин тому может быть несколько. Исполняющаяся задача может запустить операцию, которая заставит ее отдать управление, например ожидание завершения ввода-вывода. Отдать управление также приходится, когда задача полностью использует выделенное ей время процессора. Кроме того, может случиться, что исполняющаяся задача будет вытеснена другой, более важной (приоритетной).
Всякий раз, когда исполняющаяся задача отдает управление, оно передается задаче, следующей по важности в TDQ, которая и становится новой исполняющейся задачей. Таким образом, любой TDE в TDQ находится по определению либо в исполняющемся, либо в готовом состоянии.
 Рисунок 9.2. Очередь диспетчеризации задач
Рисунок 9.2. Очередь диспетчеризации задач
Очереди и счетчики приема-передачи
В основе метода синхронизации выполнения задач, а также и для связи между задачами лежит семафор Дейкстры (Dijkstra). В 1968 году Дейкстра предложил примитив для синхронизации исполнения процессов в ОС с мультипрограммированием. Синхронизация — это способность задачи приостанавливаться и ждать до тех пор, пока другая задача не выполнит некоторую операцию. Семафор предоставляет задаче механизм ожидания. Семафор имеет счетчик и список ожидания. Определены две операции (команды). Синхронизация задач осуществляется следующим образом. Оператор V увеличивает значение счетчика на 1. Оператор P проверяет значение счетчика; если оно больше 0, то уменьшает значение на 1 и дает возможность выполняться следующей команде в потоке. Если значение счетчика не больше 0, то оператор Р ждет пока значение увеличится и станет больше 0, прежде чем операция завершится и следующая команда сможет выполняться. То есть ситуация, когда при выполнении оператора Р счетчик не больше 0, означает ожидание. В этом случае, задача, выполнившая оператор Р, ждет до тех пор, пока какая-либо другая задача не увеличит счетчик с помощью оператора V. Во многих случаях, при синхронизации желательно обменяться некоторой информацией или сообщением. Для поддержки синхронизации и передачи сообщений AS/ 400 определяет очередь приема-передачи SRQ (send/receive queue). SRQ — это структура данных в памяти, используемая как «почтовый ящик» для передачи сообщений от одной задачи к другой. Когда исполняющаяся задача выполняет операцию «Отправить сообщение», в очередь SRQ, связанную с некоторой другой задачей, добавляется структура данных, называемая сообщением приема-передачи SRM (send/receive message). SRM содержит сообщение, которое исполняющаяся задача желает передать другой задаче. Когда исполняющаяся задача хочет получить сообщение из SRQ (из своего почтового ящика), она выполняет операцию «Принять сообщение». Если сообщения нет, то задача может подождать его поступления. Если она решает ждать, то TDE исполняющейся задачи извлекается из TDQ и помещается в список ожидания — часть каждой SRQ. Затем вызывается диспетчер задач, который выбирает готовую задачу наибольшей важности и делает ее исполняющейся. Некоторое время спустя другая исполняющаяся задача выполняет для данной SRQ операцию «Отправить сообщение». Если TDE ждет сообщения, то он извлекается из SRQ и помещается в очередь TDQ в порядке важности (приоритетности). Если важность вновь добавленного в очередь TDE выше, чем у исполняющегося, то исполняющая задача вытесняется. Если в процессе ожидания находятся несколько SRQ, то разряд в заголовке SRQ указывает, следует ли при поступлении сообщения «разбудить» их все, или только первую. Любая задача, чей TDE находится в очереди SRQ, по определению находится в состоянии ожидания. На рисунке 9.3 показаны перемещения TDE и то, каким образом положение TDE определяет состояние задачи. Рисунок 9.3. Перемещения элемента диспетчеризации задач
Рисунок 9.3. Перемещения элемента диспетчеризации задач
На рисунке не показаны другие структуры данных, которые могут находиться в очередях TDE. Одна из таких структур — счетчик приема-передачи SRC (send/receive counter). SRC не занимается передачей сообщений, так что похож на обычный семафор. SLIC предоставляет операции «Отправить счетчик» и «Принять счетчик», которые позволяют синхронизировать задачи, если обмен сообщениями не нужен. Некоторые читатели, знакомые с командами «SNDPGMMSG» (Send Program Message) и «RCVMSG» (Receive Message) в OS/400 могут спросить: имеют ли эти команды отношение к операциям, используемым структурой задач SLIC. Ответ: «Да, они состоят в очень тесном родстве». Формат SRM, SRQ и SRC спроектирован для управления задачами, но операции добавления и извлечения сообщений из очереди фундаментально одинаковы во всей системе. За реализацию всех этих функций отвечает SLIC.
Мультипроцессирование
В предшествующем разделе описывались ситуации, подразумевающие наличие только одного процессора, и, следовательно, только одной исполняющейся задачи. На многопроцессорной же системе потенциально может быть несколько исполняющихся задач. Многопроцессорные системы поддерживаются механизмом диспетчеризации задач, большая часть которого присутствовала еще в оригинальной System/38, хотя никогда не использовалась на этой системе. Лишь в 1990 году мультипроцессирова-ние было впервые использовано в AS/400. Оригинальная поддержка мультипроцес-сирования AS/400 до сих пор задействована не полностью, ее резервы предназначены для будущих расширений.Симметричное мультипроцессирование
Ранее мы видели, что система симметричного мультипроцессирования (SMP) дает возможность ОС обрабатывать задачи на любом свободном процессоре или на всех процессорах сразу, при этом память остается общей для всех процессоров. Именно так устроена n-канальная (n-way) обработка на AS/400. Любой компонент ОС, включая диспетчер задач, может выполняться на любом или на всех процессорах системы. Диспетчер задач в n-канальной системе автоматически обеспечивает баланс нагрузки между процессорами, не требуя изменения программ, написанных для однопроцессорной архитектуры. Так как память для всех процессоров общая, диспетчер задач, независимо от процессора, на котором он выполняется, имеет доступ ко всем очередям, включая TDQ. Однако, диспетчер задач не ограничен тем процессором, на котором он выполняется, — он может вызвать переключение задач и на другом процессоре. В многопроцессорной системе одновременно исполняется несколько задач — по одной на процессор. Упрощенно, следует лишь направить на выполнение верхние n TDE из TDQ. Естественно, эти n задач имеют наивысшую приоритетность среди всех готовых задач. Однако такой простой метод часто только кажется наилучшим. Предположим, что у нас есть две задачи, А и В, исполняющиеся на процессорах 1 и 2 в двухпроцессорной системе. Предположим далее, что задача С, приоритет которой выше чем у А, но ниже чем у В, выходит из состояния ожидания. Ее TDE будет добавлен в очередь TDQ непосредственно перед TDE задачи А. Диспетчер задач выполнит переключение задач на процессоре 1, чтобы начать исполнение задачи С. Теперь допустим, что задача В на процессоре 2 либо завершилась, либо перешла в состояние ожидания. Приоритет задачи А — наивысший среди готовых задач, и ее следует направить на процессор 2. Но этот выбор может быть не лучшим. В зависимости от того, насколько давно задача А была вытеснена, мы можем захотеть, а можем и не захотеть начать ее выполнение на процессоре 2. Если задача вытеснена недавно, то в кэше процессора 1 по-прежнему находятся команды и данные задачи А. Направление задачи на процессор 2 означало бы, что кэш процессора 2 должен быть перезагружен в результате промахов, что снизит производительность, как данной задачи, так и системы. В данном случае, лучшим выходом было бы начать выполнение на процессоре 2 какой-либо следующей задачи и подождать, пока для задачи А освободится процессор 1. Мы только что описали понятие сродства кэша (cache affinity). Говорят, что данная задача имеет сродство с некоторым процессором на основании содержимого его кэша. Диспетчеризация задач на многопроцессорной версии AS/400 использует комбинацию приоритета, сродства кэша и еще одной характеристики, под названием приемлемость (eligibility). Приемлемость используют, чтобы ограничить возможный набор процессоров для исполнения данной задачи. Приемлемость никогда не изменяется диспетчером задач. Если все процессоры, для которых приемлемо исполнение данной задачи, заняты задачами более высокого приоритета, то данная задача не направляется на выполнение. Итак, задача отправляется на выполнение только в том случае, если доступен процессор, для которого она имеет сродство кэша. Исключение из этого правила делается тогда, когда его соблюдение может привести к простою процессора или если пропускается значительное число задач высокого приоритета в TDQ. Пороговое значение пропуска зависит от числа процессоров и устанавливается SLIC для конкретной системы. Если число пропущенных задач достигает порогового значения, то сродство игнорируется и задача направляет на любой процессор, для которого она приемлема. Если в процессе пропуска задач был достигнут конец TDQ, прежде чем каждому процессору назначена какая-либо задача, то порог пропуска динамически снижается до тех пор, пока не останется либо незанятых процессоров, либо пропущенных задач. Для диспетчеризации задачи на мультипроцессорной системе используются три поля TDE, а именно: Поле приемлемости, где содержится по одному биту на каждый процессор в системе. Если бит установлен, то задача приемлема для выполнения на соответствующем процессоре. Если установлены все биты, то задача приемлема для выполнения на всех процессорах. Поле активности, включающее по одному биту на каждый процессор в системе и указывающее процессор, на котором данная задача в настоящий момент активна. Может быть установлен максимум один бит, если задача выполняется. В противном случае, все биты сброшены. Поле сродства содержит по одному биту на каждый процессор в системе и указывает процессор, на котором данная задача исполнялась в последний раз. Помимо только что описанной поддержки многопроцессорных систем, AS/400 может иметь множественные TDQ. Данный механизм был включен в оригинальную System/38, чтобы обеспечить диспетчеризацию нескольких очередей, но не использовался там для этой цели. Если число процессоров возрастет настолько, что одиночная TDQ станет тормозить работу системы, то диспетчеризацию можно будет осуществлять с помощью нескольких TDQ. Современные n-канальные процессоры используют модель SMP с разделяемой памятью, в которой все процессоры работают с одной и той же памятью. В главе 12 мы рассмотрим другие модели SMP, которые найдут применение в будущих системах AS/ 400. Все они поддерживаются существующей структурой задач.Асимметричное мультипроцессирование
Давайте, хотя бы кратко, затронем системы асимметричного мультипроцессирова-ния (ASMP). В системе ASMP части одной или даже разных ОС выполняются на выделенных процессорах. Структура задач AS/400 поддерживает и такую модель мультипроцессирования. Один из ранних проектов System/38 предусматривал несколько процессоров, каждый из которых выполнял часть ОС ниже MI. Идея состояла в том, чтобы выделить один процессор для СУБД, другой для управления памятью и т. д. В данном проекте ASMP использовалась та же структура задач для обмена сообщениями между процессорами и распределения работ. В точности такая модель мультипроцессирования никогда не использовалась в System/38. Однако в AS/400 была введена некая разновидность модели ASMP. В главе 10 мы рассмотрим структуру ввода-вывода AS/400, которая существенно изменилась по сравнению с System/38. AS/400 использует множество процессоров для исполнения разных функций ввода-вывода. Большая система может иметь сотни таких процессоров. Мы увидим, что каждый из этих процессоров имеет собственную ОС. Хотя большинство из таких ОС разработаны специально для поддержки функций ввода-вывода, некоторые из них все же более универсальны. Такая архитектура позволяет другим ОС и написанным для них приложениям исполняться «под крышей» AS/400. Таким образом, к AS/400 возможно подключать множество таких машин-приложений в дополнение к основным процессорам.Динамическое планирование приоритетов
В предыдущих разделах мы рассмотрели более понятную, но упрощенную модель диспетчеризации задач в AS/400. Со времен первой System/38 в структуру задач было внесено множество изменений для удовлетворения требований различных приложений и структур системы. Например, мы предполагали, что когда-нибудь системе понадобится динамически настраивать приоритет задачи во время исполнения. Предположим, что задача не получает достаточного для ее решения процессорного времени, или заблокировала некоторый системный ресурс, которого ожидает задача с большим приоритетом. Если бы система могла временно повышать и понижать приоритеты подобных задач, то можно было бы найти выход из только что описанных ситуаций. Такая возможность была добавлена в System/38 и ранние AS/400. С появлением многопроцессорных конфигураций, и особенно в связи с нашим намерением использовать большее количество процессоров в конфигурациях SMP, было решено, что нужна более гибкая настройка приоритета задач. Группа исследователей в подразделении IBM Research в Нью-Йорке работала над механизмом, который они назвали планировщик с оценкой задержки (delay-cost scheduler). Специалисты из Рочестера подключились к этому проекту и вместе с IBM Research создали версию этого планировщика, которая теперь используется в SLIC на всех RISC-системах AS/400. Применяемые в планировщике алгоритмы, пожалуй, слишком сложны для этой книги. Но они вполне позволяют выполнять задачи вне порядка их приоритетов, если производительность системы при этом возрастает. В результате, загрузка RISC-процессоров становится более эффективной, особенно, в n-канальных конфигурациях. Теперь, когда мы закончили рассмотрение самого низкого уровня диспетчеризации задач AS/400, можно перейти к рассмотрению этой функции на более высоких уровнях.Процессы в MI
Процесс в MI — это системный объект, называемый пространством управления процессом. Обратите внимание, что эквивалентного объекта OS/400 нет. (Мы еще поговорим об этом в разделах, посвященных управлению работами). Задача процесса в MI — связать воедино ресурсы, необходимые для исполнения, или, точнее, вызова программы. Программы разделяемы, поэтому одна программа может исполняться несколькими пользователями. Конечно, данные, используемые программой, для всех пользователей будут разными. Так как программе необходимо некоторое место для временного хранения используемых переменных, то для каждого ее вызова нужно выделить рабочую область. Ответственность за это лежит на процессе MI. Прежде чем займемся собственно структурой процесса, необходимо разобраться с типами памяти, задействованными исполняющейся программой. На исполнение программы сильно влияют компилятор и ЯВУ. Особенно важно то, как компилятор размещает и адресует переменные, используемые в программе. Часто ЯВУ имеет некоторую форму оператора объявления, позволяющего задать тип переменной и место, где компилятор должен ее разместить. Чтобы понять, какие варианты размещения переменных должен поддерживать процесс, необходимо рассмотреть три отдельные области, используемые для размещения данных современными ЯВУ, а именно: Статическая область памяти. Данный тип памяти компилятор использует для размещения глобальных переменных и констант программы. Переменные называются глобальными, так как эта область памяти доступна любой части программы (на некоторых системах сама область называется областью глобальных данных). Автоматический стек. Эта область памяти используется для размещения локальных переменных. При выполнении в программе процедуры вызова, переменные должны быть где-то сохранены, чтобы их можно было восстановить после возврата. Переменные называются локальными, так как имеют смысл только в процедуре, исполняющей вызов. Вызовы могутбыть вложенными, то есть одна процедура может вызвать другую, та — третью и т. д. Соответственно, область для сохранения переменных должна автоматически расти и сокращаться при вызовах и возвратах. В качестве такой области автоматического хранилища используется стек. Стек состоит из двух компонентов: непрерывного блока памяти, содержащей данные, и указателя стека, определяющего положение вершины стека в памяти. Дно стека располагается по фиксированному адресу. При вызове программы адрес указателя стека увеличивается, чтобы предоставить достаточно места для локальных переменных; а при выполнении возврата — уменьшается на соответствующую величину. Таким образом, размер стека растет и сокращается динамически. В некоторых системах эту память называют динамической. 3.Область кучи. Эта область памяти используется для размещения динамичес- ких данных, которые не вписываются в структуру стека. Стек удобен для хранения одиночных переменных (скаляров), так как все его элементы, обычно, одинаковы и равны размеру регистров. Стек не очень хорошо подходит для данных переменной длины, таких как массивы элементов данных. Массивы данных можно хранить в куче. Доступ к массиву в куче осуществляется по адресу, указывающему на его начало, к которому прибавляются смещения элементов. Обратите внимание, что описанные выше области — это области памяти (в общем смысле), а не оперативной памяти. Конкретная система может для реализации этих областей использовать любую комбинацию регистров, оперативной памяти и дисков, поэтому мы и говорим о «просто памяти».Исходная модель процессов
 Подобно исходной модели программ (ОРМ), обсуждавшейся в главе 4, исходная модель процессов была разработана для поддержки таких языков, как RPG, Cobol и CL. Исходная модель соответствует структуре, в которой каждый процесс — единица работы. Программы, исполнявшиеся процессами, зачастую не были модульными.
Процесс реализован как системный объект в MI. В дополнение к управляющей информации, данный объект либо содержит области памяти, используемые процессом, либо указывает на них. Три описанные выше области памяти, необходимые для процесса, поддерживались в исходной модели процессов следующим образом:
1. Область статической памяти программы PSSA (Program Static Storage Area) — единственная копия статической области памяти для всего процесса.
Область автоматической памяти программы PASA (Program Automatic Storage Area) содержала стек вызовов.
Область кучи — в исходной модели процессов не поддерживалась. Куча должна была обеспечиваться компилятором каждого языка отдельно.
Системный объект MI для процесса исходной модели, который также называется пространством управления процессом, содержит два сегмента: базовый сегмент, где находится основная часть управляющей информации вместе с TDE процесса; а также сегмент рабочей области вызова IWA (invocation work area). Основное назначение последнего — хранение стека вызовов-возвратов процесса.
Исходная модель процессов очень хорошо работала для приложений, написанных для System/38 и ранних моделей AS/400. Однако переход на блочно-структурирован-ные языки и необходимость поддержки приложений, написанных в соответствии со стандартами POSIX, привели к разработке модели процессов ILE.
Подобно исходной модели программ (ОРМ), обсуждавшейся в главе 4, исходная модель процессов была разработана для поддержки таких языков, как RPG, Cobol и CL. Исходная модель соответствует структуре, в которой каждый процесс — единица работы. Программы, исполнявшиеся процессами, зачастую не были модульными.
Процесс реализован как системный объект в MI. В дополнение к управляющей информации, данный объект либо содержит области памяти, используемые процессом, либо указывает на них. Три описанные выше области памяти, необходимые для процесса, поддерживались в исходной модели процессов следующим образом:
1. Область статической памяти программы PSSA (Program Static Storage Area) — единственная копия статической области памяти для всего процесса.
Область автоматической памяти программы PASA (Program Automatic Storage Area) содержала стек вызовов.
Область кучи — в исходной модели процессов не поддерживалась. Куча должна была обеспечиваться компилятором каждого языка отдельно.
Системный объект MI для процесса исходной модели, который также называется пространством управления процессом, содержит два сегмента: базовый сегмент, где находится основная часть управляющей информации вместе с TDE процесса; а также сегмент рабочей области вызова IWA (invocation work area). Основное назначение последнего — хранение стека вызовов-возвратов процесса.
Исходная модель процессов очень хорошо работала для приложений, написанных для System/38 и ранних моделей AS/400. Однако переход на блочно-структурирован-ные языки и необходимость поддержки приложений, написанных в соответствии со стандартами POSIX, привели к разработке модели процессов ILE.
Модель процессов ILE
 Модель процессов ILE впервые появилась на AS/400 в версии V2R3 вместе с одноименной программной моделью и компиляторами. Исходная модель процессов и модель процессов ILE сосуществовали в AS/400 до перехода на RISC-процессоры. Затем исходные модели были устранены, ведь RISC-системы поддерживают только модель программ и модель процессов ILE. (Модели ILE для программ и процессов создавались специально в расчете на RISC-процессоры.)
Давайте рассмотрим модель процессов ILE более подробно. Но прежде остановимся на изменениях, внесенных в AS/400 для поддержки программной модели ILE. В MI для этого используются активизации программ, группы активизации, вызовы процедур и новый процедурный указатель.
В главе 4 мы говорили о компиляторах и программной модели ILE. Мы рассмотрели, как ILE изменила способ создания программ, а также концепцию модуля. Вспомним, что модуль — это результат работы компилятора ILE. Модуль содержит одну или несколько процедур. Средство связывания (binder) ILE упаковывает модули в программы и служебные программы. Таким образом, программы и служебные программы могут содержать один или несколько модулей, которые, в свою очередь, состоят из одной или нескольких процедур. Для обращения к программам и процедурам внутри модулей как часть ILE были введены два типа команд вызова («CALLPGM» и «CALLBP»).
Программа — это системный объект MI, который всегда вызывается с помощью команды: внешнего вызова «CALLPGM» MI. Аналогично старой команде «CALLX», команда «CALLPGM» для идентификации программы использует системный указатель. Затем эта команда активизирует программу. В ходе активизации завершается межпрограммное связывание: например, если программа использует модули, связанные через ссылку, то происходит разрешение связей со служебной программой. Активизация программы неявно создает группу активизации, которая предоставляет рабочую область для программы, а также инициализирует ее статическую память.
Программа состоит из одной или нескольких процедур. Одна из процедур определяется при создании программы как точка входа, и именно ей командой «CALLPGM» передается управление. Операция передачи управления процедуре называется вызовом процедуры.
Для вызова всех остальных процедур программы применяется команда «CALLBP». Для идентификации вызываемой процедуры в этой команде используется процедурный указатель. Вызываемая процедура может находиться либо в самой программе (если связана через копию), либо в служебной программе (если связана через ссыл
ку). Обратите внимание, что MI контролирует последовательность вызовов на уровне процедур, а не программ.
Когда приложение впервые переносится на RISC-процессор, программа исходной модели конвертируется в программу ILE, состоящую из одной процедуры. Таким образом, преобразованная программа исходной модели, как и любая программа с единственной процедурой, всегда вызывается с помощью «CALLPGM». Если программа, созданная компилятором ILE, состоит из нескольких процедур, то первая процедура вызывается с помощью «CALLPGM», а последующие — с помощью «CALLBP».
В главе 4 мы также затронули группы активизации. Они предоставляют рабочие области для активизации одной или нескольких программ. Каждая группа активизации имеет собственную область статической памяти, область стека и область кучи. Так как с появлением RISC-процессоров осталась только модель ILE, данная рабочая область поддерживает также все процессы оригинальной модели и заменяет собой старые области памяти PASA/PSSA.
Группа активизации — это не системный объект, а часть объекта-процесса MI. Каждый объект-процесс содержит две или более групп активизации, одна из которых используется системой. Каждый процесс содержит также, по крайней мере, одну пользовательскую группу активизации. При переносе процесса исходной модели, созданного на системе с процессором IMPI, на систему с RISC-процессором, этот процесс трансформируется в процесс ILE с одной пользовательской группой активизации.
Группа активизации служит не только для разделения на части памяти, используемой процессом. У каждой группы активизации — собственная управляющая информация, что позволяет поддерживать разные режимы защиты, использования файлов и управления транзакциями. Это обеспечивает заданиям поверх MI большую гибкость.
Все группы активизации поименованы либо явно пользователем, либо неявно системой. В определении объекта-программы для обычных и служебных программ может быть явно задано, в какой поименованной группе активизации они должны выполняться, что вызывает неявное создание данной группы при вызове объекта-программы.
Модель процессов ILE впервые появилась на AS/400 в версии V2R3 вместе с одноименной программной моделью и компиляторами. Исходная модель процессов и модель процессов ILE сосуществовали в AS/400 до перехода на RISC-процессоры. Затем исходные модели были устранены, ведь RISC-системы поддерживают только модель программ и модель процессов ILE. (Модели ILE для программ и процессов создавались специально в расчете на RISC-процессоры.)
Давайте рассмотрим модель процессов ILE более подробно. Но прежде остановимся на изменениях, внесенных в AS/400 для поддержки программной модели ILE. В MI для этого используются активизации программ, группы активизации, вызовы процедур и новый процедурный указатель.
В главе 4 мы говорили о компиляторах и программной модели ILE. Мы рассмотрели, как ILE изменила способ создания программ, а также концепцию модуля. Вспомним, что модуль — это результат работы компилятора ILE. Модуль содержит одну или несколько процедур. Средство связывания (binder) ILE упаковывает модули в программы и служебные программы. Таким образом, программы и служебные программы могут содержать один или несколько модулей, которые, в свою очередь, состоят из одной или нескольких процедур. Для обращения к программам и процедурам внутри модулей как часть ILE были введены два типа команд вызова («CALLPGM» и «CALLBP»).
Программа — это системный объект MI, который всегда вызывается с помощью команды: внешнего вызова «CALLPGM» MI. Аналогично старой команде «CALLX», команда «CALLPGM» для идентификации программы использует системный указатель. Затем эта команда активизирует программу. В ходе активизации завершается межпрограммное связывание: например, если программа использует модули, связанные через ссылку, то происходит разрешение связей со служебной программой. Активизация программы неявно создает группу активизации, которая предоставляет рабочую область для программы, а также инициализирует ее статическую память.
Программа состоит из одной или нескольких процедур. Одна из процедур определяется при создании программы как точка входа, и именно ей командой «CALLPGM» передается управление. Операция передачи управления процедуре называется вызовом процедуры.
Для вызова всех остальных процедур программы применяется команда «CALLBP». Для идентификации вызываемой процедуры в этой команде используется процедурный указатель. Вызываемая процедура может находиться либо в самой программе (если связана через копию), либо в служебной программе (если связана через ссыл
ку). Обратите внимание, что MI контролирует последовательность вызовов на уровне процедур, а не программ.
Когда приложение впервые переносится на RISC-процессор, программа исходной модели конвертируется в программу ILE, состоящую из одной процедуры. Таким образом, преобразованная программа исходной модели, как и любая программа с единственной процедурой, всегда вызывается с помощью «CALLPGM». Если программа, созданная компилятором ILE, состоит из нескольких процедур, то первая процедура вызывается с помощью «CALLPGM», а последующие — с помощью «CALLBP».
В главе 4 мы также затронули группы активизации. Они предоставляют рабочие области для активизации одной или нескольких программ. Каждая группа активизации имеет собственную область статической памяти, область стека и область кучи. Так как с появлением RISC-процессоров осталась только модель ILE, данная рабочая область поддерживает также все процессы оригинальной модели и заменяет собой старые области памяти PASA/PSSA.
Группа активизации — это не системный объект, а часть объекта-процесса MI. Каждый объект-процесс содержит две или более групп активизации, одна из которых используется системой. Каждый процесс содержит также, по крайней мере, одну пользовательскую группу активизации. При переносе процесса исходной модели, созданного на системе с процессором IMPI, на систему с RISC-процессором, этот процесс трансформируется в процесс ILE с одной пользовательской группой активизации.
Группа активизации служит не только для разделения на части памяти, используемой процессом. У каждой группы активизации — собственная управляющая информация, что позволяет поддерживать разные режимы защиты, использования файлов и управления транзакциями. Это обеспечивает заданиям поверх MI большую гибкость.
Все группы активизации поименованы либо явно пользователем, либо неявно системой. В определении объекта-программы для обычных и служебных программ может быть явно задано, в какой поименованной группе активизации они должны выполняться, что вызывает неявное создание данной группы при вызове объекта-программы.
Внутри процесса ILE
В этом разделе мы заглянем внутрь процесса ILE. Структура процесса ILE сложна, и, подобно многим другим затронутым нами темам, ее описание насыщено таким количеством имен, сокращений и терминов, что может загнать в угол любого специалиста по компьютерам. И хотя знакомство с ней не обязательно для понимания работы процессов AS/400, я включил этот раздел в книгу ради полноты изложения. Итак, мазохисты, если Вам нужна еще одна порция аббревиатур, читайте.Структура процессов ILE

Сначала разберемся с компонентами процесса ILE и сокращениями, их обозначающими: Блок управления процессом PCB (Process Control Block) содержится в системном объекте MI. Ранее мы говорили, что этот системный объект, кроме всего прочего, содержит TDE процесса. Далее мы увидим, что PCB также содержит адреса других связанных с процессом компонентов. Рабочая область активизации процесса PAWA (Process Activation Work Area) представляет собой кучу, используемую для размещения структур времени выполнения, таких как группы активизации. У каждого процесса — одна PAWA. Родительская группа активизации PAGP (Parent Activation Group) — это корневая структура подструктуры процесса, содержащая список всех групп активизации процесса. Несмотря на свое название, сама PAGP не является группой активизации. Группа активизации ACTGRP (Activation Group) предоставляет активизации программы ресурсы памяти (стек, статическую память и кучу). ACTGRP похожа на минипроцесс. Могильные сегменты (Tombstone Segments) используются для создания указателей объектов процесса POP (process object pointer) — описателей (handle) структур SLIC. Описатели используются многими ОС, включая OS/ 2 и Apple Macintosh как косвенные указатели блоков памяти в куче. Вместо прямой адресации таких блоков описатель ссылается а основной указатель, обычно расположенный по фиксированному адресу и содержащий адрес блока. При перемещении блоков по памяти нужно изменять только значение основного указателя. Сегменты называются могильными, так как они предотвращают непосредственный доступ к структурам SLIC; даже если уровень защиты системы разрешает доступ к этим сегментам. Основной указатель находится в области памяти, доступной только SLIC. Область очередей процесса (Process Queue Space) — в ней размещаются одна или несколько очередей приема-передачи (SRQ) сообщений. На рисунке 9.4 показано расположение перечисленных компонентов в структуре процессов ILE. Обратите внимание, что в PAWA содержится список всех групп активизации (PAGP) и сами эти группы. На рисунке показаны четыре группы активизации, хотя как уже упоминалось, их может быть минимум две. По умолчанию всегда первая ACTGRP — это системная группа активизации, а вторая — пользовательская группа активизации.
 PCB = Блок управления процессом PAWA = Рабочая область активизации процесса PAGP = Родительская группа активизации ACTGRP = Группа активизации
Рисунок 9.4. Структура процесса ILE
PCB = Блок управления процессом PAWA = Рабочая область активизации процесса PAGP = Родительская группа активизации ACTGRP = Группа активизации
Рисунок 9.4. Структура процесса ILE
А теперь заглянем внутрь группы активизации.
Группа активизации ILE
Группа активизации содержит целиком или только ссылки на некоторые компоненты со странными, на первый взгляд, именами и аббревиатурами. Давайте сначала разберемся, что это за компоненты. Блок управления активизацией программы PACB (Program Activation Control Block) используется в процессе выполнения программы для хранения адресов. Эта структура позволяет находить процедуры и данные, связанные с программой. Для каждой активной программы имеется по одному PACB, и каждый PACB содержит один или несколько векторов связывания модулей. Вектор связывания модулей MBV (Module Binding Vector) предназначен для хранения адресов, используемых модулем. Он содержит адреса данных и процедур, на которые ссылается модуль. Справочник группы активизации (Activation Group Directory) представляет собой каталог имен, используемый для позднего связывания программ и данных. Справочная таблица процедур PRT (Procedure Reference Table) — одна на каждую группу активизации. Ее сегменты содержат точки входа процедур, используемые для вызовов между группами активизации и через процедурные указатели. Список кучи (Heap List) идентифицирует области кучи, связанные с данной группой активизации. Область кучи (Heap Spaces) состоит из управляющего сегмента и нескольких сегментов данных. Управление кучами для MI и SLIC осуществляется диспетчером кучи SLIC. Сегменты автоматической памяти (Auto Storage Segments) содержат стек, используемый группой активизации для автоматической памяти. Сегменты статической памяти (Static Storage Segments) — место, где располагается статическая память группы активизации. На рисунке 9.5 показано расположение перечисленных компонентов в группе активизации. PACB = Блок управления активизацией программы MBV = Вектор связывания модулей PRT = Справочная таблица процедур
Рисунок 9.5. Группа активизации ILE
PACB = Блок управления активизацией программы MBV = Вектор связывания модулей PRT = Справочная таблица процедур
Рисунок 9.5. Группа активизации ILE
Итак, подведем итоги. Каждый процесс AS/400 содержит PAWA. Внутри PAWA находятся PAGP, а также две или более ACTGRP. В каждой ACTGRP — PACB, содержащий несколько MBV, каталог группы активизации, PRT, список кучи, одну или несколько областей кучи, сегменты автоматической и статической памяти. Надеюсь, теперь Вам все понятно?
Исключения, события и прерывания
Если нечто не соответствует общему правилу, то его обычно называют исключением из правила. В вычислительных системах также имеются исключения из общих правил обработки. В этом разделе мы рассмотрим обработку исключений, событий и прерываний на AS/400. На аппаратном уровне обычно говорят о прерываниях. Как упоминалось выше в этой главе, прерывание — это событие, отличное от команды перехода, которое изменяет нормальный порядок выполнения команд. Причиной прерывания может быть выполнение некоторой команды или некоторое действие за пределами текущей программы, например, завершение операции ввода-вывода. Архитектура PowerPC определяет полноценный механизм прерываний, позволяющий процессору изменять свое состояние в ответ на внешние сигналы, ошибки и необычные ситуации, возникающие при исполнении команд. Мы еще рассмотрим это подробнее. Программы и процессы MI ничего не «знают» о прерываниях на аппаратном уровне. Однако, о прерывании, возникшем в результате исполнения программы MI, должно быть сообщено MI. За обнаружение, обработку и сообщение MI о прерываниях отвечает SLIC.Исключения и события MI
В MI различаются исключения и события. Исключение — это либо ошибка, обнаруженная машиной при исполнении команды, либо определенное состояние, обнаруженное пользовательской программой. Событие — это происшествие, возникающее в процессе работы машины и, напротив, представляющее интерес для ее пользователей. Исключения синхронны, то есть вызываются исполнением некоторой команды. События асинхронны, то есть их причина — за пределами исполняющейся в данной момент команды. Часто исключения и события очень легко перепутать. Рассмотрим несколько примеров. Предположим, что программа пытается разделить число на 0 — очевидная ошибка. Когда эта ошибка обнаружится, о ней будет сообщено с помощью исключения. Исключение синхронно, так как, если данные всегда одинаковы, та же самая ошибка будет происходить в том же самом месте при каждом выполнении программы. Теперь представим себе, что параллельно с программой исполняется операция ввода-вывода, например, чтение записи с диска. В некоторый момент времени операция ввода-вывода завершается, и об этом факте необходимо сообщить. Механизм сообщения о завершении ввода-вывода — это событие, так как его причина — действие, не связанное с выполняемой в данный момент командой. Оно асинхронно, то есть оно не связано с исполнением программы и может произойти в любой момент. Подобно подразделению исключений MI на два типа: ошибки и пользовательские состояния, — есть и два типа событий. Это объектные события, например, исчерпание максимума сообщений в очереди, и машинные события, например, истечение заданного интервала времени. Процесс MI следит за наступлением событий из определенного набора, и когда происходят все или некоторые из них, выполняет нужные действия. С появлением моделей программ и процессов ILE в модель исключений были внесены изменения. Исключение в MI — формально определенное сообщение процесса. Все сообщения процесса хранятся в пространстве очередей процесса, являющемся частью структуры процессов ILE, описанной в предыдущем разделе. Так как исключение доставляется как сообщение, то возможна задержка между сигнализацией об исключении и его обработкой. Эти характеристики описанной структуры исключений одинаковы и для исходных моделей, и для моделей ILE. С появлением ILE мониторинг и обработка исключений стали явно управляться пользователем MI. Мониторы исключений используются для отслеживания исключений. Существуют команды MI для включения и отключения мониторов исключений. Одновременно может быть включено несколько мониторов. У каждого из них свой приоритет, в соответствии с которым осуществляется поиск и обработка прерываний в том случае, если включено несколько мониторов. С каждым монитором всегда связана внешняя процедура ILE, обрабатывающая исключения. SLIC поддерживает мониторинг и обработку как событий, так и исключений. В главе 5 мы говорили, что машина ведет мониторинг доступа к системным объектам. Если добавить к этому некоторые специальные команды PowerPC, то получится почти полное представление о масштабах этой функции. Контроль за исключениями осуществляется, в основном, аппаратурой, которая сообщает о них процедурам обработки исключений SLIC с помощью механизма прерываний PowerPC. В следующем разделе мы рассмотрим компонент управления исключениями SLIC.Управление исключениями SLIC
 Управление исключениями в SLIC заключается, в основном, в маршрутизации. Маршрутизация запускается механизмом прерываний PowerPC, когда аппаратура обнаруживает прерывание. После возникновения исключения все соответствующие компоненты SLIC получают возможность обработать его. Если исключение обработано, то процесс продолжается, как будто ничего не произошло. Если же исключение не обработано SLIC, то процесс завершается и исключение передается соответствующему обработчику исключений ILE.
Прерывания классифицируются по тому, вызваны ли они исполнением конкретной команды или каким-то другим событием в системе. В архитектуре PowerPC определено 15 типов прерываний. Пять прерываний генерируются аппаратно, а именно:
сброс системы (System Reset) — прерывание при выключении или включении системы;
машинная ошибка (Machine Check), служащая для сообщения об аппаратных сбоях;
внешнее (External) — прерывание, уведомляющее процессор о том, что некоторое событие за его пределами (например, ввод-вывод) требует внимания;
монитор производительности (Performance Monitor), при включенном мониторинге производительности уведомляющий процессор о событии, за которым ведется наблюдение;
уменьшитель (Decrementer), используемый таймерами и извещающий процессор об истечении некоторого интервала времени.
Некоторые прерывания генерируются в результате выполнения команд. Перечислим их.
Память данных (Data Storage) — это прерывание сообщает, что команда предприняла безуспешные попытки доступа к хранилищу данных. Используется для сигнализации о невозможности трансляции эффективного адреса (страничная ошибка), нарушении защиты памяти или переполнении эффективного адреса (ЕАО).
Память команд (Instruction Storage) аналогично прерыванию памяти данных, но вызывается попыткой выбрать команду для исполнения.
Ошибка прямого сохранения (Direct-Store Error) также аналогично прерыванию памяти данных, но возникает при обращении по адресу прямого сохранения (DS). Отметьте, что по этому адресу не может произойти страничная ошибка.
Выравнивание (Alignment) происходит при попытке обращения к операнду, который не выровнен на необходимую границу памяти.
Программное (Program) прерывание используется для сообщений типа попытки процессора выполнить привилегированную команду при отсутствии у пользователя соответствующих прав или попытки применить неверный код операции.
«Нет плавающей точки» (Floating-Point Unavailable) — прерывание с этим названием возникает при попытке выполнить команду с плавающей точкой, если разряд в MSR указывает, что процессор не может выполнять таких команд. Архитектура PowerPC позволяет отключать операции с плавающей точкой.
Поддержка плавающей точки (Floating-Point Assist) — это прерывание используется для программной поддержки относительно редко используемых и сложных операций с плавающей точкой.
Трассировка (Trace) — прерывание, генерируемое после успешного выполнения каждой трассируемой команды. Возможность пошаговой трассировки всех команд или переходов включается установкой разрядов в MSR.
Системный вызов (System Call) — прерывания этого типа достигаются исполнением соответствующей команды PowerPC. Подробней об этом — в следующем разделе.
Системный вызов по вектору (System Call Vectored) — тип прерывания, похожий на системный вызов. Эта команда, которая также описана в следующем разделе, аналогична команде системного вызова, но может передавать управление любой из 128 процедур.
Для обработки прерываний в SLIC предусмотрены специальные процедуры. Когда аппаратура обнаруживает прерывание, управление передается одному из обработчиков исключений первого уровня FLEH (First Level Exception Handlers). То, каким образом осуществляется аппаратная передача управления, будет рассмотрено далее. Если одна из процедур FLEH обработала исключение (в основном именно так и происходит), то управление возвращается к нормальной обработке команд.
Если исключение вызвано командой и не было обработано, то FLEH передает управление обработчику исключений второго уровня SLEH (Second Level Exception Handler). SLEH обрабатывает менее частые исключения, такие как исключение блокировки системного объекта. Он также отвечает за выделение исключений, которые не могут быть обработаны SLIC. Если необработанное исключение возникло, когда система исполняла команду, транслированную MI, то SLEH передает управление генератору исключений MI.
Если же необработанное исключение произошло при исполнении команды SLIC, то SLEH передает управление обработчику исключений третьего уровня TLEH (Third Level Exception Handler). TLEH получает управление от SLEH, от обработчика машинных ошибок (если таковая произошла при выполнении процедуры SLIC), или от любой другой процедуры SLIC, обнаружившей исключение.
Сначала TLEH вызывает обработчики исключений компонентов CSEH (Component Specific Exception Handlers), которые были установлены различными компонентами SLIC. CSEH используются для освобождения ресурсов, занятых выполнением некоторой операции, или для очистки частичных результатов неудавшейся операции, или исполнения кода, позволяющего продолжать работу при ошибке. CSEH, которые должны выполняться для данной задачи, определяются блоками CSEH, присоединенными к TDE задачи. Каждый блок CSEH содержит адрес процедуры CSEH, указатель стека и данные, необходимые этой процедуре. После выполнения всех CSEH задачи управление возвращается обратно TLEH.
Затем TLEH определяет, как быть с данным исключением. Если исключение произошло в задаче SLIC, которая не является частью какого-либо процесса MI, то задача уничтожается. Если же исключение произошло в задаче, выполняющейся как часть процесса MI, то управление передается генератору исключений MI.
Генератор исключений MI подготавливает данные для сообщения процессу, выполняет некоторые операции очистки и отправляет сообщение в пространство очередей соответствующего процесса.
Управление исключениями в SLIC заключается, в основном, в маршрутизации. Маршрутизация запускается механизмом прерываний PowerPC, когда аппаратура обнаруживает прерывание. После возникновения исключения все соответствующие компоненты SLIC получают возможность обработать его. Если исключение обработано, то процесс продолжается, как будто ничего не произошло. Если же исключение не обработано SLIC, то процесс завершается и исключение передается соответствующему обработчику исключений ILE.
Прерывания классифицируются по тому, вызваны ли они исполнением конкретной команды или каким-то другим событием в системе. В архитектуре PowerPC определено 15 типов прерываний. Пять прерываний генерируются аппаратно, а именно:
сброс системы (System Reset) — прерывание при выключении или включении системы;
машинная ошибка (Machine Check), служащая для сообщения об аппаратных сбоях;
внешнее (External) — прерывание, уведомляющее процессор о том, что некоторое событие за его пределами (например, ввод-вывод) требует внимания;
монитор производительности (Performance Monitor), при включенном мониторинге производительности уведомляющий процессор о событии, за которым ведется наблюдение;
уменьшитель (Decrementer), используемый таймерами и извещающий процессор об истечении некоторого интервала времени.
Некоторые прерывания генерируются в результате выполнения команд. Перечислим их.
Память данных (Data Storage) — это прерывание сообщает, что команда предприняла безуспешные попытки доступа к хранилищу данных. Используется для сигнализации о невозможности трансляции эффективного адреса (страничная ошибка), нарушении защиты памяти или переполнении эффективного адреса (ЕАО).
Память команд (Instruction Storage) аналогично прерыванию памяти данных, но вызывается попыткой выбрать команду для исполнения.
Ошибка прямого сохранения (Direct-Store Error) также аналогично прерыванию памяти данных, но возникает при обращении по адресу прямого сохранения (DS). Отметьте, что по этому адресу не может произойти страничная ошибка.
Выравнивание (Alignment) происходит при попытке обращения к операнду, который не выровнен на необходимую границу памяти.
Программное (Program) прерывание используется для сообщений типа попытки процессора выполнить привилегированную команду при отсутствии у пользователя соответствующих прав или попытки применить неверный код операции.
«Нет плавающей точки» (Floating-Point Unavailable) — прерывание с этим названием возникает при попытке выполнить команду с плавающей точкой, если разряд в MSR указывает, что процессор не может выполнять таких команд. Архитектура PowerPC позволяет отключать операции с плавающей точкой.
Поддержка плавающей точки (Floating-Point Assist) — это прерывание используется для программной поддержки относительно редко используемых и сложных операций с плавающей точкой.
Трассировка (Trace) — прерывание, генерируемое после успешного выполнения каждой трассируемой команды. Возможность пошаговой трассировки всех команд или переходов включается установкой разрядов в MSR.
Системный вызов (System Call) — прерывания этого типа достигаются исполнением соответствующей команды PowerPC. Подробней об этом — в следующем разделе.
Системный вызов по вектору (System Call Vectored) — тип прерывания, похожий на системный вызов. Эта команда, которая также описана в следующем разделе, аналогична команде системного вызова, но может передавать управление любой из 128 процедур.
Для обработки прерываний в SLIC предусмотрены специальные процедуры. Когда аппаратура обнаруживает прерывание, управление передается одному из обработчиков исключений первого уровня FLEH (First Level Exception Handlers). То, каким образом осуществляется аппаратная передача управления, будет рассмотрено далее. Если одна из процедур FLEH обработала исключение (в основном именно так и происходит), то управление возвращается к нормальной обработке команд.
Если исключение вызвано командой и не было обработано, то FLEH передает управление обработчику исключений второго уровня SLEH (Second Level Exception Handler). SLEH обрабатывает менее частые исключения, такие как исключение блокировки системного объекта. Он также отвечает за выделение исключений, которые не могут быть обработаны SLIC. Если необработанное исключение возникло, когда система исполняла команду, транслированную MI, то SLEH передает управление генератору исключений MI.
Если же необработанное исключение произошло при исполнении команды SLIC, то SLEH передает управление обработчику исключений третьего уровня TLEH (Third Level Exception Handler). TLEH получает управление от SLEH, от обработчика машинных ошибок (если таковая произошла при выполнении процедуры SLIC), или от любой другой процедуры SLIC, обнаружившей исключение.
Сначала TLEH вызывает обработчики исключений компонентов CSEH (Component Specific Exception Handlers), которые были установлены различными компонентами SLIC. CSEH используются для освобождения ресурсов, занятых выполнением некоторой операции, или для очистки частичных результатов неудавшейся операции, или исполнения кода, позволяющего продолжать работу при ошибке. CSEH, которые должны выполняться для данной задачи, определяются блоками CSEH, присоединенными к TDE задачи. Каждый блок CSEH содержит адрес процедуры CSEH, указатель стека и данные, необходимые этой процедуре. После выполнения всех CSEH задачи управление возвращается обратно TLEH.
Затем TLEH определяет, как быть с данным исключением. Если исключение произошло в задаче SLIC, которая не является частью какого-либо процесса MI, то задача уничтожается. Если же исключение произошло в задаче, выполняющейся как часть процесса MI, то управление передается генератору исключений MI.
Генератор исключений MI подготавливает данные для сообщения процессу, выполняет некоторые операции очистки и отправляет сообщение в пространство очередей соответствующего процесса.
Аппаратное переключение контекста

Так как только что описанным процедурам обработки исключений может потребоваться доступ к привилегированным командам PowerPC, механизм прерываний должен иметь возможность переключать состояние процессора при передаче управления одной из таких процедур. Обычно говорят, что в этом случае происходит переключение контекста процессора. Контекст — это состояние процессора относительно привилегий, перемещения, защиты памяти, 64-разрядного режима и т. д. В дополнение к простому переключению, механизм прерываний должен выполнять синхронизацию контекста. Синхронизация означает, что аппаратура процессора обязана гарантировать завершение выполнения всех команд, запущенных до прерывания, в том же контексте, в котором они были запущены. Команды, следующие после этой операции, должны выбираться и исполняться в новом контексте. В главе 8 мы рассматривали регистр состояния машины (MSR) и значение некоторых его битов. Архитектура PowerPC определяет для MSR и некоторые другие биты, описанные в предыдущем разделе. Оставшиеся биты рассматриваться не будут, так как не относятся к обсуждаемой теме. Здесь лишь важно понимать, что значения всех битов MSR определяют контекст процессора. Значения битов могут измениться при прерывании процессора. Если при вызове процедуры SLIC необходимо изменить контекст процессора, то может быть использована команда «Системный вызов» («sc»). Эта команда в транслированных программах MI позволяет обратиться за обслуживанием к компонентам ОС в SLIC. Как мы только что упоминали, при исполнении команды «sc» процессор генерирует прерывание системного вызова. Читатели, знакомые с System/370, могут заметить, что этим команда «sc» в PowerPC очень похожа на команду «Вызов супервизора» («SVC») в архитектуре System/370. Архитектура PowerPC ведет свою родословную от разработанного в середине 70-х миникомпьютера 801, архитектура которого создавалась под большим влиянием мэйнфреймов System/370. В некотором роде и MSR — аналог «Слова состояния программы» («PSW») System/370. При возникновении прерывания аппаратура процессора PowerPC сначала выполняет синхронизацию контекста, чтобы гарантировать, что обработка прерывания не начнется, пока не будет определено, какие прерывания вызовут выполняющиеся в данный момент команды. Обратите внимание: у каждого прерывания есть приоритет. Так что если обработки ожидают несколько прерываний, то первым будет выбрано прерывание с наивысшим приоритетом. Затем эффективный адрес команды, исполнявшейся при возникновении прерывания, сохраняется в специальном 64-раз рядном регистре процессора, который называется «Регистр сохранения-восстановления состояния машины 0» или SSR 0 (Machine Status Save/Restore Register 0). Если прерывание было вызвано командой «sc», то в SSR 0 будет помещен адрес команды, следующей за «sc». Далее некоторые биты текущего MSR сохраняются в другом 64-разрядном регистре, который называется SSR 1. Наконец, остальные разряды SSR 1 заполняются информацией, специфичной для типа данного прерывания. После сохранения текущего состояния машины, аппаратура прерываний изменяет некоторые биты MSR, причем для каждого типа прерываний — свои. В частности, биты перемещения (MSRIR и MSRDR) всегда отключаются, так что процедуры — обработчики прерываний используют реальные адреса и не могут вызвать страничных ошибок. После изменения битов MSR аппаратура прерываний устанавливает адрес следующей выбираемой команды по определенному смещению относительно некоторого базового адреса. Архитектурой PowerPC определены конкретные смещения для каждого типа прерываний. Еще один бит MSR, называемый префиксом прерывания, выбирает один из двух базовых адресов. В результате только что описанной аппаратной обработки прерывания управление передается первой команде одного из обработчиков прерываний SLIC. Перед этим происходит переключение контекста процессора, так что процедура может, например, выполнять привилегированные команды. В конце процедуры обработки прерываний выполняется еще одна специальная команда PowerPC — «Возврат из прерывания» или «rfi» («Return From Interrupt))). По этой команде происходит восстановление процессора в состояние, в котором он находился до прерывания. Сначала часть битов SSR 1 помещается в соответствующие биты MSR. Затем, под управлением нового значения MSR, выбирается следующая команда по адресу из SSR 0. Если на момент возникновения только что обработанного прерывания имелись и другие ожидающие исключения, то перед выполнением первой команды в контексте, установленном командой «rti», генерируется прерывание, связанное с ожидающим исключением наивысшего приоритета. Две только что описанные команды PowerPC: «sc» и «rti», — позволяют процессору вызывать, если надо, обработчик прерывания и возвращаться к нормальной деятельности, когда прерывание обработано. В AS/400 мы хотели иметь аналогичный механизм, позволяющий одной процедуре SLIC вызывать другую. Например, планировалось обеспечить высокую эффективность вызова SLEH из FLEH. С этой целью в архитектуре PowerPC появились две новые команды: «системный вызов по вектору» или «scv» («System Call Vectored») и «возврат из системного вызова по вектору» или «rfscv» («Return From System Call Vectored»). Команда «scv» похожа на команду «sc», но есть и несколько важных отличий. Так, вместо передачи управление только по одному адресу, команда «scv» задает один из 128 адресов, по каждому из которых располагается отдельная процедура SLIC. Таким образом, с помощью команды «scv» можно эффективно передавать управление между процедурами SLIC. Другая отличительная черта «scv» в том, что эта команда не изменяет значения битов MSR. Это означает, например, что вызванная процедура может использовать виртуальные адреса. При использовании виртуальной адресации процедуры SLIC можно писать так, что будет возможна откачка их страниц на диск. Кроме того, команда «scv» не использует регистры SSR 0 и SSR 1 для сохранения состояния машины. Вместо этого, она задействует два процессорных регистра общего назначения. Команда «rfscv», как это и следует из ее названия, выполняет возврат после «scv».
Задания и управление ими OS/400
Прочитав предшествующие разделы, Вы увидели, как развита современная структура процессов. Наряду с огромными возможностями, она отличается и огромной сложностью в управлении, которое едва ли под силу рядовому пользователю. В соответствии с философией технологической независимости и интегрированности, AS/400 берет и эту обязанность на себя посредством компонента управления заданиями OS/400. Пользователь имеет дело с определением задания, которое точнее соответствует прикладной программе. Все остальное делает OS/400 и нижележащие компоненты. Построение всей структуры заданий поверх модели процессов имеет один недостаток: намного меньшую гибкость, чем при настройке характеристик процесса в соответствии с характеристиками конкретного приложения. Подобная настройка позволяет повысить производительность приложения, которому не нужны все возможности, предоставляемые структурой задач. Фундаментальным строительным блоком многих новых ОС становится облегченный процесс или подпроцесс, который обычно называют потоком (thread). Приложения, написанные для потоковой модели, не используют полнофункциональную структуру задач, и вследствие этого достигают большей производительности при переключении с одной программы на другую. Важно отметить, что структура задач AS/400 на аппаратном уровне — одна из наиболее эффективных. В коммерческом приложении значительная часть (до 80 — 90 процентов) обработки, выполняется ОС, а не самим приложением. Приложение запрашивает обработку у ОС, вместо того чтобы выполнять ее самостоятельно. Непосредственно выполнением такой обработки занимается, в основном, SLIC, где структура задач очень эффективна. Давайте рассмотрим, как в AS/400 поддерживаются потоки, и как это позволяет переносить приложения, написанные для других ОС.Концепции управления заданиями
Управление заданиями, переданными пользователем AS/400, выполняется компонентом управления заданиями OS/400. Задание — это единица работы, переданной на выполнение. Как Вы помните, управление заданиями различает несколько типов заданий, включая традиционные интерактивные и пакетные. В предшествующих разделах обсуждался процесс, как единица работы, переданной управлением заданиями нижележащим компонентам. Объекту-процессу MI нет аналогов в OS/400. Задание — это не объект OS/400. Не являются таковыми и маршрутизация или подсистемы, которые мы скоро будем рассматривать. Управление заданиями имеет дело непосредственно с процессами. Задание может выполняться в рамках одного или нескольких процессов, запуск которых осуществляется одним или несколькими управляющими процессами. Каждый новый запуск процесса при выполнении задания называется шагом маршрутизации (routingstep).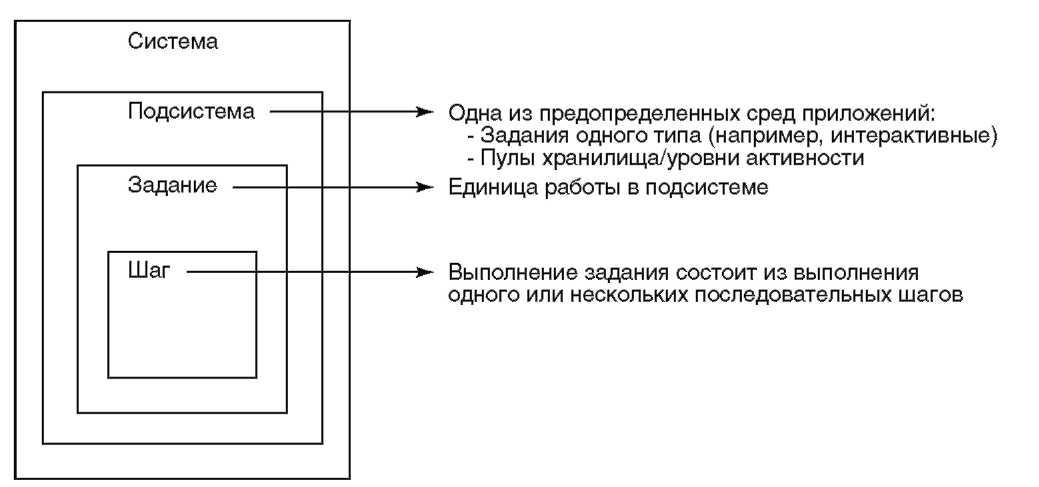 Рисунок 9.6. Концепции управления работой
Рисунок 9.6. Концепции управления работой
Управление заданиями рассматривает систему как иерархию доменов, показанную на рисунке 9.6. Шаг — самый низкий уровень этой иерархии. Следующий уровень — задание, которое обрабатывается одним или несколькими последовательными шагами. Задания находятся в подсистемах, каждая из которых содержит задания сходного типа, например, все интерактивные задания. Как мы скоро увидим, подсистемы управляют некоторыми системными ресурсами. Наконец, самый верхний уровень иерархии — собственно система, где повсеместно используются некоторые системные параметры и сетевые атрибуты. Пример — имя компьютера в вычислительной сети.
Подсистемы
Подсистема AS/400 — это одна из предопределенных операционных сред. Все задания в подсистеме должны иметь одинаковый тип (например, пакетные) и совместно использовать определенные системные ресурсы. Так как конфигурация подсистем и то, какие именно задания выполняются в данной подсистеме, могут быть разными на разных AS/400, то нет гарантии, что все задания в подсистеме однотипны. С каждой подсистемой связан объект OS/400 под названием описание подсистемы. Описание подсистемы содержит общую информацию о выделенных подсистеме ресурсах и указывает на другие объекты OS/400: описание задания, классы и программы, — предоставляющие дополнительную информацию об этой подсистеме. Описание задания — это объект OS/400, задающий атрибуты и ресурсы, связанные с заданием. Он определяет: список библиотек (по умолчанию); очередь заданий; данные маршрутизации; принтер (по умолчанию); приоритет планировщика вывода; профиль пользователя. Класс представляет собой объект OS/400, содержащий параметры, которые задают среду выполнения. Некоторые из них относятся к выделенным заданию ресурсам процессора. Например, может быть ограничено число процессов класса, выполняющихся одновременно. Это позволяет управлять объемом взаимного влияния процессов, конкурирующих за один и тот же системный ресурс. Данный предел, обычно называемый уровнем активности, связан с пулом памяти. Пул памяти, (не путать с пулом вспомогательной памяти!) — это средство резервирования для подсистемы некоторого объема основной (оперативной) памяти. В основной памяти может быть размещено до 16 пулов памяти, один из которых всегда зарезервирован машиной. Пул памяти — это часть памяти, куда осуществляется динамическая подкачка страниц процессов, связанных с этим пулом. Например, один пул памяти может быть выделен для всех интерактивных заданий, а другой — для всех пакетных. Такой подход позволяет гарантировать, что пакетное задание не отберет себе страничный фрейм у интерактивного задания, и таким образом не повлияет на время ожидания ответа пользователем. Пакетные задания могут отбирать только страничные фреймы у других пакетных задач из пакетного пула памяти. Пулы памяти определяются в описании подсистемы. Размеры, число и уровни активности пулов памяти управляются пользователем системы. Таким образом, система может быть настроена так, чтобы обеспечить максимальную производительность именно для данного пользователя. Подобная настройка в AS/400 при помощи различных средств выполняется вручную или автоматически при изменении характера рабочей нагрузки.Старая и новая структуры задания
С появлением модели процессов ILE, описанной ранее, изменилась и структура задания в AS/400. Как именно — можно понять, сравнив ресурсы приложений, доступные в старой и новой структурах заданий, а также особенности их использования. Как правило, ресурсы приложений для задания включают в себя разделяемые файлы, управление транзакциями и память.| Старая структура задания | Новая структура задания на основе |
| модели процессов ILE | |
| Разделяемые файлы видимы всем | Разделяемые файлы видимы всем |
| прикладным программам задания | прикладным программам задания, |
| либо каждое приложение определяет | |
| собственное использование файлов | |
| Внешние имена — общие на уровне | Область видимости внешних имен — |
| задания, а не на уровне приложений | одиночное приложение, то есть каж |
| дое приложение задания имеет свое | |
| собственное пространство имен для | |
| внешних переменных | |
| Управление транзакциями | Управление транзакциями осуществ |
| осуществляется для всего задания | ляется как на уровне задания, так и |
| на уровне приложений | |
| Допускается только одна активизация | Допускаются множественные активи |
| программы в задании | зации одной и той же программы. |
| Каждая активизация имеет собствен | |
| ные (защищенные) области памяти | |
| Выделяется только одна область | У каждой программы своя собствен- |
| статической и автоматической (стек) | ная защищенная статическая, авто- |
| памяти и одна область динамической | матическая (стек) и динамическая |
| памяти для каждого языка | (куча) память |
| программирования |
Процессы, задачи, задания, группы активизации и потоки
Как уже упоминалось, первоначально в AS/400 было определено три уровня работы. Самый низкий уровень, под MI, — задача. Процесс «живет» на уровне MI и построен на структуре задач SLIC. Поверх модели процессов MI OS/400 в качестве единицы работы поддерживает задание. Большинство других ОС работают непосредственно с процессами. Но не OS/400. В этом отношении задание в ней — аналог процесса в других ОС. Полнофункциональное задание обеспечивает лучшие возможности разделения ресурсов и защиты, чем процессы в других ОС; однако, для создания такого задания нужно больше времени. Задание AS/400 можно называть «полновесным». Приложения, написанные специально для AS/400, обычно соответствуют структуре полнофункционального задания, то есть, исполняются внутри одного задания. Динамическое создание множества заданий для одного приложения не рекомендуется, из-за больших накладных расходов. Конечно, для некоторых других ОС приложения пишутся не так. Например, Unix и Windows NT определяют структуру, в которой процессы могут быстро создаваться, существовать и затем разрушаться. Приложения, написанные для таких ОС, часто используют множество процессов. Для достижения достаточной производительности приложениям такого типа нужен очень «легковесный» процесс. Данная тенденция привела к новому пониманию процесса. Например, в модели POSIX процессы разделены на два отдельных компонента. Первый содержит все ресурсы для группы взаимодействующих единиц. Эти ресурсы включают в себя виртуальную память, коммуникационные порты и файлы, выделенные процессу. Некоторые ОС даже называют эту часть процесса задачей. Вторая часть процесса — активная среда выполнения, обычно называемая потоком. В процессе может исполняться один или несколько параллельных потоков. Исходное определение процесса было ограничено только одной исполняющейся единицей. Новое определение допускает несколько единиц исполнения — потоков. Поток — это подпроцесс, который имеет доступ к некоторым собственным ресурсам, а также к разделяемым ресурсам процесса. Таким образом, в многопоточном процессе может исполняться несколько потоков, совместно использующих системные ресурсы. Достоинство потоков в том, что они позволяют разным частям одного приложения исполняться параллельно. Особенно важны потоки в распределенной среде, они обязательны для стандарта, известного как DCE (Distributed Computing Environment). DCE использует модель процессов POSIX. Поскольку мы хотели реализовать в AS/400 интерфейсы DCE и POSIX, нам нужно было найти некоторый способ поддержки потоков POSIX. Мы рассмотрели две модели. Первая — встроенные потоки, где в процессе принимают участие множество TDE, для каждой группы активизации — собственный. Таким образом, группа активизации становится отдельной единицей диспетчирования, своего рода аналогом потока. Данная модель достаточно точно соответствует общепринятой модели потоков. К сожалению, она также требовала внесения в OS/400 множества изменений, больше, чем позволяло время, отведенное на проект V3R1. Поэтому для начала нам пришлось выбрать вторую, несколько менее удачную модель. Вторая модель потоков основывалась на концепции разделяемой группы активизации. Несколько заданий OS/400 могут разделять одну группу активизации. Таким образом, поток — задание OS/400, использующее разделяемую группу активизации. Процесс POSIX может быть представлен как совокупность всех заданий OS/400, совместно использующих группу активизации. Все потоки процесса POSIX совместно используют общие статическую память и кучу, при этом у каждого из них своя автоматическая память (стек). Такое использование задания OS/400 в качестве потока, успешно работает, но имеет один существенный недостаток: для создания полнофункционального задания требуется больше времени, по сравнению с другими системами, где применяются «легковесные» потоки. Для повышения производительности AS/400 мы предусмотрели пул заранее созданных заданий. Когда нужно быстро создать поток, используется одно из заданий пула. При разрушении потока задание возвращается в пул. Данная модель потоков была представлена как часть CPA (Common Programming) API в V3R1. Начальная цель была достигнута, но мы знали, что это паллиатив. Хотелось перенести на AS/400 несколько других приложений, например, Lotus Domino. Мы рассмотрим Domino в его связи сAS/400 в главе 11, сейчас же нам следует признать, что Domino написан для потоковой модели. Так, подгоняемые мечтой о нормальной работе Domino на AS/400, мы начали проектирование встроенных потоков для версии V4 OS/400. На рисунке 9.7 показано соотношение двух потоковых моделей системы и средств поддержки приложений (application enabler). Последние включают в себя библиотеки времени исполнения для языков, типа С, С+ + и Java, интегрированную файловую систему и библиотеки классов объектов. В главе 11 мы рассмотрим Java и его объектную модель, а также модели IBM SOM (System Object Model) и DSOM (Distributed System Object Model). Рисунок 9.7. Средства поддержки приложений для потоков
Рисунок 9.7. Средства поддержки приложений для потоков
Мы полагаем, что с течением времени все больше и больше приложений будет создаваться для потоковой модели. Поддержка потоков часто позволяет приложениям, написанным для какой-либо другой ОС, эффективно работать на AS/400.
Выводы
В разных ОС процессы реализованы по-разному. Каждая система определяет мощность процесса, его структуру, а также то, как он должен быть защищен. Модель процессов AS/400 доказала свою высокую эффективность и способность поддержки важнейших приложений. Современнейшая структура задач, на основе которой работают все остальные функции системы, позволяет моделям процессов и заданий эволюционировать для нужд будущих сред приложений. В следующей главе мы рассмотрим подсистему ввода-вывода и направления ее развития для поддержки будущих приложений AS/400. Структура задач играет важную роль в системе ввода-вывода. Это верно и теперь, и в будущем.Глава 10
Система ввода-вывода
Ввод-вывод — это Родни Дэнжерфилд[ 76 ] (Rodney Dangerfield) вычислительных систем: на него никто не обращает внимания. Всеобщий любимчик — процессор, а подсистема ввода-вывода рядом с ним — падчерица. Вот пример: когда надо охарактеризовать производительность компьютера чаще всего начинают считать мегагерцы. Создается впечатление, что сегодняшних разработчиков процессоров больше всего заботит максимум мегагерц, а не другие аспекты общей архитектуры. Между тем, пусть мегагерцы даже и показывают, как быстро «вертится» процессор, они все же мало что говорят о производительности вычислительной системы в целом. Вспомним главу 2, где обсуждалась подсистема памяти, и то, как важна ее роль в общей производительности вычислительной системы. Роль ввода-вывода не менее значима. Подсистема ввода-вывода определяет время отклика и производительность большинства компьютеров. Именно эти параметры больше всего волнуют заказчиков, даже если разработчикам процессоров нет до них дела. Быстро приближается время, когда вычислительные системы, начиная от простейших ПК до самых быстрых суперкомпьютеров, будут использовать одну и ту же технологию микропроцессоров. Тогда единственным их отличием станут системы ввода-вывода. Да и сам по себе ввод-вывод — важнейший компонент системы. В конце концов, без него Ваш мощнейший процессор будет просто бормотать что-то «внутри себя». Что же такое подсистема ввода-вывода? Это группа аппаратных и программных компонентов, отвечающих за обработку ввода и доставку вывода на различные устройства, подключенные к системе. Всякий раз, когда Вам нужен некий системный ресурс, — например, требуется прочитать или записать файл, запросить выполнение программы, вызвать другой системный объект, создать или уничтожить объект, поработать с каким-либо устройством — и этого ресурса еще нет в памяти, компьютер должен обратиться к системе ввода-вывода, чтобы считать или записать, создать или удалить ресурс. Как я уже говорил, в компьютере мало что происходит без участия системы ввода-вывода. В прошлом AS/400 не обладала очень уж быстрыми процессорами. Тем не менее, она прекрасно выглядела при сопоставлении с другими системами и, зачастую, могла посрамить систему с более быстрым процессором. Совершать такие подвиги ей позволяло и позволяет «секретное оружие» — одна из самых искусных и мощных систем ввода-вывода. Упрощенно, есть два способа проектирования системы ввода-вывода. Можно полностью положиться на процессор, и взвалить на него все вычисления и обработку ввода-вывода. Тогда в один момент времени процессор занят исполнением команд различных пользовательских и системных программ, в другой — занимается управлением вводом-выводом. Такой тип ввода-вывода пришел из мира ПК и Unix, где ввод-вывод очень прост. Беда лишь в том, что процессор в каждый момент времени может делать лишь что-то одно. Интенсивный ввод-вывод негативно влияет на остальные вычисления в системе. При другом подходе для обработки ввода-вывода используются отдельные процессоры. Это позволяет выполнять множественные операции ввода-вывода параллельно, лишь незначительно или вообще не снижая производительность главных процессоров. Именно такой подход, с использованием множественных процессоров ввода-вывода (IOP), применяется в AS/400. Немногие могут похвастаться, что знают что-либо о структуре ввода-вывода AS/400, помимо факта наличия множественных IOP, и буквально единицы понимают, как это работает. В этой главе мы рассмотрим некоторые аспекты системы ввода-вывода AS/ 400, как самые популярные, так и не очень известные. Начнем с эволюции системы ввода-вывода и причин, ее стимулировавших.Время перемен
Система ввода-вывода AS/400 находится на переходном этапе. В начале устройства ввода-вывода подсоединялись к системе только посредством IOP, подключенных к особой шине ввода-вывода. Она называется шиной SPD[ 77 ] и отлично служит на протяжении многих лет, включая серию AS/400е. Лишь сейчас мы начали использовать в AS/400е и другие шины ввода-вывода. У нестандартной шины SPD крупный недостаток: почти вся поддержка для нее ограничена разработками IBM. Заказчики не могут использовать иные программы и драйверы устройств, напрямую обращающиеся к шинам, IOP или устройствам ввода-вывода, за исключением весьма ограниченных средств OS/400. Впрочем, есть несколько примеров сторонних разработок, наиболее значительные из них — IOP для факсов и беспроводных ЛВС. Сейчас мы начали использовать стандартные интерфейсы ввода-вывода, что позволит разнообразить выбор дешевых устройств.Базовые концепции ввода-вывода
Пока мы еще не погрузились слишком глубоко в работу компонентов системы ввода-вывода, рассмотрим основополагающие понятия. Устройства ввода-вывода подключаются к компьютеру с помощью шины ввода-вывода. Шина — это просто электрическое соединение между двумя аппаратными компонентами. Часто, между компьютером и устройством располагается много шин. Обычно, шина ввода-вывода насчитывает примерно от 20 до 100 линий, некоторые из которых используются для передачи данных, а другие — для передачи управляющей информации на устройство и назад. Например, в шине SPD 32 линии (каждая соответствует биту) для передачи данных, 8 — для передачи команд и информации состояния, 8 — для идентификации точек отправления и назначения и несколько линий управления. Эти линии можно рассматривать как отдельные провода, но на самом деле там используются лишь несколько высокоскоростных оптических линий, и электрические сигналы посылаются по ним как цепочки разрядов, так что аналогия с отдельными проводами нарушается. Устройство ввода-вывода состоит из двух частей. Одна содержит большую часть электроники и называется контроллером ввода-вывода, другая — само физическое устройство, например, диск. Задача контроллера состоит в управлении устройством и обслуживании доступа к шине. Например, когда программе нужны данные с диска, она посылает команду контроллеру диска, который затем выдает устройству команды позиционирования и другие. В простейшем компьютере, например в ПК, для соединения процессора, памяти и адаптеров ввода-вывода используется единственная шина. Адаптером ввода-вывода обычно называют контроллер ввода-вывода, часть или вся электроника которого расположена на плате ПК. Задача адаптера — преобразование специфического интерфейса устройства ввода-вывода в стандартный интерфейс шины ПК. Таким образом, в ПК могут быть установлены адаптер дисплея, адаптер принтера и так далее для каждого устройства. А любая электроника, расположенная на самом устройстве, по-прежнему называется котроллером. Единственную шину ПК, соединяющую процессор и память, часто называют локальной шиной. Она работает на той же тактовой частоте, что и процессор (или на какой-либо части это частоты). До последнего времени адаптеры большинства ПК подключались к локальной шине непосредственно. Шина использовалась не только кот-роллерами ввода-вывода, но также и процессором для выборки команд и данных. Если процессор и адаптер ввода-вывода пытаются использовать локальную шину в один и тот же момент времени, то выбор между ними делает микросхема, называемая арбитром шины. Обычно, предпочтение отдается адаптеру ввода-вывода, так как диски и другие устройства нельзя останавливать из-за угрозы потерять информацию. Когда устройство ввода-вывода не вмешивается, процессор использует все циклы локальной шины для своих нужд. Но если при этом будет работать устройство ввода-вывода, то оно будет запрашивать и получать управление шиной по мере необходимости. Это явление, называемое кражей циклов (cycle stealing), замедляет работу системы. Новейшая тенденция состоит в установке на ПК отдельной шины, изолированной от процессора, но по-прежнему имеющей доступ к основной памяти. Для подключения этой отдельной шины к локальной шине и к памяти используется контроллер шины памяти. В этом случае контроллер также конкурирует за циклы локальной шины, но теперь множество устройств может быть подключено к отдельной шине. Преимущество отдельной шины в том, что у нее свой тактовый генератор, который работает с фиксированной скоростью и независим от процессора. Это удешевляет подключение устройств, работающих с процессорами любой частоты. Вероятно, самая популярная из таких отдельных шин — шина PCI (Peripheral Component Interconnect). Частота шины PCI равна 33 МГц, и в будущем планируется ее повышение. Некоторые компоненты ЛВС и интерфейсы жестких дисков, такие как SCSI (Small Computer System Interface), иногда по-прежнему подключаются к локальной шине напрямую. К шине PCI можно подключить до 16 плат адаптеров, обеспечивающих интерфейс устройства ввода-вывода к шине. Стандарт PCI определяет тип используемого разъема, а также размер и форму плат. Обычно, эти параметры называют фактором формы PCI (PCI form factor). Только что описанная структура ввода-вывода ПК чаще всего неприемлема для более мощного компьютера, выполняющего много операций ввода-вывода. Большим системам требуется несколько шин, а также желателен некоторый способ разгрузки основного процессора. Один из таких способов — использование канала, иначе говоря, специализированного компьютера, устанавливаемого рядом с основным процессором. Шины ввода-вывода подключаются непосредственно к каналу, а не к основному процессору. У канала собственный набор команд, предназначенный специально для взаимодействия с присоединенными к шине адаптерами и обмена данных между устройством ввода-вывода и памятью. Канал получает программы (так называемые канальные) от основного процессора. Такие программы могут выполняться каналом параллельно с выполнением других программ основным процессором. Таким образом, эти два процессорных устройства мало влияют друг на друга. Когда канал завершает обработку своей программы, он прерывает основной процессор для получения нового задания. Есть два основных типа каналов — селекторные и мультиплексные. Селекторный канал предназначен для поддержки скоростных устройств, таких как диски, и может в каждый момент времени обмениваться данными только с одним устройством. Мультиплексный канал обменивается данными со многими медленными устройствами, такими как терминалы, поочередно передавая по шине данные для каждого из них. За один прием может передаваться один байт или блок байтов. В зависимости от этого мультиплексные каналы подразделяются на байт-мультиплексные и блок-мультиплексные. Оба типа каналов поддерживаются в System/370. Многие характеристики канала в System/38 заставляли вспомнить System/370. Возврат к старому дизайну объяснялся иллюзией проектировщиков, думавших, что они делают System/370. Но в отличие от System/370, поддерживавшей несколько селекторных и мультиплексных каналов, на System/38 был только один канал. Для читателей, любящих точность, канал System/38 может быть описан как блок-мультиплексный канал, работающий в режиме фиксированной передачи (fixed-burst mode). Адаптеры ввода-вывода, использовавшиеся в System/38 для фактического управления устройствами, были довольно примитивны, то есть большая часть логики выполнения операции ввода-вывода была возложена на канал. System/34 и System/36, не имевшие каналов, использовали для управления устройствами ввода-вывода интеллектуальные процессоры, причем System/34 — разные процессоры для разных устройств. Что касается System/36, то применявшийся в ней CSP (Control Storage Processor), о котором я говорил в главе 3, был принят в качестве стандарта для большинства процессоров ввода-вывода. Поэтому к System/36 могли быть подключены адаптер диска, адаптер рабочей станции и адаптер линий связи — каждый со своим отдельным CSP. В больших System/36 для ввода-вывода использовались несколько CSP. Может быть, читатели помнят, что такие адаптеры назывались в терминологии System/36 контроллерами. Но так как они располагались на платах внутри корпусов, современная терминология велит называть их адаптерами. В AS/400 нет такого канала, как в System/38, а вместо него используются одна или несколько шин ввода-вывода, к которым подключены интеллектуальные процессоры. Большая часть обработки ввода-вывода выполняется этими IOP. Такая структура гораздо ближе к System/36, нежели к System/38. Впрочем, она отличается них обеих. Шине SPD и архитектуре IOP также присущи определенные способности к изоляции ошибок, что позволяет AS/400 ограничить последствия сбоев устройств, IOP и шин ввода-вывода. В результате AS/400 может «пережить» такие сбои ввода-вывода, которые на других системах, — например, на ПК или рабочей станции Unix — приводят к краху.Промышленные стандарты ввода-вывода
Стратегия развития AS/400 состоит в заимствовании новых структур ввода-вывода, соответствующих основным промышленным стандартам шин ввода-вывода и подключения устройств. Такой структурой быстро становится шина PCI, которую сегодня AS/ 400 непосредственно поддерживает наряду с SPD. Как мы увидим далее, в серии AS/ 400е сочетается надежность структуры шины SPD с легкодоступными компонентами PCI. С течением времени в AS/400 могут быть также включены новые стандартные шины, такие как ANSI Fiber Channel Standard. Одна из причин перехода на PCI — ее цена. Платы адаптеров PCI дешевле, так как не требуют отдельного IOP для каждого адаптера, как SPD. Один из способов уменьшения стоимости адаптеров SPD — использование MFIOP (Multifunction IOP). MFIOP содержит один IOP и допускает подключение к этой многофункциональной плате различных «дочерних» плат, у которых нет своих IOP. Дочерние платы обычно называются адаптерами ввода-вывода или IOA (I/O Adapter). При такой схеме соединения несколько IOA могут использовать общий IOP, что сокращает общую стоимость системы. Даже при использовании MFIOP платы адаптеров стандарта PCI, применяемые в обычном ПК, дешевле, чем SPD. Причина здесь — в конструктивных особенностях последней. Каждая плата адаптера SPD содержится в алюминиевом корпусе-книжке, а книжки — в специальной обойме. Такой способ размещения надежен, но дорог. Переход на PCI происходит постепенно, начиная с младших моделей серии AS/ 400е. Все эти модели поддерживают только шину и адаптеры PCI, что дает им возможность очень агрессивно конкурировать с ПК-серверами. Средние модели используют адаптеры как PCI, так и SPD. Что касается старших моделей серии, то в них предусмотрена поддержка только шины и адаптеров SPD, PCI же отложена до следующих версий. Давайте теперь подробней рассмотрим использование PCI в различных моделях. Сервер начального уровня AS/400е (известный также как Eiger), впервые объявленный в V3R7 как Advanced Entry, имеет только шину PCI. Такие серверы используют новый вид IOP. Если обычный IOP поддерживает интерфейс к конкретному типу устройств, то новый IOP — интерфейс шины PCI (до 16 адаптеров), что сравнимо с SPD MFIOP, использующим один IOP и несколько IOA. Сам новый IOP интегрирован как компонент на планарной плате Eiger. Эта плата очень напоминает материнскую плату обычного ПК, и к ней могут подключаться непосредственно платы адаптеров PCI. Новый IOP в качестве интерфейса между AS/400 и шиной PCI позволяет нам обеспечить тот же уровень надежности, что и шина SPD. IOP изолирует шину PCI от основного процессора. По сравнению с серверами ПК, которые вынуждены использовать для обработки ошибок и вспомогательных операций основной процессор, — это шаг вперед. Хочу обратить внимание на то, что для новых IOP используется процессор PowerPC. Прежние IOP, используемые адаптерами ввода-вывода SPD, были продукцией различных производителей, в основном, Motorola. Новая стратегия IBM заключается в использовании PowerPC для всех будущих IOP. В моделях среднего уровня, выпускающихся в корпусах Millenium, применяется тот же IOP, что и в Eiger. Базовые устройства ввода-вывода (такие как внутренние диски, компакт-диск и лента) используют PCI. На младших моделях среднего класса, как и на Eiger, поддерживаются только такие адаптеры. Старшие модели среднего уровня имеют возможность установки отдельной обоймы плат SPD или отдельной платы адаптеров PCI внутри корпуса Millenium по выбору. Эти корпуса в зависимости от комплектации могут поддерживать или только адаптеры PCI, или сочетания базовых адаптеров PCI и адаптеров SPD. Старшие модели серии AS/400е, устанавливаемые в высокие корпуса Mako, пока поддерживают только шину и адаптеры SPD. Поскольку большие системы, в основном, — модернизация существующих AS/400, то такое положение приемлемо. С течением времени потребность в адаптерах PCI для больших систем будет расти, и мы добавим соответствующую поддержку. Рисунок 10.1. Аппаратная структура ввода-вывода
Рисунок 10.1. Аппаратная структура ввода-вывода
Для иллюстрации структуры ввода-вывода в новых корпусах Mako я использую 12-канальную конфигурацию SMP, описанную в главе 2. По сути, рисунок 10.1 — это рисунок 2.6 с 12-канальной конфигурацией SMP, добавлена лишь структура ввода-вывода. Для подключения всей системы ввода-вывода в корпусах Mako используется SAN (System Area Network)[ 78 ]. На рисунке показаны локальные шины 6хх адреса и данных, связанные интерфейсами шины ввода-вывода и распределенные с помощью одного или нескольких соединений SAN по кольцевой топологии. В старших моделях AS/400е адаптеры шины SPD содержатся в отдельном корпусе и подключаются к Mako с помощью SAN. Соединение SAN может быть либо медным, либо оптоволоконным, в зависимости от расстояния между корпусами. На рисунке показано подключение шин SPD и PCI. В V4R1 поддерживается только подключение шины SPD. Подключение шины PCI будет добавлено позднее и проиллюстрировано здесь только для того, чтобы показать, как похожи подключения этих двух шин. IBM SAN поддерживает протокол SCIL (Scalable Coherent Interface Link) основанный на стандарте IEEE 1596 SCI. Протокол модифицирован для обеспечения уровня целостности данных, необходимой коммерческим заказчикам. Посмотрите еще раз на рисунок 10.1. SAN AS/400 предоставляет два дуплексных порта соединения для каждого интерфейса шины ввода-вывода. Каждый из портов состоит из двух однонаправленных 1-байтовых линий данных, которые «гонят» данные в противоположных направлениях для обеспечения полного дуплекса. Эти две линии данных могут быть соединены по кольцевой топологии, которая используется для подключения плат ввода-вывода. На рисунке показано два таких кольца. На тактовой частоте 250 МГц каждый из них обеспечивает скорость передачи 250 МБ/с. Еще одна интересная особенность SAN — способ, используемый для «прокачки» данных через соединение. Так как соединение SAN является асинхронным, то с передачей данных не связана какая-либо тактовая частота. В противоположность этому, при синхронном соединении среди управляющих линий есть линия тактового сигнала, а также применяется фиксированный протокол коммуникации, зависящий от тактовых импульсов. Синхронная связь требуется от каждого подключения работы на одной и той же частоте. Это обычно означает, что все такие подключения должны быть расположены достаточно близко. Асинхронные соединения отлично работают на больших расстояниях, но, как правило, требуют использования некоторого протокола: приемник и передатчик начинают следующую операцию только после того, как оба к этому готовы. Использование такого протокола может сократить производительность соединения, так как передатчику приходится ждать от приемника подтверждения получения данных. При использовании в кольце SAN может обойти этот протокол, что позволяет передатчику непрерывно подавать на линию связи новые пакеты. Приемник добавляет в полученный им пакет информацию о получении, которая возвращается и извлекается приемником, когда пакет завершает круг. Данный подход позволяет множественным устройствам, подключенным к SAN, эффективней использовать пропускную способность линии. Еще одно применение SAN — связь между системами. На рисунке 10.1 показаны два дополнительных порта SAN, выходящих из системы. Обратите внимание, что если вместо использования кольцевой топологии эти два порта напрямую связывают две системы, то общая скорость на каждый порт составляет 500 МБ/с (250 МБ/с в каждом направлении). Для повышенной надежности межсистемного соединения два порта обычно работают параллельно, что дает избыточную линию связи. Если одно из соединений по какой-то причине нарушено, то системы используют резервную линию. Новейшие реализации SAN работают со скоростью 1 ГБ/с даже в случае резервирования. Как мы увидим в главе 11, это идеально для соединения систем в кластер. Платы ввода-вывода, показанные на рисунке 10.1, содержат IOP на базе процессора PowerPC, его память и вспомогательную аппаратуру, необходимую для предоставления интерфейса шины либо SPD, либо PCI. Затем платы адаптеров ввода-вывода (на рисунке не показаны) подключаются либо к обойме плат SPD, либо к плате адаптеров PCI, которая присоединяется к соответствующей шине. Обратите внимание, что адаптеры ввода-вывода SPD по-прежнему имеют собственные IOP. В данном случае мы имеем дело с двумя уровнями IOP: один — между соединением SAN и шиной SPD и второй — между шиной SPD и устройством. Конструкция плат ввода-вывода серии AS/400е предназначена также для RS/6000 и, возможно, других систем IBM. Так как RS/6000 не использует IOP для ввода-вывода, а выполняет всю обработку основными процессорами (аналогично ПК), нужно было найти способ устранить IOP с платы ввода-вывода PCI. С этой целью IOP был замещен микросхемой моста, которая фактически подключает шину PCI непосредственно к кольцу SAN и, таким образом, к шинам 6хх. Это позволяет основным процессорам управлять шиной PCI непосредственно.
Шина SPD
Итак, компьютеры серии AS/400е могут поддерживать шины SPD, PCI или обе одновременно. Шина PCI — промышленный стандарт и известна лучше, чем шина SPD, так что мы не будем тратить время на ее детальное описание. К тому же для большинства пользователей основным способом подключения устройств ввода-вывода к системе по-прежнему остается шина SPD, особенно на старших моделях, где поддерживается только она. Поэтому, прежде чем перейти к операциям ввода-вывода на AS/ 400, давайте рассмотрим шину SPD несколько подробнее. Работу шины SPD обеспечивают платы ввода-вывода, показанные на рисунке 10.1. В терминологии первых моделей AS/400, каждая плата ввода-вывода предоставляет эквивалент устройства управления шиной BCU (bus control unit) для одной шины SPD в системе. К каждой шине может быть подключено до 32 адаптеров ввода-вывода SPD (на рисунке не показаны). Плата адаптера ввода-вывода SPD содержит IOP, а также соответствующую аппаратуру для подключения к системе одного или нескольких устройств. Каждый IOP на плате адаптера ввода-вывода SPD имеет собственную память и собственную ОС. Эти специализированные ОС реального времени предназначены, в основном, для управления устройствами ввода-вывода. Очевидно, что приложение, выполняющееся на IOP, настроено на поддерживаемый IOP интерфейс конкретного устройства, коммуникационный или ЛВС. С точки зрения функционирования ввода-вывода, IOP, включая все его ПО, является устройством ввода-вывода на шине и называется IOBU (I/O bus unit). Таким образом, к шинам SPD подключаются IOBU, которые предоставляют интерфейс к устройствам ввода-вывода. Как мы уже говорили в главе 8, для уникальной идентификации шины, IOBU и устройства процессор использует адрес прямого сохранения. IOBU получает команду от процессора системы, заставляет устройство выполнить запрошенную операцию и управляет всей передачей данных в основную память и обратно. По завершении операции ввода-вывода, IOBU передает системному процессору информацию, позволяющую определить, успешна ли операция. Мы обсудим эти операции подробнее в следующих разделах. Давайте сначала рассмотрим способ физического соединения и некоторые характеристики перечисленных компонентов.Соединения аппаратуры ввода-вывода SPD
Шина SPD работает асинхронно. Чтобы понять, почему был выбран именно этот вариант, вспомните кольцо SAN. Как отмечалось выше, синхронная шина требует, чтобы все подключенные к ней устройства работали с одинаковой тактовой частотой, что предполагает достаточно близкое расположение таких устройств. PCI — именно такая синхронная шина с тактовой частотой 33 МГц. Шины такого типа быстры и их адаптеры обычно дешевле адаптеров асинхронной шины, которые должны поддерживать собственную синхронизацию. Однако, поскольку асинхронная шина не тактирована, она допускает использование разнообразных устройств, размещенных на большем расстоянии и без угрозы искажения сигнала. Именно эта гибкость послужила причиной первоначального выбора для AS/400 асинхронной шины SPD. В отличие от SAN, шина SPD не закольцована и должна использовать протокол. Такой протокол требует, чтобы передатчик и приемник начинали следующую операцию только после того, как оба они к этому готовы. Для этого шина имеет отдельные линии управления. Например, отправитель может установить на линиях управления запрос на считывание, а на линиях данных — адрес. Управляющие сигналы не снимаются до тех пор, пока приемник не подтвердит их получение, поместив сигнал на управляющую линию подтверждения. К каждой шине SPD подключено как минимум два IOBU. И основной процессор, и контроллер устройства работают как IOBU. Таким образом, на шине SPD никогда не бывает только одного IOBU; ведь основной процессор — это IOBU, так же как и контроллер любого устройства. К одной шине SPD может быть подключено максимально до 32 IOBU. При подключении к шине нескольких IOBU необходим арбитраж, если два или более устройств захотят использовать ее одновременно. Для арбитража используется механизм приоритетности. Каждому IOBU назначается приоритет, определяющий, какой IOBU может использовать шину, если на это претендуют несколько устройств. Прежде чем закончить эту тему и продолжить обсуждение ввода-вывода, следует отметить, что IOP можно использовать не только для функций управления вводом-выводом. Совершенно ясно, что IOP — это полноценный процессор со своей собственной ОС и прикладными программами. Он также имеет непосредственный доступ к основной памяти и, посредством шины ввода-вывода, к дисковой системе AS/ 400. Таким образом, IOP годится и для выполнения пользовательских приложений, и такая возможность интенсивно реализуется в AS/400. Подробнее об этом — в следующей главе.Работа шины ввода-вывода SPD
Каждая плата ввода-вывода SPD предоставляет BCU для одной шины SPD. BCU осуществляет основное управление работой шины. Обычно BCU выполняет восстановление после ошибки и повторное выполнение операции. Он также проводит арбитраж, если несколько IOBU пытаются использовать шину одновременно. Кроме того, BCU инициализирует шину при каждой загрузке системы, назначая подключенным IOBU логические адреса. Это означает, что к AS/400 может быть подключен новый IOBU, возможно, вместе с новым устройством. При перезагрузке системы новый IOBU конфигурируется автоматически, никакого вмешательства со стороны пользователя не требуется. Эта технология аналогична plug-and-play, применяемой в ПК. Еще одна функция BCU — назначать каждому устройству приоритет шины. BCU проверяет способность каждого IOBU работать по шине и загружает код в память IOP. При нормальной работе все коммуникации осуществляются между IOBU. Как говорилось выше, и в качестве IOBU, и в качестве всех IOP на платах адаптеров ввода-вывода SPD функционируют системные процессоры. Обмен информацией всегда происходит между IOBU, начавшим операцию шины (ведущим), и другим IOBU, который был выбран (ведомым). • Информация передается между IOBU в форме сообщений фиксированной длины или операций прямого доступа к памяти DMA (direct memory access) переменной длины. Во многих вычислительных системах аппаратура DMA позволяет IOBU осуществлять блочную передачу определенного числа слов в основную память и обратно напрямую, без вмешательства процессора. • Операцию шины можно определить как кратковременное соединение между двумя IOBU. Каждая такая операция шины состоит из двух частей. Сначала ведущий выбирает ведомого, а также определяет тип и направление передачи данных. Вторая часть операции состоит из тактов данных (от 1 до 16), во время которых происходит пересылка данных (за один такт —32 бита). Шина SPD поддерживает два типа операций: операции устройств и операции памяти. При операции устройств сообщение передается от ведущего к ведомому. Длина сообщения всегда равна 12 байтам. Формат сообщений мы рассмотрим в следующем разделе. Операция памяти позволяет осуществлять пересылку DMA между памятью IOP на плате адаптера и основной памятью системы. Пересылка управляется ведущим, который устанавливает соединение и определяет направление пересылки. Максимальное число байтов, пересылаемое за одну операцию памяти — 64 (4 байта за такт Г16 тактов данных = 64). В ходе операции и системный процессор, и IOP могут функционировать и как ведущий, и как ведомый. При выполнении операции памяти системный процессор может быть как ведущим, так и ведомым, а IOP — только ведущим. Последнее ограничение означает, что данные никогда не пересылаются из памяти одного IOP в память другого IOP, то есть, что по шине SPD невозможен ввод-вывод типа «точка-точка». Следовательно, чтобы переслать, например, данные непосредственно от дискового IOP к IOP ленты, надо обязательно использовать основную память. Это снижает общую гибкость структуры системы. Хочу еще раз напомнить, что в этом разделе мы обсуждаем только шину SPD. IOP PCI также управляют платами адаптеров, подключенных к шине PCI. Но так как шина PCI синхронна, и адаптеры не требуют установки собственных отдельных процессоров, то управление и протоколирование гораздо проще.Операции ввода-вывода в AS/400
Теперь от аппаратной архитектуры ввода-вывода AS/400 перейдем к совместной работе OS/400, SLIC и аппаратуры при выполнении операции ввода-вывода для прикладной программы. Сначала рассмотрим объекты, поддерживающие ввод-вывод, затем — многоуровневую структуру, включающую OS/400, SLIC и аппаратуру. А в заключение — проследим весь путь ввода-вывода от OS/400 до устройства и обратно.Объекты поддержки ввода-вывода
Для поддержки ввода-вывода OS/400 и MI используют разные, но тесно взаимосвязанные объекты. В MI таких системных объектов три, в OS/400 — четыре. Проще всего рассмотреть эти объекты с точки зрения способов подключать устройства к AS/400. Устройство можно подключить непосредственно к плате адаптера ввода-вывода. Чтобы предоставить системе характеристики этого устройства, используется системный объект. Как Вы помните, MI не зависит от нижележащей аппаратуры, включая аппаратуру устройств ввода-вывода, поэтому необходимо логическое, а не физическое описание устройства. Другими словами, нужна информация о том, что некоторое устройство — это принтер, но формат потока данных для этого устройства требуется только на нижнем уровне системы, но не MI. Соответственно, системный объект, используемый MI для описания устройства, называется описанием логического устройства LUD (logical unit description). Эквивалентный объект OS/400 — описание устройства DEVD (device description). Устройства не обязательно подсоединяются к адаптеру непосредственно. Они могут быть подключены к внешнему контроллеру, а через него — к плате адаптера. Иногда к контроллеру можно подключать несколько устройств, одного или разного типа, но обычно он специализирован для некоторого класса устройств. Например, есть котроллеры коммуникаций, дисков, принтеров и т. д. Системный объект, используемый для описания контроллера на уровне MI, называется описанием котроллера CD (controller description), а эквивалентный объект OS/400 — также описанием котроллера, но обозначается аббревиатурой CTLD (controller description). Устройства и контроллеры могут подключаться к системе не только локально, но и удаленно с помощью разных типов связи. Системный объект MI для описания линии или сети называется описанием сетиND (network description). OS/400 использует как объект описание линии LIND (line description), так и объект описание сетевого интерфейса NETINTD (interface description). OS/400 также рассматривает весь ввод/вывод как набор устройств источников-стоков. Вспомните, что OS/400 ничего не «знает» о дисках, а все элементы поверх MI рассматривает как объекты с памятью внутри. С точки зрения OS/400 устройство ввода-вывода — либо источник информации, поступающей в систему извне, либо сток информации, передаваемой из системы. Устройство никогда не используется для хранения информации в системе. Таким образом, весь дисковый ввод-вывод выполняется в SLIC ниже MI.Компоненты ввода-вывода
4 Денис! Эту сноску — на поля! Таблица по старому изданию, сравнить с новым. Для верстальщика: по-моему, стоит убрать рамку — будет красивее Таблица 10.1. Язык ввода-вывода| AMQ | Очередь свободных сообщений |
| BCT | Таблица управления шиной |
| BCU | Устройство управления шиной |
| BTM | Механизм транспорта шины |
| BUB | Блок устройства шины |
| BUM | Сообщение устройства шины |
| CAT | Управляющая адресная таблица |
| CCB | Блок управления подключениями |
| CGCB | Блок управления группой подключений |
| CID | Идентификатор подключения |
| FBR | Запись отклика |
| IOBU | Устройство шины ввода-вывода (IOP) |
| IORM | Сообщение запроса ввода-вывода |
| IPCF | Средство связи между процессами |
| MIRQ | Очередь ответов MI |
| RID | Идентификатор запроса |
| RRCB | Блок управления запросом-ответом |
| SSD | Данные источника-стока |
| SSR | Запрос источника-стока |
Думаю, Вас уже не удивляет, что ввод-вывод, как и практически все остальные компоненты AS/400, оперирует собственной терминологией и набором аббревиатур. Чтобы рассуждать о вводе-выводе, с этими обозначениями4 необходимо познакомиться. Список сокращений, которые я собираюсь использовать в своем рассказе, приведен в таблице 10.1. Это язык ввода-вывода. Как уже говорилось, сегодня в устройствах ввода-вывода AS/400 все еще преобладает шина SPD. Поэтому рассказ о вводе-выводе в следующих разделах я буду иллюстрировать примерами именно для этой шины, при необходимости, отмечая существенные отличия с вводом-выводом по шине PCI. Впрочем, везде, за исключением самих нижних уровней SLIC, эти различия незначительны. Архитектура ввода-вывода AS/400 предназначена для работы с самыми разными интерфейсами, так что добавление в будущем новых интерфейсов окажет минимальное влияние на существующее системное ПО. И конечно, с точки зрения приложений никаких различий вообще нет; это гарантируется архитектурой, не зависящей от технологии. Структура ввода-вывода SPD для AS/400, от MI до средства связи между процессами (IPCF) в SLIC, представлена на рисунке 10-2. В верхней части рисунка показан процесс MI — пример пользовательской прикладной программы, выполняющейся в системе.
 Рисунок 10.2. Структура ввода-вывода AS/400
Рисунок 10.2. Структура ввода-вывода AS/400
В главе 8 для пояснения к рассказу об одноуровневой памяти мы использовали похожий простой пример. Теперь расширим этот пример для иллюстрации операций ввода-вывода. Если Вы помните, тогда прикладная программа выполняла последовательное чтение индексированного файла базы данных, которое, могло быть выполнено либо с помощью команды «Read» ЯВУ, либо с помощью команды: SQL «FETCH». Результатом в обоих случаях — запрос на выполнение операции ввода-вывода для считывания записи с диска. Чтобы сделать пример более интересным, предположим, что вместо считывания записи с диска, подключенного к локальной машине, нужно считать запись из удаленной системы на другом конце линии связи, используя для этого команду SQL. В главе 6 мы говорили, что интерфейс SQL использует для доступа к удаленным данным DRDA (Distributed Relational Database Architecture). Прежде чем выполнить запрос SQL, нашей программе следует выполнить оператор SQL CONNECT, чтобы задать имя удаленной базы данных в каталоге реляционной базы. После установления связи между двумя системами на удаленную систему может быть послан запрос SQL. Менеджер базы данных удаленной системы выполняет этот запрос и возвращает полученные в результате записи запросившей их системе. Мы также говорили, что для доступа к удаленной базе данных можно использовать архитектуру DDM (Distributed Data Management). В этом случае обработка файла выполняется на локальной системе. DDM возвращает локальной системе все записи файла, тогда как DRDA — только записи, соответствующие критерию выборки. Выбор для нашего примера интерфейса SQL предполагает использование DRDA. Обработка выполняется на удаленной системе, и мы увидим только ее результаты. Выполнение команды SQL «FETCH» требует четырех операций ввода-вывода: двух — на локальной машине (для отправки запроса SQL и для получения ответа) и двух соответствующих им — на удаленной. Механизм коммуникаций в AS/400 разбит на слои между OS/400, SLIC и аппаратурой. В нашем примере четыре слоя обработки, а именно: прикладная поддержка; менеджер функций; менеджер ввода-вывода (IOM) станции; IOM линии. Аппаратный уровень будет рассмотрен в следующем разделе. В OS/400 может работать прикладная поддержка коммуникаций, предоставляемая как пользователем, так и IBM. Пользовательская поддержка коммуникаций подключается с помощью API, хотя, конечно, такой поддержкой обладает далеко не каждая прикладная программа. В нашем примере, прикладная поддержка предоставляется компонентом DRDA базы данных AS/400. Менеджер функций (FM) — это компонент OS/400, предоставляющий интерфейс между приложениями и MI. Для каждого «транспорта» коммуникаций в SLIC обычно имеется соответствующий FM в OS/400. FM отвечает за верхние уровни протокола коммуникаций, например за то, чтобы данные были представлены приложению в той форме, в которой оно этого ожидает. В нашем примере используется FM для механизма коммуникаций, называемого APPC (advanced program-to-program communications). Впервые АРРС был реализован в System/38, где поддерживал параллельные сессии между системами, позволяя таким образом взаимодействовать нескольким приложениям на разных системах. При этом применялся коммуникационный протокол LU 6.2 (logical unit type 6.2). Порт для посылки и приема данных от приложения на другой системе предоставляло прикладной программе логическое устройство (logical unit). В AS/400 этот механизм был расширен до уровня APPN (advanced peer-to-peer networking), чтобы удовлетворить потребности распределенной обработки, как в ЛВС, так и в глобальных сетях. APPN, в частности, определяет по распределенному сетевому каталогу местонахождение любой удаленной системы, запрошенной локальным приложением. При наличии нескольких маршрутов между локальной и удаленной системами, APPN на основании выбранного пользователем класса обслуживания вычисляет наилучший. В последних нескольких версиях AS/400 в APPN были добавлены дополнительные функции, включая автоматическое конфигурирование при получении входящего запроса на соединение от неизвестной системы, непосредственно подключенной к ЛВС. Другое новое расширение APPN — поддержка работы по разным сетям, что позволяет приложениям, написанным для API APPC/LU 6.2 без модификации взаимодействовать с удаленным приложением, даже если сетевые сервисы предоставляются несколькими системами. В нашем примере оператор SQL CONNECT задает устройства, которое должно использоваться в данном запросе ввода-вывода. Предположим, что это устройство — не сетевой адаптер, а модем. Поддержка DRDA в базе данных передает управление FM APPC. Задача FM — построение необходимых структур ввода-вывода и создание соответствующего запроса. FM выдает MI привилегированную команду запроса ввода-вывода («REQIO»), которая не может выполняться прикладной программой. С командой «REQIO» связан SSR (Source Sink Request), который содержит три указателя на: очередь ответов MI (MIRQ), в которую будет помещено сообщение по завершении ввода-вывода; описание устройства LUD; данные приема-передачи (SSD), то есть пользовательский буфер для хранения данных, пересылаемых на устройство или наоборот (в нашем примере — запрос SQL, посылаемый на удаленную систему). Затем запрос ввода-вывода посылается в виде сообщения в очередь, находящуюся ниже MI и принадлежащую IOM станции. IOM станции — это программа SLIC, которая принимает запросы от FM для установления соединений (иногда называемых сессиями) с удаленными системами, устройствами или приложениями. IOM станции отвечает за обработку средних уровней протокола коммуникаций. В состав функций среднего уровня входит, среди прочих, управление путями коммуникаций — каждому из них соответствует определенный IOM станции: например, поддерживающий коммуникации «точка-точка», или коммуникации с центральными системами, такими как System/390. Другой IOM станции обеспечиваетподключение ПК, использующих протокол LU 6.2. В нашем примере необходимо соединение «точка-точка» с удаленной системой, заданной в операторе SQL CONNECT. Следовательно, мы будем использовать IOM станции для APPN. Этот IOM станции дополняет запрос управляющей информацией, необходимой для удаленной сессии. Он также обеспечивает интерфейс между FM и IOM линии. IOM станции использует для данного соединения описание котроллера CTLD, в MI — CD. CD — это конфигурационный объект, содержащий информацию об удаленной системе (ее адрес, имя порта управления APPN и другие необходимые параметры). Руководствуясь информацией из CD, IOM станции добавляет к запросу ввода-вывода команды или необходимую управляющую информацию, а затем IOM станции посылает запрос ввода-вывода в очередь IOM линии. IOM линии реализует протоколы канала. Он обеспечивает для IOM станции прозрачный интерфейс, не зависящий от нижележащего канального протокола и используемой сети. В нашем примере мы собираемся воспользоваться протоколом SDLC (synchronous data link communications). IOM линии управляет передачей данных и определяет физические подключения к линии. Для этого он использует описание линии LIND, которому в MI соответствует описание сети ND, а для линии SDLC добавляет к запросу необходимые управляющие символы. IOM линии также обеспечивает интерфейс между верхними слоями коммуникационного протокола и аппаратным соединением. Далее запрос передается средству связи между процессами IPCF, расположенному в SLIC. IPCF используется для всех устройств; оно взаимодействует с аппаратурой ввода-вывода для отправки запроса IOP на плате адаптера по шине SPD. С помощью LUD (DEVD указан в SSR) IPCF определяет, что в нашем примере используется модем, подсоединенный к плате адаптера, а та, в свою очередь, — к физической линии связи. Вскоре мы поговорим, как именно выполняется передача; но сначала нужно рассмотреть блоки управления вводом-выводом, позволяющие SLIC работать с аппаратурой. Блоки управления ввода-вывода и связи между ними показаны на рисунке 10.3. Блоки содержат всю информацию, необходимую IPCF для поиска устройства. Эта информация в виде таблиц находится в памяти, где она доступна как аппаратуре, так и ПО, и обновляется во время загрузки системы, когда назначаются адреса IOBU. Обратите внимание, что стрелки на рисунке 10.3 соответствуют адресам, тогда как на рисунке 10.2 — передачам управления. CAT
 Рисунок 10.3. Блок управления вводом-выводом
Рисунок 10.3. Блок управления вводом-выводом
Кроме того, на рисунке 10.3 показаны семь блоков управления. Давайте рассмотрим их подробней[ 79 ]. 1. Управляющая адресная таблица (CAT) — эта общесистемная таблица, в которой содержатся адреса основных блоков управления, используемых SLIC. Очередь свободных сообщений (AMQ) — это очередь незаполненных сообщений, на которую указывает один из адресов в CAT. Сообщения из этой очереди могут использоваться различными компонентами SLIC, включая IPCF. Таблица управления шиной (BCT) содержит буферы, SRQ и указатели на другие блоки управления. На каждую шину SPD приходится по одной BCT. Блок устройства шины (BUB) содержит информацию о различных подключенных к шине устройствах. На каждую шину SPD приходится по одному BUB. Здесь размещается очередь сообщений ввода-вывода, ожидающих завершения операции. Обратите внимание, что этот BUB не то же самое, что BUB (Bring Up Bind), о котором говорилось в главе 3. Тот BUB использовался для оценки прогресса в разработке SLIC, и, возможно, мне не следовало его упоминать, чтобы не путать читателей. Удаленный CCB ( или удаленный CGCB) — имеется по одному для каждой шины SPD в системе, а также для каждого идентификатора подключения, назначенного IOBU. Этот управляющий блок хранит для удаленных (находящихся вне процессора) IOBU идентификаторы устройств, состояния и адресов IOBU. Некоторые IOBU могут поддерживать несколько устройств и, соответственно, иметь несколько идентификаторов подключения. Локальный CCB (или локальный CGCB) — один из этих блоков также имеется для каждой шины SPD в системе. Они очень похожи на удаленные блоки, но содержат информацию об IOBU, подключенных локально (внутри процессора). 7.Блок управления подключениями (CCB) — один для всей системы. Он содержит идентификаторы подключений и маршруты для всех шин SPD, а также обеспечивает доступ к информации подключений для каждой отдельной шины.
Как все это работает
 В этом разделе мы продолжим разговор о вводе-выводе на примере шины SPD. Мы рассмотрим подробности низкоуровневых операций, выполняемых ниже IPCF и очень специфичных для структуры шины SPD, используемой как в старых, так и в новых моделях AS/400. Чтобы представить себе операцию ввода-вывода по SPD в целом, проследим ее с самого начала, когда приложение запрашивает выполнение ввода-вывода, и до момента получения приложением уведомления о завершении операции.
Иллюстрировать наш рассказ будет рисунок 10.4, представляющий собой несколько упрощенную версию рисунка 9.2. На нем показаны действия, выполняющиеся до посылки сообщения о начале операции («Opstart») по шине SPD соответствующему
IOP.
На рисунке изображена команда MI «REQIO», а также SPD и пользовательский буфер. Для простоты показан только один IOM. Как и раньше, запрос посылается в очередь IOM. Когда IOM завершает свою обработку, запрос на передачу («SENDREQ») отправляется IPCF. Именно здесь мы ранее остановились, рассматривая пример.
Для операции ввода-вывода IPCF создает две структуры данных. Первая — это сообщение запроса ввода-вывода (IORM), позволяющее IPCF отслеживать выполнение этого запроса и хранить информацию о его отправителе. Вторая структура данных — это блок управления запросом-ответом (RRCB). С его помощью IOP на плате адаптера SPD определяет тип запрошенной операции, расположение в памяти данных, которые должны быть считаны или записаны, а также то, куда следует поместить состояние завершения. Эта структура данных получает информацию от семи блоков управления, изображенных на рисунке 10.3
В этом разделе мы продолжим разговор о вводе-выводе на примере шины SPD. Мы рассмотрим подробности низкоуровневых операций, выполняемых ниже IPCF и очень специфичных для структуры шины SPD, используемой как в старых, так и в новых моделях AS/400. Чтобы представить себе операцию ввода-вывода по SPD в целом, проследим ее с самого начала, когда приложение запрашивает выполнение ввода-вывода, и до момента получения приложением уведомления о завершении операции.
Иллюстрировать наш рассказ будет рисунок 10.4, представляющий собой несколько упрощенную версию рисунка 9.2. На нем показаны действия, выполняющиеся до посылки сообщения о начале операции («Opstart») по шине SPD соответствующему
IOP.
На рисунке изображена команда MI «REQIO», а также SPD и пользовательский буфер. Для простоты показан только один IOM. Как и раньше, запрос посылается в очередь IOM. Когда IOM завершает свою обработку, запрос на передачу («SENDREQ») отправляется IPCF. Именно здесь мы ранее остановились, рассматривая пример.
Для операции ввода-вывода IPCF создает две структуры данных. Первая — это сообщение запроса ввода-вывода (IORM), позволяющее IPCF отслеживать выполнение этого запроса и хранить информацию о его отправителе. Вторая структура данных — это блок управления запросом-ответом (RRCB). С его помощью IOP на плате адаптера SPD определяет тип запрошенной операции, расположение в памяти данных, которые должны быть считаны или записаны, а также то, куда следует поместить состояние завершения. Эта структура данных получает информацию от семи блоков управления, изображенных на рисунке 10.3

Форматы IORM и RRCB показаны на рисунке 10.5. Здесь также представлен формат двух сообщений шины SPD, используемых для начала и завершения операции ввода-вывода.
 Рисунок 10.5 Структуры данных IPCF
Рисунок 10.5 Структуры данных IPCF
Рисунок 10.4. Операция ввода-вывода (начало) IORM — это сообщение, указывающее, кто запросил данную операцию ввода-вывода, или, точнее, кого следует уведомить о ее завершении. Поля сообщения задают его тип и адрес блока устройства шины. Этот адрес показывает, где расположен BUB для шины SPD, а также IOP для устройства, которому послан запрос. Данное сообщение будет поставлено в очередь, связанную с указанным BUB, на все время ожидания завершения ввода-вывода. Постановка в очередь означает, что IPCF сохраняет в BUB адрес данного IORM. В очереди одного BUB одновременно может находиться более одного IORM, то есть на шине SPD может одновременно быть несколько ожидающих операций. В IORM также указан адрес очереди, куда будет послано сообщение по завершении ввода-вывода. Эта очередь связана с IOM, отправившим запрос IPCF. Перед посылкой сообщения в очередь IOM, поле состояния в IORM будет заполнено информацией о том, завершилась ли операция нормально или нет. Последние два поля IORM — это идентификатор подключения CID и адрес RRCB. CID инициализируется IPCF с использованием блоков управления подключениями, рассмотренных в предыдущем разделе. CID уникально идентифицирует устройство. IPCF получает CID из удаленного блока управления подключением, используя информацию IORM. Адрес RRCB задает место расположения в памяти данного блока управления. Обратите внимание, что в этих блоках используются реальные, а не виртуальные адреса. RRCB — это блок управления, от которого IOP получает подробную информацию об отправляемом запросе ввода-вывода. В отличие от блоков управления, инициализируемых во время загрузки системы, RRCB — это временный блок управления, который создается для каждого запроса ввода-вывода. RRCB может иметь переменную длину, так что первое поле задает размер блока в памяти. После поля длины следуют два поля, задающие CID (тот же, что и в IORM) и идентификатор RID, позволяющий различать запросы. Далее следует поле расширенного состояния, нужное, если возвращаемая информация состояния не умещается в поле состояния в IORM. Остальные поля RRCB содержат адреса основной памяти. Первым идет адрес самого запроса ввода-вывода, за ним — адреса одного или нескольких буферов данных. В нашем примере запрос ввода-вывода — это команда модему, а не запрос на получение находящейся в буферах данных информации от удаленной вычислительной системы. Запрос ввода-вывода не записывается в RRCB, так как имеет разную длину для разных устройств, а находится в памяти по адресу, заданному этим полем. Буферы данных, на которые указывают следующие поля, содержат данные, подлежащие передаче на устройство. В нашем примере здесь будет размещаться адрес пользовательского буфера — SSD, в котором хранится запрос SQL к удаленной системе. На рисунке 10.5 приведены также форматы двух сообщений шины: «OPSTART» и «OPEND». Это примеры 12-байтовых сообщений, посылаемых по шине SPD во время операций устройства, о которых говорилось выше. Первое сообщение, «OPSTART», используется в нашем примере для запуска операции ввода-вывода. Сообщение «OPSTART» содержит четыре поля. В первом находится длина RRCB в памяти. Второе поле идентифицирует это сообщение как сообщение «OPSTART». Третье — занято адресом RRCB в памяти. Последнее поле содержит идентификатор подключения сервера. Сервером здесь выступает IOP, так что нам необходимо задать сервер для сообщения шины. Идентификатор подключения сервера — часть CID. Полный CID в RRCB задает устройство. Для запуска операции ввода-вывода IPCF, используя операцию устройства, посылает сообщение «OPSTART» по соответствующей шине SPD указанному IOP на плате адаптера (до модема дело еще не дошло). При получении сообщения IOP инициирует операцию памяти на шине и, используя DMA, считывает в свою память весь RRCB. После получения RRCB IOP снова запускает операцию памяти для считывания из основной памяти запроса. Наконец, поскольку данная операция требует пересылки данных (нашего запроса SQL удаленному компьютеру) на устройство, IOP выбирает данные из буферов, которые содержат наш запрос SQL FETCH. Теперь IOP выдает модему команду на посылку нашего запроса по линии связи на удаленный компьютер. Данные пересылаются из указанных буферов основной памяти. Когда операция завершается получением от удаленной системы сигнала об окончании приема, IOP формирует сообщение шины «OPEND». Затем он запускает операцию устройства для отправки сообщения «OPEND» обратно IOBU, в роли которого выступает системный процессор. Как Вы помните, в качестве IOBU выступают и IOP, и системный процессор. Сообщение шины «OPEND», показанное на рисунке 10.5, содержит четыре поля. В первом находятся различные биты флагов, предоставляющие информацию об операции и ее завершении. Второе — поле типа — идентифицирует это сообщение как «OPEND». Третье поле содержит идентификатор запроса RID, который был ранее помещен IPCF в RRCB. Наконец, четвертое поле содержит состояние завершения. В зависимости от состояния флагов, информация завершения может также находиться в поле расширенного состояния RRCB. Рисунок 10.6 иллюстрирует конец операции ввода-вывода из нашего примера. Получение сообщения «OPEND» означает, что IOP закончил обработку запроса. Обработчик ввода-вывода (не показан на рисунке) выводит IORM из очереди BUB для шины SPD, по которой было получено сообщение «OPEND», обновляет поле состояния и посылает IORM в очередь маршрутизатора IPCF.
 Рисунок 10.6 Операция ввода-вывода (завершение)
Рисунок 10.6 Операция ввода-вывода (завершение)
Маршрутизатор IPCF проверяет состояние завершения, и если все нормально, посылает ответное сообщение в очередь, указанную в поле адреса очереди возврата IORM. IOM, отправивший запрос ввода-вывода, выполняет необходимую очистку и, если операция завершилась нормально, посылает запись отклика (FBR) в очередь ответов MI (MIRQ), которая была указана в оригинальном запросе источника-стока. Эта запись уведомляет менеджера функций о завершении первой операции ввода-вывода. На этом FM заканчивает операцию и может выполнять следующие. Приложение, запросившее SQL FETCH, будет ждать, пока удаленная система не возвратит результаты обращения к базе данных. В результате только что описанной операции ввода-вывода наш запрос SQL был отправлен на удаленную систему. Когда запрос прибыл на удаленную систему, удаленный модем сообщил локальной системе о его получении. Затем модем удаленной системы запустил операцию ввода-вывода для приема запроса. Некоторое время спустя, когда база данных удаленной системы завершит выполнение нашего запроса, удаленная система инициирует операцию ввода-вывода для отправки нам результатов. IOP на локальной системе, к которому подключен модем, получит данные с удаленной системы и запустит другую операцию ввода-вывода. На этот раз IOP пошлет сообщение «OPSTART» центральному процессору, который, как мы видели выше, также может выполнять все функции IOBU. Когда MIRQ получит сообщение «OPEND» о завершении второй операции ввода-вывода на локальном компьютере, менеджер функции уведомит прикладную программу, что обработка ее запроса ввода-вывода (SQL FETCH) завершена. Прежде чем закончить рассмотрение примера, хочу отметить, что для выполнения ввода-вывода требуется гораздо меньше времени, если для соединения систем используется OptiConnect, а не линия связи. Во-первых, системы соединены высокоскоростным оптоволоконным кабелем. Во-вторых, протоколы связи APPC и APPN заменяются специальным драйвером устройства. Этому драйверу не требуются сложные проверки для отслеживания ошибок, которые возможны при обмене данными по обычной линии связи, где сигналы обязательно содержат электрические шумы. Для проверки и исправления ошибок требуется передача избыточной информации. Передача информации по оптоволокну осуществляется с помощью света и свободна от шумов. Таким образом, драйвер устройства, используемый OptiConnect, обеспечивает прямое соединение c меньшей избыточностью. Хочу особо отметить: если запрос SQL направляется локальной базе данных, то никакие из только что описанных операций, задействующих APPC FM, IOM станции APPN, или IOM станции SDLC, выполняться не будут. Вместо этого, поддержка базы данных локальной системы будет обрабатывать запрос SQL FETCH с использованием одноуровневой памяти так, как было описано в главе 8. Страничные ошибки, которые приводят к обращениям на диск, обрабатываются компонентом управления памятью, работающим напрямую с IPCF.
Выводы
Сейчас вводом-выводом занимается большая часть аппаратуры и системного ПО AS/ 400, и в будущем ситуация вряд ли изменится. Быстрый рост производительности процессоров приводит к перенапряжению большинства систем ввода-вывода. Производительность физических устройств не может расти с той же скоростью, что и производительность процессоров. Для удовлетворения все возрастающих потребностей процессоров, в высокопроизводительных системах все больше и больше устройств должны работать и управляться параллельно. Благодаря использованию множественных шин и множественных IOP, AS/400 занимает уникальные позиции по ожидаемому в следующие несколько лет росту производительности. Использование программируемых процессоров ввода-вывода и, вследствие этого, возможность выполнять огромное число операций ввода-вывода, будут еще долгие годы выгодно отличать AS/400 от других систем. Интересно, что первой системой, где применялись программируемые процессоры ввода-вывода, была CDC 6600. Там они назывались периферийными процессорами. Возможно, Вы помните, что CDC 6600, разработанная Сеймуром Креем, была первой машиной, использовавшей конвейерный процессор общего назначения архитектуры загрузка-сохранение. Развитие этой архитектуры привело к созданию RISC-процессоров. Похоже, этот первый суперкомпьютер понимал кое-что и во вводе-выводе. Современные высокопроизводительные AS/400, несомненно, усвоили его уроки.Глава 11
Версия 4
Почему я так уверен в будущем AS/400? В этой главе мы рассмотрим ПО и аппаратуру версии 4, и Вы получите представление о ближайших перспективах этой системы. Глава 12 посвящена версиям AS/400, следующим после 4. И пусть пока трудно сказать что-то конкретное, но уже есть достаточно обоснованные предположения относительно новых технологий, которые изменят всю индустрию информатики в следующие 5-10 лет. Я намерен высказать свое мнение о том, как эти технологии повлияют на AS/400. Конечно, всякие предположения — это лишь предположения. Мы живем в эпоху постоянных перемен, и создаем компьютерные технологии в соответствии с ее требованиями. Предсказывать будущее различных аппаратных и программных технологий легче легкого; тяжело лишь выбрать, какие из них подойдут для решения конкретных проблем. Разумеется, у IBM свои планы на этот счет, но так как они еще не устоялись, а также из соображений защиты интересов корпорации в конкурентной борьбе, я не буду обсуждать эти планы подробно. Но и не постесняюсь сделать определенные прогнозы насчет основных тенденций развития информатики и их влияния на AS/400. В компьютерной индустрии важную роль играет мода. Самый безошибочный, на мой взгляд, способ предсказать будущее — понаблюдать за тем, какие журналы читает Ваш босс в самолете. Если в каком-нибудь из этих журналов есть статья о новой вычислительной технике, то весьма велика вероятность, что скоро Вас попросят освоить эту модель. Никто не хочет отставать от моды! В этой главе мы поговорим о том, что в моде сегодня, и какие технологии лежат в основе этой моды.Расширенная версия 4 AS/400
Как я уже говорил, версия 3 ознаменовала переход на RISC-процессоры. Отдельные версии OS/400 для CISC- и RISC-систем позволили заказчикам пользоваться старыми и новыми моделями с равной функциональностью. С объявлением в 1997 году версии 4, ситуация изменилась. Новые возможности этой версии будут реализованы только на RISC-моделях. Возможно, некоторых из новых функций будут доступны и на CISC-моделях, но IBM не будет больше эквивалентно поддерживать системы разных архитектур. Но, конечно, приложения, написанные для CISC-модели, в версии 4 работают по-прежнему без изменений, полностью используя возможности RISC-ап-паратуры. С момента первого появления AS/400 в 1988 году, срок жизни версии OS/400 составлял три года. У каждой версии было разное число выпусков, но эта цифра оставалась неизменной. У меня нет причин сомневаться, то и версию 4 ждет та же судьба. Новые выпуски начались в 1997 году и, наверняка, будут продолжаться до 1999 года. Учитывая быстроту изменений в окружающем нас мире, вероятно, у версии 4 будет еще больше выпусков, чем у предыдущих. И если история повторится, то примерно к 2000 году можно ожидать или новой версии, или совершенно новой системы. В следующей главе я постараюсь спрогнозировать, что будет с AS/400 после 2000 года. IBM вкладывает большие средства в развитие различных компонентов AS/400. На рисунке 11.1 показаны области связанных с электронным бизнесом капиталовложений в версию 4[ 80 ]. Эти инвестиции отражают предполагаемые направления развития компьютерной индустрии в соответствии с нуждами наших заказчиков в течение нескольких следующих лет. Они также указывают на те расширения, которые Вы можете ожидать в AS/400. Рисунок 11.1. Поддержка е-бизнеса в AS/400
Рисунок 11.1. Поддержка е-бизнеса в AS/400
Итак, поговорим о перспективных направлениях развития AS/400. В этой главе мы рассмотрим: три модели приложений — сетевые, совместные и клиент-серверные вычисления; два направления развития ПО — поддержку приложений и оптимизацию обработки данных; две ветви развития аппаратных средств — расширения в старших моделях и улучшение соотношения цена-производительность. Многих из этих тем мы уже так или иначе касались в предыдущих главах, и на них я не буду останавливаться подробно. Мы начнем с сетевых вычислений — модели приложений, которая сейчас привлекает наибольшее внимание.
Сетевые вычисления
В компьютерной индустрии любят революции. В центре внимания постоянно находятся принципиально новые модели вычислений. Газеты, журналы, консультанты и эксперты до небес превозносят их достоинства и убеждают Вас немедленно применить их на деле. Но лишь немногие революционные технологии фундаментально изменяют методы ведения бизнеса, и единственной движущая сила здесь — реальная возможность решения насущных проблем и рост доходов. Революцию, произведенную ПК, можно считать свершившимся фактом. Она коренным образом и повсеместно изменила всю систему бизнеса. А вот в отношении клиент-серверной модели подобная категоричность еще не вполне уместна. Многие фирмы находят ее вполне подходящей для ведения своих дел, но есть и те, кто считает, что дороговизна и сложность клиент-серверных вычислений не перевешивают получаемых от них выгод. В следующем разделе мы посмотрим, как AS/400 упрощает клиент-серверные вычисления, делая их более привлекательными для заказчиков. Обычно переход на новую модель вычислений связан с расходами и риском, так что предварительно нужно четко просчитать, что перевесит: временные неудобства или продолжительные выгоды, которые сулит новшество. Кстати, очень часто революционные идеи не оправдывают наших надежд. Однако некоторые из них могут оказаться работоспособными, и не использовать их вовремя — значит, упустить выгоду. Поэтому обычно применяется подход «поживем — увидим»: дождемся, пока кто-нибудь другой попробует первым. Сетевые вычисления — одна из таких новейших технологий. Многие (и я в том числе) считают, что эффект от этого следующего поколения клиент-серверных вычислений изменит бизнес больше, чем революция,произведенная ПК. Сетевые технологии уже изменили наш образ жизни и работы. Интернет, и особенно появление в 1993 году WWW (Word Wide Web), сделали то же, что в свое время электричество или телефон. По мере расширения доступа к всемирной сети компьютеров географические границы исчезают. В киберпространстве уже появились свои сообщества, в которых люди сходных интересов могут объединяться для обмена информацией и общения с помощью комнат переговоров (chat room) и дискуссионных форумов. Колонизация киберпространства предоставляет бизнесу новые, ранее недостижимые, возможности целенаправленной работы с определенными группами потенциальных клиентов. Очевидно, что движущая сила перехода к сетевым вычислениям — потребности рынка. Благодаря сетевым вычислениям, предприятия могут резко увеличить свою конкурентоспособность: Интернет позволяет поддерживать с клиентами и смежниками самый тесный и постоянный контакт. Кроме того, постепенно распространяется понимание преимуществ использования Интернета внутри организации. Многие фирмы сейчас реализуют интранеты. Интранет использует технологии Интернета на внутренней закрытой сети, которая может быть локальной или охватывать все предприятие. Все это помогает понять, почему в наши дни бизнес все больше и больше становится электронным.Реализация стандартов
Сетевые вычисления основаны на стандартах. Это важно, ведь принятие очень небольшого набора стандартов и повсеместное их соблюдение — единственный способ создать всемирную сеть из несхожих друг с другом компьютеров. AS/400 — полноценный сервер Интернета, она поддерживает все стандарты сервера WWW. Различные предлагаемые AS/400 сетевые возможности, а также используемые для их поддержки стандарты Вы можете видеть на рисунке 11.2. Впервые IBM представила Internet Connection в 1996 году как часть TCP/IP Connectivity Utilities в OS/400 и продолжает совершенствовать это ПО в каждом выпуске версии 4. Рисунок 11.2. Поддержка Интернета в AS/400
Рисунок 11.2. Поддержка Интернета в AS/400
Многие сокращения, использованные на рисунке 11.2, расшифровывались и пояснялись в главе 7 при обсуждении защищенного сервера WWW. Некоторые из этих пояснений я повторю. Мы не будем подробно рассматривать каждый компонент, а лишь постараемся оценить широту диапазона функций AS/400 для обслуживания Интернета и интранетов. Важно отметить, что и новые, и существующие приложения поддерживают выход в сетевой мир. Итак: Any Mail — позволяет использовать AS/400 в качестве сервера электронной почты, поддерживая соответствующие стандарты; SMTP (Simple Mail Transfer Protocol) обеспечивает посылку и прием электронной почты; сервер POP (Post Office Protocol) — почтовый ящик, в котором почта хранится до тех пор, пока ее не заберет реципиент (последняя версия данного стандарта — РОР3); IMAP (Internet Message Access Protocol) поддерживает синхронизацию локальных данных на множественных узлах Интернета (например, компьютер дома и компьютер на работе), что позволяет большим массивам электронной почты «перетекать» с компьютера на компьютер; MIME (Multipurpose Internet Messaging Extensions) — это стандарт Интернет для посылки почты с заголовками, описывающими содержимое почтового сообщения; при этом сообщения могут содержать файлы, видео, картинки, звук, текст или двоичные данные; SMIME (Secure Multipurpose Internet Messaging Extensions) — вариант MIME с обеспечением секретности. Клиенты WWW могут работать с существующими приложениями 5250 с помощью Telnet, который обеспечивает терминальную эмуляцию 3270, 5250 и VT100 по сети или с помощью HTML Gateway. HTML (Hypertext Markup Language) — это формат потока данных между сервером WWW и браузером на пользовательской машине. HTML Gateway позволяет графически отображать приложения 5250 с помощью браузера. Стандартный транспортный протокол Интернета, известный как HTTP (Hypertext Transport Protocol), используется Internet Connection Secure Server и Internet Connection Server для обмена информацией с клиентами WWW. Отличие между этими двумя серверами в том, что один защищен, а другой нет. Выбор того или другого зависит от конкретных обстоятельств, о которых мы еще поговорим. Вы можете использовать несколько протоколов для доступа к IFS (Integrated File System), которая поддерживает файлы HTML и Java. На рисунке 11.2 показаны серверы для двух таких протоколов. Есть также серверы и для других протоколов: это сервер BootP (BootStrap Protocol), сервер TFTP (Trivial FTP), сервер Telnet и сервер RIP (Routing Information Protocol). CGI (Common Gateway Interface) — это стандартный протокол сервера WWW, позволяющий программам, расположенным на сервере, напрямую взаимодействовать с браузером на пользовательском компьютере. Приложения CGI — стандарт для сетевых приложений на всех остальных серверах, они также поддерживаются и AS/ 400. Альтернатива программам CGI — макропроцессор Net.Data, упрощающий доступ к DB2/400 из WWW. TCP/IP (Transmission Control Protocol/Internet Protocol) — это промышленный стандарт передачи данных по Интернету. Физические подключения могут осуществляться по выделенным линиям, асинхронным телефонным линиям и ЛВС. В случае подключения к Интернету по телефону можно использовать любой из двух протоколов: SLIP (Serial Link Internet Protocol) или PPP (point-to-point protocol). В качестве ЛВС могут использоваться Token-Ring, Ethernet со скоростью до 100 Мбит в секунду, беспроводные сети или новые сети ATM (Asynchronous Transfer Mode) со скоростью до 155 Мбит в секунду. Защита на Интернете крайне важна, особенно при коммерческих операциях. Расширения сетевой защиты продолжают добавляться к AS/400 либо как часть базовой поддержки в составе OS/400, либо как отдельные продукты. Например, базисная аутентификация HTTP — часть базовой поддержки. Она запрашивает у пользователя идентификатор и пароль при попытке обратиться к странице WWW с ограниченным доступом. Таким образом, профили пользователей AS/400 или отдельный список пользователей сервера могут применяться для разграничения доступа пользователей к страницам WWW. Internet Connection Secure Server для AS/400 — отдельный продукт, обеспечивающий секретность коммуникаций в WWW. Он позволяет браузерам и серверам WWW выполнять взаимную аутентификацию, обеспечивает владельцев узлов WWW возможностью управлять доступом к серверу и позволяет передавать между браузером и сервером закрытую информацию так, чтобы она была недоступна третьим лицам. В своей работе Internet Connection Secure Server использует SSL (Secure Sockets Layer) фирмы Netscape. SSL предоставляет закрытый канал между пользователем и сервером, гарантируя защиту данных, аутентификацию участников сессии и целостность сообщений. Обратите внимание, что на SSL на рисунке 11.2, используется именно Internet Connection Secure Server, а не Internet Connection Server. Защиту при обслуживании WWW обеспечивают такие продукты AS/400, как аппаратное шифрование данных и брандмауэры. Мы обсудили их в главе 7. Еще более надежную защиту дает прокси-сервер, выступающий посредником между пользователем и сервером WWW. Запрос пользователя направляется на прокси-сервер, который выполняет запрос к серверу WWW, а затем возвращает клиенту результаты. Новый продукт IBM для AS/400 под названием Net.Commerce (на рисунке 11.2 не показан) позволяет разрабатывать собственные торговые системы для Интернета. Он предоставляет средства для создания и управления интерактивным сетевым магазином. С помощью функции построения каталога Вы можете определить категории или отделы, переходя по которым покупатели добираются до продаваемых продуктов. Net.Commerce применяет как DB2/400, в которой размещается как вся информация каталога, так и Internet Connection Secure Server. Для обеспечения защиты платежей по Интернету Net.Commerce использует протокол SET (Secure Electronics Transaction), описанный в главе 7.
Битва за рабочий стол
Первые залпы этой битвы прогремели 4 сентября 1995 года. Место сражения — форум в Париже, где всеобщее внимание привлекла речь Ларри Эллисона (Larry Ellison), главы фирмы Oracle. Он сказал: «По нашему мнению, в мире происходит переход от ориентации на рабочие места к ориентации на сети. Вы можете поставить терминал всего за 400-500 долларов США. При этом такое дорогое и сложное устройство, как ПК, становится нелепым анахронизмом. Гораздо проще воткнуть вилку в розетку и таким образом получить нужные данные». Так Эллисон заявил концепцию сетевого компьютера (СК). Битва началась. В парижском форуме участвовал и Билл Гейтс (Bill Gates), глава Microsoft — компании-лидера на рынке «нелепых анахронизмов» ПК. Речь Ларри Эллисона явно задела его самолюбие и Гейтс нанес ответный удар, сказав, что «тупой терминал» Эл-лисона никогда не будет доминировать среди настольных устройств. Комментируя утверждение Эллисона, что будущее настольное устройство будет удешевлено за счет отсутствия дисковой памяти, Гейтс сказал: «Вам по-прежнему потребуется способ хранения информации, полученной из сети, а также своих личных данных». С этого момента компьютерщики всего мира встали по ту или иную сторону баррикад. С одной стороны бой вели Oracle, Sun Microsystems, Netscape, Apple и IBM, с другой — Microsoft, Intel и другие производители ПК, которые потерпели бы наибольшие убытки в случае распространения СК. Сторонники ПК утверждали, что ПК на рабочих местах доминируют безраздельно и повсеместно, и что ни одна организация никогда не откажется от них, даже при переходе к сетевым вычислениям. Сторонники СК, в свою очередь, клялись, что их главный аргумент — низкая цена — неизбежно приведет к переходу всего мира на СК. По их мнению, стоимость использования ПК в бизнесе (так называемая общая стоимость владения — ОСВ), за последние 10 лет взлетела до небес. Цифры, представленные в 1996 году Gartner Group, Inc. из Стамфорда (Stamford), штат Коннектикут, показали, что ОСВ ПК за типичный амортизационный период в три-пять лет составляет более 40 000 долларов или 8 000—13 000 долларов в год. Gartner Group также подсчитала, что эквивалентная стоимость ПК в 1987 году была менее 20 000 долларов, то есть за последние 10 лет ОСВ удвоилась. Gartner Group строила свои расчеты исходя из методики четырех основных составляющих ОСВ ПК. Цена самого ПК — около 21 процента, затраты на администрирование —еще около 9 процентов, на техническую поддержку — 27 процентов. Огромные 43 процента стоимости падают на «операции конечного пользователя», то есть пользователь плохо использует ПК, теряя время на установку специального ПО или аппаратуры, или тратит ресурсы машины на задачи, не связанных с основной работой. Глава Sun Скотт Мак Нили (Scott McNealy) утверждает: «Фактором, предрешающим победу СК, будет ОСВ... Мы собираемся снизить ее до 2 500 долларов в год». 20 мая 1996 года Oracle, Apple, Netscape, Sun и IBM выпустили первое руководство по СК под названием Network Computer Reference Profile. Этот документ должен был «обеспечить общий подход к созданию популярных и широко распространенных вычислительных технологий на всем диапазоне масштабируемых сетевых вычислительных устройств, включая персональные компьютеры». Подразумевалось, что создатели ПК могут присоединиться к этой программе, оснастив свою продукцию всеми атрибутами СК. При этом вопрос, сможет ли ПК с его большим жестким диском и памятью конкурировать с «облегченными», построенными в соответствие с новым общим подходом, устройствами, оставался открытым. Network Computer Reference Profile определил ресурсы пользовательского интерфейса, такие как терминал VGA, указательное устройство и возможность ввода текста. Были также заданы коммуникационные протоколы, которых должны поддерживаться, чтобы обеспечить ориентацию СК на работу с сети. Таковыми объявлялись, в частности TCP/IP, Telnet с поддержкой терминалов 3270 и 5250 и SNMP (simple network management protocol). Кроме того, перед СК ставилась задача: поддерживать основные стандарты WWW, такие как HTTP, HTML и виртуальная машина Java (описана в следующем разделе). Работа над спецификацией СК началась в IBM задолго до того, как Ларри Эллисон в Париже «сделал первый выстрел». Но небольшая группа инженеров в Рочестере была обеспокоена тем, что дело продвигается медленно, и решила создать свой собственный СК. В конце концов, говорили они, AS/400 — идеальный сервер для такого устройства, особенно если его оснастить шлюзом HTML (это планировалось на 1996 год). Под руководством инженеров Гленна Баталдена (Glenn Batalden) и Лу Беренса (Lou Behrens) эта небольшая группа быстро разработала свой СК на PowerPC. Они решили поместить свое творение в маленькую темную башенку размером примерно со среднего размера книгу, и даже скруглили заднюю часть корпуса, что оно больше походило на крошечную AS/400. В апреле 1996 года разработчики продемонстрировали прототип нового СК на конференции группы пользователей COMMON в Сан-Франциско, вызвав восторженные отклики заказчиков. После этого соответствующие службы немедленно занялись планами поставок нового СК на рынок. 5 сентября 1996 года инженеры Рочестера с гордостью представили миру свое детище, получившее имя IBM Network Station. Новый компьютер был первым СК, разработанным в соответствии с документом Network Computer Reference Profile. Новый СК подключается к серверам IBM и других фирм, но черный цвет и скругленная задняя часть ясно выдают его происхождение от AS/400. 29 октября 1996 года Sun представила свою версию СК — JavaStation. Затем появились и СК других производителей, также созданные в соответствии с общей спецификацией. Эти СК построены на RISC-процессорах различных фирм и используют собственные ОС, обычно на основе Unix. Чтобы противостоять такому напору СК, за день до презентации Sun JavaStation, Microsoft и Intel объявили о своей разработке руководящей спецификации настольного компьютера нового типа, который они назвали NetPC. Подобно СК, NetPC проще обычного ПК, и кроме того, менее гибок и менее расположен к модернизациям. В отличие от СК, NetPC построен на процессоре Intel Pentium и работает только с Windows. В NetPC встроен жесткий диск. Спецификация NetPC не планирует покупную стоимость системы ниже 500 долларов. Ее назначение — лишь сократить стоимость владения ПК, а также создать систему, которой легче управлять в корпоративной среде. Для этого в NetPC используются две новые концепции: одна от Intel под названием Wired for Management, а другая от Microsoft под названием Zero Administration for Windows. Wired for Management разработана Desktop Management Task Force, учрежденной несколькими компаниями в 1992 году. Она предоставляет собой продукт, который подразделения техобслуживания ПК могут использовать для упрощения управления ПК, подключенных к ЛВС. Концепция Zero Administration фирмы Microsoft включена в ОС Windows для автоматического обновления ОС NetPC с сервера при загрузке NetPC, а также для автоматической установки приложений при вызове их пользователем. Кроме того, все созданные или введенные пользователем данные могут автоматически копироваться на сервер, благодаря чему у пользователя всегда будет доступ к ним, независимо от того на каком NetPC в сети он работает. Центральный администратор также может управлять всеми аспектами конфигурации NetPC по сети. Кто же победит в битве за рабочий стол? Скорее всего, фирмы-заказчики. Как СК, так и NetPC обладают возможностями снижения ОСВ. Конкретный тип рабочего места будет зависеть, в конечном счете, от используемых организацией приложений и серверов. Традиционным клиент-серверным приложениям, вероятно, по-прежнему лучше подойдут полноценные ПК. Если же, как утверждают сторонники СК, будущие клиент-серверные приложения будут писаться на Java, то победят приверженцы СК. NetPC также не останется без дела, но полностью его преимущества раскрываются только тогда, когда и сервер, и все пользователи работают исключительно под Windows. В этом отношении СК, который может работать с любым сервером, гораздо более гибок. И не забывайте о тысячах и тысячах приложений, написанных для терминалов 3270 и 5250. Здесь годятся и СК, и ПК. AS/400 поддерживает всех пользователей, начиная от 5250 и заканчивая СК и ПК. Более того, в сети возможны любые сочетания таких пользователей, что позволяет каждому из них оборудовать свое рабочее место так, как ему нравится.Совместные вычисления
Рабочим группам, состоящим из сотрудников одной или нескольких организаций, необходимо взаимодействие и разделение информации. В этой связи многих привлекает клиент-серверное ПО для рабочих групп, обычно называемое групповым ПО (groupware). В основе группового ПО лежит модель совместных действий нескольких пользователей, работающих в группе над общими задачами. Поэтому второе название такой модели — модель совместных вычислений (collaborative computing). Типичные примеры совместных вычислений — создание документа аналитической группой, проведение конференций, участники которых географически удалены друг от друга, или просто обмен электронной почтой. Общий объем применения группового ПО быстро растет. IBM полагает, что 1999 во всем мире у него будет более 250 миллионов пользователей. Мы прилагаем значительные усилия для того, чтобы AS/400 стал для этих пользователей наилучшим сервером. Сервер группового ПО поддерживает пять основных видов деятельности. 1. Управление документами. Электронные документы могут содержать текст, графику, картинки, аудио и даже видео. Сервер группового ПО поддерживает управление этими мультимедийными документами. Он может осуществлять хранение, индексацию, сжатие, выборку и перемещение документов для оптимизации соотношения цена-производительность между различными носителями. Пользователи имеют доступ к документам для просмотра, аннотирования, изменения, распечатки и отправки по факсу. Электронная почта. Этот простой и удобный способ связи очень быстро распространился по всему миру и используется как внутри оргструктур, так и для внешних контактов между ними. Сервер группового ПО в качестве сервера электронной почты должен поддерживать различные системы электронной почты ПК (например, Lotus cc:Mail, Microsoft Mail или Internet Mail). Обычно для этой цели серверу служат стандартные почтовые API. Серверы электронной почты также должны предоставлять шлюзы в различные системы электронной почты, доступ к которым требуется обслуживаемым организациям. Конференции. Масштабы применения СК и ПК в этой области быстро увеличиваются. С помощью электронных досок объявлений, предоставляемых CompuServe, Prodigy, America Online и в Интернете, миллионы людей могут участвовать в дискуссиях в любое удобное для себя время. Такой тип конференций можно назвать асинхронным, так как ее участники могут присоединяться к обсуждению или покидать его в любое время. В конференциях другого типа, называемым синхронными, участники интерактивно работают над совместным проектом в реальном времени, используя мгновенно обновляемые документы и доски объявлений, а также средства, позволяющие слышать и даже видеть друг друга. Такие «электронные собрания» весьма популярны. Планирование. С помощью сервера группового ПО можно планировать время проведения совещаний, а также совместные графики и планы работ. Задача сервера в этом случае — управление разделяемой информацией. Для планирования групповых мероприятий могут использоваться даже такие средства, как триггеры базы данных. Автоматизация деловых процедур (АДП). Технология, известная как АДП (workflow), — средство сократить время, затрачиваемое на различные этапы производственной деятельности: например, на получение и выполнение заказов клиентов или управление техобслуживанием компьютеров. Идеи АДП лежат в основе организационной перестройки многих фирм. В рамках этой технологии работа автоматически передается от одной программы к другой. АДП определяет операции, которые должны выполняться на каждом шаге, и действия, которые нужно предпринять при возникновении исключительных ситуаций. АДП произошла от АСУП (автоматизированная система управления производством) — средства оптимизации и автоматизации последовательности производственных операций. Теперь АДП применяется и во многих других областях, например, в конторской работе с большим документооборотом. Представим себе страховую компанию, где занимаются обработкой страховых претензий клиентов. Подобно производственному конвейеру, обработка претензий включает множество операций с участием большого числа людей; отличие состоит в том, том обработка претензии выполняется на бумаге и не связана с физическим перемещением изделия. Если бумага становится электронным документом, то компьютер может обрабатывать передачу документа с одного этапа процесса на другой автоматически. В такой системе сервер получает запросы и уведомления о событиях и интерпретирует их в соответствии правилами, определенными пользователем. Затем сервер направляет работу соответствующему сотруднику. Сервер также отслеживает прохождение работ, гарантируя, что они выполняются в срок и теми, кто обязан это делать. Сервер группового ПО объединяет пять компонентов, соответствующих этим видам деятельности в интегрированную среду. Например, когда компонент АДП определяет, что в некий процесс должен быть вовлечен дополнительный сотрудник, сервер может для уведомления сотрудника воспользоваться компонентом электронной почты. Добавьте к этому поддержку WWW, обеспечивающую доступ ксерверу с любого терминала из любой точки мира, и Вы получите современный продукт группового ПО, такой как Lotus Notes, Netscape SuiteSpot или Microsoft Exchange. Вероятно, лучший продукт группового ПО на сегодняшний день — Lotus Notes. Его серверная часть, известная как Domino, доступна на AS/400. Domino полностью интегрирован с другими компонентами AS/400, включая DB2/400 и почту AS/400. Он отлично поддерживает WWW, что обеспечивает доступ к нему с помощью любого браузера, не требуя наличия ПК с клиентской частью Notes. Domino может действовать на интегрированном ПК-сервере — Integrated PC Server (IPCS) на всех моделях AS/ 400. На IPCS работают и другие продукты группового ПО и АДП. Мы подробно рассмотрим это в следующем разделе. Встроенная поддержка, известная как Domino for AS/400, имеется только на RISC-моделях в составе версии 4. В прежних версиях AS/400 можно установить до 16 плат IPCS, каждая из которых выполняет Domino и поддерживает около 150 пользователей Notes. Но все же встроенная поддержка обладает большей производительностью и поддерживает тысячи пользователей Notes, а также обеспечивает более тесную интеграцию с данными. Например, встроенный драйвер Domino устраняет надобность в ODBC или каком-либо другом пакетном интерфейсе для доступа к данным AS/ 400. Встроенный Domino также использует многие средства AS/400, включая защиту и управление разделяемыми каталогами. Короче говоря, все те средства, благодаря которым AS/400 получила всеобщее признание, теперь доступны Domino.Упрощенные клиент-серверные вычисления
Хотя мы уже говорили о клиент-серверных вычислениях, я, по сути, так и не определил термин клиент-сервер. Часто даже организации, использующие клиент-серверные вычисления (когда приложение разбивается между серверами и ПК), не имеют ясного представления, что это такое. Поэтому мы кратко рассмотрим модель клиент-сервер, а затем обсудим, чем увенчались усилия IBM по ее упрощению в версии 4. Уже из названия вытекает, что два разных агента — пользователь (клиент) и сервер — работают совместно для выполнения некоторой задачи. Клиент-серверные вычисления устанавливают соотношение между разными машинами: сервер предоставляет обслуживание, а клиент его потребляет. Ключевое слово для описания этого соотношения — взаимодействие, то есть две или более системы кооперируются так, что для пользователя выглядят единой системой. Старое название клиент-серверных вычислений — кооперативная обработка. Как бы мы не определяли понятие клиент-сервер, вот его основные характеристики: в клиент-серверных вычислениях интеллект распределен по сети, а не находятся в каком-то одном месте; ресурсы сервера, как аппаратура, так и ПО, совместно используются многими клиентами; местонахождение разделяемых ресурсов прозрачно для пользователя, независимо от того, располагаются эти ресурсы на той же системе, что и клиент, или в любом другом месте сети; взаимодействие всегда инициируется клиентами, запрашивающими обслуживание, а сервер ожидает от них запросов; клиент и сервер обмениваются информацией посредством сообщений; соединение между ними может быть либо локальным, либо сетью удаленных коммуникаций; система рассматривается с точки зрения пользователя. Путем распределения данных и вычислений клиент-серверные вычисления делают деятельность организаций и их сотрудников намного эффективнее. Но для этого требуется больше, чем просто объединение отдельных приложений, — нужно качественное изменение организации работ. За последние несколько лет многие организации успешно реализовали клиент-серверные приложения, перестроив свой бизнес в соответствии с этой моделью. Те же структуры, где установка клиент-серверных приложений не сопровождалась реорганизацией, немногое выиграли. Дело в том, что клиент-серверные вычисления по сравнению с другими моделями достаточно дороги. Следовательно, если затраты на них не дают ощутимых результатов, то это серьезный удар для фирмы. По этим и другим причинам многие организации просто не рискуют затевать переход на клиент-серверную модель. Исследование Standish Group показало, что лишь один из шести клиент-серверных проектов (16 процентов) заканчивается успехом, в то время как 31 процент — преждевременно прекращается, а остальные просто терпят неудачу. Эти цифры не слишком воодушевляют начинающих, но, в конце концов, кто сказал, что все должно быть легко? Так как модель клиент-сервер сложна и ее внедрение дорого, многие пользователи AS/400 по-прежнему работают только с централизованными приложениями, используя в качестве терминалов 5250 или ПК. Но, хотя они часто заявляют о намерении перейти в будущем к клиент-серверным вычислениям, все же подход «поживем — увидим» будет доминировать в их сознании до тех пор, пока преимущества новой модели не станут очевидными. Задача проектировщиков AS/400 — сделать модели клиент-сервер более привлекательными, путем упрощения создания, установки и сопровождения клиент-серверных приложений. Для этого мы разработали и интегрировали в AS/400 целый ряд продуктов, среди которых важнейшие — представители семейства Client Access. О Client Access кратко упоминалось в главе 5. Эти продукты появились в 1994 году на замену PC Support/400. Хотя последний успешно работал примерно на 80 процентах всех AS/400, через 11 лет потребовалась что-то новое. Нашим ответом на вопрос, заданный временем, стал Client Access. Продукты семейства Client Access поддерживают различные ОС, включая Windows 3.1/95/NT, OS/2, Unix и Macintosh. Client Access представляет собой единый интегрированный пакет, куда входят средства поддержки: соединений с обеспечением независимости от протокола; графического интерфейса пользователя; эмуляции дисплея 5250; сервисов печати; почтовых и офисных сервисов; мультимедийных функций; защиты; управления системой; доступа к базе данных; пересылки файлов; приложений и API. Новые расширения семейства Client Access будут сопровождать каждый выпуск версии 4. Сейчас я хочу лишь познакомить Вас с некоторыми предоставляемыми им возможностями упрощения клиент-серверных вычислений, не рассматривая все средства Client Access подробно. Однако два новейших расширения требуют большего внимания, так как они сильно влияют на управление системой клиент-сервер и создание соответствующих приложений. Добавление нового графического интерфейса администрирования системы в Client Access для пользователей Windows 95/NT сделало удобнее работу с AS/400 для тех, кто предпочитает ПК. Новый интерфейс, названный Operations Navigator, упростил выполнение многих пользовательских задач через панель Windows. Например, при регистрации нового пользователя в системе сразу же автоматически создается профиль пользователя, данные о нем добавляются в системный справочник, и он регистрируется как пользователь Notes или NetWare. Графический интерфейс Windows позволяет осуществлять и многие другие административные действия для AS/400, такие как администрирование базы данных, поддержка резервного копирования, политика защиты и аудита, поддержка принтеров и заданий. Operations Navigator обеспечивает единый интерфейс к ресурсам как ПК, так и AS/400, что значительно упрощает администрирование клиент-серверных конфигураций с участием пользователей Windows. Тем, в конечном счете, нужно освоить только один дополнительный интерфейс. Еще одно расширение, на котором мы задержим свое внимание, имеет кодовое название Project Lightning. Этот продукт обеспечивает эффективный и легкий доступ к базе данных AS/400 для 32-разрядных Windows-приложений. Он предназначен для работы в среде Windows, что достигается соответствием стандартам СОМ/OLE (будут обсуждаться далее в этой главе) и ActiveX. Встроенные модули Visual Basic обеспечивают программистам легкий доступ к хранимым процедурам, базам данным, программам, очередям данных и командам. По командам меню Windows на экран выводятся мастера, которые направляют программиста в процессе подключения к различным функциям AS/400. Фактически, мастера генерируют код, необходимый для обращения к каждой функции AS/400. Затем программисты могут модифицировать код вручную или продолжать генерировать его с помощью мастеров. Три модели приложений, которые были здесь кратко рассмотрены, ни в коем случае не единственные модели вычислений, используемые сегодня на AS/400. Наше повышенное внимание к ним объясняется их особой ролью в версии 4. Следующие разделы посвящены четырем другим основным направлениям модификации AS/400 в версии 4 — двум программным и двум аппаратным. Это также не единственные, но самые заметные расширения.Поддержка приложений
Мы уже обсуждали новые продукты поддержки приложений и в этой, и в предшествующих главах. Вероятно, наиболее значительна в AS/400 поддержка Java. Java быстро становится универсальным языком разработки приложений. По некоторым оценкам уже сейчас его предпочитают более 500 000 разработчиков. Если это так, что вскоре Java будет доминировать среди языков программирования, доступных всем вычислительным системам. В Java мы, кажется, нашли Святой Грааль — открытый язык разработки приложений.Java, Java везде и всюду
Язык Java был разработан фирмой Sun Microsystems, Inc. Первоначально он предназначался для прикладного ПО бытовых электронных приборов, но скоро стал использоваться для приложений, выполнявшихся браузерами. В конце 1995 года Sun сделала Java доступной, разрешив загружать со своего сервера WWW компании Java Development Kit (JDK). Лицензии на спецификации языка стали выдавать всем желающим. В компьютерной индустрии этот язык был принят на «ура» и практически единогласно. Java — объектно-ориентированный язык, похожий на С и С++. Как уже говорилось, он разрабатывался для работы программ на маломощных процессорах, во множестве применяемых в бытовой электронике. Я люблю называть Java упрощенной (de-geeked) версией С++, так как в нем присутствуют многие преимущества последнего, но он не такой сложный. Для обеспечения модульности и быстрой загрузки программ по сети, в модели Java используются небольшие программы, называемые апплетами. Первоначально, Java использовался для расширения возможностей страниц WWW с помощью апплетов, но уже вскоре — для разработки целых клиент-серверных приложений. Все приложение хранилось на сервере, и только часть программы загружалась на пользовательскую машину (ПК или СК) при необходимости. Такое разбиение больших монолитных приложений на небольшие динамически загружаемые фрагменты часто называют моделью компонентного ПО (componentware). Java больше чем просто язык; это целая программная платформа, так как включает виртуальную машину (ВМ), программно моделирующую компьютер. ВМ Java может быть встроена в любую ОС или браузер. Существует и аппаратура, предназначенная специально для Java. Для этих компьютеров Sun создала семейство Java-спе-цифичных микросхем процессора. Среда для программы Java включает в себя ВМ Java, библиотеки классов Java, загрузчик классов, верификатор байт-кода и интерпретатор байт-кода. Байт-код — это внутреннее представление программы на Java. Он генерируется компилятором Java и не зависит от какой-либо аппаратной платформы. Проще всего описать байт-код как промежуточное представление, аналогичное используемому в AS/400 для других языков. Именно этот байт-код пересылается по сети. Так как Java — интерпретируемый язык, обычно, в состав среды времени выполнения входит интерпретатор байт-кода. Для некоторых приложений скорости интерпретации недостаточно, так что в состав среды времени выполнения может быть включен мгновенный компилятор JIT (just-in-time compiler). JIT-компилятор повышает производительность, преобразуя байт-код Java в машинный код процессора, что устраняет необходимость интерпретации. Обратите внимание, что байт-код Java может быть сгенерирован при компиляции программы с любого языка, например с недавно разработанного Netscape JavaScript. Компиляторы других языков и генераторы программ различных фирм также могут генерировать байт-код Java. В настоящее время легко доступны готовые программные (любые: от анимации до элементов деловой логики) компоненты Java Beans[ 81 ], изготавливаемые Sun и другими фирмами. Их применение облегчает написание приложений Java: собрав вместе несколько Beans, можно создать простенький апплет Java без какого-либо программирования. Вы также можете включить Beans как часть в сложное приложение. Далее в этой главе мы рассмотрим среды приложений, сходные с Java Beans. Главное достоинство Java в том, что он принят всеми основными производителями аппаратных и программных средств[ 82 ]. Программирование на этом языке часто характеризуют так: «Пишется однажды — исполняется всегда». Разработчики, создавая программу на одной машине Java, уверены в том, что она будет работать и на любой другой Java-машине. У Java по-прежнему есть конкуренты, наиболее значительный из них — набор протоколов OLE (Object Linking and Embedding) фирмы Microsoft с объектами ActiveX. Объекты ActiveX служат в OLE так же, как Beans в Java. В основе OLE — объектная модель Microsoft, известная под названием СОМ (Component Object Model) OLE и COM привязаны к Windows и нескольким другим ОС. Java существует только в ПО, и поэтому мирно сосуществует с любой ОС на любой аппаратной платформе. Благодаря своей универсальности Java, скорее всего, будет лидировать при разработке будущих клиент-серверных приложений. Первоначально Java воспринимали только как язык программирования WWW, но он быстро стал одним из основных языков всей компьютерной индустрии. Сейчас Java настолько широко распространился, что имеет реальные шансы стать доминирующим языком объектно-ориентированного программирования, заменив С++.Java для AS/400
Мы, разработчики новых версий AS/400, видим в Java язык будущих объектно-ориентированных бизнес-приложений и прилагаем большие усилия для его поддержки. Вопрос, как лучше реализовать ВМ Java на AS/400, задействовав при этом все преимущества системы, — один из самых важных для нас. Ответ на него очевиден, особенно тем, кто в описании Java как полностью программной платформы, моделирующей компьютер в ПО, уловил что-то знакомое. Аналогичными характеристиками обладает машинный интерфейс (MI) AS/400. Возьмем, например, Advanced 36. Для каждой RISC-модели AS/400 в MI встроена полная «виртуальная машина» System/36, которая может выполнять ОС SSP и все приложения System/36. Более того, набор команд System/36 эмулируется MI, то есть эти команды интерпретируются. Та же концепция лежит в основе байт-кода Java. Отсюда вытекает, что логичный путь реализации байт-кода Java на AS/400 — расширение MI. Этот подход также схож с тем, что использовался для поддержки программной модели ILE: там мы реализовали W-код (генерируемое компиляторами ILE промежуточное представление) непосредственно в MI. Следующий шаг — реализация ВМ Java (точнее, интерпретатора байт-кода, необходимого для исполнения программ Java) в SLIC, так же как был реализован код System/36. Интерпретируемый Java отлично подойдет для большинства пользовательских приложений, но, вероятно, не сможет обеспечить достаточную производительность многих серверных приложений. Поэтому мы решили добавить в среду времени выполнения Java не только интерпретатор, но и полный компилятор. Ключ для повышения производительности Java на AS/400 — встроенные потоки, о которых уже говорилось в главе 9. Хотя традиционные приложения AS/400 не написаны для модели потоков, приложения для других систем обычно создаются именно так. Модель потоков поддерживают и Unix, и NT, так что следует ожидать, что приложения Java, предназначенные для выполнения на нескольких платформах, последуют этому примеру. Поддержание хорошей производительности потоков — крайне важно для AS/400. На рисунке 9.7 (глава 9) показана взаимосвязь различных средств поддержки приложений (application enablers) — библиотек времени выполнения — для С, С+ + и Java, IFS и библиотек классов для объектов с реализацией встроенных потоков. Очевидно, что реализация встроенных потоков выгодна не только приложениям Java, но также и всем перенесенным приложениям, которые первоначально были написаны для ОС Unix или NT. Например, Domino для AS/400 представляет собой перенос Domino для AIX. Таким образом, Domino для AS/400 также зависит от хорошей работы потоков. Хотя язык и модель объектов Java — самая большая наша надежда при разработке приложений для разных платформ, AS/400 продолжает поддерживать модель IBM SOM (System Object Model). В отличие от объектной модели Java, SOM не зависит от языка. Объекты SOM описываются на языке IDL (Interface Definition Language) и могут использоваться как объектно-ориентированными, так и языками других типов. SOM основывается на стандарте CORBA (Common Object Request Broker Architecture), разработанном Object Management Group (OMG). Основная цель его создания — сделать открытую, не зависящую от платформы объектную модель, которая будет использоваться разными языками и ОС. Последняя версия стандарта — CORBA-2 — позволяет старым приложениям, написанным на С++ и Smalltalk, взаимодействовать с Java, а также облегчает их перенос на Java. В соревновании производителей за объектную модель, которая станет стандартом для всей индустрии, лидируют Java и Microsoft СОМ, тогда как OMG CORBA-2 — на третьем месте, то есть отстает. Будущее стандарта OMG CORBA неопределенно. Хотя мы сосредоточили значительную часть усилий по развитию AS/400 на Java, при этом удалось применить многое из предыдущих работ над SOM. В V3R6 для RISC-моделей появился компонент SOMobjects, обеспечивающий поддержку времени исполнения для SOM на AS/400. SOMobjects поддерживает переносимость классов между разными системами, на которых работает SOM. В состав SOMobjects также включено множество каркасов (framework). Каркас — это набор объектов, применяемый для общего решения некоторой проблемы. Этим он отличается от библиотеки классов, которая имеет более общее назначение, и не обязательно разработана в связи с какой-либо проблемой. С помощью библиотек классов объекты также можно использовать повторно (мы говорили об этом в главе 3 при разборе объектно-ориентированных концепций). Очень важная часть SOMobjects — каркас DSOM (Distributed System Object Model), который можно использовать для написания приложений на основе распределенных объектов. Каркас DSOM позволяет программе на одном компьютере вызывать метод объекта на другом компьютере. При создании программой экземпляра объекта он может размещаться на удаленной системе. Каркас DSOM определяет, что объект удаленный, и устанавливает связь с каркасом DSOM на удаленной машине. Каркас на удаленной машине создает фактический экземпляр объекта, тогда как локальный каркас DSOM — тень объекта, называемую заместителем (proxy). Программа взаимодействует с заместителем, а локальный каркас DSOM перенаправляет запросы к реальному объекту на удаленной машине. Данный процесс прозрачен для пользователей. SOM на AS/400 на шаг опережает его реализации на других системах. На такое утверждение нам дает право поддержка понятия постоянства объекта. Мы обсуждали постоянство в главе 8 при рассмотрении одноуровневой памяти. На других системах время жизни объекта соответствует времени исполнения создавшего его задания. Это ограничение мешает, если Вам нужно использовать объект в нескольких заданиях. В других системах применяются различные варианты решения данной проблемы; например в OS/2 и AIX — каркас Persistence. Эти решения требуют от программиста явно управлять постоянством объекта, обеспечивая периодическое сохранение его содержимого на диске, что может требовать значительных усилий. AS/400 не использует каркас Persistence, вместо него постоянные SOM-объекты в AS/400 поддерживает одноуровневая память, что не требует усилий программиста. При создании экземпляра SOM-объекта задается, будет ли он защищенным (то есть постоянным в терминах AS/400). Защищенные объекты инкапсулируются и существуют параллельно с уже рассмотренными нами объектами OS/400. Созданный же постоянный объект помещается в каталог IFS, аналогично созданию объекта OS/400 в библиотеке AS/400. Защищенные объекты имеют имена и могут разделяться, сохраняться или восстанавливаться, как и любые объекты OS/400 с помощью соответствующих команд. В MI эти объекты реализованы в виде байтовых пространств. Таким образом, защита постоянных объектов обеспечивается с помощью системных указателей и компонентов контроля доступа SLIC. По соображениям совместимости SOMobjects также поддерживают незащищенные объекты SOM. С началом внедрения в AS/400 языка и объектов Java, мы смогли использовать поддержку одноуровневой памятью постоянных объектов так же, как поддержку SOM-объектов. Преимущество модели постоянных объектов AS/400 — в меньших накладных расходах системы при работе с объектами. Другим системам для поддержания постоянства объектов и обеспечения их совместного использования несколькими программами приходится выполнять дополнительные команды; постоянно обновлять объекты на диске. Постоянная одноуровневая память не требует подобного обновления, поэтому при работе с объектами AS/400 выполняет меньше команд и обращений к диску, чем другие системы. Как уже говорилось в главе 8, одноуровневой памяти AS/400 не приходится заниматься «сборкой мусора» для разделяемых объектов. Все это означает, что AS/400 имеет явное преимущество в масштабируемости сервера Java, его способности поддерживать приложения Java и пользователей перед другими аналогичными системами. Лаборатория IBM в Торонто разрабатывает инструментальные средства типа VisualAge for Java, помогающие пользователям совмещать приложения Java на разных платформах. VisualAge for Java обеспечивает интегрированную среду разработки таких приложений. Бизнес-партнеры AS/400 также предоставляют разнообразные средства разработки для Java. Пользователи, желающие использовать Java прямо сейчас, могут сделать это с помощью VisualAge for Java. Полная среда Java на AS/400, выпущенная в начале 1998 года, включает встроенные потоки, значительно повышающие общую производительность системы.Проект San Francisco (Каркасы Java)
В 1994 году группа разработчиков приложений AS/400 предложила лаборатории в Рочестере подумать о разработке новой базы приложений на основе объектных технологий. Общая прикладная база давала возможность избежать больших расходов и риска в ходе объектно-ориентированного программного проекта, получившего название San-Francisco. Ранее мы говорили, что каркас — это набор объектов, обеспечивающих общее решение некоторой задачи. Как правило, каркасы приложений разрабатываются таким образом, чтобы разработчики приложений могли легко настроить их для своих нужд. Основой San-Francisco были избраны С+ + и SOM. Но в начале 1996 года мы попробовали обучать бизнес-партнеров созданию SOM-объектов с помощью этих языков и пришли к выводу, что они слишком сложны. Гораздо более легкой и продуктивной средой оказалась Java, которая в то время быстро завоевывала позиции промышленного стандарта. Поэтому проект San-Francisco был переориентирован на Java. San-Francisco — это серверный продукт, предназначенный для разработчиков, создающих Java-приложения для различных серверных ОС. Первоначально проект предназначался только для OS/400, но позднее был расширен для поддержки NT, AIX, HP/UX, OS/2 и MVS, а также Java (СК и ПК) и Windows. Часть группы разработчиков San-Francisco работала в Рочестере, а часть — в Беб-лингене (Boeblingen), Германия. Рочестерцы отвечали за структуры низкого уровня и их встраивание в ОС. В Беблингене разрабатывали каркасы высокого уровня. На рисунке 11.3 показаны три уровня каркасов San-Francisco. Базовый уровень взаимодействует с ОС через ВМ Java. Он управляет интерфейсами с ОС, другими приложениями, вводом-выводом и сетью, доступом к объектам, а также отслеживает последние. Базовый уровень также содержит классы объектов, из которых создаются объекты верхних уровней. Таким образом, базовый уровень скрывает сложности нижележащих структур от разработчика. Рисунок 11.3. Каркасы Сан-Франциско
Рисунок 11.3. Каркасы Сан-Франциско
Уровень общих деловых объектов содержит множество объектов, обычно необходимых деловым приложениям: время, дата, условия конвертации валют, единицы измерения и др. Общие деловые объекты — это «строительные блоки», которые разработчик может использовать при создании приложения. На уровне основных деловых процессов создаются приложения. Каждый основной деловой процесс предназначен для конкретного типа приложений, например, главной бухгалтерской книги или электронного обмена данными. Сам по себе такой процесс не является полноценным приложением, но содержит основные функции, необходимые всем приложениям данного типа. Для создания базы приложения каркас связывает нужные общие деловые объекты с объектами в основном деловом процессе. То есть он не только содержит часто используемые функции для данного типа приложений, но и позволяет их комбинировать. Так что каркас может быть легко настроен разработчиком для своих нужд. Некоторые авторы приложений используют только один или два нижних уровня, самостоятельно создавая общие деловые объекты или даже основные деловые процессы. IBM поощряет такую деятельность разработчиков — участников проекта San-Francisco. Отдельные крупные разработчики приложений уже перешли на собственные объектные среды разработки и San-Francisco им не нужен. Основной рынок для этого проекта — множество средних и мелких создателей программ во всем мире. Так, большой интерес проявлен в Европе — ведь большинство средних разработчиков трудятся там. Многие из потенциальных заказчиков уже сотрудничают с нами в рамках координирующей группы San Francisco Advisory Group. Далее мы рассмотрим две другие темы, связанные с поддержкой приложений: использование интегрированных ПК-серверов в качестве дополнительных процессоров приложений AS/400; и серверные модели AS/400.
Интегрированные ПК-серверы
В главе 10 мы говорили о том, как IOP и его специализированная ОС реального времени управляют устройствами. Управление устройствами было первоначальным, но не единственным назначением IOP. Так как IOP — это полноценные процессоры, которые могут поддерживать различные функции и даже различные ОС, то использование их IBM для других типов приложений было лишь вопросом времени. В последние несколько лет в AS/400 были введены IOP специального назначения, большего, нежели только поддержка устройств. На них возлагалась поддержка таких специфических функций как RAID-5, факс, беспроводные сети и AppleTalk. В связи с этим совершенно естественно дальнейшее использование таких IOP для выполнения и других типов приложений, включая серверные. В 1994 году IBM объявила о первом серверном приложении, выполнявшемся на IOP, — FSIOP (File Server I/O Processor). FSIOP представлял собой плату удвоенной ширины, которая вставлялась в AS/400. На плате находился процессор Intel 486 и память для него. Другие устройства, включая диски, разделялись с AS/400. Плата FSIOP поддерживала один или два порта ЛВС из расчета до 255 пользователей на порт. Можно было подключать сети Token-Ring или Ethernet, причем в сервере AS/400 могло быть установлено нескольких таких плат. На FSIOP работала ОС OS/2, хотя пользователи никогда не имели с ней дела напрямую. AS/400 управляла всеми взаимодействиями с OS/2; пользователю были видимы только приложения файл-сервера. Первым файл-серверным приложением, о котором мы объявили, был OS/2 LAN Server. Позднее к нему добавились NetWare и Lotus Domino. Когда стало очевидно, что FSIOP можно использовать не только как файл-сервер, мы изменили его название на Integrated PC Server (IPCS) и позже создали новые модели IPCS с более мощными процессорами Intel Pentium и увеличенными объемами памяти. В версии 4 OS/2 была заменена Warp Server. Были добавлены и новые приложения, такие как Flowmark Workflow. У IPCS внутри AS/400 много преимуществ. Во-первых, выполнение файл-серверных приложений перекладывается на выделенный процессор, что повышает общую производительность. Нет необходимости в отдельном ПК-сервере вне AS/400 — заказчик получает среду с единым сервером. AS/400 предоставляет файл-серверу интегрированную защиту, целостность и функции администрирования. Например, одна из поддерживаемых в IFS файловых систем, называемая QLANSrv, используется файл-сервером. С помощью простых команд данные перемещаются между разными файловыми системами. Кроме того, у файл-сервера есть доступ ко всем устройствам AS/400. Недостаток отдельного файл-сервера ПК — необходимость иметь собственные диски. Если данные на сервере очень важны для пользователя, последний, несомненно, предпримет определенные меры, чтобы предохранить их. AS/400 может автоматически выполнять резервное копирование данных, на тот случай, если что-то случится с дисками сервера, но даже эта мера может оказаться недостаточной. Некоторые пользователи требуют особо устойчивой дисковой системы для защиты своих данных, а также гарантий, что работа не нарушится из-за сбоя диска. Для ПК-серверов доступны технологии зеркалирования дисков и RAID, а для достижения должного уровня безопасности могут быть установлены соответствующие программные пакеты. Так что, по сути, проблема отдельного сервера ПК сводится к дублированию ресурсов. Так как в AS/400 уже реализована и технология зеркалирования дисков, и технология RAID, то явно имеет смысл использовать дисковые устройства AS/400. То же самое верно и для защиты. Одно из очевидных решений — поместить ПК «под крышу» AS/400 и предоставить ему доступ к ресурсам последней. Именно это и делает IPCS. Использование IPCS в AS/400 вместо отдельного ПК-сервера дает дополнительные преимущества, если AS/400 и ПК-сервер располагаются на значительном удалении друг от друга. Предположим, что некто в удаленном подразделении добавил на сервер ПК новое приложение, что полностью исчерпало дисковое пространство на нем. Если на месте нет подготовленного персонала, то специалисту из головной организации нужно туда ехать, создавать резервную копию дисков, устанавливать диски большего объема и восстанавливать резервную копию. Если таких удаленных подразделений много, то затраты на командировки могут быть огромны. Но так как IPCS использует часть диска AS/400, то в центральном подразделении можно просто изменить объем дискового пространства, выделенного для IPCS. Успех IPCS показал, что отдельные машины приложений «под крышей» AS/400 могут быть полезны заказчикам AS/400, не желающим иметь дела с отдельными ПК-серверами. IBM решила распространить концепцию машин приложений на другие серверные ОС, конкретно, на Unix и Windows NT. Процессор приложений Unix мы впервые подготовили в начале 1997 для одного крупного заказчика, которому требовалось установить во множестве удаленных подразделений сервера как AS/400, так и Unix. (Позже процессор приложений Unix стал доступен и другим желающим.) Помещение сервера Unix под крышу AS/400 позволило этому заказчику содержать только одну систему в каждом подразделении и по-прежнему использовать приложения как AS/400, так и Unix. Интегрированный сервер Unix представляет собой плату, аналогичную IPCS. В отличие от IPCS, в сервере Unix применяется процессор PowerPC, а не Intel. ОС для этого интегрированного сервера служит AIX, версия Unix от IBM. Следует отметить, что интегрированный сервер AIX использует не только некоторые драйверы устройств AS/400, но также и собственные локальные устройства. Другой пример интеграции полного сервера приложений в AS/400 — Windows NT на IPCS. В первой реализации используется процессор Intel Pentium Pro. Сейчас в качестве ОС используется Microsoft Windows NT Server 4.0, но в будущем возможна установка следующих версий этой ОС. В 1997 году IBM поставляла процессор приложений Windows NT лишь своим бизнес-партнерам, общедоступным он стал в начале 1998. Так как на таком IPCS может выполняться любое приложение NT Server для процессора Intel, то IBM пришлось добавить некоторые локальные устройства, включая клавиатуру, мышь и дисплей. Таким образом, в отличие от оригинального IPCS, эта версия имеет разъемы для подключения локальных устройств. К этому серверу приложений можно подключать и другие адаптеры PCI. Некоторые устройства, такие как диски, компакт-диски и адаптеры ЛВС разделяются с AS/400. Для этой цели процессор приложений AS/400 использует драйверы устройств AS/400. Чтобы Windows NT могла исполняться на разных аппаратных платформах, Microsoft определила так называемый слой абстрагирования от оборудования HAL (hardware abstraction layer). HAL — это слой кода, предназначенный для изоляции ядра ОС от аппаратных различий разных платформ. Например, HAL скрывает такие детали, как интерфейсы ввода-вывода, котроллеры прерываний и механизмы многопроцессорных коммуникаций. Вместо работы с этой аппаратурой напрямую, NT обращается к процедурам HAL. Концептуально HAL напоминает MI, но на значительно более низком уровне. Так как большая часть процессоро-зависимого кода по-прежнему находится в ядре, Windows NT нельзя считать аппаратно-независимой. То же самое можно сказать и о приложениях NT, поскольку они компилируются непосредственно в двоичные коды конкретного процессора. Тем не менее, HAL позволяет обеспечить некоторую дополнительную интеграцию между процессором приложений NT и AS/400. Для процессора приложений NT был разработан новый HAL, который обеспечивает разделение устройств и передачу команд в обе стороны без изменений в NT. Например, вместо прерывания NT при возникновении ошибки, новый HAL передает ошибки на обработку AS/400. Другие функции администрирования и управления также выполняются либо AS/400, либо NT. Файловая система NT (NTFS) размещается в байтовом пространстве OS/400. Пока отдельные файлы видимы только NT. Когда-нибудь, NTFS будет интегрирована в IFS, либо эти файлы станут «видимы» AS/400 с помощью какого-то другого механизма. Сегодня же для связи между этими двумя серверными ОС можно использовать ODBC.Серверные модели AS/400e
С начала 90-х мы стремились превратить AS/400 в сервер мирового класса. Архитектура системы позволяла организовать полную серверную среду без ущерба для наших традиционных заказчиков, привыкших использовать AS/400 в централизованных конфигурациях. Заказчики говорили нам, что хотят перейти к клиент-серверным вычислениям, но не желают ради этого нарушать порядок работ в своей фирме. Для AS/400 это не проблема. Однако мы столкнулись с нежеланием других производителей мини-компьютеров терять свой имидж. Некоторые из них тоже хотели поставлять на рынок серверы, но при этом не смогли модифицировать свои действующие модели. Практически каждая вторая из этих фирм заменила свои централизованные системы новыми, установив на них ОС Unix. Соответственно этим фирмам пришлось объяснять своим заказчикам, что если те хотят перейти на клиент-серверные вычисления, то им придется переделывать или покупать заново все приложения для новой системы. Никто не верил, что мы можем превратить в сервер существующую AS/400. Поэтому мы решили продемонстрировать серьезность своих намерений, создав несколько новых серверных моделей. Это не было чисто маркетинговой уловкой, но и помогло нам добиться лучшего соотношения цена-производительность в работе новых моделей. В сентябре 1993 года мы представили первые серверные модели семейства AS/400. Новое семейство серверов AS/400 Advanced Server появилось в мае 1994 года и включало две модели — для мелких и средних фирм. В июне 1995 года были объявлены три новые серверные модели, позволившие занять весь рынок AS/400. Мы старались, чтобы они оптимально функционировали в качестве: сервера базы данных; сервера коммуникаций; обработчика пакетных программ. Все эти функции требуют большего объема вычислений, чем интерактивная обработка, и, соответственно, более высокой производительности по сравнению с традиционными моделями. Поэтому первоначально установили в младшие модели серверов высокопроизводительные процессы IMPI из старших традиционных моделей. Например, один или два процессора из старшей модели F70 (1993 год), выполненной в виде стоек, были использованы в меньших серверных моделях 135 и 140 соответственно. Мы также снабдили эти модели достаточным объемом памяти, дискового пространства и возможностями подключения к ЛВС для поддержки мощных процессоров в серверной среде. Эти процессоры значительно повысили производительность серверных приложений в сравнении с традиционными моделями. Работа сети, базы данных, файл-сервера и компиляторов также улучшилась. Появление RISC-процессоров, гораздо более производительных по сравнению с их предшественниками IMPI, позволило использовать одинаковые процессоры как в серверах, так и в традиционных системах. Поскольку серверные модели не предназначены для интерактивных вычислений, производительность традиционных интерактивных приложений, например, использующих рабочие станции 5250, на этих моделях снизилась. Число интерактивных рабочих станций, которые могут быть подключены к серверной модели, также сократилось. Пользователи, применяющие как интерактивные, так и клиент-серверные приложения, могли добиться той же производительности, что и на серверных моделях, сочетая традиционную модель с одним из этих процессоров. Ведь традиционные модели не имеют ограничений ни для интерактивных, ни для серверных приложений. Серверные модели — это системы, специально разработанные для повышения производительности за меньшую цену при работе в условиях клиент-сервер. Серверные модели AS/400 стали так популярны, что в е-серии мы решили расширить их диапазон и предложили рынку новые типы серверов. К этому нас побудили, в том числе, некоторые изменения в приложениях наших бизнес-партнеров. Например, многие из них теперь используют многоуровневую (multi-tier) клиент-серверную архитектуру. В трехуровневой архитектуре, клиенты ПК могут быть подключены к одному или нескольким выделенным серверам приложений, которые, в свою очередь, подключены к выделенным серверам базам данных. К серверам разных уровней предъявляются и разные требования. Поэтому теперь мы предоставляем своим заказчикам специально сконфигурированные мощные модели серверов приложений написанных бизнес-партнерами. С распространением AS/400 на другие среды появятся и новые специализированные модели е-серверов.Обработка данных
Подробно тема обработки данных уже обсуждалась в главе 6, а сейчас мы лишь кратко рассмотрим последние модификации в этой области. Сразу отмечу, что расширение возможностей по обработке данных в AS/400 — одно из приоритетных направлений нашей работы. Я уже говорил, что огромный незадействованный ресурс для бизнеса многих фирм — их оперативные данные. И по мере того как наши заказчики начинают это понимать, они пытаются применить свои AS/400 соответствующим образом. В конце концов, данные это только товар; конкурентные преимущества же позволяют получить знания. Поэтому неудивительно, что хранилища данных и средства их анализа так быстро развиваются. Самой распространенная ныне реализация хранилища данных для небольшой рабочей группы — использование отдельных серверов. На этом рынке IBM сталкивается с сильной конкуренцией других производителей. Но в случае, когда главный критерий выбора системы — возможности базы данных, корпорация чувствует себя вполне уверенно. AS/400 оснащена первоклассной базой данных с очень широким диапазоном применения. На одном краю этого диапазона — системы AS/400 начального уровня, прямо конкурирующие с серверами и базами данных ПК. На другом — многопроцессорные конфигурации, объединяющие до 32 систем в кластере с помощью OptiConnect. Учитывая, что к каждой из таких систем можно подключить от одного до нескольких терабайтов дискового пространства, общий размер базы данных превосходит все, что только можно было вообразить себе несколько лет назад. Ключевая и ближайшая задача IBM в этой области — повышение производительности базы данных (особенно SQL) на всем диапазоне систем. Вообще-то, «родной» интерфейс DB2/400 позволяет обеспечить более высокую производительность, нежели SQL, но поскольку все больше и больше приложений пишется для интерфейса SQL, то именно он — наша главная забота. Другая проблема DB2/400 (как и любой другой базы данных) — обработка сложных типов данных, таких как объекты. При повсеместном переходе на использование распределенных объектов, база данных должна будет работать с этими абстрактными типами данных. Хотя крайне маловероятно, что кто-либо из основных производителей баз данных до конца столетия откажется от реляционной модели в пользу полностью объектно-ориентированной, все же нужно работать на опережение. Несмотря на то, что в данной области по-прежнему нет стандартов, организации типа OMG вносят предложения по методам хранения объектов или их компонентов в реляционной базе данных с возможностью выборки через систему управления объектно-ориентированной базой данных. IBM также рассматривает аналогичные предложения по базе DB2. Если эти предложения будут приняты, мы их реализуем. DB2/400 будет оставаться опорой для приложений AS/400 в версии 4. В базы данных AS/400 будут внесены изменения, повышающие производительность и расширяющие функциональные возможности как больших, так и малых баз данных. В следующие несколько лет, в силу ожидаемого громадного увеличения мощности AS/400, возможно появление очень больших баз данных.Качественный рост старших моделей AS/400е
Уже рассмотренные нами новые программные технологии позволят обеспечить значительный рост производительности и емкости AS/400. В то же время, цена этого роста будет гораздо ниже, чем в прошлом. Давайте остановимся на двух основных аппаратных направлениях развития, которые позволят значительно расширить возможности старших моделей и сократить стоимость аппаратуры для всех систем серии AS/400е. Развитие старших моделей стало основным направлением наших работ в начале 90-х. Тогда многие наши крупные заказчики «уперлись в потолок» возможностей своих AS/400. Их требования к производительности и объемам системы превосходили то, что мы могли предоставить. Эти требования и подтолкнули нас к переходу на PowerPC. С появлением систем AS/400 на базе RISC-процессоров мы смогли на какое-то время удовлетворить потребности заказчиков в новых системах старшего уровня. Но спрос на еще большие объемы и производительность не уменьшился. Нашим ответом на растущие требования должны стать возможности моделей серии AS/400е. В этом разделе мы рассмотрим два метода, с помощью которых IBM планирует достичь намеченных высот производительности: одиночные системы и кластеры.RISC-процессор и перспективы его развития
Я всегда считал, что у автомобиля не может быть слишком много лошадиных сил, а у компьютера — слишком мощного процессора. Кажется, я же упоминал, что люблю управлять гоночными автомобилями? Даже машина, на которой я езжу каждый день, заключает в своем двигателе Northstar (имя, которое мне всегда нравилось) 300 лошадиных сил. Мне не часто требуется столь мощный двигатель, чтобы добраться до своего офиса в IBM, но как приятно иногда «пощекотать своих лошадок» и убедиться, что все они проснулись! Так же преданно, как и мощные машины,я люблю мощные компьютеры. В моем домашнем ПК два процессора Pentium Pro. Разница в моей привязанности к мощным автомобилям и мощным компьютерам — это разница между спортивным интересом и деловой необходимостью.
Требования бизнеса к обслуживающим его приложениям на протяжении многих лет постоянно стимулируют рост мощности процессоров. Именно поэтому в серии AS/400е мы увеличили мощность процессоров примерно в пять раз. Эта тенденция сохранится и в будущем, и мы создадим еще более мощные системы и серверы AS/400е.
Несколько лет назад производительность процессора для System/38 и ранних моделей AS/400 не считалась крайне важной. Мы шутили, что Pacific — кодовое название для System/38 — является сокращением от «Performance Ain't Critical if Function Is Complete»[ 83 ]. Мы сознательно жертвовали мощностью в пользу функциональности, зная, что, в конце концов, технологический прогресс приведет нас и к оптимальной производительности. Как показало время, такое решение было верным: сегодня у AS/400 есть и то, и другое.
К тому же ранние системы использовались для приложений интерактивной обработки, где производительность процессора менее важна, чем производительность ввода-вывода. В главе 10 мы рассмотрели, как на протяжении многих лет велась оптимизация AS/400 для достижения выдающейся производительности ввода-вывода.
Архитектура AS/400 также уменьшала потребность в высокопроизводительном процессоре. В главах 8 и 9 говорилось, что одноуровневая память и эффективная структура задач AS/400 делают ненужным выполнение ОС многих процессорных команд, необходимых для тех же самых приложений на других компьютерах. Также было отмечено, что благодаря постоянной одноуровневой памяти AS/400 выполняет меньше команд и меньше обращений к диску при работе с объектами. Если команду не нужно выполнять, то это вполне компенсирует недостаток производительности процессора.
По сравнению с интерактивными приложениями, большинство новых приложений для AS/400 требуют большей мощности процессора. Когда в начале 90-х наметился переход к клиент-серверным вычислениям, приложения AS/400 стали работать более интенсивно. Серверные модели были одним из способов обеспечения поддержки этой интенсивности. Другим способом стала технология PowerPC.
Технология PowerPC лежит в основе повышения производительности для версии 4. (Этот процессор, а также все поколения 64-разрядных процессоров, которые разрабатывались или разрабатываются в Рочестере, подробно описаны в главе 2.) Мы использовали первое и второе поколения RISC-процессоров PowerPC в AS/400 в 1994 и 1995 годах. Системы версии 4 оснащены процессорами PowerPC третьего и четвертого поколений.
Производительность одиночного процессора важна для ПК, где процессор обрабатывает все вычисления и операции ввода-вывода. В таких системах нужны процессоры с высокими тактовыми частотами и большими кэшами. Однако для многопользовательских систем оптимально сочетание нескольких процессоров. Если требуется разделение памяти, как в большинстве коммерческих приложений, то наиболее эффективна модель SMP.
В главе 2 мы говорили, что слабое место большинства современных систем SMP — интерфейс памяти. Без эффективной системы памяти высокопроизводительные процессоры в конфигурации SMP по большей части простаивают в ожидании доставки данных.
Я очень люблю систему Cray CS6400, в которой 64 процессора использовали общую память с помощью четырех шин памяти, а не одной. Этот суперкомпьютер стоимостью в 4 миллиона долларов, предназначавшийся, кстати, для деловых приложений, использовал процессоры SuperSparc, тактовая частота которых — всего лишь 60 или 85 МГц. Высочайшая производительность достигалась этим компьютером не за счет высокоскоростных процессоров, которые большую часть времени простаивают, но за счет передового интерфейса памяти, регулирующего доступ процессоров к памяти.
Суперкомпьютер ASCI Option Blue Pacific — совместная разработка IBM и Министерства энергетики США — достигает высокой производительности за счет другой новейшей подсистемы памяти. В главе 2 рассматривалась и эта сама подсистема, и то, как ее версия используется в AS/400 для обеспечения производительности масштабируемых 8-ми и 12-процессорных конфигураций SMP. Несмотря на достаточно скромные возможности процессоров Apache второго поколения, эта подсистема памяти позволила компьютерам серии AS/400е достичь производительности в несколько раз выше, чем у ранних систем, оснащенных высокопроизводительными процессорами первого поколения Muskie. 12-процессорные системы с процессорами Apache сейчас могут поспорить по этому поводу с самыми крупными мэйнфреймами.
Мы планируем продемонстрировать промышленную модель самого мощного в мире суперкомпьютера в декабре 1998 года. Он использует новую реализацию подсистемы памяти процессоров Apache, что позволяет эффективно применять высокоскоростные процессоры даже в больших конфигурациях SMP.
Процессоры PowerPC четвертого поколения используют новую реализацию подсистемы памяти для достижения супервысокой эффективности. Эти процессоры могут поддерживать 16-канальные конфигурации. Четвертое поколение 64-разрядных процессоров PowerPC имеет различные уровни производительности, от 250 МГц до, примерно, 800 МГц. Не стоит и говорить, что мы ожидаем значительный рост общей производительности систем в течение следующих нескольких лет.
Конечно, одной мощности процессора недостаточно для высокой производительности компьютера. Мы в Рочестере — сторонники сбалансированных систем. Возможности памяти, дисков и ввода-вывода будут возрастать так же быстро, как и процессора. В главе 12 я познакомлю Вас с тестами, используемыми для оценки сегодняшней и будущей производительности. Мы также сравним серии AS/400е с некоторыми другими компьютерами по этому параметру.
Для сбалансированного роста производительности мы предусматриваем также улучшение процедур резервного копирования, IPL и восстановления после сбоев. Наконец, чтобы защитить вложения наших заказчиков в аппаратуру, мы обеспечили поддержку всех только что обсуждавшихся расширений вновь разработанными корпусами серии AS/400е. Прирост аппаратной производительности достигается простой заменой платы процессора.
Ушло в прошлое время, когда немногочисленные разработчики архитектуры AS/ 400 мечтали о процессорах класса суперкомпьютеров, сотнях гигабайтах памяти и терабайтах дискового пространства. Бывало, что над нашими идеями архитектуры, которая будет соответствовать таким невообразимым возможностям, смеялись. Нам говорили, что никто и никогда не создаст таких больших систем. И вот, это «никогда» наступило.
Кажется, я же упоминал, что люблю управлять гоночными автомобилями? Даже машина, на которой я езжу каждый день, заключает в своем двигателе Northstar (имя, которое мне всегда нравилось) 300 лошадиных сил. Мне не часто требуется столь мощный двигатель, чтобы добраться до своего офиса в IBM, но как приятно иногда «пощекотать своих лошадок» и убедиться, что все они проснулись! Так же преданно, как и мощные машины,я люблю мощные компьютеры. В моем домашнем ПК два процессора Pentium Pro. Разница в моей привязанности к мощным автомобилям и мощным компьютерам — это разница между спортивным интересом и деловой необходимостью.
Требования бизнеса к обслуживающим его приложениям на протяжении многих лет постоянно стимулируют рост мощности процессоров. Именно поэтому в серии AS/400е мы увеличили мощность процессоров примерно в пять раз. Эта тенденция сохранится и в будущем, и мы создадим еще более мощные системы и серверы AS/400е.
Несколько лет назад производительность процессора для System/38 и ранних моделей AS/400 не считалась крайне важной. Мы шутили, что Pacific — кодовое название для System/38 — является сокращением от «Performance Ain't Critical if Function Is Complete»[ 83 ]. Мы сознательно жертвовали мощностью в пользу функциональности, зная, что, в конце концов, технологический прогресс приведет нас и к оптимальной производительности. Как показало время, такое решение было верным: сегодня у AS/400 есть и то, и другое.
К тому же ранние системы использовались для приложений интерактивной обработки, где производительность процессора менее важна, чем производительность ввода-вывода. В главе 10 мы рассмотрели, как на протяжении многих лет велась оптимизация AS/400 для достижения выдающейся производительности ввода-вывода.
Архитектура AS/400 также уменьшала потребность в высокопроизводительном процессоре. В главах 8 и 9 говорилось, что одноуровневая память и эффективная структура задач AS/400 делают ненужным выполнение ОС многих процессорных команд, необходимых для тех же самых приложений на других компьютерах. Также было отмечено, что благодаря постоянной одноуровневой памяти AS/400 выполняет меньше команд и меньше обращений к диску при работе с объектами. Если команду не нужно выполнять, то это вполне компенсирует недостаток производительности процессора.
По сравнению с интерактивными приложениями, большинство новых приложений для AS/400 требуют большей мощности процессора. Когда в начале 90-х наметился переход к клиент-серверным вычислениям, приложения AS/400 стали работать более интенсивно. Серверные модели были одним из способов обеспечения поддержки этой интенсивности. Другим способом стала технология PowerPC.
Технология PowerPC лежит в основе повышения производительности для версии 4. (Этот процессор, а также все поколения 64-разрядных процессоров, которые разрабатывались или разрабатываются в Рочестере, подробно описаны в главе 2.) Мы использовали первое и второе поколения RISC-процессоров PowerPC в AS/400 в 1994 и 1995 годах. Системы версии 4 оснащены процессорами PowerPC третьего и четвертого поколений.
Производительность одиночного процессора важна для ПК, где процессор обрабатывает все вычисления и операции ввода-вывода. В таких системах нужны процессоры с высокими тактовыми частотами и большими кэшами. Однако для многопользовательских систем оптимально сочетание нескольких процессоров. Если требуется разделение памяти, как в большинстве коммерческих приложений, то наиболее эффективна модель SMP.
В главе 2 мы говорили, что слабое место большинства современных систем SMP — интерфейс памяти. Без эффективной системы памяти высокопроизводительные процессоры в конфигурации SMP по большей части простаивают в ожидании доставки данных.
Я очень люблю систему Cray CS6400, в которой 64 процессора использовали общую память с помощью четырех шин памяти, а не одной. Этот суперкомпьютер стоимостью в 4 миллиона долларов, предназначавшийся, кстати, для деловых приложений, использовал процессоры SuperSparc, тактовая частота которых — всего лишь 60 или 85 МГц. Высочайшая производительность достигалась этим компьютером не за счет высокоскоростных процессоров, которые большую часть времени простаивают, но за счет передового интерфейса памяти, регулирующего доступ процессоров к памяти.
Суперкомпьютер ASCI Option Blue Pacific — совместная разработка IBM и Министерства энергетики США — достигает высокой производительности за счет другой новейшей подсистемы памяти. В главе 2 рассматривалась и эта сама подсистема, и то, как ее версия используется в AS/400 для обеспечения производительности масштабируемых 8-ми и 12-процессорных конфигураций SMP. Несмотря на достаточно скромные возможности процессоров Apache второго поколения, эта подсистема памяти позволила компьютерам серии AS/400е достичь производительности в несколько раз выше, чем у ранних систем, оснащенных высокопроизводительными процессорами первого поколения Muskie. 12-процессорные системы с процессорами Apache сейчас могут поспорить по этому поводу с самыми крупными мэйнфреймами.
Мы планируем продемонстрировать промышленную модель самого мощного в мире суперкомпьютера в декабре 1998 года. Он использует новую реализацию подсистемы памяти процессоров Apache, что позволяет эффективно применять высокоскоростные процессоры даже в больших конфигурациях SMP.
Процессоры PowerPC четвертого поколения используют новую реализацию подсистемы памяти для достижения супервысокой эффективности. Эти процессоры могут поддерживать 16-канальные конфигурации. Четвертое поколение 64-разрядных процессоров PowerPC имеет различные уровни производительности, от 250 МГц до, примерно, 800 МГц. Не стоит и говорить, что мы ожидаем значительный рост общей производительности систем в течение следующих нескольких лет.
Конечно, одной мощности процессора недостаточно для высокой производительности компьютера. Мы в Рочестере — сторонники сбалансированных систем. Возможности памяти, дисков и ввода-вывода будут возрастать так же быстро, как и процессора. В главе 12 я познакомлю Вас с тестами, используемыми для оценки сегодняшней и будущей производительности. Мы также сравним серии AS/400е с некоторыми другими компьютерами по этому параметру.
Для сбалансированного роста производительности мы предусматриваем также улучшение процедур резервного копирования, IPL и восстановления после сбоев. Наконец, чтобы защитить вложения наших заказчиков в аппаратуру, мы обеспечили поддержку всех только что обсуждавшихся расширений вновь разработанными корпусами серии AS/400е. Прирост аппаратной производительности достигается простой заменой платы процессора.
Ушло в прошлое время, когда немногочисленные разработчики архитектуры AS/ 400 мечтали о процессорах класса суперкомпьютеров, сотнях гигабайтах памяти и терабайтах дискового пространства. Бывало, что над нашими идеями архитектуры, которая будет соответствовать таким невообразимым возможностям, смеялись. Нам говорили, что никто и никогда не создаст таких больших систем. И вот, это «никогда» наступило.
Кластеры и постоянная готовность
Если всех описанных расширений одиночных систем Вам мало, то можете объединить до 32 систем AS/400 в кластер. Кластер AS/400, несомненно, позволяет повысить производительность и емкость, но, что гораздо важнее, обеспечивает готовность вычислительной системы к работе 24 часа в день 7 дней в неделю. Одиночные системы таких гарантий дать не могут. Кластеры были впервые использованы Digital Equipment Corporation как средство масштабируемости систем VAX. С течением времени кластеры завоевали популярность на рынках Unix и MVS, как средство обеспечения повышенной готовности. Появившиеся в последнее время заявления о поддержке кластеров в новых системах, таких как Windows NT, снова привлекли внимание к этой технологии. С перемещением деятельности большинства организаций в сетевой мир, который не спит никогда, требования к постоянной работе серверов обычны. Впервые IBM предоставила самым крупным заказчикам AS/400 кластерную технологию OptiConnect в середине 1994 года. В главе 3 мы говорили, что сфера применения этого оптоволоконного продукта значительно расширилась за последние несколько лет. Например, поддержка параллельных слабо связанных баз данных позволила эксплуатировать такие приложения, как хранилища данных и сильно загруженные среды OLTP на очень больших системах. Сегодня в мире работает немало огромных конфигураций AS/400 с OptiConnect. Существует пример использования технологии OptiConnect для кластера AS/400, к которому подключено более 20 000 терминалов. Этот кластер обрабатывает почти миллион транзакций в час. Вот какими большими стали сейчас системы! Как мы уже отмечали, кластеры OptiConnect служат не только для увеличения размеров системы, но и для поддержания постоянной готовности. Наши бизнес-партнеры легко добиваются высоких коэффициентов готовности системы, устанавливая на кластере AS/400 свои пакеты зеркалирования (репликации). Эти пакеты реплицируют данные и транзакции DB2/400 на несколько AS/400. AS/400 могут быть связаны с помощью OptiConnect или любой другой линии. В случае аппаратного или программного сбоя одной системы кластера, обработка автоматически переключается на другую. Такой механизм автоматического переключения позволяет предотвратить общее снижение производительности и уменьшить время, когда доступ пользователя к системе невозможен. Подобные системы также обеспечивают круглосуточную работу на производстве, так как резервное копирование может выполняться с зеркального компьютера в кластере. Недостаток кластера AS/400 — им нельзя управлять как единой системой, в то время как кластеры других производителей предоставляют программисту и системному администратору такую возможность. Задача AS/400е — обеспечить для кластера иллюзию единой системы, что даст пользователю возможность управлять всем кластером из одной точки. Это и некоторые другие расширения поддержки кластеров будут вводиться в версию 4 постепенно. В дополнение к новым кластерным расширениям в версии 4 будут улучшены параметры готовности одиночной системы, а именно: значительно сократится время IPL и повысится производительность операций создания — восстановления резервных копий. В главе 6 мы отмечали, что один из новых способов соединения компьютеров в кластер — OptiConnect — реализован как последовательная оптическая шина SPD. В будущем потребуется более быстрое и более безотказное соединение. Мы считаем, что этим требованиям вполне удовлетворяет соединение SAN. Компьютеры в кластере, использующем SAN, будут объединены в отказоустойчивую кольцевую конфигурацию. Два порта SAN непосредственно свяжут каждую систему со следующей системой кольца. Безотказную связь между системами обеспечит резервное соединение, которое будет работать при отказе основного. Протокол SAN аппаратно поддерживает обнаружение ошибок, повторную пересылку пакетов и переключение на альтернативное соединение. Средством соединения в петле SAN может быть либо медный провод, либо оптоволокно, в зависимости от расстояния между компьютерами. Оптоволокно оптимально на больших расстояниях. Очень большие скорости соединения SAN могут быть достигнуты, когда вместо последовательных оптических соединений станут использоваться параллельные. Разработчики Рочестера уже продемонстрировали параллельное оптико-волоконное соединение с 32 волокнами, работающее на частоте 500 МГц. Даже когда половина волокон используется для дублирования, производительность этого соединения равна 1 ГБ в секунду, что в 8 раз быстрее, чем производительность в 1 гигабит самой быстрой реализации OptiConnect. Конечно, так как SAN имеется только на самых новых системах и серверах AS/400е, OptiConnect еще несколько лет будет оставаться единственным средством объединения систем в кластер. Можно с достаточной степенью вероятности предсказать этапы расширений поддержки кластеров с высокими параметрами готовности. Сначала будет улучшена система удаленного журналирования и репликации объектов между системами для устранения всех единичных точек сбоя. Это повысит производительность и функциональные возможности пакетов зеркалирования и репликации наших бизнес-партнеров. Следующим логическим шагом будет поддержка переключения дисков между системами. Тогда при сбое основной системы диски, содержащие базу данных, можно будет переключить на резервный компьютер. Это позволит избежать затрат на дублирование базы данных, но также исключит и возможность выполнения резервного копирования с вторичной системы. По этой причине некоторые заказчики могут предпочесть прежнее зеркалирование систем. Третьим шагом будет обеспечение разделения базы данных между системами. В настоящее время IBM использует такую модель в System/390 Parallel Sysplex. Механизм, поддерживающий как переключение, так и разделение дисков — независимые пулы вспомогательной памяти ASP (IASP), описанные в главе 8. ASP представляет собой набор дисковых устройств, в котором вся память пула выглядит одной непрерывной областью. ASP содержат различные системные объекты и применяются для оптимизации восстановления при сбоях дисков, изолируя эти сбои. Существуют один системный и до 15 пользовательских ASP. IASP — специальная форма пользовательского ASP. Каждый IASP автономен, то есть, например, при выполнении загрузки системы IASP можно не подключать. Кроме того, IASP можно отключать, не останавливая всю систему. Задача в системе получает исключение, если пытается обратиться к объекту, находящемуся в отключенном IASP. IASP может быть подключен к одной или нескольким системам. IASP, подключенный к нескольким системам, рассматривается как ресурс кластера и может переключаться или разделяться между компьютерами кластера. Идея создания IASP появилась в результате одной работы, проведенной возглавляемым мною отделом вскоре после объявления о выходе AS/400. Именно тогда Джим Рэнуайлер (Jim Ranweiler) исследовал способы создания кластеров AS/400 высокой готовности и пришел к концепции IASP. Мы положили эту работу на полку, пока она нам не понадобилась. Теперь, когда в наших планах — создание кластеров постоянной готовности, мы можем стряхнуть с этой работы пыль и использовать ее в AS/400.Улучшения соотношения цена-производительность в серии AS/400е
Последняя тема этой главы — разработки аппаратных средств, предпринимаемые нами для дальнейшего улучшения соотношения цена — производительность (Ц — П) моделей серии AS/400е. За последние несколько лет наши клиенты стали свидетелями существенных улучшений в этой области. В е-серии это соотношение улучшилось примерно на 60 процентов по всем моделям, а для некоторых серверов — даже значительнее. В прошлом производительность и емкость системы улучшали без снижения цен, но чем дальше, тем больше соотношение Ц—П выходило на первый план. Сейчас цены быстро падают. Я помню покупку своего первого ПК в 1982 году. В IBM была программа поддержки сотрудников, приобретавших в личное пользование первые IBM PC. В моей машине было 64К памяти и два 5-дюймовых дисковода (на тех первых ПК не было жестких дисков). Вместе с монохромным монитором и матричным принтером все это стоило мне 4 500 долларов. Сегодня за те же деньги я могу купить один из самых больших и мощных ПК. Я знаю это не понаслышке — я так и сделал. Но, конечно, я мог бы купить гораздо менее дорогой ПК, причем вполне приемлемой емкости и производительности. Подобная ситуация достаточно типична и вполне иллюстрирует проблему, с которой сегодня столкнулись производители компьютеров. Несколько лет назад, большинство из нас постоянно добавляли все новые и новые приложения, что требовало адекватного увеличения объемов и производительности систем. Иными словами, пользователи тратили примерно одну и ту же сумму всякий раз, когда модернизировали свой компьютер. Времена изменились. Увеличение емкости и производительности большинства систем превзошли потребности большинства пользователей. В результате, заказчики теперь меньше тратят на модернизацию своих компьютеров меньше, независимо от того, покупают ли ПК, AS/400 или мэйнфреймы. Сегодня задача всех производителей компьютеров — поиск путей дальнейшего снижения себестоимости систем, сокращение цен на свою продукцию. В этом разделе мы рассмотрим два подхода, используемые для гармонизации Ц—П AS/400: универсальность и новые технологии ввода-вывода.Универсальность
Для современных серверов стандарты Ц—П устанавливает индустрия ПК. Серверы на процессорах Intel с Windows NT задали планку, которой приходится соответствовать всем остальным. Пока Ц—П серверов AS/400 весьма конкурентоспособна. Однако планка не фиксирована, она продолжает снижаться. Преимущество серверов ПК состоит в универсальной аппаратуре, используемой многими производителями. Для поддержания конкурентоспособности AS/400е также переходит на универсальную аппаратуру. Наиболее очевидный знак этого перехода — помещение компьютеров е-серии в новые корпуса, такие же, как используются для RS/6000. Большая часть компонентов внутри корпусов также одинакова для обеих систем. Использование универсальных компонентов означает меньшую стоимость учета, складирования и даже самих компонентов из-за роста объемов производства. Такая универсальнность дала IBM возможность сократить производственных расходы, сконцентрировав все производство для AS/400 и RS/6000 в Рочестере и Санта-Паломбе (Santa Palomba), Италия. Если заглянуть внутрь новых корпусов, мы увидим вновь разработанный CEC (Central Electronics Complex)[ 84 ]. CEC состоит из основных процессоров, основной памяти, источника питания и шин ввода-вывода. Ранее при переходе на выпуск новых и более быстрых моделей IBM эти компоненты обычно заменялись. Благодаря более эффективному СЕС теперь заказчик можете обойтись просто вставкой новых плат. Вновь разработанные корпуса предназначены для использования на все время существования версии 4, что должно сократить стоимость модернизации большинства моделей е-серии. Но есть и модели, изначально не подлежащие модернизации, разработанные так специально для сокращения цены. Такой же подход используется на рынке ПК. IBM привержена универсальной аппаратуре на всех своих платформах, что сокращает расходы на разработку и производство компонентов, общих для нескольких систем. Неполный список универсального оборудования включает процессоры, контроллеры памяти, системные шины, адаптеры ввода-вывода, источники питания и корпуса. Общие компоненты встречаются и в серии AS/400е: процессоры PowerPC, системные шины 6хх, адаптеры PCI и соединения SAN. Результатом всей этой деятельности станет дальнейшее улучшение показателя Ц—П.Новые технологии ввода-вывода
Вероятно, самая перспективная область улучшения Ц—П — ввод-вывод. Переход на PCI и возможность использования в серии AS/400е стандартных адаптеров — большой шаг вперед, но это лишь начало. В настоящее время ведется ряд работ по снижению цены ввода-вывода, но мы рассмотрим только две из них, относящиеся к сокращению цены и повышению производительности дисков. IBM приняла на вооружение новую архитектуру SSA (Serial Storage Architecture), которая уже начала появляться в различных системах корпорации. Стандарт этой архитектуры разработан Американским национальным институтом стандартов ANSI (American National Standards Institute). SSA определяет высокопроизводительное последовательное соединение для подключения устройств ввода-вывода. Данное соединение было оптимизировано для устройств хранения данных, таких как жесткие диски, платы хост-адаптеров, и контроллеры дисковых массивов. Первые дисковые подсистемы SAA были созданы IBM в 1996 году. У SSA много преимуществ перед существующими параллельными интерфейсами, такими как SCSI (Small Computer Systems Interface) по ключевым параметрам: производительности, возможностям подключения, надежности. Кроме того, она использует более компактные кабели и разъемы. Для поддержки миграции и совместного использования SAA сохраняет значительную часть логического протокола SCSI-2. Использование SSA в последующих выпусках версии 4 для е-серии снизит стоимость подключения дисков и повысит производительность. Типичная конфигурация кольца с одним хост-адаптером может обеспечить пропускную способность до 73 МБ в секунду, и в будущем эта скорость повысится. Физическим средством соединения может быть либо медный кабель длиной до 20 метров, либо оптоволокно — для больших расстояний. Последовательная связь выигрывает по сравнению с существующими параллельными интерфейсами. Более дешевые и малоразмерные кабели и разъемы хорошо подходят для маленьких 3,5- и 2,5-дюймовых дисков, причем к одному хост-адаптеру можно подключить больше устройств. Увеличение производительности дает и дуплексное соединение с устройствами. Чтобы повысить надежность, используется не простая проверка четности на шине, а CRC. Наконец, на последовательной линии легче и дешевле осуществлять переключение, что станет особенно важно, когда в AS/ 400 будут реализованы переключаемые и разделяемые диски для кластеров с постоянной готовностью. Со временем преимущества SSA распространятся и на другие устройства. Например, новые контроллеры дисковых массивов, подключаемых к линиям SSA, должны сократить стоимость и повысить производительность, а также обеспечить новые дешевые решения RAID на всех наших системах. Второе направление модернизации, которое я хочу рассмотреть — технологии сжатия. Сжатие данных позволяет эффективнее использовать устройства хранения, такие как диски, а также повышает скорость обмена между дисками и адаптером ввода-вывода. Стоимость дискового хранилища снижается без изменений приложений или методов доступа к данным. Максимальные выгоды достигаются тогда, когда упаковка и распаковка выполняются без потери производительности. Для этого нужна технология обработки данных без значительных накладных расходов, что может произойти при использовании некоторых алгоритмов сжатия. Кроме того, эта технология должна сочетаться с современными скоростными шинами ввода-вывода. IBM разработала быстрые и очень надежные микросхему и алгоритм сжатия данных, специально предназначенные для систем хранения и соответствующие указанным требованиям. Алгоритм сжатия IBMLZ1 был разработан так, что обеспечивает не только очень эффективное сжатие, но и весьма высокую надежность[ 85 ]. Это важно потому, что сжатие убирает из исходных данных избыточность, делающую их весьма уязвимыми для разрушения. IBM достигла высокой надежности технологии сжатия посредством комбинированного использования технологии КМОП для микросхемы и взаимосвязанной схемы проверки упаковки — распаковки, при которой CRC оригинальных данных сравнивается с CRC распакованных данных. Еще раз подчеркну, все это осуществляется микросхемой без потери производительности операций чтения и записи с диска! Использование в дисковых адаптерах микросхемы сжатия повышает емкость дисков AS/400 (алгоритм сжатия IBMLZ1 обычно позволяет достичь трехкратной экономии дискового пространства на старших моделях), а также позволяет снизить нагрузки на шины ввода-вывода. Описанная технология сжатия будет использоваться во всех будущих дисковых адаптерах.Выводы
1997 год ознаменовал появление нового поколения систем AS/400. Переход к сетевым вычислениям направляет многие модификации серии AS/400е. В этой главе я затронул некоторые, но далеко не все расширения, которые можно ожидать в версии 4. В конечном счете, наибольшие выгоды от этого получат наши заказчики, независимо от того, какую модель вычислений предпочитают. Мы живем в «эру WWW», где длина года — три месяца. Изменения происходят так быстро, что теперь наши циклы разработки мы измеряем в «годах WWW». Теперь Вам ясно, почему в версии 4 будет так много выпусков? Тогда не удивляйтесь, что в следующие несколько лет произойдут новые изменения, причем такие, какие сегодня даже трудно предсказать. Таков наш бизнес. Но если все так неопределенно, то можно ли загадывать, что будет после версии 4? Иногда предсказать отдаленное будущее проще, ведь издалека открывается более широкий обзор вероятных возможностей. Некоторые из таких предсказаний я попытаюсь сделать в следующей главе.Глава 12
AS/400 в XXI веке
Предсказывать, какой будет компьютерная промышленность через три-пять лет, это все равно, что пытаться угадать, кто выиграет Кубок мира по теннису, чемпионат Формулы 1 или Super Bowl[ 86 ] в 2001 году. Нельзя сказать, что это невозможно в принципе, чем видимо и объясняется то, что так много людей имеют по этому вопросам свое мнение, которым с удовольствием делятся с окружающими. И все же подобные попытки чаще всего бесплодны. Компьютерные эксперты регулярно выдают прогноз на следующие пять лет, не смущаясь тем, что все их предыдущие предсказания были абсолютно ошибочны. Вот и я, в свою очередь, хочу ознакомить читателей со своими предположениями, какой будет компьютерная индустрия после 2001 года. Мой оптимизм относительно достоверности этих прогнозов основывается на том, что нам уже многое известно о технологиях будущего. Возможно Вы удивлены, что за точку отсчета я взял 2001, а не 2000 год. Отчасти это объясняется тем, что я сторонник точности — ведь на самом деле XXI век начнется только в 2001 году. Но есть и другие причины. Начиная с 1998 года и далее многие производители замедлят переход на новые технологии, особенно требующие значительных усилий, так как 1 января 2000 года — самая страшная дата для компьютерщиков. Сложно предсказать масштаб грозящей опасности, но очевидно, что большинство компаний не захотят тратить силы на новые изобретения в этот промежуток времени, за исключением случаев, когда это будет абсолютно необходимо. Но даже тем компаниям, которые стремятся развивать новые технологии, трудно подобрать для этого персонал с достаточным опытом: так как много людей заняты сейчас проблемой 2000 года. Суть этой проблемы достаточно широко известна. Когда календарный год изменится с 1999 на 2000, многие прикладные и даже системные программы прекратят правильно работать. Для представления года в них заданы только две цифры, так что по их внутреннему календарю наступит не 2000, а 1900 год. А так как ошибка будет массовой, то она может вызвать огромный беспорядок в делах по всему миру. Гиганты компьютерной индустрии уже прилагают огромные усилия, чтобы предотвратить грозящую неразбериху. Производители программ и ОС готовят свои продукты к 2000 году. Например, все системное ПО AS/400 и ПО многих бизнес-партнеров IBM уже сертифицировано на готовность к 2000 году. Но, так или иначе, в 2001 году мы все уже придем в себя и с новым рвением вернемся к поиску новых технологий.Будущие технологии процессоров
Я начну свой прогноз с самого простого: будущего аппаратных технологий процессоров. Аппаратурой управляют законы физики, так что ее развитие можно предсказать с определенной долей уверенности. Единственное затруднение — предвидеть с высокой точностью, какие конкретно технологии и как именно будут применяться в наших вычислительных системах. В главе 2 мы упоминали «закон Мура», в соответствии с которым, число транзисторов на одной микросхеме удваивается примерно через каждые 18 месяцев. Многие эксперты полагают, что действие этого «закона» сохранится, по меньшей мере, еще в течение 15 лет, то есть что компьютерная промышленность еще долго не откажется от технологии КМОП. Это также означает, что число цепей на кремниевой микросхеме будет продолжать удваиваться каждые 18 месяцев благодаря уменьшению размеров транзисторов. Производительность будет расти по мере увеличения количества транзисторов на одной микросхеме. К тому же, чем ближе друг к другу расположены транзисторы, тем быстрее электрические сигналы, передающиеся примерно со скоростью света, будут это расстояние преодолевать. Мы часто воспринимаем прогресс в аппаратных технологиях как нечто само •<=>в собой разумеющееся. За последние 30 лет в производительности, цене и потребляемой мощности аппаратуры компьютеров достигнуты огромные успехи. Но попробуйте представить себе, что такими же семимильными шагами развивалось и автомобилестроение. Тогда Вы смогли бы купить новый «Порше» примерно за 2 доллара; причем эта машина двигалась бы быстрее звука и могла бы пройти более 1000 миль, израсходовав менее 30 грамм бензина, — будь я проклят! В этом разделе я постараюсь спрогнозировать будущее аппаратных средств AS/400 на ближайшие 5-10 лет. Как и все предсказатели, я не даю никаких гарантий, что что-либо из моих предсказаний сбудется, но делать прогнозы занимательно. Итак, получше затяните свой пристяжной ремень; наш новый Порше быстро набирает скорость звука и мы устремляемся вперед в возможное будущее.Процессоры пятого поколения
В течение нескольких следующих лет серия AS/400е будет использовать процессоры PowerPC. Как мы уже говорили, третье и четвертое поколение процессоров, разработанных в Рочестере, будет применяться на протяжении всего времени выпуска версии 4 и далее. Эти же процессоры используются моделями RS/6000. (IBM обсуждала идею конвергенции процессоров между AS/400 и RS/6000 для коммерческих приложений с момента начала работ над PowerPC, но не смогла осуществить ее в первом поколения процессоров AS/400.) Процессоры AS/400 первого и второго поколений поддерживали только режим активных тегов, а все процессоры третьего и четвертого поколения — режимы как активных, так и неактивных тегов. Как мы уже упоминали, на этих процессорах также работают стандартные интерфейсы ввода-вывода, на них возможна установка как OS/400, так и других ОС PowerPC. В главе 2 обсуждался мощный процессор Belatrix для систем высшего уровня, названный так в честь звезды в созвездии Орион. Повторюсь: этот проект, который по первоначальному замыслу должен был завершиться созданием процессора как для научных, так и для коммерческих расчетов, был слишком амбициозен и, потому, ни к чему не привел. В результате, лаборатория в Остине начала разработку своей версии Belatrix для научных расчетов, а Рочестер — своей, под названием Northstar, которая и стала началом семейства процессоров четвертого поколения. Затем эти процессоры были оптимизированы для коммерческих расчетов как для AS/400е, так и для RS/6000. Процессоры четвертого поколения особо примечательны тем, что спроектированы с учетом перехода на более быстрые технологии КМОП. Семейство четвертого поколения насчитывает несколько версий, все они используют общую архитектуру, но реализованы на разных этапах развития микросхем. Можно ожидать, что диапазон производительности этих 64-разрядных процессоров PowerPC составит от 250 до 800 МГц. В подразделении IBM Research также ведется работа для достижения на этом процессоре тактовой частоты более 1 гигагерца (ГГц). Поэтому, если будет принято соответствующее решение, архитектура третьего поколения может использоваться и после версии 4. Теперь поговорим о пятом поколении процессоров AS/400. Здесь возможны разные интересные варианты. Но сначала, давайте разберемся, как обстоят дела с технологией КМОП. Примерно к 2005 году появится возможность размещения до 100 миллионов транзисторов на одном кристалле. Как лучше использовать все это множество цепей — предмет больших дискуссий. Современные микросхемы процессоров содержат от 5 до 8 миллионов цепей. Одно из очевидно возможных применений дополнительных цепей — увеличение внутренних кэшей. Другой вариант — реализация с их помощью функций, для которых сейчас выделяются отдельные микросхемы. Третий — доверить им новые функции, по примеру Intel, включившей в свои процессоры Pentium технологию MMX. Но даже после всего этого часть цепей, возможно, останется незадействованной. Их можно использовать для создания процессоров со сверхширокими трактами данных. 128- и даже 256-разрядные процессоры уже не кажутся чем-то мифическим. 128-разрядный видеопроцессор уже сейчас используется на многих ПК. Конечно, проблема перевода процессоров общего назначения на большие размеры регистров связана с ПО. К 2005 году многие компании лишь только перейдут на 64-разрядное ПО. Вероятно, для перехода на 128 или 256-разрядные процессоры не стоит ждать еще 12 лет. Куда практичней размещать на одной плате несколько процессоров. Например, благодаря прогрессу в области SMP вполне реально представить себе n-процес-сорный узел SMP вместе со всеми кэш-памятями на одной микросхеме. Подобная реализация не потребует изменения ПО, которое уже сейчас поддерживает SMP. По мере увеличения размеров конфигураций SMP и размещения на одном кристалле нескольких процессоров, не за горами и такая фантастическая картина: миллиард транзисторов на одном кристалле. Это может произойти примерно после 2010 года. Фактически, мы уже идем по этому пути. У каждого процессора четвертого поколения — два полных набора регистров на одном кристалле. Аппаратура процессора может попеременно использовать их то для одного, то для другого потока управления в программе. (Процесс может иметь одну или несколько единиц исполнения, называемых потоками, — об этом рассказано в главе 9). Когда говорят о параллелизме внутри процесса, обычно подразумевают, что несколько потоков выполняются одновременно на нескольких процессорах. Однако выполнение нескольких потоков возможно и на единственном процессоре с несколькими наборами регистров, которые аппаратура использует попеременно. Такой процессор называется многопоточным (multithreaded). В главе 2 мы говорили, что современные процессоры обречены на простои во много циклов из-за промахов кэшей и длительного обмена с памятью. Чтобы предотвратить потери, многопоточный процессор может использовать такие циклы для исполнения команд из другого потока, что повышает загрузку процессора, и, таким образом, производительность. В конце 70-х годов суперкомпьютер на неоднородных элементах HEP (heterogeneous element processor) ныне несуществующей фирмы Denelcor продемонстрировал поддержку процессором до 16 потоков команд. Многопоточные процессоры отлично вписываются в концепцию AS/400. Сегодня даже в самых малых системах AS/400 установлено не менее двух процессоров: основной и IOP. В будущем все IOP перейдут на PowerPC, и тогда многопоточные процессоры появятся на всех AS/400. Например, один набор регистров на микросхеме процессора третьего поколения может использоваться для основного процессора, а второй — для IOP, а значит можно будет выпускать дешевые модели, использующие лишь одну микросхему. Весьма вероятен и такой вариант использования многопоточности: с появлением в 1998 году встроенной поддержки потоков каждая процессорная микросхема будет поддерживать несколько потоков процесса. А теперь попробуем заглянуть еще дальше. Придет время, когда на одной микросхеме разместятся нескольких независимых процессоров. В AS/400 это, несомненно, будет кристалл с несколькими процессорами как узел SMP, но есть и другие возможности. Вообразите себе на мгновение, что мы можем динамически назначать процессорам одной микросхемы разные функции. Например, сейчас все процессоры выполняют операции ввода-вывода, а в следующий момент некоторые из них переключаются на вычисления. Возможности таких архитектур сегодня трудно даже оценить.После RISC
Разговоры о технологиях процессоров после RISC вызывают в IBM большие волнения. Стратегия IBM в отношении будущих процессоров серии AS/400е и RS/6000 — PowerPC. Другие компании собираются перейти на новые архитектуры процессоров. Например, новая архитектура Intel IA-64 процессора под кодовым наименованием Merced имеет определенные признаки отхода от философии х86. Впрочем, здесь детали еще не вполне ясны, и только время покажет, что все означает для существующих программ ПК. Некоторые производители могут не пережить драматического роста себестоимости процессоров. Этот рост, как предполагается, наступит в районе 2005 года. Как мы отмечали в главе 2, стоимость предприятия по производству микросхем с размерами транзисторов менее 0,1 микрона достигнет, вероятно, величин порядка 10 миллиардов долларов. В таких условиях вряд ли, скажем, Digital, чей годовой доход примерно равен этой цифре, сможет производить процессоры Alpha. HP уже заявила, что прекратит производство PA-RISC и заменит их процессорами, разработанными совместно с Intel. В прессе довольно часто можно встретить предположения, что HP не станет даже переводить на 64 разряда свою ОС HP-UX, но объединит силы с SCO (Santa Cruz Operations) для создания новой 64-разрядной ОС Unix. Так как современная SCO Unix работает на процессорах Intel, то основания верить в переход HP исключительно на архитектуру IA-64, бесспорно, есть. Будет интересно понаблюдать за попытками владельцев HP 9000 перейти на новые процессоры и новую ОС без остановки повседневной работы. Ни одна конструкция не вечна. Эффект от использования суперскалярной RISC-архитектуры с выполнением команд вне порядка их следования и предсказанием переходов уже стал уменьшаться. Возникает вопрос: что же дальше? Широко обсуждаемая альтернатива RISC — VLIW (Very Long Instruction Word)[ 87 ]. Сначала полагали, что первый процессор, разрабатываемый Intel вместе НР (Merced) будет использовать VLIW-технологию. Теперь оказывается, что в нем, вероятно, использована гораздо более привычная суперскалярная архитектура и лишь задействованы некоторые концепции VLIW. Давайте разберемся, почему VLIW-технология вызывает столь большой интерес. Дело в том, что ее применение может изменить генеральное направление развития современной информатики: от суперскалярных RISC-процессоров — вспять, к повышению сложности схем на кристалле. Ранее, такие процессоры с повышенной сложностью мы назвали Brainiac. Более простые архитектуры, такие как Speed Demons, могут «крутиться» быстрее и достигать больших тактовых частот. VLIW переносит сложность на компиляторы, позволяя создавать более быстрые процессоры. Главный недостаток RISC-процессоров и причина сложности аппаратуры — трудности в поддержании загрузки конвейера. Мы уже говорили, что самые суперскалярные RISC-процессоры способны обрабатывать за один цикл лишь несколько команд (как правило, три—четыре), что ограничивает параллелизм выполнения команд на одном процессоре. Четыре команды: за один цикл означают лишь четырехкратный параллелизм, а из-за зависимостей между командами и переходов средний показатель вряд ли превзойдет двукратный. В реальности для некоторых задач он даже меньше. Почему же суперскалярный RISC-процессор не может диспетчировать 8-16 команд за цикл? Во-первых, мешает ограничение аппаратной технологии: у обычного RISC-процессора для этого просто мало независимых функциональных узлов. Другая причина в том, что в цикле недостаточно времени, чтобы проанализировать 8-16 команд, определить, какие функциональные устройства не заняты, и отправить каждую команду на соответствующий узел; увеличение же времени цикла сократит производительность процессора. Третье ограничение — генерировать для каждого цикла по 8-16 независимых команд не способен компилятор. Развитие аппаратных технологий позволяет создать однокристальный процессор с 8, 16 и даже большим числом функциональных узлов. Технология компиляторов также развилась достаточно, чтобы распознать многократный параллелизм команд и обеспечить работой больше функциональных узлов. Но возможность выбирать на выполнение большее число команд бесполезна, если аппаратура суперскалярного RISC-процессора может выполнять одновременно лишь малое их число. VLIW-технология решает эту проблему, снимая с аппаратуры процессора задачу распределения команд. Вместо того чтобы, как в RISC-процессоре, анализировать каждую инструкцию в потоке команд и затем распределять их по одной в функциональные узлы, компилятор VLIW генерирует отдельную команду для каждого функционального узла на каждом цикле. Например, если функциональных узлов 16, то компилятор генерирует для каждого процессорного цикла 16 команд; но в отличие от RISC-процессора, который анализирует, в какой функциональный узел направлять каждую команду, VLIW-процессор просто посылает первую команду в первый узел, вторую — во второй и т. д. Конечно, если на каком-то цикле у компилятора не оказывается команды для некоторого узла, он по-прежнему должен сгенерировать код «нет операции». Так как VLIW-процессор ни о чем не «размышляет», то его время цикла меньше, чем время цикла суперскалярного RISC-процессора. Меньшее время цикла и увеличенная степень параллелизма исполнения команд, достигаемая посредством загрузки большего числа функциональных узлов, дает VLIW преимущества перед RISC. Вы можете спросить, откуда взялось название «VLIW»2. Компилятор упаковывает независимые команды для каждого цикла в одно очень длинное слово — отсюда и название. На каждом цикле процессор выбирает по одному такому очень длинному слову из своего кэша команд. Таким образом, если каждая из 16 команд занимает 4 байта, то в результате получается 64-байтовое (512-битное) слово команды. Несомненно, название «очень длинное» здесь уместно. Генератор кода компилятора (аналог транслятора AS/400) для VLIW-процессора находит процессору достаточно работы на каждом цикле и генерирует соответствующие команды:. Если на каждом цикле исполняется от 4 до 20 полезных команд, то на одном процессоре можно добиться производительности на уровне миллиарда команд в секунду. Самая большая проблема VLIW в том, что генератор кода компилятора должен быть тесно связан с аппаратурой. Чтобы генерировать команды для каждого функционального узла процессора, компилятор должен иметь точную информацию, сколько узлов на микросхеме, какие они и как связаны друг с другом. В результате, практически невозможно использовать код, сгенерированный таким компилятором на любом модифицированном процессоре, так как у них отсутствует двоичная совместимость (или они имеют разное число функциональных узлов). Ранее предполагалось, что Intel использует в микросхеме Merced трансляцию команд х86 и IA-64 в команды VLIW «на лету», аналогично Pentium II и Pentium Pro, где команды х86 и IA-64 «на лету» транслируются в последовательность RISC-подобных команд непосредственно микросхемой. Intel называет эти RISC-подобные команды микрооперациями и описывает данный прием как динамическое исполнение. Затем ядро процессора исполняет эти микрооперации конвейерным устройством, которое выглядит точно так же, как и любой RISC-процессор. Intel не первая применила такой механизм. Точно так же работал процессор Nx586 другого производителя микросхем х86 — NexGen, теперь приобретенной AMD (Advanced Micro Devices). NexGen называла этот подход внутренними командами RISC86. Теперь он использован в другой совместимой с х86 микросхеме AMD — К6. Все эти продукты продемонстрировали, что динамическое исполнение удачно для RISC-процессора. В то же время оно может не очень хорошо сказываться на объеме параллелизма в потоке команд VLIW-процессора. Далее RISC-процессор анализирует следующие 3 — 6 команд и направляет их в максимально возможное в данный момент количество узлов процессора.RISC-компиляторы отвечают за помещение в поток команд независимых друг от друга инструкций, чтобы за один цикл можно было отправить на выполнение их максимальное количество. Генератор кода компилятора обрабатывает промежуточное представление и генерирует двоичные машинные команды. Обычно для предоставления процессору достаточного числа независимых команд требуется анализ команд некоторого участка промежуточного представления. В VLIW-машине число функциональных устройств сильно возрастает, что нужно для достижения большего параллелизма. В ближайшее время можно вполне ожидать появления процессоров, имеющих от 16 до 32 (а в будущем и более) функциональных узлов. Для обеспечения загрузки командами компьютеров такого типа генератору кода компилятора потребуется проанализировать гораздо больший диапазон промежуточного представления. Для генерации команд каждого цикла компилятору придется просмотреть, возможно, сотни и даже тысячи промежуточных команд. При использовании динамического подхода «на лету», для генерации команды VLIW просматривается лишь несколько команд. Способность эффективной загрузки большого числа функциональных узлов в этом случае остается под большим вопросом. В соответствии с последней информацией от Intel, подход, который будет использован в Merced, будет больше походить на RISC-подобный подход Pentium Pro. В новом процессоре могут быть использованы некоторые базовые концепции VLIW, включая параллельное диспетчирование большого числа команд. Один из руководителей Intel сказал, что они взяли разработки VLIW от HP и разработки CISC/RISC от Intel и собираются создать на их основе нечто новое. Он сказал, что это новый тип архитектуры, который идет дальше не только RISC, но и VLIW. Мы в Рочестере наблюдаем за происходящим с большим интересом.VLIW в Рочестере
Рочестер заинтересовался архитектурой с очень длинным словом команд в начале 80-х. В то время здесь было организовано специальное подразделение исследования новых технологий для наших будущих системах. В этом подразделении я руководил группой систем. Задача группы состояла не в том, чтобы создать продукт, который будет поставляться заказчикам, но разобраться, заслуживают ли некоторые идеи внимания, и может ли на их основе быть создана аппаратура. Разумеется, лучший способ продемонстрировать положительный ответ — работоспособный прототип. Наша группа сосредоточила свое внимание на высокопроизводительных вычислениях и параллельной обработке, в основном, применительно к System/38. Мы были убеждены, что когда-нибудь создадим модели System/38 очень высокой производительности, и хотели быть готовы к этому. Исследование процессоров возглавлял Рой Хоффман. Его идея состояла в следующем: добавить к System/38 процессоры, специально предназначенные для приложений, с которыми эта система справлялась не очень хорошо. Одним из сопроцессоров, которые мы присоединили к System/38, был высокопроизводительный процессор операций с плавающей точкой. После этого мы решили пойти дальше и построить System/38 с производительностью суперкомпьютера. В наши намерения входило добиться на своем прототипе большей производительности приложений, интенсивно использующих плавающую точку, чем на System/ 390 с ее векторными возможностями. Достичь поставленной цели мы собирались с помощью сопроцессора фирмы FPS (Floating Point Systems). В 1975 году FPS выпустила АР-120В — первенец семейства матричных процессоров FPS, использовавшийся, в основном, для обработки сигналов. Матричные процессоры работают с упорядоченными наборами данных, обычно, векторами или матрицами. В 1980 году FPS выпустила FPS-164 на основе архитектуры АР, предназначенный для сложных научных расчетов. FPS-164 был полностью 64-разрядным процессором. Он мог с успехом соревноваться с любыми суперкомпьютерами того времени, включая Cray. Процессор FPS не был автономным, а подключался к управляющей вычислительной системе. Мы купили его и подключили к System/38, а параллельно стали разыскивать коммерческие приложения, которым требовались высокопроизводительные вычисления с плавающей точкой. Мы хотели показать, что вычисления такого типа применимы не только к научным расчетам. Наиболее обещающими были приложения для банков и работы с ценными бумагами. ^чЧУЦ//>, Физически FPS-164 был гораздо больше System/38. У него были также свои «капризы», которыми не страдала наша система, например требования к охлаждению воздуха. Мы оборудовали ему специальную комнату с фальшполом и самым большим кондиционером, который когда-либо устанавливали наши техники. Вентиляторы FPS засасывали холодный воздух из-под фальшпола с таким шумом, будто в комнате находилось судно на воздушной подушке. Когда мы его выключали, в комнате становилось так холодно, и никто из персонала не мог там долго находиться. Однако, как вычислительная машина FPS-164 работал по-настоящему быстро. У FPS были планы — создать с помощью новых технологий такие версии FPS-164, которые работали бы вместе с System/38 в нормальных условиях офиса. Но именно тогда проект Fort Knox был прекращен, и мы сосредоточили все свои силы на Silverlake. Увы, проект использования с System/38 новых сопроцессоров нам не довелось довести до конца. Однако он кое-чему научил нас, и этот опыт пригодился при работе над сопроцессорами для AS/400. Системы FPS были одними из первых с длинным словом команды, содержавшим по несколько операций на команду. В машине имелось 10 функциональных узлов, и каждому из них требовалась на каждом цикле собственная подкоманда. В длинном слове команды были отдельные подкоманды для каждого узла. Одна команда могла полностью обработать вектор. Вместо оптимизирующего компилятора для создания длинных слов команд применялись библиотеки языка ассемблера. Основной компьютер обрабатывал логику программы и вызывал процедуры с длинными командами для исполнения на машине FPS. Данный тип программирования схож с микрокодом с длинным словом типа HMC, использовавшегося в System/38. Хотя в командах НМС было не так много битов, как длинном слове команды FPS, но каждая команда НМС запускала несколько функций процессора System/38. Одно время мы рассматривали возможности использовать в НМС некоторые приемы для распределения команд по функциональным узлам. Примерно в то же самое время, группа исследователей Йельского университета (Yale University) предложила создать машину с очень длинной командой (512 бита), которую они назвали VLIW. Коммерческий проект попыталась осуществить фирма Multiflow Computers, но, в конечном счете, потерпела неудачу из-за недостатка финансирования. В 1993 HP лицензировала у более не существующей компании пакет ее патентов. Интерес к машинам VLIW в Рочестере сохранялся и в конце 80-х годов, главным образом, благодаря связи этой технологии и НМС. После объявления IBM AS/400 мы начали работу над процессором для систем следующего поколения. Технология VLIW стала частью новой архитектуры. Одним из руководителей проекта VLIW был Дэйв Льюк (Dave Luick). Дэйв начинал с нашего первого процессора, возглавлял разработку процессора System/38 Model 7 и с тех пор участвовал в проектировании всех наших процессоров. Он из тех, кто всегда стремится выйти за пределы традиционной технологии, и очень заинтересовался применением к НМС некоторых технологий VLIW. Процессор C-RISC, обсуждавшийся в главе 2, был разработан как процессор для Advanced Series перед тем, как мы перешли на технологию PowerPC. Так вот, благодаря Дэйву и некоторым его соратникам, C-RISC имел НМС с рядом характеристик машины VLIW. В 1991 году Дэйв в составе группы из 10 человек занимался оценкой возможности использования процессоров PowerPC для AS/400. После принятия решения о переходе на технологию PowerPC, он и его единомышленники направили свои усилия на создание PowerPC-совместимой машины VLIW. Так как VLIW очень зависит от технологии компиляторов, немедленно начались совместные исследования с IBM Research. Специалисты этой лаборатории, работавшие над VLIW, не могли найти для этой технологии такую платформу, чтобы новшества не оказали негативного влияния на бизнес заказчиков. Технологическая независимость AS/400 снимала этот вопрос. Мы могли внедрить VLIW в AS/400 безболезненно для пользователей. Работа над VLIW в Рочестере показала огромный потенциал данной технологии для повышения производительности AS/400. Во-первых, благодаря упрощенной архитектуре, больше похожей на Speed Demon; можно сократить время такта процессора и создать по той же технологии микросхему, которая по скорости будет вдвое превосходить стандартный PowerPC. Во-вторых, в течение нескольких следующих лет достижим намного больший параллелизм (16 или даже более конвейеров) на одной микросхеме, чем в суперскалярных RISC; где всего лишь пять или шесть конвейеров. В настоящее время работа над VLIW в Рочестере по ряду причин приостановлена. Дело, прежде всего, в том, что мы договорились использовать универсальную технологию процессора как для серии AS/400е, так и для продуктов линии RS/6000. Хотя благодаря независимости от технологии в AS/400 можно внедрить столь радикально новую технологию как VLIW, на RS/6000 это невозможно. Зато обе системы могут использовать RISC-процессоры PowerPC. Некоторое время мы рассматривали возможность создания процессора PowerPC с ядром VLIW. Такой процессор мог бы использоваться как AS/400, так и RS/6000. Новый транслятор для AS/400 генерировал бы код либо для интерфейса процессора PowerPC, либо обходил его и генерировал код непосредственно для ядра VLIW. Компоненты SLIC работали бы через интерфейс PowerPC, а со временем мы переписали бы их для исполнения непосредственно ядром VLIW. Прикладные программы с шаблоном внутри программного объекта, могли бы автоматически конвертироваться для VLIW, а программы без шаблона продолжали бы работать как программы PowerPC. Из-за споров вокруг эффективности трансляции команд в операции ядра VLIW мы приостановили работы над процессором PowerPC с таким ядром. Придется подождать и посмотреть, сколь успешно технология VLIW будет использована в Intel Merced. Некоторые из наших разработчиков даже предлагали подумать над возможностью перехода AS/400 на этот новый 64-разрядный процессор Intel. На мой взгляд, это было бы забавно. Вторая причина приостановок работ по VLIW — то, что производительность одиночного процессора в сегодняшних системах не является слабым местом. На наш взгляд, гораздо больше выгод принесет усовершенствование подсистем памяти, и первые реализации новых подсистем уже это подтвердили. До сих пор мы говорили только об отдельных процессорах и возможностях их применения в серии ASA^X^. Следующий раздел посвящен перспективам развития многопроцессорных систем.Будущее многопроцессорных систем
На любой конференции по компьютерным архитектурам, независимо от заявленной темы, разговор обязательно заходит о масштабируемых многопроцессорных системах с общей памятью. Я твердо верю, что многопроцессорные системы данного типа обеспечат в будущем прогресс вычислительных систем. Внимание к архитектурам МРР без разделения памяти гораздо меньше — ведь они более специализированы и набор типов приложений для них ограничен. А, кроме того, заниматься масштабируемыми архитектурами с общей памятью нам просто интересно!Масштабируемые многопроцессорные системы с общей памятью

Системы с централизованной и распределенной общей памятью мы рассматривали в главе 2. В первой из них имеется центральная память, которую совместно используют несколько процессоров, и именно такую модель имеют в виду, когда говорят об SMP. Так как в такой системе время, требуемое каждому процессору для доступа к центральной памяти, одинаково, то их обычно называют системами с однородным доступом к памяти или системами UMA. Во втором случае память распределена между несколькими узлами, каждый из которых содержит небольшое число процессоров, подключенных к памяти узла по схеме SMP. В узле есть процессоры и память, но нет дисков и других устройств ввода-вывода. Адресное пространство всех узлов общее, то есть любой процессор может адресовать память любого узла. Чтобы проще представить это себе, вообразите фрагменты общей памяти расположенные в узлах системы и связанные между собой вы сокоскоростным глобальным соединением. У каждого узла общая шина памяти, соединенная с его фрагментом общей памяти, но доступ к этому фрагменту возможен и для процессоров всех остальных узлов с помощью глобального соединения. Отличие состоит только во времени доступа. Локальный доступ выполняется быстрее глобального, и поэтому подобный кластер узлов SMP называется машиной с неоднородным доступом к памяти, или машиной NUMA. Мы уже достаточно подробно рассмотрели модель централизованной общей памяти в AS/400. Описанная в главе 2 подсистема памяти UMA с перекрестными переключателями и ее разновидности могут с легкостью поддерживать 16-канальные конфигурации SMP с высокопроизводительными процессорами, планируемыми для серии AS/400е. После версии 4, возможно, появятся 20- или даже 24-канальные конфигурации SMP. Для очень больших конфигураций будут использованы кластеры узлов SMP. В главе 11 мы рассмотрели последовательность кластерной поддержки для AS/400: и системы без разделения, каждая из которых использует собственные дисковые устройства; и кластеры с переключением дисков между системами; и, наконец, системы с разделением дисков между компьютерами кластера. Получив с помощью независимых ASP возможность разделения всех дисков кластерного пула, мы можем подумать о разделении памяти между узлами, и, таким образом, о создании нашей первой машины NUMA. Интерес к применению NUMA в AS/400 возник несколько лет назад. Дик Бут (Dick Booth), рочестерский инженер, занимался в начале 90-х годов многопроцессорными системами в IBM Research. В процессе работы у него возникла идея новой архитектуры. Первоначально Дик назвал ее «крепко связанным мультипроцессором», так как она занимает промежуточное положение между слабо связанными (МРР) и сильно связанными (SMP) мультипроцессорами. Теперь подобная структура называется просто NUMA. Дик верил, что NUMA будет работать в AS/400. Вернувшись в Рочестер, он заразил своей идеей коллег. В 1991 году был основан объединенный проект с IBM Research и началась работа над прототипом. Как это часто бывает, новая идея натолкнулась на определенный скептицизм. Группа выстояла, завершила прототип и продемонстрировала его, чем завербовала в свои ряды новых сторонников. Сегодня эти люди успешно работают над NUMA для будущих AS/400.
CC-NUMA и COMA

Для AS/400 возможны как минимум две реализации NUMA. Первая — неоднородный доступ к памяти с когерентным кэшем CC-NUMA (cache-coherent non-uniform memory access), вторая — архитектура памяти только с кэшем COMA (cache-only memory architecture). Конкретные детали реализации и оценки производительности этих архитектур широко отражены в компьютерной прессе. С начала 90-х годов разновидности этих архитектур исследуются в нескольких университетах и лабораториях. Некоторые компьютерные компании, такие как SGI (Silicon Graphics, Inc.), Sequent и Convex уже поставляют на рынок серверы CC-NUMA с большими возможностями масштабирования. Итак, давайте кратко, не слишком вдаваясь в технические подробности, поговорим о том, какие детали этих архитектур Вы можете ожидать в будущих конфигурациях AS/400. Обе схемы используют протокол когерентности кэшей на основе справочников, что необходимо для поддержки «вроде бы» общей памяти, хотя основная память и распределена между узлами. Проще говоря, в каждом узле имеется справочник, показывающий расположение всех страниц в глобальной адресуемой основной памяти (как локальной, так и удаленной). Это отличается от шинной когерентности со слежением (snoopy bus-based coherence), используемой для кэшей второго уровня в узле SMP, описанной в главе 2. Одни и те же данные из страницы общей памяти могут одновременно находиться в нескольких кэшах процессоров узла SMP. При изменении данных в кэше одним процессором должны быть обновлены и копии в кэшах других процессоров. Под когерентностью кэшей понимают актуальность всех копий. При использовании протокола слежения справочник кэша каждого процессора содержит информацию только о тех страницах, которые находятся в его собственном кэше. При всяком изменении процессором данных в кэше об этом сообщается по шине слежения всем остальным процессорным кэшам, с целью обновить те же данные. Таким образом, каждый кэш следит за изменениями во всех других кэшах и обеспечивается когерентность кэшей. Поддержание в кэшах процессоров множественных копий гарантирует одинаковое время доступа ко всем данным (поэтому данная архитектура и называется UMA). Но необходимость широковещательного оповещения об изменениях начинает мешать, если число кэшей растет. Протокол когерентности кэшей на основе справочников устраняет необходимость широковещательных оповещений об изменениях, так как справочники содержат информацию только о том, в каком узле находятся данные, но не о самих данных. Каждый узел отслеживает только свои собственные локальные данные, совместно используемые данные не дублируются. Обращение к данным локального узла выполняется быстрее, чем к данным удаленного узла. Вспомните, что узлы имеют общее адресное пространство, а не память. Каждому узлу кластера выделяется часть общего адресного пространства. Расширение адресного пространства и обновление справочников позволяет добавлять в кластер новые узлы. Каталоги, о которых мы говорим, содержат только информацию о данных в памяти различных узлов, данные на диске вне этой структуры. Проще говоря, аппаратура следит за тем, что происходит в памяти, тогда как ОС — за тем, что находится на дисках. Ранние реализации NUMA с когерентностью кэшей на основе справочников имели большую разницу во времени обработки промахов удаленных и локальных кэшей. Когда процессор в узле определяет промах кэша L2, время получения данных из памяти удаленного узла может быть значительно больше времени получения данных из памяти узла, в котором находится процессор. Например, на ранней машине Sequent промахи удаленных кэшей обрабатывались в 10 раз медленнее локальных. Чтобы добиться от такой архитектуры достаточной производительности, требуется поддерживать приемлемо низкое число удаленных обращений путем тщательного распределения данных приложений по узлам. Обычно число таких обращений пытаются свести к 10 процентам. Таким образом, переход от архитектуры SMP к распределенному кластеру может потребовать изменений в прикладных программах и перераспределению данных приложений. В последних системах NUMA преодолена проблема множества удаленных обращений, присущих ранним системам, так что необходимость в изменении приложений и перераспределении данных отпала. CC-NUMA и COMA используют для этого некоторое дополнительное оборудование. На каждом узле расположено по одному или несколько процессоров, а также собственные кэши, подключенные через подсистемы памяти к локальной памяти узла (это в точности соответствует описанной ранее конфигурации SMP). Теперь представьте себе, что к подсистеме памяти и к сети межузловых соединений подключено отдельно устройство удаленного доступа RAD (remote access device). Применительно к AS/400 я называю эту дополнительную аппаратуру RAD, однако, общепринятого названия не существует. Для некоторых систем ее именуют контроллером когерентности, для других — хабом. Независимо от названия, ее назначение — реализация протокола когерентности кэшей на основе справочника между подсистемой памяти узла и сетью межузловых соединений. Подключения RAD для AS/400 будут очень похожи на подсистемы ввода-вывода, представленные на рисунке 10.1, но при этом с одной стороны к RAD присоединены шины 6хх, а с другой — порты SAN. В машине CC-NUMA RAD содержит отдельный кэш, в котором находятся только удаленные данные. При адресации процессором данных, которых нет в его собственном кэше, запрошенные данные считываются из памяти узла (если адрес локальный), или из кэша RAD (если адрес удаленный). Обращения к удаленным данным, которые не могут быть обслужены кэшем RAD, должны быть посланы по межузловой сети к «домашнему» узлу соответствующей страницы памяти, чтобы получить нужный блок данных из памяти удаленного узла, а также для поддержания когерентности. Кэш RAD повышает производительность машины архитектуры CC-NUMA, сокращая число удаленных промахов кэша, которые должны обрабатываться удаленным узлом. Очевидно, что первое обращение к удаленной странице памяти будет связано с большим временем ожидания выборки данных из памяти удаленного узла и помещения их в кэш RAD. Последующие обращения к той же странице любым процессором узла будут отрабатываться быстрее, так как не надо пересылать данные по межузловой сети. В результате, соотношение времени обработки промахов удаленных и локальных кэшей сокращено в современных системах от 2:1 до 3:1. Расходы на удаленные обращения достаточно невелики, так что большинство приложений при переносе их с SMP на кластер не требуют изменений. В связи с этим, CC-NUMA часто называют системами масштабируемого SMP. Пример системы CC-NUMA — SGI/Cray Origin 2000. Origin 2000 может содержать до 64 узлов, соединенных масштабируемой сетью CrayLink. В каждом узле один или два процессора, до 4 ГБ памяти и соединения с подсистемой ввода-вывода. Максимальная конфигурация — 128 процессоров с общим объемом памяти в 256 ГБ. Пока в Origin 2000 устанавливаются процессоры MIPS R10000, работающие на частоте 195 МГц и имеющие кэши второго уровня объемом 4МБ. Два процессора в одном узле работают не так, как в конфигурации SMP, из-за того, что между кэшами L2 нет протокола слежения. Вместо этого, они действуют как два отдельных процессора, использующие общие линии связи с памятью узла и вводом-выводом. Процессоры узла соединены с микросхемой хаба, которая, в свою очередь, подключена к памяти узла, подсистеме ввода-вывода и межузловой сети CrayLink. Микросхема хаба передает локальные обращения непосредственно памяти узла. Отдельная память в хабе предназначена для кэширования удаленных данных. Если запрос на удаленные данные не может быть удовлетворен памятью хаба, то выполняется обращение по межузловой сети к удаленному узлу. Интересно также то, что для быстрого переключения потоков информации внутри хаба есть перекрестный переключатель. Кроме всего прочего, Cray Origin 2000 (конфигурации, насчитывающие более 64 процессоров, обозначены как системы Cray; меньшие модели — как SGI) — основа проекта ASCI Blue Mountain, о котором мы говорили в главе 2. Возможно, Вы помните, что этот проект состоит из двух частей. Работы ведутся поэтапно в Национальной лаборатории Лос-Аламоса, с задачей получить в конце 1998 года конфигурацию с 3072 процессорами, которая сможет достичь 4 терафлоп. Параллельно в Ливерморской национальной лаборатории будет развернута система IBM ASCI Blue Pacific, которая должна достичь аналогичного уровня производительности с помощью 512 8-каналь-ных узлов SMP. Успех или неудача этих двух систем, несомненно, многое скажут о том, каковы перспективы машин с распределенной общей памятью. Недавно было проведено несколько исследований, направленных на улучшение производительности систем CC-NUMA и дальнейшее сокращение соотношения времени обработки промахов локальных и удаленных кэшей. Выяснилось, что в этом плане много обещает конфигурация СОМА. Эта система использует тот же самый протокол когерентности кэшей на основе справочника, что и CC-NUMA, но в СОМА часть основной памяти узла выделяется для работы в качестве большого кэша удаленных данных. Отдельный кэш удаленных данных в RAD СОМА устранен; вместо этого удаленные данные размещаются в иерархии кэшей процессора и основной памяти узла. Первый проект СОМА в начале 90-х годов, позволял осуществлять перенос данных в основную память узла порциями, равными по размеру блоку кэша (такой подход аналогичен хранению блоков кэша в отдельном удаленном кэше CC-NUMA). Проблема этого подхода в том, что размеры блоков кэша меньше страниц памяти, поэтому для управления вторым размером страниц основной памяти в узле нужна дополнительная аппаратура, по сути, дублирующая описанную в главе 8 аппаратуру виртуальной памяти. Последние реализации СОМА, названные S-COMA (simple-COMA), хранят удаленные данные в основной памяти узла только блоками, равными размеру страницы. Благодаря этому, доступ как к удаленным, так и к локальным данным может осуществляться имеющейся аппаратурой виртуальной памяти. Конечно, в узле SMP по-прежнему нужна аппаратура, поддерживающая протокол когерентности кэша на основе справочников для удаленных данных, вместо протокола слежения для локальных данных. S-СОМА потенциально превосходит по производительности CC-NUMA, так как в состоянии задействовать для хранения удаленных данных большую память узла. Эта архитектура может динамически настраивать размер памяти для удаленных данных в соответствии с потребностями приложения. С другой стороны, S-COMA требует пересылки по сети межузловых соединений блоков данных большего размера в случае удаленного промаха на узле. В течение следующих нескольких лет мы увидим, вытеснит ли СОМА или какой-либо ее вариант используемую ныне архитектуру CC- NUMA.
Будущее ввода-вывода AS/400
Высокопроизводительные процессоры для будущих систем AS/400 ничего не дадут, если им не поставлять достаточно данных для полноценной загруженности. Давайте кратко рассмотрим будущее подсистемы ввода-вывода AS/400. Хотя этому вопроса уже уделено большое внимание в предыдущих главах, я постараюсь не повторяться.Будущие технологии подсистем ввода-вывода
В главе 10 мы говорили о том, что архитектура подсистемы ввода-вывода в ходе выпуска версии 4 будет перестраиваться. Вероятно, это будет продолжаться и после 2001 года. В намерения IBM входит создание структуры ввода-вывода, в которую можно будет легко внедрять самые современные технологии. Внедрение шин и адаптеров PCI следует рассматривать как шаг в этом направлении, а не как окончательную цель. Для подключения устройств к AS/400 по-прежнему будут использоваться различные интерфейсы. Большая часть средств подключения ввода-вывода уже обсуждалась в главах 10 и 11, включая SPD, PCI, ATM, Ethernet, SCSI и SSA. При необходимости, мы можем задействовать и другие, например ANSI Fibre Channel. Используемая System Area Network (SAN) допускает применение большинства новых интерфейсов. SAN, которая, как уже говорилось, обычно подключается как кольцо, поддерживает протокол SCIL (Scalable Coherent Interface Link) и обладает большим потенциалом пропускной способности и скорости. В главе 11 я упомянул параллельное соединение SAN с 32 волокнами, работающее на частоте 500 МГц, что обеспечивает пропускную способность 1 ГБ в секунду (при том, что половина волокон используется для избыточных линий). Возможны и более быстрые версии. Так как соединения этого типа основаны на стандарте IEEE и используются в системах и IBM, и других фирм, то в будущем возможны новые подключения. При переходе к сетевым вычислениям соотношение быстродействия и цены высокоскоростных коммуникационных адаптеров также будет улучшаться. Прогнозируется самое широкое распространение новейших коммуникационных технологий, таких как АТМ, оптоволоконные соединения и спутниковая связь, что позволит создавать еще более распределенные приложения. Ожидаемое значительное удешевление высокопроизводительных беспроводных коммуникаций (как локальных, так и на большие расстояния) будет, в свою очередь, способствовать увеличению масштабов мобильных вычислений. В будущем нас также ожидают более объемные подсистемы хранения данных, и SAN позволит их подключать. Скорее всего, на всех системах IBM для этого будет применяться SSA — последовательная архитектура, оптимизированная для хранилищ. Следовательно, можно ожидать появления больших массивов дисков, лент и оптических устройств, совместно используемых многими системами. IOP современных AS/400 будут продолжать развиваться. Все новые IOP используют процессоры PowerPC. Каждый из них имеет собственную память и работает под управлением специализированной ОС реального времени. Процессоры для новых IOP будут либо стандартными представителями семейства 32-разрядных процессоров PowerPC, создаваемых в Барлингтоне, либо (мы уже говорили о такой возможности) — размещаться на той же микросхеме, что и основной процессор. Так как ОС реального времени на сегодняшних IOP, подобно всем другим были за последние несколько лет многократно модифицированы, то на разных IOP одной AS/400 могут выполняться разные версии ОС. Самая современная версия ОС, работающая на IOP PowerPC, основана на микроядре для лучшей переносимости ПО. В будущем мы сможем использовать для IOP стандартную ОС, так как ОС все меньше и меньше управляют устройствами. Уже сегодня, благодаря технологиям PCI, IOP отвечает за интерфейс шины PCI и за выполнение некоторых высокоуровневых функций ввода-вывода ОС.Дисковые массивы
Хотя дисковые устройства работают все быстрее, им все равно не угнаться за технологиями процессоров, ведь повысить скорость работы механических устройств гораздо сложнее. Чтобы не зависеть от прогресса самих устройств, нужно попробовать их в других конфигурациях. Несколько производителей недавно представили технологию чередования блоков данных (data striping) между дисками массива, заявив, что это глобальный прорыв в борьбе за повышение производительности систем. Между тем, впервые подобная технология стала коммерчески доступна еще на System/38. Ранее мы говорили, что приложение System/38 или AS/400 использует несколько системных объектов. В целях повышения производительности IBM решила распределить различные объекты по нескольким дискам, обеспечив параллельный доступ к ним. Таким образом, и System/ 38 и AS/400 использовали чередование блоков данных с момента своего появления на рынке. Технология чередования эффективна, если нужно считывать или записывать несколько объектов. Но увеличить производительность доступа к одиночной записи этот прием не поможет. В этом случае лучше предпочесть разновидность этой технологии, состоящую в синхронном вращении всех дисков массива. При этом головки всех дисков всегда расположены над одной и той дорожкой, и сектор 0 каждого диска проходит под головками всех дисков одновременно. Подобная синхронизация позволяет разбивать одну запись по всем дискам массива, и таким образом повышает производительность пересылок индивидуальных записей. С точки зрения системы такой массив выглядит как один диск с одной головкой, но со скоростью передачи данных в четыре раза большей, чем у любого одиночного диска массива. Это аналогично повышению скорости вращения диска в четыре раза, что не всегда возможно физически. Давайте попробуем представить себе все это более наглядно. Итак, существует массив из четырех синхронно вращающихся дисков. При достаточном числе контроллеров устройств и трактов данных, мы могли бы записывать части одного объекта на все диски параллельно: четверть записи — на первый диск; другую — на второй и т. д. Вся запись в целом производится на четыре диска в четыре раза быстрее, чем та же самая — на один диск. Такая же экономия времени достигается и при считывании записи. Технология синхронизации вращения дисков использовалась на протяжении многих лет суперкомпьютерами для получения большой скорости передачи данных в систему и из нее. Ее единственный недостаток в том, что весь массив с точки зрения системы имеет только одну головку. Многолетний опыт показал, что системы AS/ 400 работают тем быстрее, чем больше дисковых головок, иначе сокращается число возможных параллельных обращений к диску, и, таким образом, общая производительность потенциально снижается. По мере дальнейшего удешевления станет возможным подключать к системе все больше дисковых массивов, и это поможет повысить общую производительность, не дожидаясь прогресса в области механики. В главе 8 мы определили как одно из преимуществ одноуровневой памяти то, что ни прикладное ПО, ни ПО ОС над MI никогда не имеют информации о дисковых устройствах. Одной из причин сокрытия дисков было предположение о скорой замене механической технологии чем-то иным. Полупроводниковые диски (большие полупроводниковые памяти с батареями питания) могут быть одним из вариантов такой замены, но возможны и другие. Теперь давайте перейдем к будущему некоторых программных технологий для AS/400.Будущие программные технологии AS/400
Как уже отмечалось, аппаратные технологии управляются законами физики, так что их будущее достаточно предсказуемо. Зная, какие работы ведутся в разных лабораториях мира, можно с достаточной долей уверенности предположить, когда изучаемые аппаратные технологии будут готовы к промышленному использованию. Однако оценить таким же образом перспективы ПО нельзя. Программными технологиями управляют законы бизнеса, а точнее — огромные капиталовложения в ПО, сделанные в уже существующие средства разработки программ и обучение пользователей. Поэтому каких-то радикальных изменений во всех прикладных программах и средствах разработки в ближайшем будущем ждать нельзя. Возьмем, например, современные работы по объектно-ориентированным базам данных. Компьютерная пресса регулярно сообщает о новых разработках или реализациях объектно-ориентированных баз данных в различных исследовательских центрах. Очевидно, что уже сегодня возможно создание весьма развитых объектно-ориентированных баз данных, но лишь немногие пользователи захотят и смогут отказаться от своих сегодняшних реляционных баз данных в пользу этих новшеств. Поэтому, как уже упоминалось в главе 11, в будущем вероятно размещение в реляционной базе данных объектов, доступ к которым будет осуществляться через объектную систему управления. Мой прогноз таков: хотя в ближайшие 5-10 лет можно ожидать революционных изменений в аппаратных средствах, прогресс в ПО будет гораздо более эволюционным. Пуристы могут сказать, что нужно отвернуться от старой технологии, чтобы понять огромнейшие преимущества новой. Но, увы, пуристы редко управляют бизнесом.Операционные системы
В предисловии я говорил, что большинство новшеств современных ОС — «хорошо забытые старые» работы 60-х годов. Такое положение вряд ли скоро изменится, независимо от пропаганды производителями революционных расширений, планируемых для очередной «новой» ОС. ПО будет развиваться медленно, и в 2001 году мы по-прежнему будем оперировать сегодняшними ОС. Некоторые из них будут расширены, другие исчезнут, но фундаментальная структура используемых ОС останется неизменной. Рост емкости и производительности аппаратуры заставит большинство разработчиков ОС устранять ограничения, присутствующие в сегодняшних реализациях. Переписывание основной части для 64-разрядных процессоров займет разработчиков Unix на следующие несколько лет. Производители 32-разрядных ОС ПК, вероятно, до 2001 года даже не начнут заниматься полной 64-разрядной реализацией, за исключением использования 64-разрядного адреса. Как и все, OS/400 вряд ли претерпит значительные изменения, кроме обусловленных текущими потребностями. Большая часть таких изменений будет связана с поддержкой новых функций и средств, которые мы уже обсудили. В начале 90-х IBM переписала SLIC, предоставляющий базовые функции ОС/400, чтобы воспользоваться предполагаемым ростом емкости и производительности аппаратных средств. Таким образом, у OS/400 есть прочная основа для развития в будущем.Глобальные файловые системы
Я испытываю особый интерес к файловым системам, поддерживающим устройства хранения информации подключенные к сети. Когда мы начнем разделять диски между несколькими системами в сети, скорость доставки данных станет очень важным фактором. Инженеры любят приводить пиковые значения скоростей передачи в мегабайтах в секунду для характеристики аппаратуры как таковой, подразумевая при этом пересылку файлов бесконечного размера и без учета накладных расходов. Но на практике, размеры файлов, обычно, малы, а накладные расходы файловых систем, напротив, значительны. Таким образом, фактические скорости передачи данных обычно значительно меньше тех, которых в принципе может достичь аппаратура. Рассмотрим простой пример двух RISC-систем AS/400, соединенных с помощью OptiConnect через оптоволоконную шину SPD. Оптоволокно способно передавать данные с пиковой скоростью 1 ГБит/с, что равно примерно 100 МБ/с, считая, что несколько разрядов используется для обнаружения ошибок. Измерения показывают, что фактическая скорость передачи данных между такими системами ближе к 32 МБ/с (и это очень высокий результат!), что примерно в три раза меньше пиковой. Причина уменьшения скорости передачи данных — накладные расходы ПО. При каждой передаче данных ПО ОС должно выполнить некоторую последовательность команд. В главе 10 мы рассматривали шину SPD и функции SLIC, необходимые для операции ввода-вывода. В будущем для подобного соединения можно будет использовать SAN, обеспечивающий более высокую скорость при меньших накладных расходах. Для файловой системы с разделением дисков между двумя или несколькими системами, к накладным расходам ПО файловой системы на передачу данных добавляются еще и накладные расходы позиционирования головок диска. Также надо учитывать, что накладные расходы: не зависят от размеров пересылаемого файла, поэтому скорость пересылки небольших файлов значительно ниже, чем больших. Например, NFS (Network File System) Sun Microsystems на типичной высокопроизводительной рабочей станции Unix может пересылать файлы по 10 МБ со скоростью примерно 2 МБ/с, а файлы по 40 МБ — примерно 6 МБ/с. Для повышения скорости пересылки данных на факультете электротехники и информатики Университета Миннесоты (University of Minnesota), где я являюсь адъюнкт-профессором, разрабатывался проект разделяемой файловой системы для хранилища, подключенного напрямую к сети. Эта модель получила название GFS (Global File System). GFS должна была иметь меньшие накладные расходы по сравнению с современными файловыми системами и поддерживать высокие скорости передачи данных даже для файлов малого размера. Впервые GFS была публично продемонстрирована в апреле 1997 года на выставке NAB (National Association of Broadcasters) в Лас-Вегасе (Las Vegas), штат Невада. Телекорпорации и производители кинофильмов, широко использующие компьютерную анимацию и спецэффекты — крупные пользователи сетевых файловых систем, позволяющих передавать данные от высокопроизводительных дисковых массивов на мощные рабочие станции Unix. В связи с этим несколько производителей показали на выставке NAB свои наиболее эффективные системы. Среди прочих демонстрировалась и файловая система GFS, установленная на нескольких очень мощных рабочих станциях Silicon Graphics. Эти рабочие станции были выбраны потому, что ILM (Industrial Light & Magic) использовала аналогичные рабочие станции для продолжения сериала «Jurassic Park» фильмом «The Lost World: Jurassic Park», претендующего на то, чтобы стать «хитом» следующего месяца. В ходе его съемок были применены новейшие достижения компьютерной анимации. Команда компьютерных художников ILM использовала технологию Silicon Graphics для создания пугающе правдоподобных динозавров. Причем этих искусственных созданий было сгенерировано в четыре раза больше, чем в фильме-предшественнике. Рабочие станции были подключены к нескольким дисковым массивам Ciprico Fibre Channel[ 88 ], любимых киноиндустрией за очень большую скорость передачи данных. Новый дисковый массив Ciprico способен обеспечивать скорость 85 МБ/с, а пиковая скорость передаче достигает 100 МБ/с. Демонстрация GFS на стенде Ciprico была первой демонстрацией хранилища непосредственно подключенного к сети на основе Fibre Channel. На выставке NAB GFS пересылала файлы Silic on Graphics на рабочие станции и обратно с изумительной скоростью в 60 МБ/с — в 10 раз быстрее традиционных сетевых файловых систем и примерно в 3 раза быстрее всех остальных, демонстрировавшихся на выставке систем. Не стоит и говорить об огромном интересе, проявленном к ней телевещательными корпорациями и киногигантами. После выставки такой интерес возник еще у ряда компаний, представляющих самые разные отрасли, от медицины до обслуживания Интернета. Мое отношение к GFS носит личный характер. Мой сын, Стивен Солтис (Steven Soltis), спроектировал и разработал GFS в рамках своей докторской диссертации в Университете Миннесоты. К тому же GFS — это только начало. Концепции, разработанные Стивом, без сомнения, найдут применение в других системах для еще более высокопроизводительных файловых систем. Возможно, они даже будут применены в AS/400. А вдруг с помощью AS/400 появится на свет следующее поколение фильмов о звездных войнах?
Мое отношение к GFS носит личный характер. Мой сын, Стивен Солтис (Steven Soltis), спроектировал и разработал GFS в рамках своей докторской диссертации в Университете Миннесоты. К тому же GFS — это только начало. Концепции, разработанные Стивом, без сомнения, найдут применение в других системах для еще более высокопроизводительных файловых систем. Возможно, они даже будут применены в AS/400. А вдруг с помощью AS/400 появится на свет следующее поколение фильмов о звездных войнах?
Интерфейсы пользователя
Особый интерес вызывает будущий интерфейс пользователя вычислительной системы. Вчерашний графический интерфейс пользователя GUI (graphical user interface) быстро уступает дорогу новому сетевому интерфейсу пользователя NUI (network user interface). Несколько производителей, включая IBM, Lotus, Microsoft, Oracle, Netscape и Sun, объявили о создании новых NUI для ПК и СК. Эти интерфейсы по типу браузеров предоставляют пользователю прозрачный доступ к ресурсам как локальных, так и удаленных систем. Задача в том, чтобы средства удаленной системы выглядели для пользователя так же привычно, как и средства локального ПК. Пользовательские интерфейсы никогда так интенсивно не развивались с момента своего появления в середине 80-х. Кажется сейчас любой создатель NUI имеет собственное представление о том, как они должны выглядеть. Многие следуют по пути Windows (панель задач, раскрывающиеся меню и множество окон на экране). Другие склонны ломать эти привычные концепции и упрощать пользовательский интерфейс. Например, Sun представил NUI для JavaStation, в котором пользователю не надо открывать, закрывать, или сохранять приложения. Вместо этого все приложения выглядят выполняющимся постоянно. Один щелчок значка (Sun полагает, что двойные щелчки слишком сложны) позволяет переключаться между приложениями, которые всегда занимают полный экран, чтобы избежать путаницы перекрывающихся окон. Такие NUI предназначены для подавляющего большинства людей в мире, никогда не видевших интерфейса Macintosh или Windows. Netscape, например, предполагает, что ее NUI будет также использоваться в домашних компьютерных видеоиграх и в телевизорах с поддержкой Интернета. Первый NUI, созданный для IBM Network Station гораздо менее радикален. Он разрабатывался так, чтобы сохранить привычный пользователю внешний вид. С помощью отдельных окон на экране можно запускать терминальную эмуляцию для приложений5250/3270, приложения Unix motif, браузер и стандартные приложения Windows. Со временем этот интерфейс может быть расширен для поддержки специфических NUI, требующихся пользователям AS/400. Несколько лет уйдет на то, чтобы отобрать все наилучшие для рабочего стола возможности — идеал, которого, вероятно, не достигнет ни один интерфейс. Будущий рост производительности всех систем позволит применять еще более простые интерфейсы, в том числе воспринимающие голос и рукописный текст. Подобный прогресс значительно увеличит число пользователей компьютеров за счет тех людей, на чьем видеомагнитофоне со дня покупки так и мигает «00:00». Хотя распространение новых интерфейсов будет зависеть от культурных и географических факторов, к 2001 году мы станем свидетелями размывания границ между традиционными видами человеческой деятельности: работой в офисе, дома, или в дороге, ведением личных дел, обучением и отдыхом. Происходит быстрое слияние рынков компьютеров: развлечений, коммуникаций, и потребительского (возможно, дойдет даже до того, что Doom[ 89 ] будет работать «вживую» на AS/400).Технологии приложений
В главе 11 я потратил много места на обсуждение трех моделей приложений, на развитие которых направлены основные инвестиции в версию 4 (сетевые, совместные и клиент-серверные вычисления). Ожидается, что эти направления сохранятся и в дальнейшем. Пока не похоже, что в ближайшем будущем их заменят какие-либо другие, но в то же время, мало кто мог еще несколько лет назад предсказать быстрое распространение, например, сетевых вычислений. Возможно, в ближайшие 5-10 лет появится новая модель приложений, но какой она будет? В любом случае, я не сомневаюсь, что способность AS/400 осваивать новые модели не подведет. Было бы замечательно, если бы любое приложение отлично работало на любой системе, но увы... Многие заказчики AS/400 хотят работать с приложениями, написанным для другой системы, или точнее для другой операционной системы. Интегрированные серверы приложений, описанные в главе 11, почти всегда позволяют им это. Конкретно, на этих серверах могут исполняться приложения, написанные для OS/2, AIX и Windows NT. Если наших заказчиков увлечет какая-либо другая ОС, IBM легко добавит ее поддержку в новые интегрированные серверы. Основой разработки новых приложений станет объектно-ориентированная технология. Уже доказано, что она может значительно поднять продуктивность и самой разработки, и полученных в результате новых приложений. Традиционные процедурные программы будут расширяться до тех пор, пока не окажутся полностью переделанными или замененными. Этот процесс займет многие годы. Самая большая проблема объектно-ориентированной технологии — требуемый ею уровень подготовки. В результате разработка и настройка будущих приложений будут выполняться на нескольких уровнях с разными требованиями к подготовке программистов. Например, только относительно небольшая группа профессионалов, создающих ОС и средства разработки приложений, будут использовать собственно объектно-ориентированные языки, такие как С++ (часто сравниваемый с обоюдоострой бритвой). Поставщики решений и ISV, вероятно, будут использовать такие языки как Java, а также настраиваемые каркасы и готовые компоненты, например, из проекта San Francisco. Прикладные программисты, по-видимому, предпочтут визуальное соединение компонентов, а пользователи, программирующие от случая к случаю, — дружественные интерфейсы и самообучающиеся средства. Еще до 2001 года мы узнаем, работает ли подход Java «Пишется однажды — исполняется везде». Учитывая, что виртуальная машина Java реализована для всех основных платформ, вполне возможно создание Java-приложения, работающего на всех платформах. Насколько универсален такой подход — предмет споров. Объектно-ориентированные технологии предоставляют нам принципиально новый способ разработки программ. А как быстро и плодотворно мы сумеем этим воспользоваться — покажет только время. Но общее направление поисков для большинства специалистов очевидно.Общая производительность системы
В этой и предыдущей главах мы говорили о будущем AS/400, включая планы по значительному повышению производительности системы, удовлетворению потребностей новых приложений. Надеюсь, читателям ясно, что наши намерения создать в будущем новые высокопроизводительные версии системы AS/400, вполне обоснованы. Но что можно сказать о сегодняшнем дне? Как выглядит серия AS/400е на фоне своих конкурентов? Недавно я просматривал результаты тестов на производительность по нескольким вычислительным системам и размышлял о методиках ее измерения. Как часто, все же, мы предпринимаем смешные попытки свести всю нужную заказчику информацию о данном компьютере к одной цифре! Чаще всего в роли такого «универсального» показателя выступает тактовая частота процессора в мегагерцах. Как Вы помните, тактовая частота эквивалентна оборотам двигателя автомобиля — она показывает, как быстро «крутится» двигатель, но ничего не говорит об объеме выполняемой работы. Многие современные процессоры «крутятся» очень быстро, но при этом выполняют незначительную работу. Тестовые программы должны давать нам представление о том, какой объем работ выполняется на самом деле.Программы тестирования производительности
Сегодня существует великое множество разнообразных программ тестирования производительности, так что выбор той, которая больше Вам подходит — дело нелегкое. Среди производителей компьютеров наиболее широко распространены тесты, созданные независимыми разработчиками, — SPEC (Standard Performance Evaluation Corporation) и TPC (Transaction Processing Performance Council). SPEC образована в 1988 группой фирм — производителей компьютеров для разработки набора тестов для рабочих станций и серверов Unix. Набор тестов SPEC представляет собой группу программ, написанных на С и Fortran. По одним из них, ориентированным на обработку целых чисел, вычисляется показатель SPECint, по другим, ориентированным на операции с плавающей запятой, — показатель SPECfp. Для определения производительности тестовые программы запускают по очереди, замеряя время их выполнения. Итоговым значением считается среднее геометрическое (перемножение n чисел с последующим извлечением корня n-ой степени) промежуточных результатов. Первым набором тестов этой серии был SPEC89 (89 — год создания) из 10 программ (4 целочисленных и 6 с плавающей запятой). В SPEC92 число программ возросло до 20, а в последнюю версию SPEC95 были добавлены еще несколько дополнительных программ. Сейчас ведется работа над SPEC98. Так как тестовые программы очень малы и выполняются по одной, то обычно программа целиком умещается во внутреннюю кэш-память процессора. В SPEC95 было добавлено несколько программ большего размера, но и кэши так же растут. В результате, SPEC может измерить «грубую силу» процессора, но не производительность системы в целом, так как эти тесты не охватывают память и подсистему ввода-вывода. В результате, SPEC применяется, в основном, для измерения производительности однопользовательской рабочей станции Unix. И, как можно было предсказать заранее, процессоры с большими значениями МГц, такие как Digital Alpha, показывают на этих тестах очень хорошие результаты. Тесты ТРС предназначены для измерения общей производительность системы, а не только процессора. В соответствии с программным заявлением, ТРС — это бесприбыльная организация, чья цель — организация тестирования обработки транзакций и баз данных, а также распространение объективных и проверяемых результатов этих тестов. В ТРС сейчас 45 членов, в их числе все основные производители компьютеров. ТРС определяет свои тесты в терминах деловых транзакций. Например, обычная транзакция ТРС включает обновление базы данных для таких приложений, как управление инвентарным списком (товары), заказом авиабилетов (обслуживание) или банковскими операциями (деньги). На сегодня основные тесты этой группы — ТРС-С и ТРС-D. ТРС-С представляет собой тест OLTP. В процессе его пять транзакций разного типа и сложности выполняются либо параллельно, либо помещаются в очередь для отложенного исполнения. База данных содержит девять типов записей, которые сильно различаются размерами. ТРС-С измеряется в транзакциях в минуту (tpm). ТРС-С моделирует реальную вычислительную среду, где группа операторов за терминалами выполняют транзакции с обращением к базе данных. Назначение теста — проверка скорости выполнения единичных операций (транзакций) в системе обработки заказов, например, таких, как прием и доставка заказов, регистрация выплат, проверка состояния заказа и контроль за наличием товаров на складе. Хотя данный тест имитирует работу оптового поставщика, ТРС-С не ограничен каким-либо конкретной отраслью, а представляет любой бизнес по продаже или распространению товаров или услуг. Тест ТРС-D — новейший тест, определяющий эффективность широкого диапазона приложений поддержки принятия решений, где требуются сложные, долго выполняющиеся запросы к большим и сложным структурам данных. Кстати, по этой модели были написаны программы, содержащие 17 сложных запросов и примененные затем в реальном бизнесе. Для большинства современных приложений тест ТРС-С — вероятно, наилучшее средство оценки производительности. По мере дальнейшего распространения приложений поддержки принятия решений, значение теста TPC-D будет расти. В Рочестере для измерения производительности используется тест ТРС-С. Он довольно сложен и требует существенной предварительной подготовки. ТРС также добивается, чтобы все результаты ее тестов были выверены, и гарантирует это с помощью сложных и многократно дублированных измерений. С одной стороны это необходимо, чтобы обеспечить воспроизводимость результатов, но с другой — мы не можем позволить себе подобный объем тестирования для всех возможных конфигураций AS/400. Поэтому мы измеряем показатели ТРС-С лишь некоторых систем из нашей линейки серверов и отправляем результаты в ТРС для проверки. Именно эти показатели ТРС затем и публикует в виде сравнительного анализа производительности различных систем. Мы хотим предоставить нашим заказчикам правдивую и точную информацию о каждой из наших систем, и поэтому в основе всех измерений, независимо от конфигурации и режимов, лежит некоторая разновидность ТРС-С. Несколько лет назад мы выбрали одну из версий ТРС-С в качестве постоянного теста для всех наших систем. Мы не можем публиковать эти цифры как окончательные показатели ТРС-С, так как сам ТРС-С продолжает развиваться. Взамен мы публикуем информацию, собранную на основе другой системы измерения производительности — CPW (Commercial Processing Workload). Как правило, умножение показателя производительности CPW на 10 дает грубое приближение к показателю производительности ТРС-С, хотя значения, полученные в результате реального тестирования ТРС-С, обычно дают более высокий результат.Как мы сравниваем?
Новые значения показателей производительности CPW и ТРС-С для моделей серии AS/400е публикуются с каждым новым выпуском. Мы рассмотрим их на примере версии V4R1 (август 1997 года) для 12-канальных систем. (Дело в том, что к моменту написания этой книги показатели серии AS/400е еще не были сертифицированы, и потому их нельзя рассматривать как окончательные). В таблице 12.1 даны значения производительности пяти лучших систем на момент выхода V4R1, а также моя оценка места в этом списке 12-канальной AS/400. Разумеется, и конкретные цифры, и положение систем в списке все время меняются по мере выпуска новых моделей и проведения повторных тестовых измерений.| Место | Система (конфигурация) | tpm |
| 1 | Sun Ultra Enterprise 6000 (24-канальная) | 31.147 |
| 2 | Digital AlphaServer 8400 5/350 | 30.390 |
| (4 узла x 12-каналов) | ||
| 3 | SGI Origin 2000 Server (28-канальная) | 25.309 |
| 4 | IBM AS/400 9406 S40 (12-канальная) | 25.149[ 90 ] |
| 5 | Sun Ultra Enterprise 6000 (16-канальная) | 23.143 |
Вы можете получить текущие показатели производительности ТРС-С из ряда источников, включая узел WWW Transaction Processing Performance Council (http: //www.tpc.org). Лично я предпочитаю узел WWW IDEAS International (http:// www.ideasinternational.com) — компании из Сиднея (Sydney), Австралия, которая специализируется на распространении сравнительной информации о вычислительных системах по Интернету. Эта организация — член совета ТРС и принимает участие в разработке тестов. На странице WWW IDEAS International опубликованы сравнительные результаты тестов для многих систем. Я предпочитаю их Top 20 для ТРС-С. Информация таблицы 12.1 интересна с нескольких точек зрения. Во-первых, значения для 12-канальной AS/400 во много раз выше, чем предыдущие опубликованные значения ТРС-С для любой AS/400. Теперь эта одиночная система сравнялась с самыми крупными одиночными системами IBM, считая мэйнфреймы, и уступает лишь кластерам. Во-вторых, эти показатели демонстрируют эффективность и перспективность AS/400. Для наглядности давайте рассмотрим системы, превосходящие AS/400 по показателю ТРС-С. Самый высокий показатель tpm в таблице 12.1 принадлежит 24-канальному серверу Sun Ultra Enterprise, который содержит 24 процессора UltraSPARC с тактовой частотой 250 МГц. Учитывая, что по сравнению с AS/400 в данной системе Sun вдвое больше процессоров с вдвое большей тактовой частотой, логично ожидать такого же превосходства по числу выполняемых ею транзакций. Но нет, их больше лишь на четверть. Обратите внимание на то, что 12-канальная AS/400 стоит в списке выше 16-канального сервера Sun Ultra Enterprise. Так или иначе, 24-канальная система Sun достаточно эффективна по сравнению с другими машинами из списка. Второе место в таблице занимает 48-процессорный Digital AlphaServer, сконфигурированный как кластер из четырех 12-канальных серверов. Учитывая, что процессоры данной системы работают на тактовой частоте 350 МГц, можно сделать вывод, что это, вероятно, самая малоэффективная система в списке. От быстрых процессоров, которые большую часть времени простаивают, ожидая памяти или ввода-вывода, не слишком много толку, за исключением возможности похвастаться высокими МГц. Данная конфигурация служит прекрасной иллюстрацией тезиса, что само по себе высокое значение тактовой частоты еще ничего не дает. На третьем месте, лишь на доли процента обгоняя AS/400, стоит 28-канальная Silicon Graphics Origin2000 Server. Как я уже упоминал, данная система примечательна тем, что лежит в основе проекта ASCI Blue Mountain. Тем не менее, она со своими 28 процессорами, имеющими частоту 195 МГц, лишь ненамного превосходит AS/400 с 12 процессорами, работающими на частоте лишь 125 МГц. Высокие показатели коммерческого тестирования, такого как ТРС-С, может дать только сбалансированная система. Мы стремимся повышать производительность процессора, памяти и подсистемы ввода-вывода в целом, и каждого компонента в отдельности. Высоким показателем общей производительности AS/400 обязана необычайной эффективности своих подсистем памяти и ввода-вывода Благодаря новой структуре памяти, AS/400 теперь использует возможности полной 64-разрядной реализации. Следующие версии этой подсистемы позволят устанавливать на AS/400 еще больше процессоров с повышенной тактовой частотой. Наш подход остается прежним — реальную полезную производительность для деловых вычислений дает лишь сбалансированная система.
Выводы
В компьютерной индустрии постоянны только перемены. Сегодняшние технологии устаревают очень быстро, а вместе с ними меняется и современный бизнес. В будущем эта тенденция только усилится. Все технологии приходят и уходят; некоторые из них оказываются полезными заказчикам, повышают конкурентоспособность их бизнеса. Когда эта польза становится очевидной производителям компьютеров и ПО, они внедряют новые технологии в свои вычислительные системы. Несомненно, та же судьба ожидает аппаратные и программные технологии, описанные в этой главе. Со временем их заменят еще более совершенные. Подобно тому, как приходят и уходят технологии, приходят и уходят вычислительные системы, и производящие их компьютерные фирмы. История показывает, что особенно часто это случается, если вычислительная система или фирма привязана к технологии, которая рано или поздно теряет свое значение для бизнеса, или становится общедоступной на рынке. Представьте себе на мгновение, что сейчас начало 80-х. Вы собираетесь купить для своего предприятия коммерческий компьютер среднего класса. Далее, представьте себе, что Рочестер в 1969 не стал заниматься компьютерами. По каким причинам? Ну, скажем, руководство IBM в 60-х годах «засекло» план Рочестера по созданию новой линии несовместимых компьютеров и сказало «Нет». Да какая, в общем-то, разница?! Важно то, что Вы не можете выбрать для своего предприятия систему Рочестера, так как таковых нет. Самой популярной технологией тех дней были офисные системы. Большинство производителей предлагали офисные системы и системы обработки данных по отдельности. Одним из первопроходцев интеграции была компания Wang Computers. В начале 80-х годов Wang считался лидером офисных систем. Другие компьютерные фирмы также быстро поняли значение данной технологии офисных систем, и скоро началось ее массовое внедрение в системах среднего класса.
Итак, предположим, что систем Рочестера в природе не существует, и Вы покупаете одну из офисных систем Wang. Наступает конец 80-х, и Вы решаете модернизировать свое предприятие путем покупки новой вычислительной системы среднего класса. В это время твердые позиции на рынке заняли производители миникомпьютеров, начинавшие с освоения технических расчетов. Возглавляемые такими системами, как VAX фирмы Digital, они теперь поддерживают большинство необходимых бизнесу технологий. Например, Digital предлагает ПО All-in-One, которое реализует большинство офисных функций. Вы решаете заменить Wang на Digital VAX.
Проходит еще несколько лет, и теперь у нас начало 90-х. Вы, как и многие предприниматели обеспокоены тем, что привязаны к нестандартным вычислительным системам, таким как Digital VAX. Если каждые несколько лет заменять свои системы более совершенными, нормальный ход дел в офисе постоянно нарушается. На повестке дня — открытость и стандарты. Самой открытой системой считается Unix. Производители, прекратившие выпуск своих нестандартных систем, например HP, расхваливают открытость Unix. Многие заказчики думают, что смогут легко менять разные системы от разных производителей, если просто станут работать на Unix. Соблазн велик, и Вы решаете еще раз и навсегда пройти через смену систем. Вы заменяете
свою Digital VAX на HP 9000.
И вот наступает середина 90-х. Практически все производители компьютеров используют открытые стандарты. Системы Unix не оправдали возлагавшихся на них надежд: перевод делопроизводства с одной системы на другую не стал легче, а затраты владельцев превзошли первоначальные ожидания. «Хитом дня» становятся клиент-серверные вычисления. Некоторые фирмы пытаются заменить свои системы среднего класса на ЛВС ПК, но это себя оправдывает лишь для самых небольших организаций. Возможным выходом из тупика выглядят большие многопроцессорные ПК-серверы. Кроме того, внезапно обнаруживается, что нестандартные ОС, такие как Microsoft Windows NT, могут быть столь же открытыми, как Unix. В результате, популярность Unix на рынке быстро угасает. Вы хотите использовать на своем предприятии новейшие технологии, и поэтому в очередной раз проглатываете наживку и заменяете свою HP 9000 сервером Compaq ProLiant с Windows NT.
Время не стоит на месте, и настает 2001 год. Расходы на персональные компьютеры превысили все ожидания. Приложения различных производителей работают совместно ничуть не лучше, чем раньше. Все что Вы сэкономили, потрачено на модернизацию аппаратных и программных средств, которой Вам приходится заниматься каждые шесть месяцев лишь для того, чтобы не отстать от конкурентов. И вот технологический прогресс привел к созданию концептуально новой вычислительной системы, которая наконец-то решит все Ваши проблемы. Это уж точно последний раз! Вы выбрасываете свой сервер Compaq и ставите новый компьютер VR2000 от корпорации «Виртуальная реальность». Девиз этой новой фирмы гласит: «Наша продукция слишком хороша, чтобы быть реальной — она виртуальная!». Наша сага на этом заканчивается, потому что никто не знает, станет ли новой модной системой VR2000 или что-нибудь еще. Но наверняка «свято место пусто не бывает» и такая система будет. И также можно быть уверенным, что и эта новейшая система, увы, не решит все проблемы, а переход на нее снова серьезно скажется на Вашем бизнесе.
Почему же фирмы продолжают жонглировать своими вычислительными системами? Несомненно, такой подход обеспечивает рабочие места, но есть ли в этом смысл? Правильный ответ: общее нежелание отстать от конкурентов. Именно поэтому так много заказчиков постоянно ищут новую систему, которая приведет их в будущее.
По счастью, семейство систем, которое обеспечит Вам конкурентные преимущества в бизнесе без огромных расходов и перебоев в работе все же существует. За последние 15 лет по всему миру было установлено более 700 000 коммерческих систем Рочестера. Никто другой не может даже приблизиться к такому результату.
Вернемся снова к началу. Помните, слова, открывавшие главу 1: «Выносливость любой компьютерной системы и ее способность сохранять инвестиции, — самые важные аргументы при выборе компьютера для производства или офиса». Если это так, то AS/400 — самый успешный многопользовательский компьютер для бизнеса из всех когда-либо существовавших. А благодаря чему, все это достигнуто (все эти искусные архитектуры и новейших технологии) — так ли уж важно?
Представьте себе на мгновение, что сейчас начало 80-х. Вы собираетесь купить для своего предприятия коммерческий компьютер среднего класса. Далее, представьте себе, что Рочестер в 1969 не стал заниматься компьютерами. По каким причинам? Ну, скажем, руководство IBM в 60-х годах «засекло» план Рочестера по созданию новой линии несовместимых компьютеров и сказало «Нет». Да какая, в общем-то, разница?! Важно то, что Вы не можете выбрать для своего предприятия систему Рочестера, так как таковых нет. Самой популярной технологией тех дней были офисные системы. Большинство производителей предлагали офисные системы и системы обработки данных по отдельности. Одним из первопроходцев интеграции была компания Wang Computers. В начале 80-х годов Wang считался лидером офисных систем. Другие компьютерные фирмы также быстро поняли значение данной технологии офисных систем, и скоро началось ее массовое внедрение в системах среднего класса.
Итак, предположим, что систем Рочестера в природе не существует, и Вы покупаете одну из офисных систем Wang. Наступает конец 80-х, и Вы решаете модернизировать свое предприятие путем покупки новой вычислительной системы среднего класса. В это время твердые позиции на рынке заняли производители миникомпьютеров, начинавшие с освоения технических расчетов. Возглавляемые такими системами, как VAX фирмы Digital, они теперь поддерживают большинство необходимых бизнесу технологий. Например, Digital предлагает ПО All-in-One, которое реализует большинство офисных функций. Вы решаете заменить Wang на Digital VAX.
Проходит еще несколько лет, и теперь у нас начало 90-х. Вы, как и многие предприниматели обеспокоены тем, что привязаны к нестандартным вычислительным системам, таким как Digital VAX. Если каждые несколько лет заменять свои системы более совершенными, нормальный ход дел в офисе постоянно нарушается. На повестке дня — открытость и стандарты. Самой открытой системой считается Unix. Производители, прекратившие выпуск своих нестандартных систем, например HP, расхваливают открытость Unix. Многие заказчики думают, что смогут легко менять разные системы от разных производителей, если просто станут работать на Unix. Соблазн велик, и Вы решаете еще раз и навсегда пройти через смену систем. Вы заменяете
свою Digital VAX на HP 9000.
И вот наступает середина 90-х. Практически все производители компьютеров используют открытые стандарты. Системы Unix не оправдали возлагавшихся на них надежд: перевод делопроизводства с одной системы на другую не стал легче, а затраты владельцев превзошли первоначальные ожидания. «Хитом дня» становятся клиент-серверные вычисления. Некоторые фирмы пытаются заменить свои системы среднего класса на ЛВС ПК, но это себя оправдывает лишь для самых небольших организаций. Возможным выходом из тупика выглядят большие многопроцессорные ПК-серверы. Кроме того, внезапно обнаруживается, что нестандартные ОС, такие как Microsoft Windows NT, могут быть столь же открытыми, как Unix. В результате, популярность Unix на рынке быстро угасает. Вы хотите использовать на своем предприятии новейшие технологии, и поэтому в очередной раз проглатываете наживку и заменяете свою HP 9000 сервером Compaq ProLiant с Windows NT.
Время не стоит на месте, и настает 2001 год. Расходы на персональные компьютеры превысили все ожидания. Приложения различных производителей работают совместно ничуть не лучше, чем раньше. Все что Вы сэкономили, потрачено на модернизацию аппаратных и программных средств, которой Вам приходится заниматься каждые шесть месяцев лишь для того, чтобы не отстать от конкурентов. И вот технологический прогресс привел к созданию концептуально новой вычислительной системы, которая наконец-то решит все Ваши проблемы. Это уж точно последний раз! Вы выбрасываете свой сервер Compaq и ставите новый компьютер VR2000 от корпорации «Виртуальная реальность». Девиз этой новой фирмы гласит: «Наша продукция слишком хороша, чтобы быть реальной — она виртуальная!». Наша сага на этом заканчивается, потому что никто не знает, станет ли новой модной системой VR2000 или что-нибудь еще. Но наверняка «свято место пусто не бывает» и такая система будет. И также можно быть уверенным, что и эта новейшая система, увы, не решит все проблемы, а переход на нее снова серьезно скажется на Вашем бизнесе.
Почему же фирмы продолжают жонглировать своими вычислительными системами? Несомненно, такой подход обеспечивает рабочие места, но есть ли в этом смысл? Правильный ответ: общее нежелание отстать от конкурентов. Именно поэтому так много заказчиков постоянно ищут новую систему, которая приведет их в будущее.
По счастью, семейство систем, которое обеспечит Вам конкурентные преимущества в бизнесе без огромных расходов и перебоев в работе все же существует. За последние 15 лет по всему миру было установлено более 700 000 коммерческих систем Рочестера. Никто другой не может даже приблизиться к такому результату.
Вернемся снова к началу. Помните, слова, открывавшие главу 1: «Выносливость любой компьютерной системы и ее способность сохранять инвестиции, — самые важные аргументы при выборе компьютера для производства или офиса». Если это так, то AS/400 — самый успешный многопользовательский компьютер для бизнеса из всех когда-либо существовавших. А благодаря чему, все это достигнуто (все эти искусные архитектуры и новейших технологии) — так ли уж важно?



Последние комментарии
4 часов 56 минут назад
4 часов 59 минут назад
5 часов 10 минут назад
5 часов 16 минут назад
5 часов 18 минут назад
5 часов 21 минут назад